Le langage de programmation Rust
par Steve Klabnik, Carol Nichols et Chris Krycho, avec la participation de la Communauté Rust
Cette version du document suppose que vous utilisez Rust 1.90.0 (publié le 18/09/2025) ou ultérieur, avec edition = "2024" renseigné dans le fichier Cargo.toml de tous les projets pour qu’ils soient configurés afin d’utiliser les expressions de l’édition 2024 de Rust. Voir la section “Installation” du chapitre 1 pour installer ou mettre à jour Rust.
Le format HTML de la version anglaise est disponible en ligne à l’adresse https://doc.rust-lang.org/stable/book/ et en hors-ligne avec l’installation de Rust qui a été effectuée avec rustup ; vous pouvez lancer rustup doc --book pour l’ouvrir.
Vous avez aussi à votre disposition quelques traductions entretenues par la communauté.
La version anglaise de ce livre est disponible au format papier et e-book chez No Starch Press.
🚨 Si vous souhaitez un apprentissage qui soit plus interactif, vous pouvez essayer une autre version du Livre de Rust qui comprend des quiz, de la coloration syntaxique, des visualisations et bien plus encore : https://rust-book.cs.brown.edu
Avant-propos
Le langage de programmation Rust a parcouru un bien long chemin en l’espace de quelques années seulement, depuis sa création et son incubation par une petite communauté naissante de passionnés, jusqu’à devenir l’un des langages de programmation les plus appréciés et les plus demandés au monde. En prenant du recul, il était inévitable que la puissance et le potentiel de Rust attirent l’attention et lui permettent de s’imposer dans le domaine de la programmation système. Ce qui n’était pas inévitable, en revanche, c’était l’intérêt et l’innovation croissants à l’échelle mondiale qui ont imprégné les communautés open source et catalysé son adoption à grande échelle dans tous les secteurs.
À l’heure actuelle, il est facile de mettre en avant les fonctionnalités exceptionnelles offertes par Rust pour expliquer cet engouement et cette adoption qui furent fulgurants. En effet, qui ne souhaite pas bénéficier d’une sécurité mémoire et de performances rapides et d’un compilateur convivial et d’excellents outils, parmi une multitude d’autres fonctionnalités exceptionnelles ? Le langage Rust tel qu’il existe aujourd’hui est le fruit de nombreuses années de recherche en programmation système et du savoir-faire pratique d’une communauté dynamique et passionnée. Ce langage a été conçu avec un objectif précis et élaboré avec soin, afin d’offrir aux développeurs un outil qui facilite l’écriture de code sûr, rapide et fiable.
Mais ce qui rend Rust vraiment spécial, c’est sa volonté de vous donner, à vous, l’utilisateur, les moyens d’atteindre vos objectifs. C’est un langage qui veut vous aider à réussir, et le principe d’autonomisation est au cœur de la communauté qui développe, maintient et promeut ce langage. Depuis la précédente édition de cet ouvrage de référence, Rust s’est encore développé pour devenir un langage véritablement mondial et fiable. Le projet Rust bénéficie désormais du soutien solide de la Fondation Rust, qui investit également dans des initiatives clés visant à garantir la sécurité, la stabilité et la pérennité de Rust.
Cette édition de The Rust Programming Language est une mise à jour complète qui reflète l’évolution du langage au fil des ans et fournit de nouvelles informations précieuses. Mais il ne s’agit pas seulement d’un guide sur la syntaxe et les bibliothèques, c’est aussi une invitation à rejoindre une communauté qui valorise la qualité, la performance et la conception réfléchie. Que vous soyez un développeur chevronné souhaitant découvrir Rust pour la première fois ou un Rustacé expérimenté cherchant à perfectionner ses compétences, cette édition a quelque chose à offrir à chacun.
Le parcours de Rust a été marqué par la collaboration, l’apprentissage et l’itération. La croissance du langage et de son écosystème reflète directement la communauté dynamique et diversifiée qui le soutient. Les contributions de milliers de développeurs, depuis les concepteurs du langage de base jusqu’aux contributeurs occasionnels, font de Rust un outil unique et puissant. En choisissant ce livre, vous n’apprenez pas seulement un nouveau langage de programmation, vous êtes en train de rejoindre un mouvement visant à rendre les logiciels meilleurs, plus sûrs et plus agréables à utiliser.
Bienvenue dans la communauté Rust !
- Bec Rumbul, directeur exécutif de la Fondation Rust
Introduction
Note : la version anglaise de ce livre est disponible au format papier et ebook chez No Starch Press à cette adresse : The Rust Programming Language
Bienvenue sur Le langage de programmation Rust, un livre d’initiation à Rust. Le langage de programmation Rust vous aide à écrire plus rapidement des logiciels plus fiables. L’ergonomie de haut-niveau et la maîtrise de bas-niveau sont souvent en opposition dans la conception des langages de programmation ; Rust remet en cause ce conflit. Grâce à l’équilibre entre ses puissantes capacités techniques et une bonne ergonomie de développement, Rust vous donne la possibilité de contrôler les détails de bas-niveau (comme l’utilisation de la mémoire) sans tous les soucis traditionnellement associés à ce genre de pratique.
À qui s’adresse Rust
Rust est idéal pour de nombreuses personnes pour diverses raisons. Analysons quelques-uns des groupes les plus importants.
Équipes de développeurs
Rust se révèle être un outil productif pour la collaboration entre de grandes équipes de développeurs ayant différents niveaux de connaissances en programmation système. Le code de bas-niveau est sujet à une multitude de bogues subtils, qui, dans la plupart des autres langages, ne peuvent être prévenus qu’au moyen de campagnes de test étendues et de minutieuses revues de code menées par des développeurs chevronnés. Avec Rust, le compilateur joue le rôle de gardien en refusant de compiler du code qui comprend ces bogues discrets et vicieux, y compris les bogues de concurrence. En travaillant avec le compilateur, l’équipe peut se concentrer sur la logique du programme plutôt que de traquer les bogues.
Rust offre aussi des outils de développement modernes au monde de la programmation système :
- Cargo, l’outil intégré de gestion de dépendances et de compilation, qui uniformise et facilite l’ajout, la compilation, et la gestion des dépendances dans l’écosystème Rust.
- L’outil de formatage Rustfmt, qui assure une cohérence de style de codage pour tous les développeurs.
- Le Rust Langage Server alimente les environnements de développement intégrés (IDE) pour la complétion du code et l’affichage direct des messages d’erreur.
En utilisant ces outils ainsi que d’autres dans l’écosystème Rust, les développeurs peuvent être plus productifs quand ils écrivent du code système.
Étudiants
Rust est conçu pour les étudiants et ceux qui s’intéressent à l’apprentissage des concepts système. En utilisant Rust, de nombreuses personnes ont appris des domaines comme le développement de systèmes d’exploitation. La communauté est très accueillante et répond volontiers aux questions des étudiants. Grâce à des initiatives comme ce livre, les équipes de Rust veulent rendre les notions système accessibles au plus grand nombre, particulièrement à ceux qui débutent dans la programmation.
Entreprises
Des centaines d’entreprises, petites et grosses, utilisent Rust en production pour différentes tâches, lesquelles incluent des outils en ligne de commande, des services web, des outils DevOps, des systèmes embarqués, de l’analyse et de la conversion audio et vidéo, des cryptomonnaies, de la bio-informatique, des moteurs de recherche, de l’Internet des objets (IoT), de l’apprentissage automatique (machine learning), et même des parties importantes du navigateur internet Firefox.
Développeurs de logiciel libre
Rust est ouvert aux personnes qui veulent développer le langage de programmation Rust, la communauté, les outils de développement et les bibliothèques. Nous serions ravis que vous contribuiez au langage Rust.
Les personnes qui recherchent la rapidité et la stabilité
Rust est une solution pour les personnes qui chérissent la rapidité et la stabilité dans un langage. Par rapidité, nous entendons la vitesse des programmes que vous pouvez créer avec Rust et la rapidité avec laquelle Rust vous permet de les écrire. Les vérifications du compilateur de Rust assurent la stabilité durant l’ajout de fonctionnalités ou le remaniement du code. Cela le démarque des langages qui ne font pas ces contrôles sur du code instable que le programme a hérité avec le temps, et que bien souvent les développeurs ont peur de modifier. En s’efforçant de mettre en place des abstractions sans coût, des fonctionnalités de haut-niveau qui compilent vers du code bas-niveau aussi rapide que s’il avait été écrit à la main, Rust fait en sorte que le code sûr soit aussi du code rapide.
Le langage Rust espère aider beaucoup d’autres utilisateurs ; ceux cités ici ne font partie que d’un univers bien plus grand. Globalement, la plus grande ambition de Rust est d’éradiquer les compromis auxquels les développeurs se soumettaient depuis des décennies en leur apportant sécurité et productivité, rapidité et ergonomie. Essayez Rust et vérifiez si ses décisions vous conviennent.
À qui est destiné ce livre
Ce livre suppose que vous avez écrit du code dans un autre langage de programmation mais ne suppose pas lequel. Nous avons essayé de rendre son contenu le plus accessible au plus grand nombre d’expériences de programmation possible. Nous ne nous évertuons pas à nous questionner sur ce qu’est la programmation ou comment l’envisager. Si vous êtes débutant en programmation, vous seriez mieux avisé en lisant d’abord un livre qui vous initie à la programmation.
Comment utiliser ce livre
Globalement, ce livre est prévu pour être lu dans l’ordre. Les chapitres suivants s’appuient sur les notions abordées dans les chapitres précédents, et lorsque les chapitres précédents ne peuvent pas approfondir un sujet, ce sera généralement fait dans un chapitre suivant.
Vous allez rencontrer deux différents types de chapitres dans ce livre : les chapitres théoriques et les chapitres de projet. Dans les chapitres théoriques, vous allez apprendre un sujet à propos de Rust. Dans un chapitre de projet, nous allons construire ensemble des petits programmes, pour appliquer ce que vous avez appris précédemment. Les chapitres 2, 12 et 21 sont des chapitres de projet ; les autres sont des chapitres théoriques.
Le chapitre 1 explique comment installer Rust, comment écrire un programme “Hello, world!” et comment utiliser Cargo, le gestionnaire de paquets et outil de compilation. Le chapitre 2 est une initiation pratique à l’écriture d’un programme en Rust, qui vous fait écrire un jeu de devinette de chiffres. Nous y aborderons des concepts de haut niveau, et les chapitres suivants apporteront plus de détails. Si vous voulez vous salir les mains tout de suite, le chapitre 2 est l’endroit pour cela. Toutefois, si vous êtes un apprenti particulièrement minutieux qui préfère apprendre chaque particularité avant de passer à la suivante, vous pouvez sauter le chapitre 2 et passer directement au chapitre 3, lequel aborde les fonctionnalités de Rust semblables aux autres langages de programmation, puis revenir au chapitre 2 lorsque vous souhaitez travailler sur un projet en appliquant les notions que vous avez apprises.
Dans le chapitre 4, vous apprendrez ce qu’est le système de possession (ownership) de Rust. Le chapitre 5 traite des structures et des méthodes. Le chapitre 6 couvre les énumérations, les expressions match, et les structures de contrôle if let et let...else. Vous emploierez les structures et les énumérations pour créer des types personnalisés avec Rust.
Au chapitre 7, vous apprendrez le système de modules de Rust et les règles de visibilité, afin d’organiser votre code et son interface de programmation applicative (API) publique. Le chapitre 8 traitera des structures de collections de données usuelles fournies par la bibliothèque standard : les vecteurs, les chaînes de caractères et les tables de hachage (hash maps). Le chapitre 9 explorera la philosophie et les techniques de gestion d’erreurs de Rust.
Le chapitre 10 nous plongera dans la généricité, les traits et les durées de vie, qui vous donneront la capacité de créer du code qui s’adapte à différents types. Le chapitre 11 traitera des techniques de test, qui restent nécessaires malgré les garanties de sécurité de Rust, pour s’assurer que la logique de votre programme est valide. Au chapitre 12, nous écrirons notre propre implémentation d’un sous-ensemble des fonctionnalités du programme en ligne de commande grep, qui recherche du texte dans des fichiers. Pour ce faire, nous utiliserons de nombreuses notions abordées dans les chapitres précédents.
Le chapitre 13 explorera les fermetures (closures) et itérateurs : ce sont les fonctionnalités de Rust inspirées des langages de programmation fonctionnels. Au chapitre 14, nous explorerons plus en profondeur Cargo et les bonnes pratiques pour partager vos propres bibliothèques avec les autres. Le chapitre 15 parlera de pointeurs intelligents qu’apporte la bibliothèque standard et des traits qui activent leurs fonctionnalités.
Au chapitre 16, nous passerons en revue les différents modes de programmation concurrente et comment Rust nous aide à développer dans des tâches parallèles sans crainte. Dans le chapitre 17, nous approfondissons ce sujet en explorant la syntaxe async et await de Rust, ainsi que les tâches, les futurs et les flux, et le modèle de concurrence léger qu’ils permettent.
Le chapitre 18 comparera les fonctionnalités de Rust aux principes de programmation orientée objet, que vous connaissez peut-être. Le chapitre 19 est une référence sur les motifs et le filtrage de motif (pattern matching), qui sont des moyens puissants permettant de communiquer des idées dans les programmes Rust. Le chapitre 20 contient une foultitude de sujets avancés intéressants, comme le code Rust non sécurisé (unsafe), les macros et plus de détails sur les durées de vie, les traits, les types, les fonctions et les fermetures (closures).
Au chapitre 21, nous terminerons un projet dans lequel nous allons implémenter en bas-niveau un serveur web multitâches !
Et finalement, quelques annexes qui contiennent des informations utiles sur le langage sous forme de référentiels qui renvoient à d’autres documents. L’annexe A liste les mots-clés de Rust, l’annexe B couvre les opérateurs et symboles de Rust, l’annexe C parle des traits dérivables qu’apporte la bibliothèque standard, l’annexe D référence certains outils de développement utiles, et l’annexe E explique les différentes éditions de Rust. Dans l’annexe F, vous trouverez les traductions du Livre, et dans l’annexe G, nous expliquerons comment Rust est créé et ce qu’est Rust nightly.
Il n’y a pas de mauvaise manière de lire ce livre : si vous voulez sauter des étapes, allez-y ! Vous devrez alors peut-être revenir sur les chapitres précédents si vous éprouvez des difficultés. Mais faites comme bon vous semble.
Une composante importante du processus d’apprentissage de Rust est de comprendre comment lire les messages d’erreur qu’affiche le compilateur : ils vous guideront vers du code correct. Ainsi, nous citerons de nombreux exemples qui ne compilent pas, avec le message d’erreur que le compilateur devrait vous afficher dans chaque cas. C’est donc normal que dans certains cas, si vous copiez et exécutez un exemple au hasard, il ne compile pas ! Assurez-vous d’avoir lu le texte autour pour savoir si l’exemple que vous tentez de compiler doit échouer. Dans la plupart des cas, nous vous guiderons vers la version correcte de tout code qui ne compile pas. Ferris va aussi vous aider à identifier du code qui ne devrait pas fonctionner :
| Ferris | Signification |
|---|---|
 | Ce code ne compile pas ! |
 | Ce code panique ! |
 | Ce code ne se comporte pas comme voulu. |
Dans la plupart des cas, nous vous guiderons vers la version du code qui devrait fonctionner.
Code source
Les fichiers du code source qui a généré ce livre en anglais sont disponibles sur GitHub.
Des versions françaises sont aussi disponibles sur GitHub et à rust-lang-translations.org.
Prise en main
Démarrons notre périple avec Rust ! Il y a beaucoup à apprendre, mais chaque aventure doit commencer quelque part. Dans ce chapitre, nous allons aborder :
- L’installation de Rust sur Linux, macOS et Windows
- L’écriture d’un programme qui affiche
Hello, world! - L’utilisation de
cargo, le gestionnaire de paquets et système de compilation de Rust
Installation
Installation
La première étape consiste à installer Rust. Nous allons télécharger Rust via rustup, un outil en ligne de commande conçu pour gérer les versions de Rust et les outils qui leur sont associés. Vous allez avoir besoin d’une connexion Internet pour le téléchargement.
Note : si vous préférez ne pas utiliser rustup pour une raison ou une autre, vous pouvez vous référer à la page des autres moyens d’installation de Rust pour d’autres méthodes d’installation.
L’étape suivante est d’installer la dernière version stable du compilateur Rust. La garantie de stabilité de Rust assurera que tous les exemples dans le livre qui se compilent bien vont continuer à se compiler avec les nouvelles versions de Rust. La sortie peut varier légèrement d’une version à une autre, car Rust améliore souvent les messages d’erreur et les avertissements. En résumé, toute nouvelle version stable de Rust que vous installez de cette manière devrait fonctionner en cohérence avec le contenu de ce livre.
La notation en ligne de commande
Dans ce chapitre et les suivants dans le livre, nous allons montrer quelques commandes tapées dans le terminal. Les lignes que vous devrez écrire dans le terminal commencent toutes par $. Vous n’avez pas besoin d’écrire le caractère $; c’est l’invite (prompt) qui marque le début de chaque commande. Les lignes qui ne commencent pas par $ montrent généralement le résultat de la commande précédente. De plus, les exemples propres à PowerShell utiliseront > plutôt que $.
Installer rustup sur Linux ou macOS
Si vous utilisez Linux ou macOS, ouvrez un terminal et écrivez la commande suivante :
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Cette commande télécharge un script et lance l’installation de l’outil rustup, qui va installer la dernière version stable de Rust. Il est possible que l’on vous demande votre mot de passe. Si l’installation se déroule bien, vous devriez voir la ligne suivante s’afficher :
Rust is installed now. Great!
Vous aurez aussi besoin d’un linker, qui est un programme que Rust utilise pour regrouper ses multiples résultats de compilation dans un unique fichier. Il est probable que vous en ayez déjà un d’installé, mais si vous avez des erreurs à propos du linker, cela veut dire que vous devrez installer un compilateur de langage C, qui inclura généralement un linker. Un compilateur C est parfois utile car certains paquets Rust communs nécessitent du code C et auront besoin d’un compilateur C.
Sur macOS, vous pouvez obtenir un compilateur C en lançant la commande :
$ xcode-select --install
Les utilisateurs de Linux doivent généralement installer GCC ou Clang, en fonction de la documentation de leur distribution. Par exemple, si vous utilisez Ubuntu, vous pouvez installer le paquet build-essential.
Installer rustup sous Windows
Sous Windows, il faut aller sur https://www.rust-lang.org/tools/install et suivre les instructions pour installer Rust. À un moment donné durant l’installation, vous aurez un message vous expliquant qu’il va vous falloir installer Visual Studio. Ce dernier fournit un linker et les bibliothèques natives nécessaires à la compilation de programmes. Si vous avez besoin de plus d’aide concernant cette étape, voyez https://rust-lang.github.io/rustup/installation/windows-msvc.html .
La suite de ce livre utilisera des commandes qui fonctionnent à la fois dans cmd.exe et PowerShell. S’il y a des différences particulières, nous vous expliquerons lesquelles utiliser.
Dépannage
Pour vérifier si Rust est correctement installé, ouvrez un terminal et entrez cette ligne :
$ rustc --version
Vous devriez voir le numéro de version, le hash de commit, et la date de commit de la dernière version stable qui a été publiée, au format suivant :
rustc x.y.z (abcabcabc yyyy-mm-dd)
Si vous voyez cette information, c’est que vous avez installé Rust avec succès ! Si vous ne voyez pas cette information, vérifiez que Rust est présent dans votre variable d’environnement système %PATH% comme suit.
Dans le terminal CMD de Windows, entrez :
> echo %PATH%
Dans PowerShell, entrez :
> echo $env:Path
Sous GNU/Linux et macOS, entrez :
$ echo $PATH
Si tout est correct et que Rust ne fonctionne toujours pas, il y a quelques endroits où vous pourrez trouver de l’aide. Découvrez comment entrer en contact avec d’autres Rustacés (un surnom ridicule que nous nous donnons entre nous) sur la page communautaire.
Mettre à jour et désinstaller
Après avoir installé Rust avec rustup, la mise à jour vers la dernière version est facile. Dans votre terminal, lancez le script de mise à jour suivant :
$ rustup update
Pour désinstaller Rust et rustup, exécutez le script de désinstallation suivant dans votre terminal :
$ rustup self uninstall
Lecture de la documentation en local
L’installation de Rust embarque aussi une copie de la documentation en local pour que vous puissiez la lire hors ligne. Lancez rustup doc afin d’ouvrir la documentation locale dans votre navigateur.
À chaque fois que vous n’êtes pas sûr de ce que fait un type ou une fonction fournie par la bibliothèque standard ou que vous ne savez pas comment l’utiliser, utilisez cette documentation de l’interface de programmation applicative (API) pour le savoir !
Utilisation d’éditeurs de texte et d’IDEs
Ce livre ne fait aucune supposition quant aux outils que vous utilisez pour écrire du code Rust. N’importe quel éditeur de texte fera l’affaire ! Cependant, de nombreux éditeurs de texte et environnements de développement intégrés (IDE) prennent en charge Rust. Vous trouverez une liste assez récente de nombreux éditeurs et IDE sur la page des outils du site web Rust.
Travailler hors-ligne avec ce livre
Dans plusieurs exemples, nous utiliserons des paquets Rust qui ne font pas partie de la bibliothèque standard. Pour travailler sur ces exemples, vous devrez soit disposer d’une connexion à Internet, soit avoir téléchargé ces dépendances à l’avance. Pour télécharger les dépendances à l’avance, vous pouvez exécuter les commandes suivantes (nous expliquerons plus en détail ce qu’est cargo et ce que fait chacune de ces commandes ultérieurement).
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
Cela mettra en cache les téléchargements de ces paquets afin que vous n’ayez pas à les télécharger ultérieurement. Une fois cette commande exécutée, vous n’avez plus besoin de conserver le répertoire get-dependencies. Si vous avez exécuté cette commande, vous pouvez utiliser le drapeau --offline avec toutes les commandes cargo dans le reste du livre pour utiliser ces versions mises en cache, au lieu d’essayer d’utiliser le réseau.
Hello, World!
Hello, World!
Maintenant que vous avez installé Rust, il est temps d’écrire notre premier programme Rust. Lorsqu’on apprend un nouveau langage, il est de tradition d’écrire un petit programme qui écrit le texte “Hello, world!” à l’écran, donc c’est ce que nous allons faire !
Note : ce livre part du principe que vous êtes familier avec la ligne de commande. Rust n’impose pas d’exigences sur votre éditeur, vos outils ou l’endroit où vous mettez votre code, donc si vous préférez utiliser un environnement de développement intégré (IDE) au lieu de la ligne de commande, vous êtes libre d’utiliser votre IDE favori. De nombreux IDE prennent en charge Rust à des degrés divers ; consultez la documentation de l’IDE pour plus d’informations. L’équipe Rust s’est attelée à améliorer l’intégration dans les IDE via rust-analyzer. Voir l’annexe D pour plus de détails.
Créer un répertoire projet
Nous allons commencer par créer un répertoire pour y ranger le code Rust. Là où vous mettez votre code n’est pas important pour Rust, mais pour les exercices et projets de ce livre, nous vous suggérons de créer un répertoire projects dans votre répertoire utilisateur et de ranger tous vos projets là-dedans.
Ouvrez un terminal et écrivez les commandes suivantes pour créer un répertoire projects et un répertoire pour le projet “Hello, world!” à l’intérieur de ce répertoire projects.
Sous GNU/Linux, MacOS et PowerShell sous Windows, écrivez ceci :
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
Avec CMD sous Windows, écrivez ceci :
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Les bases d’un programme Rust
Ensuite, créez un nouveau fichier source et appelez-le main.rs. Les fichiers Rust se terminent toujours par l’extension .rs. Si vous utilisez plusieurs mots dans votre nom de fichier, la convention est d’utiliser un tiret bas (_) pour les séparer. Par exemple, vous devriez utiliser hello_world.rs au lieu de helloworld.rs.
Maintenant, ouvrez le fichier main.rs que vous venez de créer et entrez le code de l’encart 1-1.
fn main() {
println!("Hello, world!");
}Hello, world!Enregistrez le fichier et retournez dans votre terminal dans le répertoire ~/projects/hello_world. Sur Linux ou macOS, écrivez les commandes suivantes pour compiler et exécuter le fichier :
$ rustc main.rs
$ ./main
Hello, world!
Sur Windows, écrivez la commande .\main.exe à la place de ./main :
> rustc main.rs
> .\main
Hello, world!
Peu importe votre système d’exploitation, la chaîne de caractères Hello, world! devrait s’écrire dans votre terminal. Si cela ne s’affiche pas, référez-vous à la partie “dépannage” du chapitre d’installation pour vous aider.
Si Hello, world! s’affiche, félicitations ! Vous avez officiellement écrit un programme Rust. Cela fait de vous un développeur Rust — bienvenue !
Anatomie d’un programme Rust
Regardons en détail ce qui s’est passé dans votre programme “Hello, world!”. Voici le premier morceau du puzzle :
fn main() {
}Ces lignes définissent une fonction dans Rust. La fonction main est spéciale : c’est toujours le premier code qui est exécuté dans tous les programmes en Rust. Ici, la première ligne déclare une fonction qui s’appelle main, qui n’a pas de paramètre et qui ne retourne aucune valeur. S’il y avait des paramètres, ils seraient placés entre les parenthèses (()).
Le corps de la fonction est placé entre accolades {}. Rust a besoin d’avoir ces accolades autour du corps de chaque fonction. C’est une bonne pratique d’insérer l’accolade ouvrante sur la même ligne que la déclaration de la fonction, en ajoutant une espace entre les deux.
Note : si vous souhaitez formater le code de tous vos projets Rust de manière standardisée, vous pouvez utiliser un outil de formatage automatique tel que rustfmt (pour en savoir plus sur rustfmt, voir l’annexe D). L’équipe de Rust a intégré cet outil dans la distribution standard de Rust, comme pour rustc par exemple, donc il est probablement déjà installé sur votre ordinateur ! Consultez la documentation en ligne pour en savoir plus.
Le corps de la fonction main contient le code suivant :
#![allow(unused)]
fn main() {
println!("Hello, world!");
}Cette ligne fait tout le travail dans ce petit programme : il écrit le texte à l’écran. Il y a trois détails importants à noter ici.
Premièmement, println! fait appel à une macro Rust. S’il avait appelé une fonction à la place, cela aurait été écrit println (sans le !). Nous aborderons les macros Rust plus en détail dans le chapitre 20. Pour l’instant, vous avez juste à savoir qu’utiliser un ! signifie que vous utilisez une macro plutôt qu’une fonction classique. Les macros ne suivent pas toujours les mêmes règles que les fonctions.
Deuxièmement, vous voyez la chaîne de caractères "Hello, world!". Nous envoyons cette chaîne en argument à println! et cette chaîne est affichée à l’écran.
Troisièmement, nous terminons la ligne avec un point-virgule (;), qui indique que cette expression est terminée et que la suivante est prête à commencer. La plupart des lignes de Rust se terminent avec un point-virgule.
Compilation et exécution
Vous venez de lancer un nouveau programme fraîchement créé, donc penchons-nous sur chaque étape du processus.
Avant de lancer un programme Rust, vous devez le compiler en utilisant le compilateur Rust en entrant la commande rustc et en lui passant le nom de votre fichier source, comme ceci :
$ rustc main.rs
Si vous avez de l’expérience en C ou en C++, vous observerez des similarités avec gcc ou clang. Après avoir compilé avec succès, Rust produit un binaire exécutable.
Avec Linux, macOS et PowerShell sous Windows, vous pouvez voir l’exécutable en utilisant la commande ls dans votre terminal :
$ ls
main main.rs
Avec Linux et macOS, vous devriez voir deux fichiers. Avec PowerShell sous Windows, vous devriez voir les trois mêmes fichiers que vous verriez en utilisant CMD. Avec CMD sous Windows, vous devez saisir la commande suivante :
> dir /B %= l'option /B demande à n'afficher que les noms de fichiers =%
main.exe
main.pdb
main.rs
Ceci affiche le fichier de code source avec l’extension .rs, le fichier exécutable (main.exe sous Windows, mais main sur toutes les autres plateformes) et, quand on utilise Windows, un fichier qui contient des informations de débogage avec l’extension .pdb. Dans ce répertoire, vous pouvez exécuter le fichier main ou main.exe comme ceci :
$ ./main # ou .\main.exe sous Windows
Si main.rs est votre programme “Hello, world!”, cette ligne affiche Hello, world! dans votre terminal.
Si vous connaissez un langage dynamique, comme Ruby, Python, ou JavaScript, vous n’avez peut-être pas l’habitude de compiler puis lancer votre programme dans des étapes séparées. Rust est un langage à compilation anticipée, ce qui veut dire que vous pouvez compiler le programme et le donner à quelqu’un d’autre, et il peut l’exécuter sans avoir Rust d’installé. Si vous donnez à quelqu’un un fichier .rb, .py ou .js, il a besoin d’avoir respectivement un interpréteur Ruby, Python, ou Javascript d’installé. Cependant, avec ces langages, vous n’avez besoin que d’une seule commande pour compiler et exécuter votre programme. Dans la conception d’un langage, tout est une question de compromis.
Compiler avec rustc peut suffire pour de petits programmes, mais au fur et à mesure que votre programme grandit, vous allez avoir besoin de régler plus d’options et faciliter le partage de votre code. À la page suivante, nous allons découvrir l’outil Cargo, qui va vous aider à écrire des programmes Rust à l’épreuve de la réalité.
Hello, Cargo!
Hello, Cargo!
Cargo est le système de compilation et de gestion de paquets de Rust. La plupart des Rustacés utilisent cet outil pour gérer les projets Rust, car Cargo s’occupe de nombreuses tâches pour vous, comme compiler votre code, télécharger les bibliothèques dont votre code dépend, et compiler ces bibliothèques. (On appelle dépendance une bibliothèque nécessaire pour votre code.)
Des programmes Rust très simples, comme le petit que nous avons écrit précédemment, n’ont pas de dépendance. Si nous avions compilé le projet “Hello, world!” avec Cargo, cela n’aurait fait appel qu’à la fonctionnalité de Cargo qui s’occupe de la compilation de votre code. Quand vous écrirez des programmes Rust plus complexes, vous ajouterez des dépendances, et si vous créez un projet en utilisant Cargo, l’ajout des dépendances sera plus facile à faire.
Comme la large majorité des projets Rust utilisent Cargo, la suite de ce livre va supposer que vous utilisez aussi Cargo. Cargo s’installe avec Rust si vous avez utilisé l’installateur officiel présenté dans la section “Installation”. Si vous avez installé Rust autrement, vérifiez que Cargo est installé en utilisant la commande suivante dans votre terminal :
$ cargo --version
Si vous voyez un numéro de version, c’est qu’il est installé ! Si vous voyez une erreur comme Commande non trouvée (ou command not found), alors consultez la documentation de votre méthode d’installation pour savoir comment installer séparément Cargo.
Créer un projet avec Cargo
Créons un nouveau projet en utilisant Cargo et analysons les différences avec notre projet initial “Hello, world!”. Retournez dans votre répertoire projects (ou là où vous avez décidé d’enregistrer votre code). Ensuite, sur n’importe quel système d’exploitation, lancez les commandes suivantes :
$ cargo new hello_cargo
$ cd hello_cargo
La première commande crée un nouveau répertoire et projet appelés hello_cargo. Nous avons appelé notre projet hello_cargo, et Cargo crée ses fichiers dans un répertoire avec le même nom.
Rendez-vous dans le répertoire hello_cargo et afficher la liste des fichiers. Vous constaterez que Cargo a généré deux fichiers et un répertoire pour nous : un fichier Cargo.toml et un répertoire src avec un fichier main.rs à l’intérieur.
Il a aussi créé un nouveau dépôt Git ainsi qu’un fichier .gitignore. Les fichiers de Git ne seront pas générés si vous lancez cargo new au sein d’un dépôt Git ; vous pouvez désactiver ce comportement temporairement en utilisant cargo new --vcs=git.
Note : Git est un système de gestion de versions très répandu. Vous pouvez changer cargo new pour utiliser un autre système de gestion de versions ou ne pas en utiliser du tout en écrivant le drapeau --vcs. Lancez cargo new --help pour en savoir plus sur les options disponibles.
Ouvrez Cargo.toml dans votre éditeur de texte favori. Son contenu devrait être similaire au code dans l’encart 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
cargo newCe fichier est au format TOML (Tom’s Obvious, Minimal Language), qui est le format de configuration de Cargo.
La première ligne, [package], est un en-tête de section qui indique que les instructions suivantes configurent un paquet. Au fur et à mesure que nous ajouterons plus de détails à ce fichier, nous ajouterons des sections supplémentaires.
Les trois lignes suivantes définissent les informations de configuration dont Cargo a besoin pour compiler votre programme : le nom, la version, et l’édition de Rust à utiliser. Nous aborderons la clé edition dans l’annexe E.
La dernière ligne, [dependencies], est le début d’une section qui vous permet de lister les dépendances de votre projet. Dans Rust, les paquets de code sont désignés sous le nom de crates. Nous n’allons pas utiliser de crate pour ce projet, mais nous le ferons pour le premier projet au chapitre 2 ; nous utiliserons alors cette section à ce moment-là.
Maintenant, ouvrez src/main.rs et jetez-y un coup d’œil :
Fichier : src/main.rs
fn main() {
println!("Hello, world!");
}Cargo a généré un programme “Hello, world!” pour vous, exactement comme celui que nous avons écrit dans l’encart 1-1 ! Pour le moment, les seules différences entre notre projet précédent et le projet que Cargo a généré sont que Cargo a placé le code dans le répertoire src, et que nous avons un fichier de configuration Cargo.toml à la racine du répertoire projet.
Cargo prévoit de stocker vos fichiers sources dans le répertoire src. Le répertoire parent est là uniquement pour les fichiers README, pour les informations à propos de la licence, pour les fichiers de configuration et tout ce qui n’est pas directement relié à votre code. Utiliser Cargo vous aide à structurer vos projets. Il y a un endroit pour tout, et tout est à sa place.
Si vous commencez un projet sans utiliser Cargo, comme nous l’avons fait avec le projet “Hello, world!”, vous pouvez le transformer en projet qui utilise Cargo. Déplacez le code de votre projet dans un répertoire src et créez un fichier Cargo.toml adéquat. Pour créer aisément ce fichier Cargo.toml, vous pouvez lancer cargo init, qui le créera automatiquement.
Compiler et exécuter un projet Cargo
Maintenant, regardons ce qu’il y a de différent quand nous compilons et exécutons le programme “Hello, world!” avec Cargo ! À l’intérieur de votre répertoire hello_cargo, compilez votre projet en utilisant la commande suivante :
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Cette commande crée un fichier exécutable dans target/debug/hello_cargo (ou target\debug\hello_cargo.exe sous Windows) plutôt que de le déposer dans votre répertoire courant. Étant donné que la compilation par défaut est une compilation de débogage, Cargo place le binaire dans un répertoire nommé debug. Vous pouvez lancer l’exécutable avec cette commande :
$ ./target/debug/hello_cargo # ou .\target\debug\hello_cargo.exe sous Windows
Hello, world!
Si tout s’est bien passé, Hello, world! devrait s’afficher dans le terminal. Lancer cargo build pour la première fois devrait aussi mener Cargo à créer un nouveau fichier à la racine du répertoire projet : Cargo.lock. Ce fichier garde une trace des versions exactes des dépendances de votre projet. Ce projet n’a pas de dépendance, donc le fichier est un peu vide. Vous n’aurez jamais besoin de changer ce fichier manuellement ; Cargo va gérer son contenu pour vous.
Nous venons de compiler un projet avec cargo build avant de l’exécuter avec ./target/debug/hello_cargo, mais nous pouvons aussi utiliser cargo run pour compiler le code et ensuite lancer l’exécutable dans une seule et même commande :
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Il est plus pratique d’utiliser cargo run que d’avoir à se souvenir d’exécuter cargo build et d’ensuite utiliser le chemin complet vers l’exécutable ; c’est pourquoi la plupart des développeurs utilisent cargo run.
Notez que cette fois-ci, nous ne voyons pas de messages indiquant que Cargo a compilé hello_cargo. Cargo a détecté que les fichiers n’avaient pas changé, donc il n’a pas recompilé, il a juste exécuté le binaire. Si vous aviez modifié votre code source, Cargo aurait recompilé le projet avant de le lancer, et vous auriez eu les messages suivants :
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo fournit aussi une commande appelée cargo check. Elle vérifie rapidement votre code pour s’assurer qu’il est compilable, mais ne produit pas d’exécutable :
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Dans quel cas n’aurions-nous pas besoin d’un exécutable ? Parfois, cargo check est bien plus rapide que cargo build, car il saute l’étape de création de l’exécutable. Si vous vérifiez votre travail continuellement pendant que vous écrivez votre code, utiliser cargo check accélèrera le processus de vous informer que votre projet continue à pouvoir se compiler correctement ! C’est pourquoi de nombreux Rustacés utilisent périodiquement cargo check quand ils écrivent leur programme afin de s’assurer qu’il compile. Ensuite, ils lancent cargo build quand ils sont prêts à utiliser l’exécutable.
Récapitulons ce que nous avons appris sur Cargo :
- Nous pouvons créer un projet en utilisant
cargo new. - Nous pouvons compiler un projet en utilisant
cargo build. - Nous pouvons compiler puis exécuter un projet en une seule fois en utilisant
cargo run. - Nous pouvons compiler un projet sans produire de binaire afin de vérifier l’existence d’erreurs en utilisant
cargo check. - Au lieu d’enregistrer le résultat de la compilation dans le même répertoire que votre code, Cargo l’enregistre dans le répertoire target/debug.
Un autre avantage d’utiliser Cargo est que les commandes sont les mêmes peu importe le système d’exploitation que vous utilisez. Donc à partir de maintenant, nous n’allons plus faire d’opérations spécifiques à Linux et macOS par rapport à Windows.
Compiler pour diffuser
Quand votre projet est finalement prêt à être diffusé, vous pouvez utiliser cargo build --release pour le compiler en l’optimisant. Cette commande va créer un exécutable dans target/release au lieu de target/debug. Ces optimisations rendent votre code Rust plus rapide à exécuter, mais l’utiliser rallonge le temps de compilation de votre programme. C’est pourquoi il y a deux différents profils : un pour le développement, quand vous voulez recompiler rapidement et souvent, et un autre pour compiler le programme final qui sera livré à un utilisateur, qui n’aura pas besoin d’être recompilé à plusieurs reprises et qui s’exécutera aussi vite que possible. Si vous évaluez le temps d’exécution de votre code, assurez-vous de lancer cargo build --release et d’utiliser l’exécutable dans target/release pour vos bancs de test.
Tirer parti des conventions de Cargo
Pour des projets simples, Cargo n’apporte pas grand-chose par rapport à rustc, mais il vous montrera son intérêt au fur et à mesure que vos programmes deviendront plus complexes. Avec des programmes qui évoluent avec des fichiers multiples ou demandant une dépendance, il est plus facile de laisser Cargo prendre en charge la coordination de la compilation.
Même si le projet hello_cargo est simple, il utilise maintenant une grande partie de l’outillage que vous rencontrerez dans votre carrière avec Rust. En effet, pour travailler sur n’importe quel projet Rust existant, vous n’avez qu’à saisir les commandes suivantes pour télécharger le code avec Git, vous déplacer dans le répertoire projet et compiler :
$ git clone example.org/projet_quelconque
$ cd projet_quelconque
$ cargo build
Pour plus d’informations à propos de Cargo, vous pouvez consulter sa documentation.
Résumé
Vous êtes déjà bien lancé dans votre périple avec Rust ! Dans ce chapitre, vous avez appris comment :
- Installer la dernière version stable de Rust en utilisant
rustup. - Mettre à jour Rust vers une nouvelle version.
- Ouvrir la documentation installée en local.
- Écrire et exécuter un programme “Hello, world!” en utilisant directement
rustc. - Créer et exécuter un nouveau projet en utilisant les conventions de Cargo.
C’est le moment idéal pour construire un programme plus ambitieux pour s’habituer à lire et écrire du code Rust. Donc, au chapitre 2, nous allons écrire un programme de jeu de devinettes. Si vous préférez commencer par apprendre comment les principes de programmation de base fonctionnent avec Rust, rendez-vous au chapitre 3, puis revenez au chapitre 2.
Programmer le jeu du plus ou du moins
Entrons dans le vif du sujet en travaillant ensemble sur un projet concret ! Ce chapitre présente quelques concepts couramment utilisés en Rust en vous montrant comment les utiliser dans un véritable programme. Nous aborderons notamment les instructions let et match, les méthodes et fonctions associées, l’utilisation des crates, et bien plus encore ! Dans les chapitres suivants, nous approfondirons ces notions. Dans ce chapitre, vous n’allez exercer que les principes de base.
Nous allons coder un programme fréquemment réalisé par les débutants en programmation : le jeu du plus ou du moins. Le principe de ce jeu est le suivant : le programme va tirer au sort un nombre entre 1 et 100. Il invitera ensuite le joueur à saisir un nombre qu’il pense deviner. Après la saisie, le programme indiquera si le nombre saisi par le joueur est trop grand ou trop petit. Si le nombre saisi est le bon, le jeu affichera un message de félicitations et se fermera.
Mise en place d’un nouveau projet
Pour créer un nouveau projet, rendez-vous dans le répertoire projects que vous avez créé au chapitre 1 et utilisez Cargo pour créer votre projet, comme ceci :
$ cargo new jeu_du_plus_ou_du_moins
$ cd jeu_du_plus_ou_du_moins
La première commande, cargo new, prend comme premier argument le nom de notre projet (jeu_du_plus_ou_du_moins). La seconde commande nous déplace dans le répertoire de notre nouveau projet créé par Cargo.
Regardons le fichier Cargo.toml qui a été généré :
Fichier : Cargo.toml
[package]
name = "jeu_du_plus_ou_du_moins"
version = "0.1.0"
edition = "2024"
[dependencies]
Comme vous l’avez expérimenté dans le chapitre 1, cargo new génère un programme “Hello, world!” pour vous. Ouvrez le fichier src/main.rs :
Fichier : src/main.rs
fn main() {
println!("Hello, world!");
}Maintenant, lançons la compilation de ce programme “Hello, world!” et son exécution en une seule commande avec cargo run :
$ cargo run
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/jeu_du_plus_ou_du_moins`
Hello, world!
Cette commande run est très pratique lorsqu’on souhaite itérer rapidement sur un projet, comme c’est le cas ici, pour tester rapidement chaque modification avant de passer à la suivante.
Ouvrez à nouveau le fichier src/main.rs. C’est dans ce fichier que nous écrirons la totalité de notre code.
Traitement d’un nombre saisi
La première partie du programme consiste à demander au joueur de saisir du texte, à traiter cette saisie, et à vérifier que la saisie correspond au format attendu. Commençons par permettre au joueur de saisir son nombre. Entrez le code de l’encart 2-1 dans le fichier src/main.rs.
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Ce code contient beaucoup d’informations, nous allons donc l’analyser petit à petit. Pour obtenir la saisie utilisateur et ensuite l’afficher, nous avons besoin d’importer la bibliothèque d’entrée/sortie io (initiales de input/output) afin de pouvoir l’utiliser. La bibliothèque io provient de la bibliothèque standard, connue sous le nom de std :
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Par défaut, Rust importe dans la portée de tous les programmes un ensemble de fonctionnalités définies dans la bibliothèque standard. Cela s’appelle l’étape préliminaire (the prelude), et vous pouvez en savoir plus dans sa documentation de la bibliothèque standard.
Si vous voulez utiliser un type qui ne s’y trouve pas, vous devrez l’importer explicitement avec l’instruction use. L’utilisation de la bibliothèque std::io vous apporte de nombreuses fonctionnalités utiles, comme ici la possibilité de récupérer une saisie utilisateur.
Comme vous l’avez vu au chapitre 1, la fonction main est le point d’entrée du programme :
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Le mot clé fn déclare une nouvelle fonction ; les parenthèses () indiquent que cette fonction n’accepte aucun paramètre ; et l’accolade ouvrante { marque le début du corps de la fonction.
Comme vous l’avez également appris au chapitre 1, println! est une macro qui affiche une chaîne de caractères à l’écran :
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Ce code affiche du texte qui indique le titre de notre jeu, et un autre qui demande au joueur d’entrer un nombre.
Enregistrer des données dans des variables
Ensuite, on crée une variable pour stocker la saisie de l’utilisateur, comme ceci :
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Le programme commence à devenir intéressant ! Il se passe beaucoup de choses dans cette petite ligne. Nous utilisons l’instruction let pour créer la variable. Voici un autre exemple :
let pommes = 5;Cette ligne permet de créer une nouvelle variable nommée pommes et à lui assigner la valeur 5. Par défaut en Rust, les variables sont immuables, ce qui implique qu’à partir du moment où l’on donne une valeur à une variable, cette valeur ne changera pas. Nous aborderons plus en détail cette notion dans la section “Variables et Mutabilité” au chapitre 3. Pour rendre une variable mutable (c’est-à-dire modifiable), nous ajoutons mut devant le nom de la variable :
let pommes = 5; // immuable
let mut bananes = 5; // mutable, modifiableRemarque : La syntaxe // permet de commencer un commentaire qui s’étend jusqu’à la fin de la ligne. Rust ignore tout ce qu’il y a dans un commentaire. Nous verrons plus en détail les commentaires dans le chapitre 3.
Lorsque vous revenez sur le jeu du plus ou du moins, vous comprenez donc maintenant que la ligne let mut supposition permet de créer une variable mutable nommée supposition. Le signe égal (=) indique à Rust que nous voulons désormais lier quelquechose à la variable. À la droite du signe égal, nous avons la valeur liée à supposition, qui est ici le résultat de l’utilisation de String::new, qui est une fonction qui retourne une nouvelle instance de String. String est un type de chaîne de caractères fourni par la bibliothèque standard, qui est une portion de texte encodée en UTF-8 et dont la longueur peut augmenter.
La syntaxe :: dans String::new() indique que new est une fonction associée au type String. Une fonction associée est une fonction qui est implémentée sur un type, ici String. Cette fonction new crée une nouvelle chaîne de caractères vide, une nouvelle String. Vous trouverez fréquemment une fonction new sur d’autres types car c’est un nom souvent donné à une fonction qui crée une nouvelle valeur ou instance d’un type.
En définitif, la ligne let mut supposition = String::new(); crée une nouvelle variable mutable qui contient une nouvelle chaîne de caractères vide, une instance de String. Ouf !
Recueillir la saisie utilisateur
Rappelez-vous que nous avons importé les fonctionnalités d’entrée/sortie de la bibliothèque standard avec use std::io; à la première ligne de notre programme. Nous allons maintenant appeler la fonction stdin du module io, qui va nous permettre de traiter la saisie utilisateur :
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Si nous n’avions pas importé le module io avec use std::io au début du programme, nous aurions toujours pu utiliser la fonction en écrivant l’appel à la fonction de cette manière : std::io::stdin. La fonction stdin retourne une instance de std::io::Stdin, qui est un type qui représente une référence abstraite (handle) vers l’entrée standard du terminal dans lequel vous avez lancé le programme.
Ensuite, la ligne .read_line(&mut supposition) appelle la méthode read_line sur l’entrée standard afin d’obtenir la saisie utilisateur. Nous passons aussi &mut supposition en argument de read_line pour lui indiquer dans quelle chaîne de caractère il faut stocker la saisie utilisateur. Le but final de read_line est de récupérer tout ce que l’utilisateur écrit dans l’entrée standard et de l’ajouter à la fin d’une chaîne de caractères (sans écraser son contenu) ; c’est pourquoi nous passons cette chaîne de caractères en argument. Cet argument doit être mutable pour que read_line puisse en modifier le contenu.
Le & indique que cet argument est une référence, ce qui permet de laisser plusieurs morceaux de votre code accéder à une même donnée sans avoir besoin de copier ces données dans la mémoire plusieurs fois. Les références sont une fonctionnalité complexe, et un des avantages majeurs de Rust est qu’il rend sûr et simple l’utilisation des références. Il n’est pas nécessaire de trop s’apesantir sur les références pour terminer ce programme. Pour l’instant, tout ce que vous devez savoir est que, comme les variables, les références sont immuables par défaut. D’où la nécessité d’écrire &mut supposition au lieu de &supposition pour la rendre mutable. (Le chapitre 4 expliquera plus en détail les références.)
Gérer les erreurs potentielles avec Result
Nous avons encore du travail sur cette ligne de code. Nous allons discuter d’une troisième ligne de texte, mais notez bien qu’elle ne fait partie que d’une seule ligne de code logique. La prochaine partie rajoute cette méthode :
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Nous aurions pu écrire ce code de cette manière :
io::stdin().read_line(&mut guess).expect("Failed to read line");Cependant, une longue ligne de code n’est pas toujours facile à lire, c’est donc une bonne pratique de la diviser. Il est parfois utile d’ajouter une nouvelle ligne et des espaces afin de désagréger les longues lignes lorsque vous appelerez une méthode, comme ici avec la syntaxe .nom_de_la_methode(). Maintenant, voyons à quoi sert cette ligne.
Comme expliqué précédemment, read_line stocke tout ce que l’utilisateur a saisi dans la variable chaîne qu’on lui passe en argument , mais cette fonction retourne aussi une valeur Result. Result est une énumération, souvent appelée enum, qui est un type pouvant prendre plusieurs états possibles. Chaque état est appelé une variante.
Le chapitre 6 explorera les énumérations plus en détail. La raison d’être du type Result est de coder des informations pour la gestion des erreurs.
Les variantes de Result sont Ok et Err. La variante Ok signifie que l’opération a fonctionné, et elle contient la valeur générée avec succès. La variante Err signifie que l’opération a échoué, et elle contient les informations décrivant comment ou pourquoi l’opération a échoué.
Les valeurs du type Result, comme pour tous les types, ont des méthodes qui leur sont associées. Par exemple, une instance de Result a une méthode expect que vous pouvez utiliser. Si cette instance de Result a pour valeur la variante Err, l’appel à expect fera planter le programme et affichera le message que vous avez passé en argument de expect. Si l’appel à read_line retourne une variante Err, ce sera probablement dû à une erreur du système d’exploitation. Si en revanche read_line a pour valeur la variante Ok, expect récupèrera le contenu du Ok, qui est le résultat de l’opération, et vous le retournera afin que vous puissiez l’utiliser. Dans notre exemple, ce résultat est le nombre d’octets de la saisie utilisateur.
Si on n’appelle pas expect, le programme compilera, mais avec un avertissement :
$ cargo build
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut supposition);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut supposition);
| +++++++
warning: `jeu_du_plus_ou_du_moins` (bin "jeu_du_plus_ou_du_moins") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust nous prévient que l’on ne fait rien du Result que nous fournit read_line, et que par conséquent notre programme ne gère pas une erreur potentielle.
La meilleure façon de masquer cet avertissement est de réellement écrire le code permettant de gérer l’erreur, mais dans notre cas on a seulement besoin de faire planter le programme si un problème survient, on utilise donc expect. Nous verrons dans le chapitre 9 comment gérer correctement les erreurs.
Afficher des valeurs grâce aux espaces réservés de println!
Mis à part l’accolade fermante, il ne nous reste plus qu’une seule ligne à étudier dans le code que nous avons pour l’instant :
use std::io;
fn main() {
println!("Devinez le nombre !");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Cette ligne affiche la chaîne de caractères qui contient maintenant ce que l’utilisateur a saisi. La paire d’accolades {} représente un espace réservé : imaginez qu’il s’agit de pinces de crabes qui gardent la place d’une valeur. Lorsque vous affichez la valeur d’une variable, le nom de la variable peut être placé entre accolades. Pour afficher le résultat de l’évaluation d’une expression, placez des accolades vides dans la chaîne de format, puis faites suivre la chaîne de format d’une liste d’expressions séparées par des virgules, expressions dont le résultat sera affiché dans chaque espace réservé d’accolades vides, dans le même ordre. Pour afficher une variable et le résultat d’une expression en appelant println! une seule fois, on ferait comme ceci :
#![allow(unused)]
fn main() {
let x = 5;
let y = 10;
println!("x = {x} et y + 2 = {}", y + 2);
}Ce code afficherait x = 5 et y + 2 = 12.
Test de la première partie
Pour tester notre début de programme, lançons-le à l’aide de la commande cargo run :
$ cargo run
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/jeu_du_plus_ou_du_moins`
Devinez le nombre !
Veuillez entrer un nombre.
6
Votre nombre : 6
À ce stade, la première partie de notre programme est terminée : nous avons récupéré la saisie du clavier et nous l’affichons à l’écran.
Générer le nombre secret
Maintenant, il nous faut générer un nombre secret que notre joueur va devoir deviner. Ce nombre devra être différent à chaque fois pour qu’on puisse s’amuser à y jouer plusieurs fois. Nous allons tirer au sort un nombre compris entre 1 et 100 pour que le jeu ne soit pas trop difficile. Rust n’embarque pas pour l’instant de fonctionnalité de génération de nombres aléatoires dans sa bibliothèque standard. Cependant, l’équipe de Rust propose une crate rand qui offre la possibilité de le faire.
Étendre les fonctionnalités de Rust avec une crate
Souvenez-vous, une crate est un ensemble de fichiers de code source Rust. Le projet sur lequel nous travaillons est une crate binaire, qui est un programme exécutable. La crate rand est une crate de bibliothèque, qui contient du code qui peut être utilisé dans d’autres programmes, et qui ne peut pas être exécuté tout seul.
La coordination des crates externes est un domaine dans lequel Cargo excelle. Avant d’écrire le code qui utilisera rand, il nous faut éditer le fichier Cargo.toml pour y spécifier rand en tant que dépendance. Ouvrez donc maintenant ce fichier et ajoutez la ligne suivante à la fin, en dessous de l’en-tête de section [dependencies] que Cargo a créé pour vous. Assurez-vous de spécifier rand exactement comme dans le bout de code suivant, avec ce numéro de version, ou sinon les exemples de code de ce tutoriel pourraient ne pas fonctionner:
Fichier : Cargo.toml
[dependencies]
rand = "0.8.5"
Dans le fichier Cargo.toml, tout ce qui suit une en-tête fait partie de cette section, et ce jusqu’à ce qu’une autre section débute. Dans [dependencies], vous indiquez à Cargo de quelles crates externes votre projet dépend, et de quelle version de ces crates vous avez besoin. Dans notre cas, on ajoute comme dépendance la crate rand avec la version sémantique 0.8.5. Cargo arrive à interpréter le versionnage sémantique (aussi appelé SemVer), qui est une convention d’écriture de numéros de version. En réalité, 0.8.5 est une abréviation pour ^0.8.5, ce qui signifie “toute version ultérieure ou égale à 0.8.5 mais strictement antérieure à 0.9.0”.
Cargo considère que ces versions ont des API publiques compatibles avec la version 0.8.5, et cette indication garantit que vous obtiendrez la dernière version de correction qui compilera encore avec le code de ce chapitre. Il n’est pas garanti que les versions 0.9.0 et ultérieures aient la même API que celle utilisée dans les exemples suivants.
Maintenant, sans apporter le moindre changement au code, lançons une compilation du projet, comme dans l’encart 2-2 :
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
cargo build after adding the rand crate as a dependencyIl est possible que vous ne voyiez pas exactement les mêmes numéros de version, (mais ils seront compatibles avec votre code, grâce au versionnage sémantique !) et différentes lignes (en fonction de votre système d’exploitation), et les lignes ne seront pas forcément affichées dans le même ordre.
Lorsque nous ajoutons une dépendance externe, Cargo récupère les dernières versions de tout ce dont cette dépendance a besoin depuis le registre, qui est une copie des données de Crates.io. Crates.io est là où les développeurs de l’écosystème Rust publient leurs projets open source afin de les rendre disponibles aux autres.
Une fois le registre mis à jour, Cargo lit la section [dependencies] et se charge de télécharger les crates qui y sont listées que vous n’avez pas encore téléchargées. Dans notre cas, bien que nous n’ayons spécifié qu’une seule dépendance, rand, Cargo a aussi téléchargé d’autres crates dont dépend rand pour fonctionner. Une fois le téléchargement terminé des crates, Rust les compile, puis compile notre projet avec les dépendances disponibles.
Si vous relancez tout de suite cargo build sans changer quoi que ce soit, vous n’obtiendrez rien d’autre que la ligne Finished. Cargo sait qu’il a déjà téléchargé et compilé les dépendances, et que vous n’avez rien changé dans votre fichier Cargo.toml. Cargo sait aussi que vous n’avez rien changé dans votre code, donc il ne le recompile pas non plus. Étant donné qu’il n’a rien à faire, Cargo se termine tout simplement.
Si vous ouvrez le fichier src/main.rs, faites un changement très simple, enregistrez le fichier, et relancez la compilation, vous verrez s’afficher uniquement deux lignes :
$ cargo build
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Ces lignes nous informent que Cargo a recompilé uniquement à cause de notre petit changement dans le fichier src/main.rs. Les dépendances n’ayant pas changé, Cargo sait qu’il peut simplement réutiliser ce qu’il a déjà téléchargé et compilé précédemment.
Assurer la reproductibilité des compilations
Cargo embarque une fonctionnalité qui garantit que vous pouvez recompiler le même artéfact à chaque fois que vous ou quelqu’un d’autre compile votre code : Cargo va utiliser uniquement les versions de dépendances que vous avez utilisées jusqu’à ce que vous indiquiez le contraire. Par exemple, imaginons que la semaine prochaine, la version 0.8.6 de la crate rand est publiée, et qu’elle apporte une correction importante, mais aussi qu’elle produit une régression qui va casser votre code. Pour éviter cela, Rust crée le fichier Cargo.lock la première fois que vous utilisez cargo build, donc nous l’avons désormais dans le répertoire jeu_du_plus_ou_du_moins.
Quand vous compilez un projet pour la première fois, Cargo détermine toutes les versions de dépendances qui correspondent à vos critères et les écrit dans le fichier Cargo.lock. Quand vous recompilerez votre projet plus tard, Cargo verra que le fichier Cargo.lock existe et utilisera les versions précisées à l’intérieur au lieu de recommencer à déterminer toutes les versions demandées. Ceci vous permet d’avoir automatiquement des compilations reproductibles. En d’autres termes, votre projet va rester sur la version 0.8.5 jusqu’à ce que vous le mettiez à jour explicitement, grâce au fichier Cargo.lock. Du fait que le fichier Cargo.lock est important pour la reproductibilité des compilations, il est souvent enregistré dans le système de contrôle de code source, avec le reste du code de votre projet.
Mettre à jour une crate vers sa nouvelle version
Lorsque vous souhaitez réellement mettre à jour une crate, Cargo vous fournit la commande update, qui va ignorer le fichier Cargo.lock et va rechercher toutes les versions qui correspondent à vos critères dans Cargo.toml. Cargo va ensuite écrire ces versions dans le fichier Cargo.lock. Sinon par défaut, Cargo va rechercher uniquement les versions plus grandes que 0.8.5 et inférieures à 0.9.0. Si la crate rand a été publiée en deux nouvelles versions 0.8.6 et 0.9.0, alors vous verrez ceci si vous lancez cargo update :
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.999.0)
Cargo ignore la version 0.999.0. À partir de ce moment, vous pouvez aussi constater un changement dans le fichier Cargo.lock indiquant que la version de la crate rand que vous utilisez maintenant est la 0.8.6. Pour utiliser rand en version 0.999.0 ou toute autre version dans la série des 0.999._x_, il vous faut mettre à jour le fichier Cargo.toml comme ceci (ne faites pas réellement ce changement, car les exemples suivants supposent que vous utilisez rand 0.8) :
[dependencies]
rand = "0.999.0"
La prochaine fois que vous lancerez cargo build, Cargo mettra à jour son registre de crates disponibles et réévaluera vos exigences vis-à-vis de rand selon la nouvelle version que vous avez spécifiée.
Il y a encore plus à dire à propos de Cargo et de son écosystème, que nous aborderons au chapitre 14, mais pour l’instant, c’est tout ce qu’il vous faut savoir. Cargo facilite la réutilisation des bibliothèques, pour que les Rustacés soient capables d’écrire des petits projets issus d’un assemblage d’un certain nombre de paquets.
Générer un nombre aléatoire
Commençons désormais à utiliser rand pour générer un nombre à deviner. La prochaine étape est de modifier src/main.rs comme dans l’encart 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}D’abord, nous avons ajouté la ligne use rand::Rng;. Le trait Rng définit les méthodes implémentées par les générateurs de nombres aléatoires, et ce trait doit être accessible à notre code pour qu’on puisse utiliser ces méthodes. Le chapitre 10 expliquera plus en détail les traits.
Ensuite, nous ajoutons deux lignes au milieu. À la première ligne, nous appelons la fonction rand::thread_rng qui nous fournit le générateur de nombres aléatoires particulier que nous allons utiliser : il est propre au fil d’exécution courant et généré par le système d’exploitation. Ensuite, nous appelons la méthode gen_range sur le générateur de nombres aléatoires. Cette méthode est définie par le trait Rng que nous avons importé avec l’instruction use rand::Rng;. La méthode gen_range prend une expression d’intervalle en paramètre et génère un nombre aléatoire au sein de l’intervalle. Le genre d’expression d’intervalle utilisé ici est de la forme début..=fin et inclut les bornes inférieure et supérieure, nous avons donc besoin de préciser 1..=100 pour demander un nombre entre 1 et 100.
Remarque : vous ne pourrez pas deviner quels traits, méthodes et fonctions utiliser avec une crate, donc chaque crate a une documentation qui donne des indications sur son utilisation. Une autre fonctionnalité intéressante de Cargo est que vous pouvez utiliser la commande cargo doc --open, qui va construire localement la documentation intégrée par toutes vos dépendances et va l’ouvrir dans votre navigateur. Si vous vous intéressez à d’autres fonctionnalités de la crate rand, par exemple, vous pouvez lancer cargo doc --open et cliquer sur rand dans la barre latérale sur la gauche.
La seconde nouvelle ligne affiche le nombre secret. C’est pratique lors du développement pour pouvoir le tester, mais nous l’enlèverons dans la version finale. Ce n’est pas vraiment un jeu si le programme affiche la réponse dès qu’il démarre !
Essayez de lancer le programme plusieurs fois :
$ cargo run
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/jeu_du_plus_ou_du_moins`
Devinez le nombre !
Le nombre secret est : 7
Veuillez entrer un nombre.
4
Votre nombre : 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/jeu_du_plus_ou_du_moins`
Devinez le nombre !
Le nombre secret est : 83
Veuillez entrer un nombre.
5
Votre nombre : 5
Vous devriez obtenir des nombres aléatoires différents, et ils devraient être tous compris entre 1 et 100. Beau travail !
Comparer le nombre saisi au nombre secret
Maintenant que nous avons une saisie utilisateur et un nombre aléatoire, nous pouvons les comparer. Cette étape est écrite dans l’encart 2-4. Sachez toutefois que le code ne se compilera pas tout de suite, comme nous allons l’expliquer par la suite.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// -- partie masquée ici --
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => println!("Vous avez gagné !"),
}
}Premièrement, nous ajoutons une autre instruction use, qui importe std::cmp::Ordering à portée de notre code depuis la bibliothèque standard. Le type Ordering est une autre énumération et a les variantes Less (inférieur), Greater (supérieur) et Equal (égal). Ce sont les trois issues possibles lorsqu’on compare deux valeurs.
Ensuite, nous ajoutons cinq nouvelles lignes à la fin qui utilisent le type Ordering. La méthode cmp compare deux valeurs et peut être appelée sur tout ce qui peut être comparé. Elle prend en paramètre une référence de ce qu’on veut comparer : ici, nous voulons comparer supposition et nombre_secret. Ensuite, cela retourne une variante de l’énumération Ordering que nous avons importée avec l’instruction use. Nous utilisons une expression match pour décider quoi faire ensuite en fonction de quelle variante de Ordering a été retournée à l’appel de cmp avec supposition et nombre_secret.
Une expression match est composée de branches. Une branche est constituée d’un motif (pattern) avec lequel elle doit correspondre et du code qui sera exécuté si la valeur donnée au match correspond bien au motif de cette branche. Rust prend la valeur donnée à match et la compare au motif de chaque branche à tour de rôle. Les motifs et la structure de contrôle match sont des fonctionnalités puissantes de Rust : elles vous permettent de décrire une multitude de scénarios que votre code peut rencontrer, et elles s’assurent que vous les gérez toutes. Ces fonctionnalités seront expliquées plus en détail respectivement dans le chapitre 6 et le chapitre 19.
Voyons un exemple avec l’expression match que nous avons utilisée ici. Disons que l’utilisateur a saisi le nombre 50 et que le nombre secret généré aléatoirement a cette fois-ci comme valeur 38.
Quand le code compare 50 à 38, la méthode cmp va retourner Ordering::Greater, car 50 est plus grand que 38. L’expression match obtient la valeur Ordering::Greater et commence à vérifier le motif de chaque branche. Elle consulte le motif de la première branche, Ordering::Less et remarque que la valeur Ordering::Greater ne correspond pas au motif Ordering::Less ; elle ignore donc le code de cette branche et passe à la suivante. Le motif de la branche suivante est Ordering::Greater, qui correspond à Ordering::Greater ! Le code associé à cette branche va être exécuté et va afficher à l’écran C'est moins !. L’expression match se termine après la première correspondance, elle n’a donc pas besoin de consulter les autres branches de ce scénario.
Cependant, notre code dans l’encart 2-4 ne compile pas encore. Essayons de le faire :
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match supposition.cmp(&nombre_secret) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/cmp.rs:979:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `jeu_du_plus_ou_du_moins` (bin "jeu_du_plus_ou_du_moins") due to 1 previous error
Le message d’erreur nous indique que nous sommes dans un cas de types non compatibles (mismatched types). Rust a un système de types fort et statique. Cependant, il a aussi une fonctionnalité d’inférence de type. Quand nous avons écrit let mut supposition = String::new(), Rust a pu en déduire que supposition devait être une String et ne nous a pas demandé d’écrire le type. D’autre part, nombre_secret est d’un type de nombre. Quelques types de nombres de Rust peuvent avoir une valeur entre 1 et 100 : i32, un nombre entier encodé sur 32 bits ; u32, un nombre entier de 32 bits non signé (positif ou nul) ; i64, un nombre entier encodé sur 64 bits ; parmi tant d’autres. Rust utilise par défaut un i32, qui est le type de nombre_secret, à moins que vous précisiez quelque part une information de type qui amènerait Rust à inférer un type de nombre différent. La raison de cette erreur est que Rust ne peut pas comparer une chaîne de caractères à un nombre.
Au bout du compte, nous voulons convertir la String que le programme récupère de la saisie utilisateur en un nombre, pour qu’on puisse la comparer numériquement au nombre secret. Nous allons faire ceci en ajoutant cette ligne supplémentaire dans le corps de la fonction main :
Fichier : src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
println!("Veuillez entrer un nombre.");
// -- partie masquée ici --
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: u32 = supposition.trim().parse().expect("Veuillez entrer un nombre !");
println!("Votre nombre : {supposition}");
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => println!("Vous avez gagné !"),
}
}La nouvelle ligne est :
let supposition: u32 = supposition.trim().parse().expect("Veuillez entrer un nombre !");Nous créons une variable qui s’appelle supposition. Mais attendez, le programme n’a-t-il pas déjà une variable qui s’appelle supposition ? C’est le cas, mais heureusement Rust nous permet de masquer la valeur précédente de supposition avec une nouvelle. Le masquage (shadowing) nous permet de réutiliser le nom de variable supposition, plutôt que de nous forcer à créer deux variables distinctes, telles que supposition_str et supposition par exemple. Nous verrons cela plus en détails au chapitre 3, mais pour le moment cette fonctionnalité est souvent utilisée dans des situations où on veut convertir une valeur d’un type à un autre.
Nous lions cette nouvelle variable à l’expression supposition.trim().parse(). Le supposition dans l’expression se réfère à la variable supposition initiale qui contenait la saisie utilisateur en tant que chaîne de caractères. La méthode trim sur une instance de String va enlever les espaces et autres whitespaces au début et à la fin, ce que nous devons faire avant de pouvoir convertir la chaîne en un u32, qui ne peut être constitué que de chiffres. L’utilisateur doit appuyer sur entrée pour mettre fin à read_line et récupérer sa supposition, ce qui va rajouter un caractère de fin de ligne à la chaîne de caractères. Par exemple, si l’utilisateur écrit 5 et appuie sur entrée, supposition aura alors cette valeur : 5\n. Le \n représente une fin de ligne (à noter que sur Windows, appuyer sur entrée résulte en un retour chariot suivi d’un saut de ligne, \r\n). La méthode trim enlève \n et \r\n, il ne reste donc plus que 5.
La méthode parse des chaînes de caractères convertit une chaîne de caractères vers un autre type. Ici, elle est utilisée pour convertir d’une chaîne vers un nombre. Nous devons indiquer à Rust le type exact de nombre que nous voulons en utilisant let supposition: u32. Le deux-points (:) après supposition indique à Rust que nous voulons préciser le type de la variable. Rust embarque quelques types de nombres ; le u32 utilisé ici est un entier non signé sur 32 bits. C’est un bon choix par défaut pour un petit nombre positif. Vous découvrirez d’autres types de nombres dans le chapitre 3.
De plus, l’annotation u32 dans ce programme d’exemple et la comparaison avec nombre_secret permet à Rust d’en déduire que nombre_secret doit être lui aussi un u32. Donc maintenant, la comparaison se fera entre deux valeurs du même type !
La méthode parse va fonctionner uniquement sur des caractères qui peuvent être logiquement convertis en nombres et donc peut facilement mener à une erreur. Si par exemple, le texte contient A👍%, il ne sera pas possible de le convertir en nombre. Comme elle peut échouer, la méthode parse retourne un type Result, comme celui que la méthode read_line retourne (comme nous l’avons vu plus tôt dans “Gérer les erreurs potentielles avec Result”). Nous allons gérer ce Result de la même manière, avec à nouveau la méthode expect. Si parse retourne une variante Err de Result car elle ne peut pas créer un nombre à partir de la chaîne de caractères, l’appel à expect va faire planter le jeu et va afficher le message que nous lui avons passé en paramètre. Si parse arrive à convertir la chaîne de caractères en nombre, alors elle retournera la variante Ok de Result, et expect va retourner le nombre qu’il nous faut qui est stocké dans la variante Ok.
Exécutons ce programme, maintenant :
$ cargo run
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/jeu_du_plus_ou_du_moins`
Devinez le nombre !
Le nombre secret est : 58
Veuillez entrer un nombre.
76
Votre nombre : 76
C'est moins !
Très bien ! Même si des espaces ont été ajoutées avant la supposition, le programme a quand même compris que l’utilisateur a saisi 76. Lancez le programme plusieurs fois pour vérifier qu’il se comporte correctement avec différentes saisies : devinez le nombre correctement, saisissez un nombre qui est trop grand, et saisissez un nombre qui est trop petit.
La majeure partie du jeu fonctionne désormais, mais l’utilisateur ne peut faire qu’une seule supposition. Corrigeons cela en ajoutant une boucle !
Permettre plusieurs suppositions avec les boucles
Le mot-clé loop crée une boucle infinie. Nous allons ajouter une boucle pour donner aux utilisateurs plus de chances de deviner le nombre :
Fichier : src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
// -- partie masquée ici --
println!("Le nombre secret est : {nombre_secret}");
loop {
println!("Veuillez entrer un nombre.");
// -- partie masquée ici --
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: u32 = supposition.trim().parse().expect("Veuillez entrer un nombre !");
println!("Votre nombre : {supposition}");
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => println!("Vous avez gagné !"),
}
}
}Comme vous pouvez le remarquer, nous avons déplacé dans une boucle tout le code de l’invite à entrer le nombre. Assurez-vous d’indenter correctement les lignes dans la boucle avec quatre nouvelles espaces pour chacune, et lancez à nouveau le programme. Le programme va désormais demander un nombre à l’infini, ce qui est un nouveau problème. Il n’est pas possible pour l’utilisateur de l’arrêter !
L’utilisateur pourrait quand même interrompre le programme en utilisant le raccourci clavier ctrl-C. Mais il y a une autre façon d’échapper à ce monstre insatiable, comme nous l’avons abordé dans la partie “Comparer le nombre saisi au nombre secret” : si l’utilisateur saisit quelque chose qui n’est pas un nombre, le programme va planter. Nous pouvons procéder ainsi pour permettre à l’utilisateur de quitter, comme ci-dessous :
$ cargo run
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/jeu_du_plus_ou_du_moins`
Devinez le nombre !
Le nombre secret est : 59
Veuillez entrer un nombre.
45
Votre nombre : 45
C'est plus !
Veuillez entrer un nombre.
60
Votre nombre : 60
C'est moins !
Veuillez entrer un nombre.
59
Votre nombre : 59
Vous avez gagné !
Veuillez entrer un nombre.
quitter
thread 'main' panicked at src/main.rs:28:47:
Veuillez entrer un nombre !: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Taper quitter va bien fermer le jeu, mais comme vous pouvez le remarquer, toute autre saisie qui n’est pas un nombre le ferait aussi. Ce mécanisme laisse franchement à désirer ; nous voudrions que le jeu s’arrête aussi lorsque le bon nombre est deviné.
Arrêter le programme après avoir gagné
Faisons en sorte que le jeu s’arrête quand le joueur gagne en ajoutantl’instruction break :
Fichier : src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
loop {
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: u32 = supposition.trim().parse().expect("Veuillez entrer un nombre !");
println!("Votre nombre : {supposition}");
// -- partie masquée ici --
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => {
println!("Vous avez gagné !");
break;
}
}
}
}Ajouter la ligne break après Vous avez gagné ! fait sortir le programme de la boucle quand le joueur a correctement deviné le nombre secret. Et quitter la boucle veut aussi dire terminer le programme, car ici la boucle est la dernière partie de main.
Gérer les saisies invalides
Pour améliorer le comportement du jeu, plutôt que de faire planter le programme quand l’utilisateur saisit quelque chose qui n’est pas un nombre, faisons en sorte que le jeu ignore ce qui n’est pas un nombre afin que l’utilisateur puisse continuer à essayer de deviner. Nous pouvons faire ceci en modifiant la ligne où supposition est converti d’une String en un u32, comme dans l’encart 2-5 :
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
loop {
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
// -- partie masquée ici --
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: u32 = match supposition.trim().parse() {
Ok(nombre) => nombre,
Err(_) => continue,
};
println!("Votre nombre : {supposition}");
// -- partie masquée ici --
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => {
println!("Vous avez gagné !");
break;
}
}
}
}Nous remplaçons un appel à expect par une expression match pour passer d’une erreur qui fait planter le programme à une erreur proprement gérée. N’oubliez pas que parse retourne un type Result et que Result est une énumération qui a pour variantes Ok et Err. Nous utilisons ici une expression match comme nous l’avons déjà fait avec le résultat de type Ordering de la méthode cmp.
Si parse arrive à convertir la chaîne de caractères en nombre, cela va retourner la variante Ok qui contient le nombre qui en résulte. Cette variante va correspondre au motif de la première branche, et l’expression match va simplement retourner la valeur de nombre que parse a trouvée et qu’elle a mise dans la variante Ok. Ce nombre va se retrouver là où nous en avons besoin, dans la variable supposition que nous sommes en train de créer.
Si parse n’arrive pas à convertir la chaîne de caractères en nombre, elle va retourner la variante Err qui contient plus d’informations sur l’erreur. La variante Err ne correspond pas au motif Ok(nombre) de la première branche, mais elle correspond au motif Err(_) de la seconde branche. Le tiret bas, _, est une valeur passe-partout ; dans notre exemple, nous disons que nous voulons correspondre à toutes les valeurs de Err, peu importe quelle information elles ont à l’intérieur d’elles-mêmes. Donc le programme va exécuter le code de la seconde branche, continue, qui indique au programme de se rendre à la prochaine itération de loop et de demander un nouveau nombre. Ainsi, le programme ignore toutes les erreurs que parse pourrait rencontrer !
Maintenant, le programme devrait fonctionner correctement. Essayons-le :
$ cargo run
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/jeu_du_plus_ou_du_moins`
Devinez le nombre !
Le nombre secret est : 61
Veuillez entrer un nombre.
10
Votre nombre : 10
C'est plus !
Veuillez entrer un nombre.
99
Votre nombre : 99
C'est moins !
Veuillez entrer un nombre.
foo
Veuillez entrer un nombre.
61
Votre nombre : 61
Vous avez gagné !
Super ! Avec notre petite touche finale, nous avons fini notre jeu du plus ou du moins. Rappelez-vous que le programme affiche toujours le nombre secret. C’était pratique pour les tests, mais cela gâche le jeu. Supprimons le println! qui affiche le nombre secret. L’encart 2-6 représente le code final.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
loop {
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: u32 = match supposition.trim().parse() {
Ok(nombre) => nombre,
Err(_) => continue,
};
println!("Votre nombre : {supposition}");
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => {
println!("Vous avez gagné !");
break;
}
}
}
}Si vous êtes arrivé jusqu’ici, c’est que vous avez construit avec succès le jeu du plus ou du moins. Félicitations !
Résumé
Ce projet était une mise en pratique pour vous initier à de nombreux concepts de Rust : let, match, les méthodes, les fonctions associées, l’utilisation de crates externes, et bien plus. Dans les prochains chapitres, vous allez en apprendre plus sur ces concepts. Le chapitre 3 va traiter des concepts utilisés par la plupart des langages de programmation, comme les variables, les types de données, et les fonctions, et vous montrera comment les utiliser avec Rust. Le chapitre 4 expliquera la possession (ownership), qui est une fonctionnalité qui distingue Rust des autres langages. Le chapitre 5 abordera les structures et les syntaxes des méthodes, et le chapitre 6 expliquera comment les énumérations fonctionnent.
Les concepts courants de programmation
Ce chapitre explique des concepts qui apparaissent dans presque tous les langages de programmation, et la manière dont ils fonctionnent en Rust. De nombreux langages sont basés sur des concepts communs. Les concepts présentés dans ce chapitre ne sont pas spécifiques à Rust, mais nous les appliquerons à Rust et nous expliquerons les conventions qui leur sont liées.
Plus précisément, vous allez apprendre les concepts de variables, les types de base, les fonctions, les commentaires, et les structures de contrôle. Ces notions fondamentales seront présentes dans tous les programmes Rust, et les apprendre dès le début vous procurera de solides bases pour débuter.
Mots-clés
Le langage Rust possède un ensemble de mots-clés qui ont été réservés pour l’usage exclusif du langage, tout comme le font d’autres langages. Gardez à l’esprit que vous ne pouvez pas utiliser ces mots pour des noms de variables ou de fonctions. La plupart des mots-clés ont une signification spéciale, et vous les utiliserez pour réaliser de différentes tâches dans vos programmes Rust ; quelques-uns n’ont aucune fonctionnalité active pour le moment, mais ont été réservés pour être ajoutés plus tard à Rust. Vous pouvez trouver la liste de ces mots-clés dans l’annexe A.
Les variables et la mutabilité
Les variables et la mutabilité
Tel qu’abordé au chapitre 2, par défaut, les variables sont immuables. C’est un des nombreux coups de pouce de Rust pour écrire votre code de façon à garantir la sécurité et la concurrence sans problème. Cependant, vous avez quand même la possibilité de rendre vos variables mutables (modifiables). Explorons comment et pourquoi Rust vous encourage à favoriser l’immuabilité, et pourquoi parfois vous pourriez choisir d’y renoncer.
Lorsqu’une variable est immuable, cela signifie qu’une fois qu’une valeur est liée à un nom, vous ne pouvez pas changer cette valeur. À titre d’illustration, générez un nouveau projet appelé variables dans votre répertoire projects en utilisant cargo new variables.
Ensuite, dans votre nouveau répertoire variables, ouvrez src/main.rs et remplacez son code par le code suivant, qui ne se compile pas pour le moment :
Fichier : src/main.rs
fn main() {
let x = 5;
println!("La valeur de x est : {x}");
x = 6;
println!("La valeur de x est : {x}");
}Sauvegardez et lancez le programme en utilisant cargo run. Vous devriez avoir un message d’erreur à propos d’une erreur d’immutabilité, comme celui-ci :
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("La valeur de x est : {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Cet exemple montre comment le compilateur vous aide à trouver les erreurs dans vos programmes. Les erreurs de compilation peuvent s’avérer frustrantes, mais elles signifient en réalité que, pour le moment, votre programme n’est pas en train de faire ce que vous voulez qu’il fasse en toute sécurité ; elles ne signifient pas que vous êtes un mauvais développeur ! Même les Rustacés expérimentés continuent d’avoir des erreurs de compilation.
Vous avez reçu le message d’erreur impossible d'assigner à deux reprises la variable immuable `x` (cannot assign twice to immutable variable `x`) parce que vous avez tenté d’assigner une seconde valeur à la variable immuable x.
Il est important que nous obtenions des erreurs au moment de la compilation lorsque nous essayons de changer une valeur qui a été déclarée comme immuable, car cette situation particulière peut donner lieu à des bogues. Si une partie de notre code part du principe qu’une valeur ne changera jamais et qu’une autre partie de notre code modifie cette valeur, il est possible que la première partie du code ne fasse pas ce pour quoi elle a été conçue. La cause de ce genre de bogue peut être difficile à localiser après coup, en particulier lorsque la seconde partie du code ne modifie que parfois cette valeur. Le compilateur Rust garantit que lorsque vous déclarez qu’une valeur ne change pas, elle ne va jamais changer, donc vous n’avez pas à vous en soucier. Votre code est ainsi plus facile à maîtriser.
Mais la mutabilité peut s’avérer très utile et peut faciliter la rédaction du code. Bien que les variables sont immuables par défaut, vous pouvez les rendre mutables en ajoutant mut devant le nom de la variable , comme vous l’avez fait au chapitre 2. L’ajout de mut va aussi signaler l’intention aux futurs lecteurs de ce code que d’autres parties du code vont modifier la valeur de cette variable.
Par exemple, modifions src/main.rs ainsi :
Fichier : src/main.rs
fn main() {
let mut x = 5;
println!("La valeur de x est : {x}");
x = 6;
println!("La valeur de x est : {x}");
}Lorsque nous exécutons le programme, nous obtenons :
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
La valeur de x est : 5
La valeur de x est : 6
En utilisant mut, nous avons permis à la valeur liée à x de passer de 5 à 6. En fin de compte, c’est à vous de décider si vous souhaitez utiliser la mutabilité ou non, en fonction de ce qui vous semble le plus clair dans chaque situation particulière.
Déclaration des constantes
Comme les variables immuables, les constantes sont des valeurs qui sont liées à un nom et qui ne peuvent être modifiées, mais il y a quelques différences entre les constantes et les variables.
D’abord, vous ne pouvez pas utiliser mut avec les constantes. Les constantes ne sont pas seulement immuables par défaut − elles sont toujours immuables. On déclare les constantes en utilisant le mot-clé const à la place du mot-clé let, et le type de la valeur doit être indiqué. Nous allons aborder les types et les annotations de types dans la prochaine section, “Les types de données”, donc ne vous souciez pas des détails pour le moment. Sachez seulement que vous devez toujours indiquer le type.
Les constantes peuvent être déclarées à n’importe quel endroit du code, y compris la portée globale, ce qui les rend très utiles pour des valeurs que de nombreuses parties de votre code ont besoin de connaître.
La dernière différence est que les constantes ne peuvent être définies que par une expression constante, et non pas le résultat d’une valeur qui ne pourrait être calculée qu’à l’exécution.
Voici un exemple d’une déclaration de constante :
#![allow(unused)]
fn main() {
const TROIS_HEURES_EN_SECONDES: u32 = 60 * 60 * 3;
}Le nom de la constante est TROIS_HEURES_EN_SECONDES et sa valeur est définie comme étant le résultat de la multiplication de 60 (le nombre de secondes dans une minute) par 60 (le nombre de minutes dans une heure) par 3 (le nombre d’heures que nous voulons calculer dans ce programme). En Rust, la convention de nommage des constantes est de les écrire tout en majuscule avec des tirets bas entre les mots. Le compilateur peut calculer un certain nombre d’opérations à la compilation, ce qui nous permet d’écrire cette valeur de façon à la comprendre plus facilement et à la vérifier, plutôt que de définir cette valeur à 10 800. Vous pouvez consulter la section de la référence Rust à propos des évaluations des constantes pour en savoir plus sur les opérations qui peuvent être utilisées pour déclarer des constantes.
Les constantes sont valables pendant toute la durée d’exécution du programme au sein de la portée dans laquelle elles sont déclarées. Cette caractéristique rend les constantes très utiles lorsque plusieurs parties du programme doivent connaître certaines valeurs, comme par exemple le nombre maximum de points qu’un joueur est autorisé à gagner ou encore la vitesse de la lumière.
Déclarer des valeurs codées en dur et utilisées tout le long de votre programme en tant que constantes est utile pour faire comprendre la signification de ces valeurs dans votre code aux futurs développeurs. Cela permet également de n’avoir qu’un seul endroit de votre code à modifier si cette valeur codée en dur doit être mise à jour à l’avenir.
Le masquage
Comme nous l’avons vu dans le Chapitre 2, on peut déclarer une nouvelle variable avec le même nom qu’une variable précédente. Les Rustacés disent que la première variable est masquée par la seconde, ce qui signifie que la seconde variable sera ce que le compilateur verra lorsque vous utilisez le nom de cette variable. En effet, la deuxième variable masque la première, s’appropriant toutes les utilisations du nom de variable jusqu’à ce qu’elle soit elle-même masquée ou que la portée prenne fin. Nous pouvons masquer une variable en utilisant le même nom de variable et en réutilisant le mot-clé let comme ci-dessous :
Fichier : src/main.rs
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("La valeur de x dans la portée interne est : {x}");
}
println!("La valeur de x est : {x}");
}Au début, ce programme lie x à la valeur 5. Puis il crée une nouvelle variable x en répétant let x =, en récupérant la valeur d’origine et lui ajoutant 1, de sorte que la valeur de x est désormais 6. Ensuite, à l’intérieur de la portée interne créée par les parenthèses, la troisième instruction let masque aussi x et crée une nouvelle variable, en récupérant la précédente valeur et en la multipliant par 2 pour donner à x la valeur finale de 12. Dès que nous sortons de cette portée, le masque prend fin, et x revient à la valeur 6. Lorsque nous exécutons ce programme, nous obtenons ceci :
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
La valeur de x dans la portée interne est : 12
La valeur de x est : 6
Créer un masque est différent que de marquer une variable comme étant mut, car à moins d’utiliser une nouvelle fois le mot-clé let, nous obtiendrons une erreur de compilation si nous essayons de réassigner cette variable par accident. En utilisant let, on peut faire quelques modifications à une valeur tout en gardant le caractère immuable de la variable, une fois ces modifications effectuées.
Comme nous créons une nouvelle variable lorsque nous utilisons le mot-clé let une nouvelle fois, l’autre différence entre le mut et la création d’un masque est que cela nous permet de changer le type de la valeur, mais en réutilisant le même nom. Par exemple, imaginons un programme qui demande à l’utilisateur le nombre d’espaces qu’il souhaite entre deux portions de texte en saisissant des espaces, et ensuite nous voulons stocker cette saisie sous forme de nombre :
fn main() {
let espaces = " ";
let espaces = espaces.len();
}La première variable espaces est du type chaîne de caractères (string) et la seconde variable espaces est du type nombre. L’utilisation du masquage nous évite ainsi d’avoir à trouver des noms différents, comme espaces_str et espaces_num ; nous pouvons plutôt simplement réutiliser le nom espaces. Cependant, si nous essayons d’utiliser mut pour faire ceci, comme ci-dessous, nous avons une erreur de compilation :
fn main() {
let mut espaces = " ";
espaces = espaces.len();
}L’erreur indique que nous ne pouvons pas muter le type d’une variable :
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut espaces = " ";
| ----- expected due to this value
3 | espaces = espaces.len();
| ^^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Maintenant que nous avons découvert comment fonctionnent les variables, étudions les types de données qu’elles peuvent prendre.
Les types de données
Les types de données
Chaque valeur en Rust est d’un type bien déterminé, qui indique à Rust quel genre de données il manipule pour qu’il sache comment traiter ces données. Nous allons nous intéresser à deux catégories de types de données : les scalaires et les composés.
Gardez à l’esprit que Rust est un langage statiquement typé, ce qui signifie qu’il doit connaître les types de toutes les variables au moment de la compilation. Le compilateur peut souvent déduire quel type utiliser en se basant sur la valeur et sur la façon dont elle est utilisée. Dans les cas où plusieurs types sont envisageables, comme lorsque nous avons converti une chaîne de caractères en un type numérique en utilisant parse dans la section “Comparer le nombre saisi au nombre secret” du chapitre 2, nous devons ajouter une annotation de type, comme ceci :
#![allow(unused)]
fn main() {
let supposition: u32 = "42".parse().expect("Ce n'est pas un nombre !");
}Si nous n’ajoutons pas l’annotation de type : u32 montrée dans le code précédent, Rust affichera l’erreur suivante, signifiant que le compilateur a besoin de plus d’informations pour déterminer quel type nous souhaitons utiliser :
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let supposition = "42".parse().expect("Ce n'est pas un nombre !");
| ^^^^^^^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let supposition: /* Type */ = "42".parse().expect("Ce n'est pas un nombre !");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
Vous découvrirez différentes annotations de type au fur et à mesure que nous aborderons les autres types de données.
Types scalaires
Un type scalaire représente une seule valeur. Rust possède quatre types principaux de scalaires : les entiers, les nombres à virgule flottante, les booléens et les caractères. Vous les connaissez sûrement dans d’autres langages de programmation. Regardons comment ils fonctionnent avec Rust.
Types de nombres entiers
Un entier est un nombre sans partie décimale. Nous avons utilisé un entier précédemment dans le chapitre 2, le type u32. Cette déclaration de type indique que la valeur à laquelle elle est associée doit être un entier non signé encodé sur 32 bits dans la mémoire (les entiers pouvant prendre des valeurs négatives commencent par un i (comme integer : “entier”) plutôt que par un u comme unsigned : “non signé”). Le tableau 3-1 montre les types d’entiers intégrés au langage. Nous pouvons utiliser chacune de ces variantes pour déclarer le type d’une valeur entière.
Tableau 3-1 : les types d’entiers en Rust
| Taille | Signé | Non signé |
|---|---|---|
| 8 bits | i8 | u8 |
| 16 bits | i16 | u16 |
| 32 bits | i32 | u32 |
| 64 bits | i64 | u64 |
| 128 bits | i128 | u128 |
| Dépendant de l’architecture | isize | usize |
Chaque variante peut être signée ou non signée et possède une taille explicite. Signé et non signé veut dire respectivement que le nombre peut prendre ou non des valeurs négatives — en d’autres termes, si l’on peut lui attribuer un signe (signé) ou s’il sera toujours positif et que l’on peut donc le représenter sans signe (non signé). C’est comme écrire des nombres sur du papier : quand le signe est important, le nombre est écrit avec un signe plus ou un signe moins ; en revanche, quand le nombre est forcément positif, on peut l’écrire sans son signe. Les nombres signés sont stockés en utilisant le complément à deux.
Chaque variante signée peut stocker des nombres allant de −(2n − 1) à 2n − 1 − 1 inclus, où n est le nombre de bits que cette variante utilise. Un i8 peut donc stocker des nombres allant de −(27) à 27 − 1, c’est-à-dire de −128 à 127. Les variantes non signées peuvent stocker des nombres de 0 à 2n − 1, donc un u8 peut stocker des nombres allant de 0 à 28 − 1, c’est-à-dire de 0 à 255.
De plus, les types isize et usize dépendent de l’architecture de l’ordinateur sur lequel votre programme va s’exécuter, d’où la ligne “Dépendant de l’architecture” : 64 bits si vous utilisez une architecture 64 bits, ou 32 bits si vous utilisez une architecture 32 bits.
Vous pouvez écrire des littéraux d’entiers dans chacune des formes décrites dans le tableau 3-2. Notez que les littéraux numériques qui peuvent être de plusieurs types numériques autorisent l’utilisation d’un suffixe de type, tel que 57u8, afin de préciser leur type. Les nombres littéraux peuvent aussi utiliser _ comme séparateur visuel afin de les rendre plus lisible, comme par exemple 1_000, qui a la même valeur que si vous aviez renseigné 1000.
Tableau 3-2 : les littéraux d’entiers en Rust
| Littéral numérique | Exemple |
|---|---|
| Décimal | 98_222 |
| Hexadécimal | 0xff |
| Octal | 0o77 |
| Binaire | 0b1111_0000 |
Octet (u8 seulement) | b'A' |
Comment pouvez-vous déterminer le type d’entier à utiliser ? Si vous n’êtes pas sûr, les choix par défaut de Rust sont généralement de bons choix : le type d’entier par défaut est le i32. La principale utilisation d’un isize ou d’un usize est lorsque l’on indexe une quelconque collection.
Dépassement d’entier
Imaginons que vous avez une variable de type u8 qui peut stocker des valeurs entre 0 et 255. Si vous essayez de changer la variable pour une valeur en dehors de cet intervalle, comme 256, vous aurez un dépassement d’entier (integer overflow), qui peut se comporter de deux manières. Lorsque vous compilez en mode débogage, Rust embarque des vérifications pour détecter les cas de dépassements d’entiers qui pourraient faire paniquer votre programme à l’exécution si ce phénomène se produit. Rust utilise le terme paniquer quand un programme se termine avec une erreur ; nous verrons plus en détail les paniques dans une section du chapitre 9.
Lorsque vous compilez en mode publication (release) avec le drapeau --release, Rust ne va pas vérifier les potentiels dépassements d’entiers qui peuvent faire paniquer le programme. En revanche, en cas de dépassement, Rust va effectuer un rebouclage du complément à deux. Pour faire simple, les valeurs supérieures à la valeur maximale du type seront “rebouclées” depuis la valeur minimale que le type peut stocker. Dans le cas d’un u8, la valeur 256 devient 0, la valeur 257 devient 1, et ainsi de suite. Le programme ne va pas paniquer, mais la variable va avoir une valeur qui n’est probablement pas ce que vous attendez à avoir. Se fier au comportement du rebouclage lors du dépassement d’entier est considéré comme une faute.
Pour gérer explicitement le dépassement, vous pouvez utiliser les familles de méthodes suivantes qu’offrent la bibliothèque standard sur les types de nombres primitifs :
- Enveloppez les opérations avec les méthodes
wrapping_*, comme par exemplewrapping_add. - Retourner la valeur
Nones’il y a un dépassement avec des méthodeschecked_*. - Retourner la valeur et un booléen qui indique s’il y a eu un dépassement avec des méthodes
overflowing_*. - Saturer à la valeur minimale ou maximale avec les méthodes
saturating_*.
Types de nombres à virgule flottante
Rust possède également deux types primitifs pour les nombres à virgule flottante (ou flottants), qui sont des nombres avec des décimales. Les types de flottants en Rust sont les f32 et les f64, qui ont respectivement une taille en mémoire de 32 bits et 64 bits. Le type par défaut est le f64 car sur les processeurs récents, ce type est quasiment aussi rapide qu’un f32 mais est plus précis. Tous les flottants ont un signe.
Voici un exemple montrant l’utilisation de nombres à virgule flottante :
Fichier : src/main.rs
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}Les nombres à virgule flottante sont représentés selon la norme IEEE-754.
Les opérations numériques
Rust offre les opérations mathématiques de base dont vous auriez besoin pour tous les types de nombres : addition, soustraction, multiplication, division et modulo. Les divisions d’entiers tronquent le résultat à l’entier le plus près en descendant vers zéro. Le code suivant montre comment utiliser chacune des opérations numériques avec une instruction let :
Fichier : src/main.rs
fn main() {
// addition
let somme = 5 + 10;
// soustraction
let difference = 95.5 - 4.3;
// multiplication
let produit = 4 * 30;
// division
let quotient = 56.7 / 32.2;
let partie_entiere = -5 / 3; // retournera -1
// modulo
let reste = 43 % 5;
}Chaque expression de ces instructions utilise un opérateur mathématique et calcule une valeur unique, qui est ensuite attribuée à une variable. L’annexe B présente une liste de tous les opérateurs que Rust fournit.
Le type booléen
Comme dans la plupart des langages de programmation, un type booléen a deux valeurs possibles en Rust : true (vrai) et false (faux). Les booléens prennent un octet en mémoire. Le type booléen est désigné en utilisant bool. Par exemple :
Fichier : src/main.rs
fn main() {
let t = true;
let f: bool = false; // avec une annotation de type explicite
}Les valeurs booléennes sont principalement utilisées par les structures conditionnelles, comme l’expression if. Nous aborderons le fonctionnement de if en Rust dans la section “Les structures de contrôle”.
Le type caractère
Le type char (comme character) est le type de caractère le plus rudimentaire. Voici quelques exemples de déclaration de valeurs de type char :
Fichier : src/main.rs
fn main() {
let c = 'z';
let z: char = 'ℤ'; // avec une annotation de type explicite
let chat_aux_yeux_de_coeur = '😻';
}Notez que nous renseignons un littéral char avec des guillemets simples, contrairement aux littéraux de chaîne de caractères, qui nécéssite des doubles guillemets. Le type char de Rust prend quatre octets en mémoire et représente une valeur scalaire Unicode, ce qui veut dire que cela représente plus de caractères que l’ASCII. Les lettres accentuées ; les caractères chinois, japonais et coréens ; les emojis ; les espaces de largeur nulle ont tous une valeur pour char avec Rust. Les valeurs scalaires Unicode vont de U+0000 à U+D7FF et de U+E000 à U+10FFFF inclus. Cependant, le concept de “caractère” n’est pas clairement défini par Unicode, donc votre notion de “caractère” peut ne pas correspondre à ce qu’est un char en Rust. Nous aborderons ce sujet plus en détail dans la partie “Stocker du texte encodé en UTF-8 avec les Strings”dans le chapitre 8.
Les types composés
Les types composés peuvent regrouper plusieurs valeurs dans un seul type. Rust a deux types composés de base : les tuples et les tableaux (arrays).
Le type tuple
Un tuple est une manière générale de regrouper plusieurs valeurs de types différents en un seul type composé. Les tuples ont une taille fixée : à partir du moment où ils ont été déclarés, on ne peut pas y ajouter ou enlever des valeurs.
Nous créons un tuple en écrivant une liste séparée par des virgules entre des parenthèses. Chaque emplacement dans le tuple a un type, et les types de chacune des valeurs dans le tuple n’ont pas forcément besoin d’être les mêmes. Nous avons ajouté des annotations de type dans cet exemple, mais c’est optionnel :
Fichier : src/main.rs
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}La variable tup est liée à tout le tuple car un tuple est considéré comme étant un unique élément composé. Pour obtenir un élément précis de ce tuple, nous pouvons utiliser un filtrage par motif (pattern matching) pour déstructurer ce tuple, comme ceci :
Fichier : src/main.rs
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("La valeur de y est : {y}");
}Le programme commence par créer un tuple et il l’assigne à la variable tup. Il utilise ensuite un motif avec let pour prendre tup et le scinder en trois variables distinctes : x, y, et z. On appelle cela déstructurer, car il divise le tuple en trois parties. Puis finalement, le programme affiche la valeur de y, qui est 6.4.
Nous pouvons aussi accéder directement à chaque élément du tuple en utilisant un point (.) suivi de l’indice de la valeur que nous souhaitons obtenir. Par exemple :
Fichier : src/main.rs
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let cinq_cents = x.0;
let six_virgule_quatre = x.1;
let un = x.2;
}Ce programme crée le tuple x puis accède à chaque élément du tuple en utilisant leurs indices respectifs. Comme dans de nombreux langages de programmation, le premier indice d’un tuple est 0.
Le tuple sans aucune valeur a un nom spécial, unité. Cette valeur ainsi que son type correspondant s’écrivent tous deux () et représentent une valeur vide ou un type de retour vide. Les expressions retournent implicitement la valeur unité si elles ne retournent aucune autre valeur.
Le type tableau
Un autre moyen d’avoir une collection de plusieurs valeurs est d’utiliser un tableau. Contrairement aux tuples, chaque élément d’un tableau doit être du même type. Contrairement aux tableaux de certains autres langages, les tableaux de Rust ont une taille fixe.
Nous écrivons les valeurs dans un tableau via une liste entre des crochets, séparée par des virgules :
Fichier : src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
}Les tableaux sont utiles quand vous voulez que vos données soient allouées sur la pile (stack), de la même manière que les autres types que nous avons vus jusqu’ici, plutôt que sur le tas (heap) (nous expliquerons la pile et le tas au chapitre 4) ou lorsque vous voulez vous assurer que vous avez toujours un nombre fixe d’éléments. Cependant, un tableau n’est pas aussi flexible qu’un vecteur (vector). Un vecteur est un type de collection de données similaire qui est fourni par la bibliothèque standard qui, lui, peut grandir ou rétrécir en taille, dans la mesure où ses données sont situées sur le tas (heap). Si vous ne savez pas si vous devez utiliser un tableau ou un vecteur, il y a de fortes chances que vous devriez utiliser un vecteur. Le chapitre 8 expliquera les vecteurs.
Toutefois, les tableaux s’avèrent plus utiles lorsque vous savez que le nombre d’éléments n’aura pas besoin de changer. Par exemple, si vous utilisez les noms des mois dans un programme, vous devriez probablement utiliser un tableau plutôt qu’un vecteur car vous savez qu’il contient toujours 12 éléments :
#![allow(unused)]
fn main() {
let mois = ["Janvier", "Février", "Mars", "Avril", "Mai", "Juin", "Juillet",
"Août", "Septembre", "Octobre", "Novembre", "Décembre"];
}Vous pouvez écrire le type d’un tableau en utilisant des crochets et entre ces crochets y ajouter le type de chaque élément, un point-virgule, et ensuite le nombre d’éléments dans le tableau, comme ceci :
#![allow(unused)]
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}Ici, i32 est le type de chaque élément. Après le point-virgule, le nombre 5 indique que le tableau contient cinq éléments.
Vous pouvez initialiser un tableau pour qu’il contienne toujours la même valeur pour chaque élément, vous pouvez préciser la valeur initiale, suivie par un point-virgule, et ensuite la taille du tableau, le tout entre crochets, comme ci-dessous :
#![allow(unused)]
fn main() {
let a = [3; 5];
}Le tableau a va contenir 5 éléments qui auront tous la valeur initiale 3. C’est la même chose que d’écrire let a = [3, 3, 3, 3, 3]; mais de manière plus concise.
Accès aux éléments d’un tableau
Un tableau est un simple bloc de mémoire de taille connue et fixe, qui peut être alloué sur la pile. Vous pouvez accéder aux éléments d’un tableau en utilisant l’indexation, comme ceci :
Fichier : src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
let premier = a[0];
let second = a[1];
}Dans cet exemple, la variable qui s’appelle premier aura la valeur 1 car c’est la valeur à l’indice [0] dans le tableau. La variable second récupèrera la valeur 2 depuis l’indice [1] du tableau.
Accès incorrect à un élément d’un tableau
Découvrons ce qui se passe quand vous essayez d’accéder à un élément d’un tableau qui se trouve après la fin du tableau ? Imaginons que vous exécutiez le code suivant, similaire au jeu du plus ou du moins du chapitre 2, pour demander un indice de tableau à l’utilisateur :
Fichier : src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Veuillez entrer un indice de tableau.");
let mut indice = String::new();
io::stdin()
.read_line(&mut indice)
.expect("Échec de la lecture de l'entrée utilisateur");
let indice: usize = indice
.trim()
.parse()
.expect("L'indice entré n'est pas un nombre");
let element = a[indice];
println!("La valeur de l'élément d'indice {indice} est : {element}");
}Ce code compile avec succès. Si vous exécutez ce code avec cargo run et que vous entrez 0, 1, 2, 3 ou 4, le programme affichera la valeur correspondante à cet indice dans le tableau. Si au contraire, vous entrez un indice après la fin du tableau tel que 10, ceci s’affichera :
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Le programme a rencontré une erreur à l’exécution, au moment d’utiliser une valeur invalide comme indice. Le programme s’est arrêté avec un message d’erreur et n’a pas exécuté la dernière instruction println!. Quand vous essayez d’accéder à un élément en utilisant l’indexation, Rust va vérifier que l’indice que vous avez demandé est plus petit que la taille du tableau. Si l’indice est supérieur ou égal à la taille du tableau, Rust va paniquer. Cette vérification doit avoir lieu à l’exécution, surtout dans ce cas, parce que le compilateur ne peut pas deviner la valeur qu’entrera l’utilisateur quand il exécutera le code plus tard.
C’est un exemple de mise en pratique des principes de sécurité de la mémoire par Rust. Dans de nombreux langages de bas niveau, ce genre de vérification n’est pas effectuée, et quand vous utilisez un indice incorrect, de la mémoire invalide peut être récupérée. Rust vous protège de ce genre d’erreur en quittant immédiatement l’exécution au lieu de permettre l’accès en mémoire et continuer son déroulement. Le chapitre 9 expliquera la gestion d’erreurs de Rust et comment vous pouvez écrire du code lisible et sûr qui ne panique pas ni n’autorise d’accès invalide à la mémoire.
Les fonctions
Les fonctions
Les fonctions sont très utilisées dans le code Rust. Vous avez déjà vu l’une des fonctions les plus importantes du langage : la fonction main, qui est le point d’entrée de beaucoup de programmes. Vous avez aussi vu le mot-clé fn, qui vous permet de déclarer des nouvelles fonctions.
Le code Rust utilise le snake case comme convention de style de nom des fonctions et des variables, toutes les lettres sont en minuscule et on utilise des tirets bas pour séparer les mots. Voici un programme qui est un exemple de définition de fonction :
Fichier : src/main.rs
fn main() {
println!("Hello, world!");
une_autre_fonction();
}
fn une_autre_fonction() {
println!("Une autre fonction.");
}Nous définissons une fonction avec Rust en saisissant fn suivi par un nom de fonction ainsi qu’une paire de parenthèses. Les accolades indiquent au compilateur où le corps de la fonction commence et où il se termine.
Nous pouvons appeler n’importe quelle fonction que nous avons définie en utilisant son nom, suivi d’une paire de parenthèses. Comme une_autre_fonction est définie dans le programme, elle peut être appelée à l’intérieur de la fonction main. Remarquez que nous avons défini une_autre_fonction après la fonction main dans le code source ; nous aurions aussi pu la définir avant. Rust ne se soucie pas de l’endroit où vous définissez vos fonctions, du moment qu’elles sont bien définies quelque part dans une portée qui peut être vue par l’appelant.
Créons un nouveau projet de binaire qui s’appellera functions afin d’en apprendre plus sur les fonctions. Ajoutez l’exemple une_autre_fonction dans le src/main.rs et exécutez-le. Vous devriez avoir ceci :
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Une autre fonction.
Les lignes s’exécutent dans l’ordre dans lequel elles apparaissent dans la fonction main. D’abord, le message Hello, world! est écrit, et ensuite une_autre_fonction est appelée et son message est affiché.
Les paramètres
Nous pouvons définir des fonctions avec des paramètres, qui sont des variables spéciales qui font partie de la signature de la fonction. Quand une fonction a des paramètres, vous pouvez lui fournir des valeurs concrètes avec ces paramètres. Techniquement, ces valeurs concrètes sont appelées des arguments, mais dans une conversation courante, on a tendance à confondre les termes paramètres et arguments pour désigner soit les variables dans la définition d’une fonction, soit les valeurs concrètes passées quand on appelle une fonction.
Dans cette version de une_autre_fonction, nous ajoutons un paramètre :
Fichier : src/main.rs
fn main() {
une_autre_fonction(5);
}
fn une_autre_fonction(x: i32) {
println!("La valeur de x est : {x}");
}En exécutant ce programme, vous devriez obtenir ceci :
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
La valeur de x est : 5
La déclaration de une_autre_fonction a un paramètre nommé x. Le type de x a été déclaré comme i32. Quand nous passons 5 à une_autre_fonction, la macro println! place 5 là où la paire d’accolades contenant x était placée dans la chaîne de formatage.
Dans la signature d’une fonction, vous devez déclarer le type de chaque paramètre. C’est un choix délibéré de conception de Rust : exiger l’annotation de type dans la définition d’une fonction fait en sorte que le compilateur n’a presque plus besoin que vous les utilisiez autre part pour qu’il comprenne avec quel type vous souhaitez travailler. Le compilateur est également capable de fournir des messages d’erreur plus utiles s’il connaît les types attendus par la fonction.
Lorsque vous définissez plusieurs paramètres, séparez les paramètres avec des virgules, comme ceci :
Fichier : src/main.rs
fn main() {
afficher_mesure_avec_unite(5, 'h');
}
fn afficher_mesure_avec_unite(valeur: i32, unite: char) {
println!("La mesure est : {valeur}{unite}");
}Cet exemple crée la fonction afficher_mesure_avec_unite qui a deux paramètres. Le premier paramètre s’appelle valeur et est un i32. Le second, unite, est de type char. La fonction affiche ensuite le texte qui contient les valeurs de valeur et de unite.
Essayons d’exécuter ce code. Remplacez le programme présent actuellement dans votre fichier src/main.rs de votre projet functions par l’exemple précédent et lancez-le en utilisant cargo run :
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
La mesure est : 5h
Comme nous avons appelé la fonction avec la valeur 5 pour valeur et 'h' pour unite, la sortie de ce programme contient ces valeurs.
Instructions et expressions
Les corps de fonctions sont constitués d’une série d’instructions qui se termine éventuellement par une expression. Jusqu’à présent, les fonctions que nous avons vues n’avaient pas d’expression à la fin, mais vous avez déjà vu une expression faire partie d’une instruction. Comme Rust est un langage basé sur des expressions, il est important de faire la distinction. D’autres langages ne font pas de telles distinctions, donc penchons-nous sur ce que sont les instructions et les expressions et comment leurs différences influent sur le corps des fonctions.
- Les instructions effectuent des actions et ne retournent aucune valeur.
- Les expressions sont évaluées pour retourner une valeur comme résultat.
Voyons quelques exemples.
Nous avons déjà utilisé des instructions et des expressions. La création d’une variable en lui assignant une valeur avec le mot-clé let est une instruction. Dans l’encart 3-1, let y = 6; est une instruction.
fn main() {
let y = 6;
}main function declaration containing one statementLa définition d’une fonction est aussi une instruction ; l’intégralité de l’exemple précédent est une instruction à elle toute seule (cependant, comme nous le verrons prochainement, appeler une fonction n’est pas un instruction).
Une instruction ne retourne pas de valeur. Ainsi, vous ne pouvez pas assigner le résultat d’une instruction let à une autre variable, comme le code suivant essaye de le faire, car vous obtiendrez une erreur :
Fichier : src/main.rs
fn main() {
let x = (let y = 6);
}Quand vous exécutez ce programme, l’erreur que vous obtenez devrait ressembler à ceci :
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
L’instruction let y = 6 ne retourne pas de valeur, donc cela ne peut pas devenir une valeur de x. Ceci est différent d’autres langages, comme le C ou Ruby, où l’assignation retourne la valeur de l’assignation. Dans ces langages, vous pouvez écrire x = y = 6 et avoir ainsi x et y qui ont chacun la valeur 6 ; cela n’est pas possible avec Rust.
Les expressions sont calculées en tant que valeur et seront ce que vous écrirez le plus en Rust (hormis les instructions). Prenez une opération mathématique, comme 5 + 6, qui est une expression qui s’évalue à la valeur 11. Les expressions peuvent faire partie d’une instruction : dans l’encart 3-1, le 6 dans l’instruction let y = 6; est une expression qui s’évalue à la valeur 6. L’appel de fonction est aussi une expression. L’appel de macro est une expression. Un nouveau bloc de portée que nous créons avec des accolades est une expression, par exemple :
Fichier : src/main.rs
fn main() {
let y = {
let x = 3;
x + 1
};
println!("La valeur de y est : {y}");
}L’expression suivante…
{
let x = 3;
x + 1
}… est un bloc qui, dans ce cas, s’évalue à 4. Cette valeur est assignée à y dans le cadre de l’instruction let. Remarquez la ligne x + 1 sans point-virgule à la fin, ce qui est différent de la plupart des lignes que vous avez vues jusque là. Les expressions n’ont pas de point-virgule de fin de ligne. Si vous ajoutez un point-virgule à la fin de l’expression, vous la transformez en instruction, et elle ne va donc pas retourner de valeur. Gardez ceci à l’esprit quand nous aborderons prochainement les valeurs de retour des fonctions ainsi que les expressions.
Les fonctions qui retournent des valeurs
Les fonctions peuvent retourner des valeurs au code qui les appelle. Nous ne nommons pas les valeurs de retour, mais nous devons déclarer leur type après une flèche (->). En Rust, la valeur de retour de la fonction est la même que la valeur de l’expression finale dans le corps de la fonction. Vous pouvez sortir prématurément d’une fonction en utilisant le mot-clé return et en précisant la valeur de retour, mais la plupart des fonctions vont retourner implicitement la dernière expression. Voici un exemple d’une fonction qui retourne une valeur :
Fichier : src/main.rs
fn cinq() -> i32 {
5
}
fn main() {
let x = cinq();
println!("La valeur de x est : {x}");
}Il n’y a pas d’appel de fonction, de macro, ni même d’instruction let dans la fonction cinq — uniquement le nombre 5 tout seul. C’est une fonction parfaitement valide avec Rust. Remarquez que le type de retour de la fonction a été précisé aussi, avec -> i32. Essayez d’exécuter ce code ; le résultat devrait ressembler à ceci :
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
La valeur de x est : 5
Le 5 dans cinq est la valeur de retour de la fonction, ce qui explique le type de retour de i32. Regardons cela plus en détail. Il y a deux éléments importants : premièrement, la ligne let x = cinq(); dit que nous utilisons la valeur de retour de la fonction pour initialiser la variable. Comme la fonction cinq retourne un 5, cette ligne revient à faire ceci :
#![allow(unused)]
fn main() {
let x = 5;
}Deuxièmement, la fonction cinq n’a pas de paramètre et déclare le type de valeur de retour, mais le corps de la fonction est un simple 5 sans point-virgule car c’est une expression dont nous voulons retourner la valeur.
Regardons un autre exemple :
Fichier : src/main.rs
fn main() {
let x = plus_un(5);
println!("La valeur de x est : {x}");
}
fn plus_un(x: i32) -> i32 {
x + 1
}Exécuter ce code va afficher La valeur de x est : 6. Mais que se passe-t-il si nous ajoutons un point-virgule à la fin de la ligne qui contient x + 1, ce qui la transforme d’une expression à une instruction ?
Fichier : src/main.rs
fn main() {
let x = plus_un(5);
println!("La valeur de x est : {x}");
}
fn plus_un(x: i32) -> i32 {
x + 1;
}Compiler ce code va produire une erreur, comme ci-dessous :
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_un(x: i32) -> i32 {
| ------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
Le message d’erreur principal, “mismatched types” (types inadéquats) donne le cœur du problème de ce code. La définition de la fonction plus_un dit qu’elle va retourner un i32, mais les instructions ne retournent pas de valeur, ceci est donc représenté par (), le type unité. Par conséquent, rien n’est retourné, ce qui contredit la définition de la fonction et provoque une erreur. Rust affiche un message qui peut aider à corriger ce problème : il suggère d’enlever le point-virgule, ce qui va résoudre notre problème.
Les commentaires
Les commentaires
Tous les développeurs s’efforcent de rendre leur code facile à comprendre, mais parfois il est nécessaire d’écrire des explications supplémentaires. Dans ce cas, les développeurs laissent des commentaires dans leur code source que le compilateur va ignorer mais qui peuvent être utiles pour les personnes qui lisent le code source.
Voici un simple commentaire :
#![allow(unused)]
fn main() {
// hello, world
}Avec Rust, les commentaires classiques commencent avec deux barres obliques et continuent jusqu’à la fin de la ligne. Pour les commentaires qui font plus d’une seule ligne, vous pouvez ajouter // au début de chaque ligne, comme ceci :
#![allow(unused)]
fn main() {
// Donc ici on fait quelque chose de compliqué, tellement long que nous avons
// besoin de plusieurs lignes de commentaires pour le faire ! Heureusement,
// ce commentaire va expliquer ce qui se passe.
}Les commentaires peuvent aussi être aussi ajoutés à la fin d’une ligne qui contient du code :
Fichier : src/main.rs
fn main() {
let nombre_chanceux = 7; // Je me sens chanceux aujourd'hui
}Mais le plus souvent, vous les verrez utilisés de cette manière, avec le commentaire sur une ligne séparée au-dessus du code qu’il annote :
Fichier : src/main.rs
fn main() {
// Je me sens chanceux aujourd'hui
let nombre_chanceux = 7;
}#![allow(unused)]
fn main() {
/*
Donc ici on fait quelque chose de compliqué, tellement long que nous avons
besoin de plusieurs lignes de commentaires pour le faire ! Heureusement,
ce commentaire va expliquer ce qui se passe.
*/
}Une caractéristique intéressante est que Rust permet l’imbrication de ce type de commentaires : cela s’avère particulièrement utile durant la phase de débogage du code, car cela permet d’“annuler” temporairement des portions de code qui peuvent elles-même comporter des commentaires imbriqués, comme dans l’exemple suivant : voici un code manifestement problématique, qui ne compile pas :
fn main() {
let nombre_chanceux = 7;
/*
Incrémentation du nombre chanceux :
*/
nombre_chanceux = nombre_chanceux + 2;
println!("Mon nombre chanceux est {nombre_chanceux}");
}
Et voici le même code, avec une partie commentée, ce qui permet la compilation :
fn main() {
let nombre_chanceux = 7;
/* Neutralisation du code ne fonctionnant pas :
/*
Incrémentation du nombre chanceux :
*/
nombre_chanceux = nombre_chanceux + 2;
*/
println!("Mon nombre chanceux est {nombre_chanceux}");
}
Notez l’imbrication des commentaires, par rapport au fonctionnement des commentaires en C.
Enfin, Rust a aussi un autre type de commentaire, les commentaires de documentation, que nous aborderons dans la partie ["Publier une crate sur crates.io"](ch14-02-publishing-to-crates-io.html) du chapitre 14.Les structures de contrôle
Les structures de contrôle
Pouvoir exécuter ou non du code si une condition est vérifiée, ou exécuter du code de façon répétée tant qu’une condition est vérifiée, sont des constructions élémentaires dans la plupart des langages de programmation. Les structures de contrôle les plus courantes en Rust sont les expressions if et les boucles.
Les expressions if
Une expression if vous permet de diviser votre code en fonction de conditions. Vous précisez une condition et vous choisissez ensuite : “Si cette condition est remplie, alors exécuter ce bloc de code. Si la condition n’est pas remplie, ne pas exécuter ce bloc de code.”
Créez un nouveau projet appelé branches dans votre répertoire projects pour découvrir les expressions if. Dans le fichier src/main.rs, écrivez ceci :
Fichier : src/main.rs
fn main() {
let nombre = 3;
if nombre < 5 {
println!("La condition est vérifiée");
} else {
println!("La condition n'est pas vérifiée");
}
}Une expression if commence par le mot-clé if, suivi d’une condition. Dans notre cas, la condition vérifie si oui ou non la variable nombre a une valeur inférieure à 5. Nous ajoutons le bloc de code à exécuter si la condition est vérifiée immédiatement après la condition entre des accolades. Les blocs de code associés à une condition dans une expression if sont parfois appelés des branches, exactement comme les branches dans les expressions match que nous avons vu dans la section “Comparer le nombre saisi au nombre secret” du chapitre 2.
Éventuellement, vous pouvez aussi ajouter une expression else, ce que nous avons fait ici, pour préciser un bloc alternatif de code qui sera exécuté dans le cas où la condition est fausse (elle n’est pas vérifiée). Si vous ne renseignez pas d’expression else et que la condition n’est pas vérifiée, le programme va simplement sauter le bloc de if et passer au prochain morceau de code.
Essayez d’exécuter ce code ; vous verrez ceci :
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
La condition est vérifiée
Essayons de changer la valeur de nombre pour une valeur qui rend la condition non vérifiée pour voir ce qui se passe :
fn main() {
let nombre = 7;
if nombre < 5 {
println!("La condition est vérifiée");
} else {
println!("La condition n'est pas vérifiée");
}
}Exécutez à nouveau le programme, et regardez le résultat :
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
La condition n'est pas vérifiée
Il est aussi intéressant de noter que la condition dans ce code doit être un bool. Si la condition n’est pas un bool, nous aurons une erreur. Par exemple, essayez d’exécuter le code suivant :
Fichier : src/main.rs
fn main() {
let nombre = 3;
if nombre {
println!("Le nombre était trois");
}
}La condition if vaut 3 cette fois, et Rust lève une erreur :
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if nombre {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Cette erreur explique que Rust attendait un bool mais a obtenu un entier (integer). Contrairement à des langages comme Ruby et JavaScript, Rust ne va pas essayer de convertir automatiquement les types non booléens en booléens. Vous devez être précis et toujours fournir un booléen à la condition d’un if. Si nous voulons que le bloc de code du if soit exécuté quand le nombre est différent de 0, par exemple, nous pouvons changer l’expression if par la suivante :
Fichier : src/main.rs
fn main() {
let nombre = 3;
if nombre != 0 {
println!("Le nombre valait autre chose que zéro");
}
}Exécuter ce code va bien afficher Le nombre valait autre chose que zéro.
Gérer plusieurs conditions avec else if
Vous pouvez utiliser plusieurs conditions en combinant if et else dans une expression else if. Par exemple :
Fichier : src/main.rs
fn main() {
let nombre = 6;
if nombre % 4 == 0 {
println!("Le nombre est divisible par 4");
} else if nombre % 3 == 0 {
println!("Le nombre est divisible par 3");
} else if nombre % 2 == 0 {
println!("Le nombre est divisible par 2");
} else {
println!("Le nombre n'est pas divisible par 4, 3 ou 2");
}
}Ce programme peut choisir entre quatre chemins différents. Après l’avoir exécuté, vous devriez voir le résultat suivant :
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
Le nombre est divisible par 3
Quand ce programme s’exécute, il vérifie chaque expression if à tour de rôle et exécute le premier bloc dont la condition est vérifiée. Notez que même si 6 est divisible par 2, nous ne voyons pas le message Le nombre est divisible par 2, ni le message Le nombre n'est pas divisible par 4, 3 ou 2 du bloc else. C’est parce que Rust n’exécute que le bloc de la première condition vérifiée, et dès lors qu’il en a trouvé une, il ne va pas chercher à vérifier les suivantes.
Utiliser trop d’expressions else if peut encombrer votre code, donc si vous en avez plus d’une, vous devriez envisager de remanier votre code. Le chapitre 6 présente une construction puissante appelée match pour de tels cas.
Utiliser if dans une instruction let
Comme if est une expression, nous pouvons l’utiliser à droite d’une instruction let pour assigner le résultat à une variable, comme dans l’encart 3-2.
fn main() {
let condition = true;
let nombre = if condition { 5 } else { 6 };
println!("La valeur du nombre est : {nombre}");
}if expression to a variableLa variable nombre va avoir la valeur du résultat de l’expression if. Exécutez ce code pour découvrir ce qui va se passer :
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
La valeur du nombre est : 5
Souvenez-vous que les blocs de code s’exécutent jusqu’à la dernière expression qu’ils contiennent, et que les nombres tout seuls sont aussi des expressions. Dans notre cas, la valeur de toute l’expression if dépend de quel bloc de code elle va exécuter. Cela veut dire que chaque valeur qui peut être le résultat de chaque branche du if doivent être du même type ; dans l’encart 3-2, les résultats des branches if et else sont tous deux des entiers i32. Si les types ne sont pas identiques, comme dans l’exemple suivant, nous allons obtenir une erreur :
Fichier : src/main.rs
fn main() {
let condition = true;
let nombre = if condition { 5 } else { "six" };
println!("La valeur du nombre est : {nombre}");
}Lorsque nous essayons de compiler ce code, nous obtenons une erreur. Les branches if et else ont des types de valeurs qui ne sont pas compatibles, et Rust indique exactement où trouver le problème dans le programme :
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let nombre = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
L’expression dans le bloc if donne un entier, et l’expression dans le bloc else donne une chaîne de caractères. Ceci ne fonctionne pas car les variables doivent avoir un seul type, et Rust a impérativement besoin de savoir de quel type est la variable nombre au moment de la compilation. Savoir le type de nombre permet au compilateur de vérifier que le type est valable n’importe où nous utilisons nombre. Rust ne serait pas capable de faire cela si le type de nombre était déterminé uniquement à l’exécution ; car le compilateur deviendrait plus complexe et nous donnerait moins de garanties sur le code s’il devait prendre en compte tous les types hypothétiques pour une variable.
Les répétitions avec les boucles
Il est parfois utile d’exécuter un bloc de code plus d’une seule fois. Dans ce but, Rust propose plusieurs types de boucles, qui parcourt le code à l’intérieur du corps de la boucle jusqu’à la fin et recommence immédiatement du début. Pour tester les boucles, créons un nouveau projet appelé loops.
Rust a trois types de boucles : loop, while, et for. Essayons chacune d’elles.
Répéter du code avec loop
Le mot-clé loop demande à Rust d’exécuter un bloc de code encore et encore jusqu’à l’infini ou jusqu’à ce que vous lui demandiez explicitement de s’arrêter.
Par exemple, changez le fichier src/main.rs dans votre répertoire loops comme ceci :
Fichier : src/main.rs
fn main() {
loop {
println!("À nouveau !");
}
}Quand nous exécutons ce programme, nous voyons À nouveau ! s’afficher encore et encore en continu jusqu’à ce qu’on arrête le programme manuellement. La plupart des terminaux utilisent un raccourci clavier, ctrl-c, pour arrêter un programme qui est bloqué dans une boucle infinie. Essayons cela :
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
À nouveau !
À nouveau !
À nouveau !
À nouveau !
^CÀ nouveau !
Le symbole ^C représente le moment où vous avez appuyé sur ctrl-c.
Vous devriez voir ou non le texte À nouveau ! après le ^C, en fonction de là où la boucle en était dans votre code quand elle a reçu le signal d’arrêt.
Heureusement, Rust fournit aussi un autre moyen de sortir d’une boucle en utilisant du code. Vous pouvez ajouter le mot-clé break à l’intérieur de la boucle pour demander au programme d’arrêter la boucle. Souvenez-vous que nous avions fait ceci dans le jeu de devinettes, dans la section “Arrêter le programme après avoir gagné” du chapitre 2 afin de quitter le programme quand l’utilisateur gagne le jeu en devinant le bon nombre.
Nous avons également continue dans le jeu du plus ou du moins qui, dans une boucle, demande au programme de sauter le code restant dans cette itération de la boucle et de passer directement à la prochaine itération.
Retourner des valeurs d’une boucle
L’une des utilisations d’une boucle loop est de réessayer une opération qui peut échouer, comme vérifier si une tâche a terminé son travail. Vous aurez aussi peut-être besoin de passer le résultat de l’opération au reste de votre code à l’extérieur de cette boucle. Pour ce faire, vous pouvez ajouter la valeur que vous voulez retourner après l’expression break que vous utilisez pour stopper la boucle ; cette valeur sera retournée à l’extérieur de la boucle pour que vous puissiez l’utiliser, comme ci-dessous :
fn main() {
let mut compteur = 0;
let resultat = loop {
compteur += 1;
if compteur == 10 {
break compteur * 2;
}
};
println!("Le résultat est {resultat}");
}Avant la boucle, nous déclarons une variable avec le nom compteur et nous l’initialisons à 0. Ensuite, nous déclarons une variable resultat pour stocker la valeur retournée de la boucle. À chaque itération de la boucle, nous ajoutons 1 à la variable compteur, et ensuite nous vérifions si le compteur est égal à 10. Lorsque c’est le cas, nous utilisons le mot-clé break avec la valeur compteur * 2. Après la boucle, nous utilisons un point-virgule pour terminer l’instruction qui assigne la valeur à resultat. Enfin, nous affichons la valeur de resultat, qui est 20 dans ce cas-ci.
Vous pouvez également utiliser l’instruction return à l’intérieur d’une boucle. Alors que l’instruction break se contente de sortir de la boucle courante, return sort toujours de la fonction en cours.
Lever des ambiguïtés à l’aide d’étiquettes de boucles
Si vous avez des boucles imbriquées dans d’autres boucles, break et continue s’appliquent uniquement à la boucle au plus bas niveau. Si vous en avez besoin, vous pouvez associer une etiquette de boucle à une boucle que nous pouvons ensuite utiliser en association avec break ou continue pour préciser que ces mot-clés s’appliquent sur la boucle correspondant à l’étiquette plutôt qu’à la boucle la plus proche possible. Voici un exemple avec deux boucles imbriquées :
fn main() {
let mut compteur = 0;
'increment: loop {
println!("compteur = {compteur}");
let mut restant = 10;
loop {
println!("restant = {restant}");
if restant == 9 {
break;
}
if compteur == 2 {
break 'increment;
}
restant -= 1;
}
compteur += 1;
}
println!("Fin du compteur = {compteur}");
}La boucle la plus à l’extérieur a l’étiquette increment, et elle va incrémenter de 0 à 2. La boucle à l’intérieur n’a pas d’étiquette et va décrementer de 10 à 9. Le premier break qui ne précise pas d’étiquette va arrêter uniquement la boucle interne. L’instruction break 'increment; va arrêter la boucle la plus à l’extérieur. Ce code va afficher :
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
compteur = 0
restant = 10
restant = 9
compteur = 1
restant = 10
restant = 9
compteur = 2
restant = 10
Fin du compteur = 2
Les boucles conditionnelles avec while
Un programme a souvent besoin d’évaluer une condition dans une boucle. Tant que la condition est vraie, la boucle tourne. Quand la condition arrête d’être vraie, le programme appelle break, ce qui arrête la boucle. Il est possible d’implémenter un comportement comme celui-ci en combinant loop, if, else et break ; vous pouvez essayer de le faire, si vous voulez. Cependant, cette utilisation est si fréquente que Rust a une construction pour cela, intégrée dans le langage, qui s’appelle une boucle while. Dans l’encart 3-3, nous utilisons while pour boucler trois fois, en décrémentant à chaque fois, et ensuite, après la boucle, il va afficher un message et se fermer.
fn main() {
let mut nombre = 3;
while nombre != 0 {
println!("{nombre} !");
nombre -= 1;
}
println!("DÉCOLLAGE !!!");
}while loop to run code while a condition evaluates to trueCette construction élimine beaucoup d’imbrications qui seraient nécessaires si vous utilisiez loop, if, else et break, et c’est aussi plus clair. Tant que la condition est vraie, le code est exécuté ; sinon, il quitte la boucle.
Boucler dans une collection avec for
Vous pouvez choisir d’utiliser la construction while pour itérer sur les éléments d’une collection, comme les tableaux. Par exemple, la boucle dans l’encart 3-4 affiche chaque élément présent dans le tableau a.
fn main() {
let a = [10, 20, 30, 40, 50];
let mut indice = 0;
while indice < 5 {
println!("La valeur est : {}", a[indice]);
indice += 1;
}
}while loopIci, le code parcourt le tableau élément par élément. Il commence à l’indice 0, et ensuite boucle jusqu’à ce qu’il atteigne l’indice final du tableau (ce qui correspond au moment où la condition index < 5 n’est plus vraie). Exécuter ce code va afficher chaque élément du tableau :
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
La valeur est : 10
La valeur est : 20
La valeur est : 30
La valeur est : 40
La valeur est : 50
Les cinq valeurs du tableau s’affichent toutes dans le terminal, comme attendu. Même si indice va atteindre la valeur 5 à un moment, la boucle arrêtera de s’exécuter avant d’essayer de récupérer une sixième valeur du tableau.
Cependant, cette approche pousse à l’erreur ; nous pourrions faire paniquer le programme si la valeur de l’indice est trop grand ou que la condition du test est incorrecte. Par exemple, si vous changez la définition du tableau a pour avoir quatre éléments, mais que nous oublions de modifier la condition dans while indice < 4, le code paniquera. De plus, c’est lent, car le compilateur ajoute du code pour effectuer à l’exécution la vérification que l’indice est compris dans les limites du tableau, et cela à chaque itération de la boucle.
Pour une alternative plus concise, vous pouvez utiliser une boucle for et exécuter du code pour chaque élément dans une collection. Une boucle for s’utilise comme dans le code de l’encart 3-5.
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("La valeur est : {element}");
}
}for loopLorsque nous exécutons ce code, nous obtenons les mêmes messages que dans l’encart 3-4. Mais ce qui est plus important, c’est que nous avons amélioré la sécurité de notre code et éliminé le risque de bogues qui pourraient survenir si on dépassait la fin du tableau, ou si on n’allait pas jusqu’au bout et qu’on ratait quelques éléments.
En utilisant la boucle for, vous n’aurez pas à vous rappeler de changer le code si vous changez le nombre de valeurs dans le tableau, comme vous devriez le faire dans la méthode utilisée dans l’encart 3-4.
La sécurité et la concision de la boucle for en font la construction de boucle la plus utilisée avec Rust. Même dans des situations dans lesquelles vous voudriez exécuter du code plusieurs fois, comme l’exemple du décompte qui utilisait une boucle while dans l’encart 3-3, la plupart des Rustacés utiliseraient une boucle for. Il faut pour cela utiliser un intervalle Range, fourni par la bibliothèque standard pour générer dans l’ordre tous les nombres compris entre un certain nombre et un autre nombre.
Voici ce que le décompte aurait donné en utilisant une boucle for et une autre méthode que nous n’avons pas encore vue, rev, qui inverse l’intervalle :
Fichier : src/main.rs
fn main() {
for nombre in (1..4).rev() {
println!("{nombre} !");
}
println!("DÉCOLLAGE !!!");
}Ce code est un peu plus sympa, non ?
Résumé
Vous y êtes arrivé ! C’était un chapitre important : vous avez appris les variables, les types scalaires et composés, les fonctions, les commentaires, les expressions if, et les boucles ! Pour pratiquer un peu les concepts abordés dans ce chapitre, voici quelques programmes que vous pouvez essayer de créer :
- Convertir des températures entre les degrés Fahrenheit et Celsius.
- Générer le n-ième nombre de Fibonacci.
- Afficher les paroles de la chanson de Noël “The Twelve Days of Christmas” en profitant de l’aspect répétitif de la chanson.
Quand vous serez prêt à aller plus loin, nous aborderons une notion de Rust qui n’existe pas dans les autres langages de programmation : la possession (ownership).
Comprendre la possession
La possession (ownership) est la fonctionnalité la plus remarquable de Rust, et a des implications en profondeur dans l’ensemble du langage. Elle permet à Rust de garantir la sécurité de la mémoire sans avoir besoin d’un ramasse-miettes (garbage collector), donc il est important de comprendre comment la possession fonctionne. Dans ce chapitre, nous aborderons la possession, ainsi que d’autres fonctionnalités associées : l’emprunt, les slices et la façon dont Rust agence les données en mémoire.
Qu'est-ce que la possession ?
Qu’est-ce que la possession ?
La possession est un jeu de règles qui gouvernent la gestion de la mémoire par un programme Rust. Tous les programmes doivent gérer la façon dont ils utilisent la mémoire lorsqu’ils s’exécutent. Certains langages ont un ramasse-miettes qui scrute régulièrement la mémoire qui n’est plus utilisée pendant qu’il s’exécute ; dans d’autres langages, le développeur doit explicitement allouer et libérer la mémoire. Rust adopte une troisième approche : la mémoire est gérée avec un système de possession qui repose sur un jeu de règles que le compilateur vérifie au moment de la compilation. Si une de ces règles a été enfreinte, le programme ne sera pas compilé. Aucune des fonctionnalités de la possession ne ralentit votre programme à l’exécution.
Comme la possession est un nouveau principe pour de nombreux développeurs, cela prend un certain temps pour s’y familiariser. La bonne nouvelle est que plus vous devenez expérimenté avec Rust et ses règles de possession, plus vous développerez naturellement et facilement du code sûr et efficace. Gardez bien cela à l’esprit !
Lorsque vous comprendrez la possession, vous aurez des bases solides pour comprendre les fonctionnalités qui font la particularité de Rust. Dans ce chapitre, vous allez apprendre la possession en pratiquant avec plusieurs exemples qui se concentrent sur une structure de données très courante : les chaînes de caractères.
La pile et le tas
De nombreux langages ne nécessitent pas de se préoccuper de la pile (stack) et du tas (heap). Mais dans un langage de programmation système comme Rust, le fait qu’une donnée soit sur la pile ou sur le tas a une influence sur le comportement du langage et explique pourquoi nous devons faire certains choix. Nous décrirons plus loin dans ce chapitre comment la possession fonctionne vis-à-vis de la pile et du tas, voici donc une brève explication au préalable.
La pile et le tas sont tous les deux des emplacements de la mémoire à disposition de votre code lors de son exécution, mais sont organisés de façon différente. La pile enregistre les valeurs dans l’ordre dans lequel elle les reçoit et enlève les valeurs dans l’autre sens. C’est ce que l’on appelle le principe de dernier entré, premier sorti (d’où l’acronyme anglais LIFO pour : _last in, first out). C’est comme une pile d’assiettes : quand vous ajoutez des nouvelles assiettes, vous les déposez sur le dessus de la pile, et quand vous avez besoin d’une assiette, vous en prenez une sur le dessus. Ajouter ou enlever des assiettes au milieu ou en bas ne serait pas aussi efficace ! Ajouter une donnée sur la pile se dit empiler et en retirer une se dit dépiler. Toutes donnée stockée dans la pile doit avoir une taille connue et fixe. Les données avec une taille inconnue au moment de la compilation ou une taille qui peut changer doivent plutôt être stockées sur le tas.
Le tas est moins bien organisé : lorsque vous ajoutez des données sur le tas, vous demandez une certaine quantité d’espace mémoire. Le gestionnaire de mémoire va trouver un emplacement dans le tas qui est suffisamment grand, va le marquer comme étant en cours d’utilisation, et va retourner un pointeur, qui est l’adresse de cet emplacement. Cette procédure est appelée allocation sur le tas, ce qu’on abrège parfois en allocation tout court (l’ajout de valeurs sur la pile n’est pas considéré comme une allocation). Comme le pointeur vers le tas a une taille connue et fixe, on peut stocker ce pointeur sur la pile, mais quand on veut la vraie donnée, il faut suivre le pointeur. C’est comme si vous vouliez manger au restaurant. Quand vous entrez, vous indiquez le nombre de personnes dans votre groupe, le personnel trouve une table vide qui peut recevoir tout le monde, et vous y conduit. Si quelqu’un dans votre groupe arrive en retard, il peut leur demander où vous êtes assis pour vous rejoindre.
Empiler sur la pile est plus rapide qu’allouer sur le tas car le gestionnaire ne va jamais avoir besoin de chercher un emplacement pour y stocker les nouvelles données ; il le fait toujours au sommet de la pile. En comparaison, allouer de la place sur le tas demande plus de travail, car le gestionnaire doit d’abord trouver un espace assez grand pour stocker les données et mettre à jour son suivi pour préparer la prochaine allocation.
Accéder à des données dans le tas est généralement plus lent que d’accéder aux données sur la pile car nous devons suivre un pointeur pour les obtenir. Les processeurs modernes sont plus rapides s’ils se déplacent moins dans la mémoire. Pour continuer avec notre analogie, imaginez un serveur dans un restaurant qui prend les commandes de nombreuses tables. C’est plus efficace de récupérer toutes les commandes à une seule table avant de passer à la table suivante. Prendre une commande à la table A, puis prendre une commande à la table B, puis ensuite une autre à la table A, puis une autre à la table B serait un processus bien plus lent. De la même manière, un processeur sera généralement plus efficace dans sa tâche s’il travaille sur des données qui sont proches les unes des autres (comme c’est le cas sur la pile) plutôt que si elles sont plus éloignées (comme cela peut être le cas sur le tas).
Quand notre code utilise une fonction, les valeurs passées à la fonction (incluant, potentiellement, des pointeurs de données sur le tas) et les variables locales à la fonction sont déposées sur la pile. Quand l’utilisation de la fonction est terminée, ces données sont retirées de la pile.
La possession nous aide à ne pas nous préoccuper de faire attention à quelles parties du code utilisent quelles données sur le tas, de minimiser la quantité de données en double sur le tas, ou encore de veiller à libérer les données inutilisées sur le tas pour que nous ne soyons pas à court d’espace. Quand vous aurez compris la possession, vous n’aurez plus besoin de vous préoccuper de la pile et du tas très souvent. Mais savoir que le but principal de la possession est de gérer les données du tas peut vous aider à comprendre pourquoi elle fonctionne de cette manière.
Les règles de la possession
Tout d’abord, définissons les règles de la possession. Gardez à l’esprit ces règles pendant que nous travaillons sur des exemples qui les illustrent :
- Chaque valeur en Rust a un propriétaire.
- Il ne peut y avoir qu’un seul propriétaire à la fois.
- Quand le propriétaire sort de la portée, la valeur est supprimée.
Portée de la variable
Maintenant que nous avons vu la syntaxe Rust de base, nous n’allons plus ajouter tout le code du style fn main() { dans les exemples, donc si vous voulez reproduire les exemples, assurez-vous de les placer manuellement dans une fonction main. Par conséquent, nos exemples seront plus concis, nous permettant de nous concentrer sur les détails de la situation plutôt que sur du code normalisé.
Pour le premier exemple de possession, nous allons analyser la portée de certaines variables. Une portée est une zone dans un programme dans laquelle un élément est en vigueur. Admettons la variable suivante :
#![allow(unused)]
fn main() {
let s = "hello";
}La variable s fait référence à un littéral de chaîne de caractères, dont la valeur est codée en dur dans le code source de notre programme. La variable est valide à partir du moment où elle est déclarée jusqu’à la fin de la portée actuelle. L’encart 4-1 montre un programme avec des commentaires indiquant où la variable s est valide.
fn main() {
{ // s n'est pas en vigueur ici, car elle n'est pas encore déclarée
let s = "hello"; // s est en vigueur à partir de ce point
// on fait des choses avec s ici
} // cette portée est maintenant terminée, et s n'est plus en vigueur
}Autrement dit, il y a ici deux étapes importantes :
- Quand
srentre dans la portée, elle est en vigueur. - Cela reste ainsi jusqu’à ce qu’elle sorte de la portée.
Pour le moment, la relation entre les portées et les conditions pour lesquelles les variables sont en vigueur sont similaires à d’autres langages de programmation. Maintenant, nous allons aller plus loin en y ajoutant le type String.
Le type String
Pour illustrer les règles de la possession, nous avons besoin d’un type de donnée qui est plus complexe que ceux que nous avons rencontrés dans la section “Types de données” du chapitre 3. Les types que nous avons vus précédemment ont tous une taille connue et peuvent être stockés sur la pile ainsi que retirés de la pile lorsque la portée n’en a plus besoin, et peuvent aussi être rapidement et facilement copiés afin de constituer une nouvelle instance indépendante si une autre partie du code a besoin d’utiliser la même valeur dans une portée différente. Mais nous voulons expérimenter le stockage de données sur le tas et découvrir comment Rust sait quand il doit nettoyer ces données, et le type String est un bon exemple.
Nous allons nous concentrer sur les caractéristiques de String qui sont liées à la possession. Ces aspects s’appliquent également à d’autres types de données complexes, qu’ils soient fournis par la bibliothèque standard ou qu’ils soient créés par vous. Nous aborderons les aspects liés à la non-possession de String au chapitre 8.
Nous avons déjà vu les littéraux de chaînes de caractères, quand une valeur de chaîne est codée en dur dans notre programme. Les littéraux de chaînes sont pratiques, mais ils ne conviennent pas toujours à tous les cas où on veut utiliser du texte. Une des raisons est qu’ils sont immuables. Une autre raison est qu’on ne connaît pas forcément le contenu des chaînes de caractères quand nous écrivons notre code : par exemple, comment faire si nous voulons récupérer du texte saisi par l’utilisateur et l’enregistrer ? C’est pour ces cas-ci que Rust a un second type de chaîne de caractères, String. Ce type gère ses données sur le tas et est ainsi capable de stocker une quantité de texte qui nous est inconnue au moment de la compilation. Vous pouvez créer une String à partir d’un littéral de chaîne de caractères en utilisant la fonction from, comme ceci :
#![allow(unused)]
fn main() {
let s = String::from("hello");
}L’opérateur double deux-points :: nous permet d’appeler cette fonction spécifique dans l’espace de nom du type String plutôt que d’utiliser un nom comme string_from. Nous verrons cette syntaxe plus en détail dans la section “Méthodes” du chapitre 5 et lorsque nous aborderons les espaces de noms dans la section “Les chemins pour désigner un élément dans l’arborescence de module” du chapitre 7.
Ce type de chaîne de caractères peut être mutable :
fn main() {
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() ajoute un littéral de chaîne dans une String
println!("{s}"); // Cela va afficher `hello, world!`
}Donc, quelle est la différence ici ? Pourquoi String peut être mutable, mais pourquoi les littéraux de chaînes ne peuvent pas l’être ? La différence se trouve dans la façon dont ces deux types travaillent avec la mémoire.
Mémoire et allocation
Dans le cas d’un littéral de chaîne de caractères, nous connaissons le contenu au moment de la compilation donc le texte est codé en dur directement dans l’exécutable final. Voilà pourquoi ces littéraux de chaînes de caractères sont performants et rapides. Mais ces caractéristiques viennent de leur immuabilité. Malheureusement, on ne peut pas accorder une grosse région de mémoire dans le binaire pour chaque morceau de texte qui n’a pas de taille connue au moment de la compilation et dont la taille pourrait changer pendant l’exécution de ce programme.
Avec le type String, pour nous permettre d’avoir un texte mutable et qui peut s’agrandir, nous devons allouer une quantité de mémoire sur le tas, inconnue au moment de la compilation, pour stocker le contenu. Cela signifie que :
- La mémoire doit être demandée auprès du gestionnaire de mémoire lors de l’exécution.
- Nous avons besoin d’un moyen de rendre cette mémoire au gestionnaire lorsque nous aurons fini d’utiliser notre
String.
Nous nous occupons de ce premier point : quand nous appelons String::from, son implémentation demande la mémoire dont elle a besoin. C’est pratiquement toujours ainsi dans la majorité des langages de programmation.
Cependant, le deuxième point est différent. Dans des langages avec un ramasse-miettes, le ramasse-miettes surveille et nettoie la mémoire qui n’est plus utilisée, sans que nous n’ayons à nous en préoccuper. Dans la plupart des langages sans ramasse-miettes, c’est de notre responsabilité d’identifier quand cette mémoire n’est plus utilisée et d’appeler du code pour explicitement la libérer, comme nous l’avons fait pour la demander auparavant. Historiquement, faire ceci correctement a toujours été une difficulté pour les développeurs. Si nous oublions de le faire, nous allons gaspiller de la mémoire. Si nous le faisons trop tôt, nous allons avoir une variable invalide. Si nous le faisons deux fois, cela produit aussi un bogue. Nous devons associer exactement un allocate avec exactement un free.
Rust prend un chemin différent : la mémoire est automatiquement libérée dès que la variable qui la possède sort de la portée. Voici une version de notre exemple de portée de l’encart 4-1 qui utilise une String plutôt qu’un littéral de chaîne de caractères :
fn main() {
{
let s = String::from("hello"); // s est en vigueur à partir de ce point
// on fait des choses avec s ici
} // cette portée est désormais terminée, et s
// n'est plus en vigueur maintenant
}Il y a un moment naturel où nous devons rendre la mémoire de notre String au gestionnaire : quand s sort de la portée. Quand une variable sort de la portée, Rust appelle une fonction spéciale pour nous. Cette fonction s’appelle drop, et c’est dans celle-ci que l’auteur de String a pu mettre le code pour libérer la mémoire. Rust appelle automatiquement drop à l’accolade fermante }.
Remarque : en C++, cette façon de libérer des ressources à la fin de la durée de vie d’un élément est parfois appelée l’acquisition d’une ressource est une initialisation (Resource Acquisition Is Initialization : RAII). La fonction drop de Rust vous sera familière si vous avez déjà utilisé des techniques de RAII.
Cette façon de faire a un impact profond sur la façon dont le code Rust est écrit. Cela peut sembler simple dans notre cas, mais le comportement du code peut être surprenant dans des situations plus compliquées où nous voulons avoir plusieurs variables utilisant des données que nous avons affectées sur le tas. Examinons une de ces situations dès à présent.
Les interactions entre les variables et les données : le déplacement
Plusieurs variables peuvent interagir avec les mêmes données de différentes manières en Rust. Regardons un exemple avec un entier dans l’encart 4-2 :
fn main() {
let x = 5;
let y = x;
}x to yNous pouvons probablement deviner ce que ce code fait : “Assigner la valeur 5 à x ; ensuite faire une copie de cette valeur de x et l’assigner à y.” Nous avons maintenant deux variables, x et y, et chacune vaut 5. C’est effectivement ce qui se passe, car les entiers sont des valeurs simples avec une taille connue et fixée, et ces deux valeurs 5 sont stockées sur la pile.
Maintenant, essayons une nouvelle version avec String :
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}Cela ressemble beaucoup, donc nous allons supposer que cela fonctionne pareil que précédemment : ainsi, la seconde ligne va faire une copie de la valeur de s1 et l’assigner à s2. Mais ce n’est pas tout à fait ce qui se passe.
Regardons l’illustration 4-1 pour découvrir ce qui arrive à String sous le capot. Une String est constituée de trois éléments, présents sur la gauche : un pointeur vers la mémoire qui contient le contenu de la chaîne de caractères, une taille, et une capacité. Ce groupe de données est stocké sur la pile. À droite, nous avons la mémoire sur le tas qui contient les données.

Illustration 4-1 : Représentation en mémoire d’une String qui contient la valeur "hello" assignée à s1.
La taille est la quantité de mémoire, en octets, que le contenu de la String utilise actuellement. La capacité est la quantité totale de mémoire, en octets, que la String a reçue du gestionnaire. La notion de différence entre la taille et la capacité est importante, mais pas pour notre exemple, donc pour l’instant, ce n’est pas grave d’ignorer la capacité.
Quand nous assignons s1 à s2, les données de la String sont copiées, ce qui veut dire que nous copions le pointeur, la taille et la capacité qui sont stockés sur la pile. Nous ne copions pas les données stockées sur le tas auxquelles le pointeur se réfère. Autrement dit, la représentation des données dans la mémoire ressemble à l’illustration 4-2.

Illustration 4-2 : Représentation en mémoire de la variable s2 qui a une copie du pointeur, de la taille et de la capacité de s1
Cette représentation n’est pas comme l’illustration 4-3, qui représenterait la mémoire si Rust avait aussi copié les données sur le tas. Si Rust faisait ceci, l’opération s2 = s1 pourrait potentiellement être très coûteuse en termes de performances d’exécution si les données sur le tas étaient volumineuses.
Quatre tables : deux tables représentant les données de la pile pour s1 et s2, chacune pointant vers sa propre copie des données de chaîne de caractères dans le tas
Illustration 4-3 : une autre possibilité de ce que pourrait faire s2 = s1 si Rust copiait aussi les données du tas
Précédemment, nous avons dit que quand une variable sortait de la portée, Rust appelait automatiquement la fonction drop et nettoyait la mémoire sur le tas allouée pour cette variable. Mais l’illustration 4-2 montre que les deux pointeurs de données pointeraient au même endroit. C’est un problème : quand s2 et s1 sortent de la portée, elles vont essayer toutes les deux de libérer la même mémoire. C’est ce qu’on appelle une erreur de double libération et c’est un des bogues de sécurité de mémoire que nous avons mentionnés précédemment. Libérer la mémoire deux fois peut mener à des corruptions de mémoire, ce qui peut potentiellement mener à des vulnérabilités de sécurité.
Pour garantir la sécurité de la mémoire, après la ligne let s2 = s1, Rust considère que s1 n’est plus en vigueur. Par conséquent, Rust n’a pas besoin de libérer quoi que ce soit lorsque s1 sort de la portée. Regardez ce qui se passe quand vous essayez d’utiliser s1 après que s2 est créé, cela ne va pas fonctionner :
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}Vous allez avoir une erreur comme celle-ci, car Rust vous défend d’utiliser la référence qui n’est plus en vigueur :
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:16
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Si vous avez déjà entendu parler de copie superficielle et de copie profonde en utilisant d’autres langages, l’idée de copier le pointeur, la taille et la capacité sans copier les données peut vous faire penser à de la copie superficielle. Mais comme Rust neutralise aussi la première variable, au lieu d’appeler cela une copie superficielle, on appelle cela un déplacement. Ici, nous pourrions dire que s1 a été déplacé dans s2. Donc ce qui se passe réellement est décrit par l’illustration 4-4.

Illustration 4-4 : Représentation de la mémoire après que s1 a été neutralisée
Cela résout notre problème ! Avec seulement s2 en vigueur, quand elle sortira de la portée, elle seule va libérer la mémoire, et c’est tout.
De plus, cela signifie qu’il y a eu un choix de conception : Rust ne va jamais créer automatiquement de copie “profonde” de vos données. Par conséquent, toute copie automatique peut être considérée comme peu coûteuse en termes de performances d’exécution.
Portée et affectation
Le contraire est également vrai pour la relation entre la portée, la propriété et la libération de la mémoire via la fonction drop. Lorsque vous attribuez une valeur entièrement nouvelle à une variable existante, Rust appelle drop et libère immédiatement la mémoire occupée par la valeur d’origine. Prenons par exemple le code suivant :
fn main() {
let mut s = String::from("hello");
s = String::from("ahoy");
println!("{s}, world!");
}Nous déclarons d’abord une variable s et l’associons à une chaîne String avec la valeur "hello". Ensuite, nous créons immédiatement une nouvelle chaîne String avec la valeur "ahoy" et l’attribuons à s. À ce stade, absolument plus rien ne fait référence à la valeur d’origine sur le tas. La figure 4-5 illustre les données de la pile et du tas à ce moment-là :

Illustration 4-5 : Représentation de la mémoire après que la valeur initiale a été entièrement remplacée
La chaîne originale sort donc immédiatement de la portée. Rust exécutera la fonction drop sur celle-ci et sa mémoire sera libérée tout de suite. Quand nous affichons la valeur à la fin, ce sera "ahoy, world!"
Les interactions entre les variables et les données : le clonage
Si nous voulons faire une copie profonde des données sur le tas d’une String, et pas seulement des données sur la pile, nous pouvons utiliser une méthode commune qui s’appelle clone. Nous aborderons la syntaxe des méthodes au chapitre 5, mais comme les méthodes sont des outils courants dans de nombreux langages, vous les avez probablement utilisées auparavant.
Voici un exemple d’utilisation de la méthode clone :
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {s1}, s2 = {s2}");
}Cela fonctionne très bien et c’est ainsi que vous pouvez reproduire le comportement décrit dans l’illustration 4-3, où les données du tas sont copiées.
Quand vous voyez un appel à clone, vous savez que du code arbitraire est exécuté et que ce code peut être coûteux. C’est un indicateur visuel qu’il se passe quelque chose de différent.
Données uniquement sur la pile : la copie
Il y a un autre détail dont on n’a pas encore parlé. Le code suivant utilise des entiers - on en a vu une partie dans l’encart 4-2 - il fonctionne et est correct :
fn main() {
let x = 5;
let y = x;
println!("x = {x}, y = {y}");
}Mais ce code semble contredire ce que nous venons d’apprendre : nous n’avons pas appelé clone, mais x est toujours en vigueur et n’a pas été déplacé dans y.
La raison est que les types comme les entiers ont une taille connue au moment de la compilation et sont entièrement stockés sur la pile, donc la copie des vraies valeurs est rapide à faire. Cela signifie qu’il n’y a pas de raison pour laquelle nous voudrions neutraliser x après avoir créé la variable y. En d’autres termes, il n’y a pas ici de différence entre la copie superficielle et profonde, donc appeler clone ne ferait rien d’autre qu’une copie superficielle classique et on peut s’en passer.
Rust a une annotation spéciale appelée le trait Copy que nous pouvons utiliser sur des types comme les entiers qui sont stockés sur la pile (nous verrons les traits dans le chapitre 10). Si un type implémente le trait Copy, les variables qui l’utilisent ne sont pas déplacées, mais simplement copiées, ce qui les rend toujours valides après leur affectation à une autre variable.
Rust ne nous autorisera pas à annoter un type avec le trait Copy si ce type, ou un de ses éléments, a implémenté le trait Drop. Si ce type a besoin que quelque chose de spécial se produise quand la valeur sort de la portée et que nous ajoutons l’annotation Copy sur ce type, nous aurons une erreur au moment de la compilation. Pour savoir comment ajouter l’annotation Copy sur votre type pour implémenter le trait, référez-vous à l’annexe C sur les traits dérivables.
Donc, quels sont les types qui implémentent le trait Copy ? Vous pouvez regarder dans la documentation pour un type donné pour vous en assurer, mais de manière générale, tout groupe de valeurs scalaires peut implémenter Copy, et rien de ce qui nécessite une allocation de mémoire ou qui est une forme de ressource ne peut implémenter Copy. Voici quelques types qui implémentent Copy` :
- Tous les types d’entiers, comme
u32. - Le type booléen,
bool, avec les valeurstrueetfalse. - Tous les types de flottants, comme
f64. - Le type caractère,
char. - Les tuples, mais uniquement s’ils contiennent des types qui implémentent aussi
Copy. Par exemple, le(i32, i32)implémenteCopy, mais pas(i32, String).
La possession et les fonctions
La mécanique pour passer une valeur à une fonction est similaire à celle pour assigner une valeur à une variable. Passer une variable à une fonction va la déplacer ou la copier, comme l’assignation. L’encart 4-3 est un exemple avec quelques commentaires qui montrent où les variables rentrent et sortent de la portée :
fn main() {
let s = String::from("hello"); // s rentre dans la portée.
prendre_possession(s); // La valeur de s est déplacée dans la fonction…
// … et n'est plus en vigueur à partir d'ici
let x = 5; // x rentre dans la portée.
creer_copie(x); // Comme i32 implémente le trait Copy,
// x n'est PAS déplacée dans la fonction,
// donc on peut continuer d'utiliser x ensuite.
} // Ici, x sort de la portée, puis ensuite s. Toutefois, puisque la valeur de
// s a été déplacée, il ne se passe rien de spécial.
fn prendre_possession(texte: String) { // texte rentre dans la portée.
println!("{texte}");
} // Ici, texte sort de la portée et `drop` est appelé. La mémoire est libérée.
fn creer_copie(entier: i32) { // entier rentre dans la portée.
println!("{entier}");
} // Ici, entier sort de la portée. Il ne se passe rien de spécial.Si on essayait d’utiliser s après l’appel à prendre_possession, Rust déclencherait une erreur à la compilation. Ces vérifications statiques nous protègent des erreurs. Essayez d’ajouter du code au main qui utilise s et x pour découvrir lorsque vous pouvez les utiliser et lorsque les règles de la possession vous empêchent de le faire.
Les valeurs de retour et les portées
Retourner des valeurs peut aussi transférer leur possession. L’encart 4-4 montre un exemple d’une fonction qui retourne une valeur, avec des annotations similaires à celles de l’encart 4-3 :
fn main() {
let s1 = donne_possession(); // donne_possession déplace sa valeur de
// retour dans s1
let s2 = String::from("hello"); // s2 rentre dans la portée
let s3 = prend_et_rend(s2); // s2 est déplacée dans
// prend_et_rend, qui elle aussi
// déplace sa valeur de retour dans s3.
} // Ici, s3 sort de la portée et est éliminée. s2 a été déplacée donc il ne se
// passe rien. s1 sort aussi de la portée et est éliminée.
fn donne_possession() -> String { // donne_possession va déplacer sa
// valeur de retour dans la
// fonction qui l'appelle.
let texte = String::from("yours"); // texte rentre dans la portée.
texte // texte est retournée et
// est déplacée vers le code qui
// l'appelle.
}
// Cette fonction va prendre une String et retourne aussi une String.
fn prend_et_rend(texte: String) -> String {
// texte rentre dans
// la portée.
texte // texte est retournée et déplacée vers le code qui l'appelle.
}La possession d’une variable suit toujours le même schéma à chaque fois : assigner une valeur à une autre variable la déplace. Quand une variable qui contient des données sur le tas sort de la portée, la valeur sera nettoyée avec drop à moins que la possession de cette donnée soit donnée à une autre variable.
Même si cela fonctionne, il est un peu fastidieux de prendre la possession puis ensuite de retourner la possession à chaque fonction. Et que se passe-t-il si nous voulons qu’une fonction utilise une valeur, mais n’en prenne pas possession ? C’est assez pénible que tout ce que nous passons doive être retourné si nous voulons l’utiliser à nouveau, en plus de toutes les données qui découlent du corps de la fonction que nous voulons aussi récupérer.
Rust nous permet de retourner plusieurs valeurs à l’aide d’un tuple, comme ceci :
fn main() {
let s1 = String::from("hello");
let (s2, taille) = calculer_taille(s1);
println!("La taille de '{s2}' est {taille}.");
}
fn calculer_taille(s: String) -> (String, usize) {
let taille = s.len(); // len() retourne la taille d'une String.
(s, taille)
}Mais c’est trop laborieux et beaucoup de travail pour un principe qui devrait être banal. Heureusement pour nous, Rust a une fonctionnalité pour utiliser une valeur sans avoir à transférer la possession : les références.
Les références et l'emprunt
Les références et l’emprunt
La difficulté avec le code du tuple à la fin de la section précédente est que nous avons besoin de retourner la String au code appelant pour qu’il puisse continuer à utiliser la String après l’appel à calculer_taille, car la String a été déplacée dans calculer_taille. À la place, nous pouvons fournir une référence à la valeur de la String. Une référence est comme un pointeur dans le sens où c’est une adresse que nous pouvons suivre pour accéder à la donnée stockée à cette adresse ; cette donnée est possédée par une autre variable. Mais contrairement aux pointeurs, une référence garantit de pointer vers une valeur en vigueur, d’un type bien déterminé, pour la durée de vie de cette référence.
Voici comment définir et utiliser une fonction calculer_taille qui prend une référence à un objet en paramètre plutôt que de prendre possession de la valeur :
fn main() {
let s1 = String::from("hello");
let long = calculer_taille(&s1);
println!("La taille de '{s1}' est {long}.");
}
fn calculer_taille(s: &String) -> usize {
s.len()
}Premièrement, on peut observer que tout le code des tuples dans la déclaration des variables et dans la valeur de retour de la fonction a été enlevé. Deuxièmement, remarquez que nous passons &s1 à calculer_taille, et que dans sa définition, nous utilisons &String plutôt que String. Ces esperluettes représentent les références, et elles permettent de vous référer à une valeur sans en prendre possession. L’illustration 4-6 illustre ce concept.
<img alt=“Trois tables : la table concernant s contient seulement un pointeur vers la table concernant s1. La table concernant s1 contient les données sur la pile pour s1 et pointe vers la chaîne de caractères sur le tas.” src=“img/trpl04-06.svg” class=center“ />
Illustration 4-6 : un schéma de la &String s qui pointe vers la String s1
Remarque : l’opposé de la création de références avec & est le déréférencement, qui s’effectue avec l’opérateur de déréférencement, *. Nous allons voir quelques utilisations de l’opérateur de déréférencement dans le chapitre 8 et nous aborderons les détails du déréférencement dans le chapitre 15.
Regardons de plus près l’appel à la fonction :
fn main() {
let s1 = String::from("hello");
let long = calculer_taille(&s1);
println!("La taille de '{s1}' est {long}.");
}
fn calculer_taille(s: &String) -> usize {
s.len()
}La syntaxe &s1 nous permet de créer une référence qui se réfère à la valeur de s1 mais n’en prend pas possession. Et comme la référence ne la possède pas, la valeur vers laquelle elle pointe ne sera pas libérée quand cette référence ne sera plus utilisée.
De la même manière, la signature de la fonction utilise & pour indiquer que le type du paramètre s est une référence. Ajoutons quelques commentaires explicatifs :
fn main() {
let s1 = String::from("hello");
let long = calculer_taille(&s1);
println!("La taille de '{s1}' est {long}.");
}
fn calculer_taille(s: &String) -> usize { // s est une référence à une String
s.len()
} // Ici, s sort de la portée. Mais comme s n'a pas la possession de ce à quoi
// elle fait référence, il ne se passe rien.La portée dans laquelle la variable s est en vigueur est la même que toute portée d’un paramètre de fonction, mais la valeur pointée par la référence n’est pas libérée quand s n’est plus utilisé, car s n’en prends pas possession. Lorsque les fonctions ont des références en paramètres au lieu des valeurs réelles, nous n’avons pas besoin de retourner les valeurs pour les rendre, car nous n’en avons jamais pris possession.
Nous appelons l’emprunt l’action de créer une référence. Comme dans la vie réelle, quand un objet appartient à quelqu’un, vous pouvez le lui emprunter. Et quand vous avez fini, vous devez le lui rendre. Vous ne le possédez pas.
Donc que se passe-t-il si nous essayons de modifier quelque chose que nous empruntons ? Essayez le code dans l’encart 4-6. Attention, spoiler : cela ne fonctionne pas !
fn main() {
let s = String::from("hello");
changer(&s);
}
fn changer(texte: &String) {
texte.push_str(", world");
}Voici l’erreur :
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*texte` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | texte.push_str(", world");
| ^^^^^ `texte` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(texte: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Comme les variables sont immuables par défaut, les références le sont aussi. Nous ne sommes pas autorisés à modifier une chose quand nous avons une référence vers elle.
Les références mutables
Nous pouvons résoudre le code de l’encart 4-6 pour nous permettre de modifier une valeur empruntée avec quelques petites modifications qui utilisent plutôt une référence mutable :
fn main() {
let mut s = String::from("hello");
changer(&mut s);
}
fn changer(texte: &mut String) {
texte.push_str(", world");
}D’abord, nous précisons que s est mut. Ensuite, nous avons créé une référence mutable avec &mut s où nous appelons la fonction changer et nous avons modifié la signature pour accepter de prendre une référence mutable avec texte: &mut String. Cela précise clairement que la fonction changer va faire muter la valeur qu’elle emprunte.
Les références mutables ont une grosse contrainte : si vous avez une référence mutable pour une valeur, vous ne pouvez pas avoir d’autre référence à cette valeur. Le code suivant qui va tenter de créer deux références mutables à s va échouer :
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}Voici l’erreur :
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Cette erreur nous explique que ce code est invalide car nous ne pouvons pas emprunter s de manière mutable plus d’une fois au même moment. Le premier emprunt mutable est dans r1 et doit perdurer jusqu’à ce qu’il soit utilisé dans le println!, mais pourtant entre la création de cette référence mutable et son utilisation, nous avons essayé de créer une autre référence mutable dans r2 qui emprunte la même donnée que dans r1.
La limitation qui empêche d’avoir plusieurs références mutables vers la même donnée au même moment autorise les mutations, mais de manière très contrôlée. C’est quelque chose que les nouveaux Rustacés ont du mal à surmonter, car la plupart des langages vous permettent de modifier les données quand vous le voulez. L’avantage d’avoir cette contrainte est que Rust peut empêcher les accès concurrents au moment de la compilation. Un accès concurrent est une situation de concurrence qui se produit lorsque ces trois facteurs se combinent :
- Deux pointeurs ou plus accèdent à la même donnée au même moment.
- Au moins un des pointeurs est utilisé pour écrire dans cette donnée.
- On n’utilise aucun mécanisme pour synchroniser l’accès aux données.
L’accès concurrent provoque des comportements indéfinis et rend difficile le diagnostic et la résolution de problèmes lorsque vous essayez de les reproduire au moment de l’exécution ; Rust évite ce problème en refusant de compiler du code avec des accès concurrents !
Comme d’habitude, nous pouvons utiliser des accolades pour créer une nouvelle portée, pour nous permettre d’avoir plusieurs références mutables, mais pas en même temps :
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 sort de la portée ici, donc nous pouvons créer une nouvelle référence
// sans problème.
let r2 = &mut s;
}Rust impose une règle similaire pour combiner les références immuables et mutables. Ce code va mener à une erreur :
fn main() {
let mut s = String::from("hello");
let r1 = &s; // sans problème
let r2 = &s; // sans problème
let r3 = &mut s; // GROS PROBLÈME
println!("{r1}, {r2}, et {r3}");
}Voici l’erreur :
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // sans problème
| -- immutable borrow occurs here
5 | let r2 = &s; // sans problème
6 | let r3 = &mut s; // GROS PROBLÈME
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, et {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ah ! Nous ne pouvons pas non plus avoir une référence mutable pendant que nous en avons une autre immuable vers la même valeur.
Les utilisateurs d’une référence immuable ne s’attendent pas à ce que sa valeur change soudainement ! Cependant, l’utilisation de plusieurs références immuables ne pose pas de problème, car simplement lire une donnée ne va pas affecter la lecture de la donnée par les autres.
Notez bien que la portée d’une référence commence dès qu’elle est introduite et se poursuit jusqu’au dernier endroit où cette référence est utilisée. Par exemple, le code suivant va se compiler car la dernière utilisation de la référence immuable est dans le println! qui est situé avant l’introduction de la référence mutable :
fn main() {
let mut s = String::from("hello");
let r1 = &s; // sans problème
let r2 = &s; // sans problème
println!("{r1} et {r2}");
// Les variables r1 et r2 ne seront plus utilisés à partir d'ici.
let r3 = &mut s; // sans problème
println!("{r3}");
}Les portées des références immuables r1 et r2 se terminent après le println! où elles sont utilisées pour la dernière fois, c’est-à-dire avant que la référence mutable r3 soit créée. Ces portées ne se chevauchent pas, donc ce code est autorisé : le compilateur peut déterminer que la référence n’est plus utilisée à un moment avant la fin de la portée.
Même si ces erreurs d’emprunt peuvent parfois être frustrantes, n’oubliez pas que le compilateur de Rust nous signale un bogue potentiel en avance (au moment de la compilation plutôt que de l’exécution) et vous montre où se situe exactement le problème. Ainsi, vous n’avez pas à chercher pourquoi vos données ne correspondent pas à ce que vous pensiez qu’elles devraient être.
Les références pendouillantes
Avec les langages qui utilisent les pointeurs, il est facile de créer par erreur un pointeur pendouillant (dangling pointer), qui est un pointeur qui pointe vers un emplacement mémoire qui a été donné à quelqu’un d’autre, en libérant de la mémoire tout en conservant un pointeur vers cette mémoire. En revanche, avec Rust, le compilateur garantit que les références ne seront jamais des références pendouillantes : si nous avons une référence vers une donnée, le compilateur va s’assurer que cette donnée ne va pas sortir de la portée avant que la référence vers cette donnée en soit elle-même sortie.
Essayons de créer une référence pendouillante pour voir comment Rust va les empêcher via une erreur au moment de la compilation :
fn main() {
let reference_vers_rien = pendouille();
}
fn pendouille() -> &String {
let s = String::from("hello");
&s
}Voici l’erreur :
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn pendouille() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ce message d’erreur fait référence à une fonctionnalité que nous n’avons pas encore vue : les durées de vie. Nous aborderons les durées de vie dans le chapitre 10. Mais, si vous mettez de côté les parties qui parlent de durées de vie, le message explique pourquoi le code pose problème :
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
Ce qui peut se traduire par :
Le type de retour de cette fonction contient une valeur empruntée, mais il n'y a
aucune valeur à partir de laquelle elle peut être empruntée.
Regardons de plus près ce qui se passe exactement à chaque étape de notre code de pendouille :
fn main() {
let reference_vers_rien = pendouille();
}
fn pendouille() -> &String { // pendouille retourne une référence vers une String
let s = String::from("hello"); // s est une nouvelle String
&s // nous retournons une référence vers la String, s
} // Ici, s sort de la portée, et est libéré. Sa mémoire disparaît.
// Attention, danger !Comme s est créé dans pendouille, lorsque le code de pendouille est terminé, la variable s sera désallouée. Mais nous avons essayé de retourner une référence vers elle. Cela veut dire que cette référence va pointer vers une String invalide. Ce n’est pas bon ! Rust ne nous laissera pas faire cela.
Ici la solution est de renvoyer la String directement :
fn main() {
let chaine = ne_pendouille_pas();
}
fn ne_pendouille_pas() -> String {
let s = String::from("hello");
s
}Cela fonctionne sans problème. La possession est transférée à la valeur de retour de la fonction, et rien n’est désalloué.
Les règles de référencement
Récapitulons ce que nous avons vu à propos des références :
- À un instant donné, vous pouvez avoir soit une référence mutable, soit un nombre quelconque de références immuables.
- Les références doivent toujours être en vigueur.
Ensuite, nous aborderons un autre type de référence : les slices.
Le type slice
Le type slice
Une slice vous permet d’obtenir une référence vers une séquence continue d’éléments d’une collection. Une slice est un genre de référence, donc elle ne prend pas possession.
Voici un petit problème de programmation : écrire une fonction qui prend une chaîne de mots séparés par des espaces et retourne le premier mot qu’elle trouve dans cette chaîne. Si la fonction ne trouve pas d’espace dans la chaîne, cela veut dire que la chaîne est en un seul mot, donc la chaîne en entier doit être retournée.
Remarque : afin de simplifier l’explication des slices de chaînes, nous utiliserons uniquement l’ASCII dans cette section ; nous verrons la gestion de l’UTF-8 dans la section “Stocker du texte encodé en UTF-8 avec les chaînes de caractères” du chapitre 8.
Voyons comment écrire la signature de cette fonction sans utiliser les slices, afin de comprendre le problème que règlent les slices :
fn premier_mot(s: &String) -> ?La fonction premier_mot a un paramètre de type &String. Nous n’avons pas besoin d’en prendre possession, donc c’est ce qu’il nous faut (dans le langage Rust, les fonctions ne prennent pas possession de leurs arguments sauf si cela s’avère nécessaire ; les raisons de cette approche apparaîtront clairement au fur et à mesure que nous avancerons). Mais que devons-nous retourner ? Nous n’avons aucun moyen de désigner une partie d’une chaîne de caractères. Cependant, nous pourrions retourner l’indice de la fin du mot, qui se produit lorsqu’il y a une espace. Essayons cela, dans l’encart 4-7 :
fn premier_mot(s: &String) -> usize {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return i;
}
}
s.len()
}
fn main() {}first_word function that returns a byte index value into the String parameterComme nous avons besoin de parcourir la String élément par élément et de vérifier si la valeur est une espace, nous convertissons notre String en un tableau d’octets en utilisant la méthode as_bytes.
fn premier_mot(s: &String) -> usize {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return i;
}
}
s.len()
}
fn main() {}Ensuite, nous créons un itérateur sur le tableau d’octets en utilisant la méthode iter :
fn premier_mot(s: &String) -> usize {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return i;
}
}
s.len()
}
fn main() {}Nous aborderons plus en détail les itérateurs dans le chapitre 13. Pour le moment, sachez que iter est une méthode qui retourne chaque élément d’une collection, et que enumerate transforme le résultat de iter pour retourner plutôt chaque élément comme un tuple. Le premier élément du tuple retourné par enumerate est l’indice, et le second élément est une référence vers l’élément. C’est un peu plus pratique que de calculer les indices par nous-mêmes.
Comme la méthode enumerate retourne un tuple, nous pouvons utiliser des motifs pour déstructurer ce tuple. Nous verrons les motifs au chapitre 6. Dans la boucle for, nous précisons un motif qui indique que nous définissons i pour l’indice au sein du tuple et &element pour l’octet dans le tuple. Comme nous obtenons une référence vers l’élément avec .iter().enumerate(), nous utilisons & dans le motif.
Au sein de la boucle for, nous recherchons l’octet qui représente l’espace en utilisant la syntaxe de littéral d’octet. Si nous trouvons une espace, nous retournons sa position. Sinon, nous retournons la taille de la chaîne en utilisant s.len().
fn premier_mot(s: &String) -> usize {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return i;
}
}
s.len()
}
fn main() {}Nous avons maintenant une façon de trouver l’indice de la fin du premier mot dans la chaîne de caractères, mais il y a un problème. Nous retournons un usize tout seul, mais il n’a du sens que lorsqu’il est lié au &String. Autrement dit, comme il a une valeur séparée de la String, il n’y a pas de garantie qu’il restera toujours valide dans le futur. Imaginons le programme dans l’encart 4-8 qui utilise la fonction premier_mot de l’encart 4-7.
fn premier_mot(s: &String) -> usize {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return i;
}
}
s.len()
}
fn main() {
let mut s = String::from("hello world");
let mot = premier_mot(&s); // la variable mot aura 5 comme valeur.
s.clear(); // ceci vide la String, elle vaut maintenant "".
// mot a toujours la valeur 5 ici, mais il n'y a plus de chaîne qui donne
// du sens à la valeur 5. mot est maintenant complètement invalide !
}first_word function and then changing the String contentsCe programme se compile sans aucune erreur et le ferait toujours si nous utilisions mot après avoir appelé s.clear(). Comme mot n’est pas du tout lié à s, mot contient toujours la valeur 5. Nous pourrions utiliser cette valeur 5 avec la variable s pour essayer d’en extraire le premier mot, mais cela serait un bogue, car le contenu de s a changé depuis que nous avons enregistré 5 dans mot.
Se préoccuper en permanence que l’indice présent dans mot ne soit plus synchronisé avec les données présentes dans s est fastidieux et source d’erreur ! La gestion de ces indices est encore plus risquée si nous écrivons une fonction second_mot. Sa signature ressemblerait à ceci :
fn second_mot(s: &String) -> (usize, usize) {Maintenant, nous avons un indice de début et un indice de fin, donc nous avons encore plus de valeurs qui sont calculées à partir d’une donnée dans un état donné, mais qui ne sont pas liées du tout à l’état de cette donnée. Nous avons trois variables isolées qui ont besoin d’être maintenues à jour.
Heureusement, Rust a une solution pour ce problème : les slices de chaînes de caractères.
Les slices de chaînes de caractères
Une slice de chaîne de caractères (ou slice de chaîne) est une référence à une séquence contiguë d’éléments d’une chaîne String, et se présente ainsi :
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}Plutôt que d’être une référence vers toute la String, hello est une référence vers une partie de la String, comme indiqué dans la partie supplémentaire [0..5]. Nous créons des slices en utilisant un intervalle entre crochets en spécifiant [indice_debut..indice_fin], où indice_debut est la position du premier octet de la slice et indice_fin est la position juste après le dernier octet de la slice. En interne, la structure de données de la slice stocke la position de départ et la longueur de la slice, ce qui correspond à indice_fin moins indice_debut. Donc dans le cas de let world = &s[6..11];, world est une slice qui contient un pointeur vers le sixième octet de s et une longueur de 5.
L’illustration 4-7 montre ceci dans un schéma.

Illustration 4-7 : Une slice de chaîne qui pointe vers une partie d’une String
Avec la syntaxe d’intervalle .. de Rust, si vous voulez commencer à l’indice 0, vous pouvez ne rien mettre avant les deux points. Autrement dit, ces deux cas sont identiques :
#![allow(unused)]
fn main() {
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
}De la même manière, si votre slice contient le dernier octet de la String, vous pouvez ne rien mettre à la fin. Cela veut dire que ces deux cas sont identiques :
#![allow(unused)]
fn main() {
let s = String::from("hello");
let taille = s.len();
let slice = &s[0..taille];
let slice = &s[..];
}Vous pouvez aussi ne mettre aucune limite pour créer une slice de toute la chaîne de caractères. Ces deux cas sont donc identiques :
#![allow(unused)]
fn main() {
let s = String::from("hello");
let taille = s.len();
let slice = &s[0..taille];
let slice = &s[..];
}Remarque : les indices de l’intervalle d’une slice de chaîne doivent toujours se trouver dans les zones acceptables de séparation des caractères encodés en UTF-8. Si vous essayez de créer une slice de chaîne qui s’arrête au milieu d’un caractère encodé sur plusieurs octets, votre programme va se fermer avec une erreur.
Maintenant que nous savons tout cela, essayons de réécrire premier_mot pour qu’il retourne une slice. Le type pour les slices de chaînes de caractères s’écrit &str :
fn premier_mot(s: &String) -> &str {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {}Nous récupérons l’indice de la fin du mot de la même façon que nous l’avions fait dans l’encart 4-7, en cherchant la première occurrence d’une espace. Lorsque nous trouvons une espace, nous retournons une slice de chaîne en utilisant le début de la chaîne de caractères et l’indice de l’espace comme indices de début et de fin respectivement.
Désormais, quand nous appelons premier_mot, nous récupérons une unique valeur qui est liée à la donnée de base. La valeur se compose d’une référence vers le point de départ de la slice et du nombre d’éléments dans la slice.
Retourner une slice fonctionnerait aussi pour une fonction second_mot :
fn second_mot(s: &String) -> &str {Nous avons maintenant une API simple qui est bien plus difficile à mal utiliser, puisque le compilateur va s’assurer que les références dans la String seront toujours en vigueur. Vous souvenez-vous du bogue du programme de l’encart 4-8, lorsque nous avions un indice vers la fin du premier mot mais qu’ensuite nous avions vidé la chaîne de caractères et que notre indice n’était plus valide ? Ce code était logiquement incorrect, mais ne montrait pas immédiatement une erreur. Les problèmes apparaîtront plus tard si nous essayons d’utiliser l’indice du premier mot avec une chaîne de caractères qui a été vidée. Les slices rendent ce bogue impossible et nous signalent bien plus tôt que nous avons un problème avec notre code. Utiliser la version avec la slice de premier_mot va causer une erreur de compilation :
fn premier_mot(s: &String) -> &str {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let mot = premier_mot(&s);
s.clear(); // Erreur !
println!("Le premier mot est : {mot}");
}Voici l’erreur du compilateur :
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let mot = premier_mot(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // Erreur !
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("Le premier mot est : {mot}");
| --- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Rappelons-nous que d’après les règles d’emprunt, si nous avons une référence immuable vers quelque chose, nous ne pouvons pas avoir une référence mutable en même temps. Étant donné que clear a besoin de modifier la String, il a besoin d’une référence mutable. Le println! qui a lieu après l’appel à clear utilise la référence à mot, donc la référence immuable sera toujours en vigueur à cet endroit. Rust interdit la référence mutable dans clear et la référence immuable pour mot au même moment, et la compilation échoue. Non seulement Rust a simplifié l’utilisation de notre API, mais il a aussi éliminé une catégorie entière d’erreurs au moment de la compilation !
Les littéraux de chaîne de caractères sont aussi des slices
Rappelez-vous lorsque nous avons appris que les littéraux de chaîne de caractères étaient enregistrés dans le binaire. Maintenant que nous connaissons les slices, nous pouvons désormais comprendre les littéraux de chaîne.
#![allow(unused)]
fn main() {
let s = "Hello, world!";
}Ici, le type de s est un &str : c’est une slice qui pointe vers un endroit précis du binaire. C’est aussi la raison pour laquelle les littéraux de chaîne sont immuables ; &str est une référence immuable.
Les slices de chaînes de caractères en paramètres
Savoir que l’on peut utiliser des slices de littéraux et de String nous incite à apporter une petite amélioration à premier_mot, dont voici la signature :
fn premier_mot(s: &String) -> &str {Un Rustacé plus expérimenté écrirait plutôt la signature de l’encart 4-9, car cela nous permet d’utiliser la même fonction sur les &String et aussi les &str :
fn premier_mot(s: &str) -> &str {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let ma_string = String::from("hello world");
// `premier_mot` fonctionne avec les slices de `String`, que ce soit sur
// une partie ou sur sur son intégralité.
let mot = premier_mot(&ma_string[0..6]);
let mot = premier_mot(&ma_string[..]);
// `premier_mot` fonctionne également sur des références vers des `String`,
// qui sont équivalentes à des slices de toute la `String`.
let mot = premier_mot(&ma_string);
let mon_litteral_de_chaine = "hello world";
// `premier_mot` fonctionne avec les slices de littéraux de chaîne, qu'elles
// soient partielles ou intégrales.
let mot = premier_mot(&mon_litteral_de_chaine[0..6]);
let mot = premier_mot(&mon_litteral_de_chaine[..]);
// Comme les littéraux de chaîne *sont* déjà des slices de chaînes,
// cela fonctionne aussi, sans la syntaxe de slice !
let mot = premier_mot(mon_litteral_de_chaine);
}first_word function by using a string slice for the type of the s parameterSi nous avons une slice de chaîne, nous pouvons la passer en argument directement. Si nous avons une String, nous pouvons envoyer une référence ou une slice de la String. Cette flexibilité nous est offerte par l’extrapolation de déréferencement, une fonctionnalité que nous allons découvrir dans une section du Chapitre 15.
Définir une fonction qui prend une slice de chaîne plutôt qu’une référence à une String rend notre API plus générique et plus utile sans perdre aucune fonctionnalité :
fn premier_mot(s: &str) -> &str {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let ma_string = String::from("hello world");
// `premier_mot` fonctionne avec les slices de `String`, que ce soit sur
// une partie ou sur sur son intégralité.
let mot = premier_mot(&ma_string[0..6]);
let mot = premier_mot(&ma_string[..]);
// `premier_mot` fonctionne également sur des références vers des `String`,
// qui sont équivalentes à des slices de toute la `String`.
let mot = premier_mot(&ma_string);
let mon_litteral_de_chaine = "hello world";
// `premier_mot` fonctionne avec les slices de littéraux de chaîne, qu'elles
// soient partielles ou intégrales.
let mot = premier_mot(&mon_litteral_de_chaine[0..6]);
let mot = premier_mot(&mon_litteral_de_chaine[..]);
// Comme les littéraux de chaîne *sont* déjà des slices de chaînes,
// cela fonctionne aussi, sans la syntaxe de slice !
let mot = premier_mot(mon_litteral_de_chaine);
}Les autres slices
Les slices de chaînes de caractères, comme vous pouvez l’imaginer, sont spécifiques aux chaînes de caractères. Mais il existe aussi un type de slice plus générique. Imaginons ce tableau de données :
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
}Tout comme nous pouvons nous référer à une partie d’une chaîne de caractères, nous pouvons nous référer à une partie d’un tableau. Nous pouvons le faire comme ceci :
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
}Cette slice est de type &[i32]. Elle fonctionne de la même manière que les slices de chaînes de caractères, en enregistrant une référence vers le premier élément et une longueur. Vous utiliserez ce type de slice pour tous les autres types de collections. Nous aborderons ces collections en détail quand nous verrons les vecteurs au chapitre 8.
Résumé
Les concepts de possession, d’emprunt et de slices garantissent la sécurité de la mémoire dans les programmes Rust au moment de la compilation. Le langage Rust vous donne le contrôle sur l’utilisation de la mémoire comme tous les autres langages de programmation système, mais le fait que celui qui possède des données nettoie automatiquement ces données quand il sort de la portée vous permet de ne pas avoir à écrire et déboguer du code en plus pour avoir cette fonctionnalité.
La possession influe sur de nombreuses autres fonctionnalités de Rust, c’est pourquoi nous allons encore parler de ces concepts plus loin dans le livre. Passons maintenant au chapitre 5 et découvrons comment regrouper des données ensemble dans une struct.
Utiliser les structures pour structurer des données apparentées
Une struct, ou structure, est un type de données personnalisé qui vous permet de rassembler plusieurs valeurs associées et les nommer pour former un groupe cohérent. Si vous êtes familier avec un langage orienté objet, une structure est en quelque sorte l’ensemble des attributs d’un objet. Dans ce chapitre, nous comparerons les tuples avec les structures afin de construire sur ce que vous connaissez déjà et de montrer à quels moments les structures sont plus pertinentes pour grouper des données.
Nous verrons comment définir les fonctions associées, en particulier le type de fonctions associées que l’on appelle les méthodes, dans le but d’implémenter un comportement associé au type d’une structure. Les structures et les énumérations (traitées au chapitre 6) sont les fondements de la création de nouveaux types au sein de votre programme pour tirer pleinement parti des vérifications de types effectuées par Rust à la compilation.
Définir et instancier des structures
Définir et instancier des structures
Les structures sont similaires aux tuples, qu’on a vus dans une section du chapitre 3, car tous les deux portent plusieurs valeurs associées. Comme pour les tuples, les éléments d’une structure peuvent être de différents types. Contrairement aux tuples, dans une structure on doit nommer chaque élément des données afin de clarifier le rôle de chaque valeur. L’ajout de ces noms fait que les structures sont plus flexibles que les tuples : on n’a pas à utiliser l’ordre des données pour spécifier ou accéder aux valeurs d’une instance.
Pour définir une structure, on tape le mot-clé struct et on donne un nom à toute la structure. Le nom d’une structure devrait décrire l’utilisation des éléments des données regroupés. Ensuite, entre des accolades, on définit le nom et le type de chaque élément des données, qu’on appelle un champ. Par exemple, l’encart 5-1 montre une structure qui stocke des informations à propos d’un compte d’utilisateur.
struct Utilisateur {
actif: bool,
pseudo: String,
email: String,
nombre_de_connexions: u64,
}
fn main() {}User struct definitionPour utiliser une structure après l’avoir définie, on crée une instance de cette structure en indiquant des valeurs concrètes pour chacun des champs. On crée une instance en indiquant le nom de la structure puis en ajoutant des accolades qui contiennent des paires de clé: valeur, où les clés sont les noms des champs et les valeurs sont les données que l’on souhaite stocker dans ces champs. Nous n’avons pas à préciser les champs dans le même ordre que nous les avons déclarés dans la structure. En d’autres termes, la définition de la structure décrit un gabarit pour le type, et les instances remplissent ce gabarit avec des données précises pour créer des valeurs de ce type. Par exemple, nous pouvons déclarer un utilisateur précis comme dans l’encart 5-2.
struct Utilisateur {
actif: bool,
pseudo: String,
email: String,
nombre_de_connexions: u64,
}
fn main() {
let utilisateur1 = Utilisateur {
actif: true,
pseudo: String::from("pseudoquelconque123"),
email: String::from("quelquun@example.com"),
nombre_de_connexions: 1,
};
}User structPour obtenir une valeur spécifique depuis une structure, on utilise la notation avec le point. Par exemple, pour récupérer l’adresse électronique de cet utilisateur, nous utilisons utilisateur1.email. Si l’instance est mutable, nous pourrions changer une valeur en utilisant la notation avec le point et assigner une valeur à ce champ en particulier. L’encart 5-3 montre comment changer la valeur du champ email d’une instance mutable de Utilisateur.
struct Utilisateur {
actif: bool,
pseudo: String,
email: String,
nombre_de_connexions: u64,
}
fn main() {
let mut utilisateur1 = Utilisateur {
actif: true,
pseudo: String::from("pseudoquelconque123"),
email: String::from("quelquun@example.com"),
nombre_de_connexions: 1,
};
utilisateur1.email = String::from("unautremail@example.com");
}email field of a User instanceÀ noter que l’instance tout entière doit être mutable ; Rust ne nous permet pas de marquer seulement certains champs comme mutables. Comme pour toute expression, nous pouvons construire une nouvelle instance de la structure comme dernière expression du corps d’une fonction pour retourner implicitement cette nouvelle instance.
L’encart 5-4 montre une fonction creer_utilisateur qui retourne une instance de Utilisateur avec l’adresse e-mail et le pseudo fournis. Le champ actif prend la valeur true et le nombre_de_connexions prend la valeur 1.
struct Utilisateur {
actif: bool,
pseudo: String,
email: String,
nombre_de_connexions: u64,
}
fn creer_utilisateur(email: String, pseudo: String) -> Utilisateur {
Utilisateur {
actif: true,
pseudo: pseudo,
email: email,
nombre_de_connexions: 1,
}
}
fn main() {
let utilisateur1 = creer_utilisateur(
String::from("quelquun@example.com"),
String::from("pseudoquelconque123"),
);
}build_user function that takes an email and username and returns a User instanceIl est logique de nommer les paramètres de fonction avec le même nom que les champs de la structure, mais devoir répéter les noms de variables et de champs email et pseudo est un peu pénible. Si la structure avait plus de champs, répéter chaque nom serait encore plus fatigant. Heureusement, il existe un raccourci pratique !
Utiliser le raccourci d’initialisation des champs
Puisque les noms des paramètres et les noms de champs de la structure sont exactement les mêmes dans l’encart 5-4, on peut utiliser la syntaxe de raccourci d’initialisation des champs pour réécrire creer_utilisateur de sorte qu’elle se comporte exactement de la même façon sans avoir à répéter pseudo et email, comme le montre l’encart 5-5.
struct Utilisateur {
actif: bool,
pseudo: String,
email: String,
nombre_de_connexions: u64,
}
fn creer_utilisateur(email: String, pseudo: String) -> Utilisateur {
Utilisateur {
actif: true,
pseudo,
email,
nombre_de_connexions: 1,
}
}
fn main() {
let utilisateur1 = creer_utilisateur(
String::from("quelquun@example.com"),
String::from("pseudoquelconque123"),
);
}build_user function that uses field init shorthand because the username and email parameters have the same name as struct fieldsIci, on crée une nouvelle instance de la structure Utilisateur, qui possède un champ nommé email. On veut donner au champ email la valeur du paramètre email de la fonction creer_utilisateur. Comme le champ email et le paramètre email ont le même nom, on a uniquement besoin d’écrire email plutôt que email: email.
Créer des instances avec la syntaxe de mise à jour de structure
Il est souvent utile de créer une nouvelle instance de structure qui comporte la plupart des valeurs d’une autre instance du même type, tout en en changeant certaines. Vous pouvez utiliser pour cela la syntaxe de mise à jour de structure.
Tout d’abord, dans l’encart 5-6 nous montrons comment créer une nouvelle instance de Utilisateur dans utilisateur2 de manière classique, sans utiliser la syntaxe de mise à jour de structure. On donne une nouvelle valeur au champ email mais on utilise pour les autres champs les mêmes valeurs que dans utilisateur1 qu’on a créé à l’encart 5-2.
struct Utilisateur {
actif: bool,
pseudo: String,
email: String,
nombre_de_connexions: u64,
}
fn main() {
// -- partie masquée ici --
let utilisateur1 = Utilisateur {
email: String::from("quelquun@example.com"),
pseudo: String::from("pseudoquelconque123"),
actif: true,
nombre_de_connexions: 1,
};
let utilisateur2 = Utilisateur {
actif: utilisateur1.actif,
pseudo: utilisateur1.email,
email: String::from("quelquundautre@example.com"),
nombre_de_connexions: utilisateur1.nombre_de_connexions,
};
}User instance using all but one of the values from user1En utilisant la syntaxe de mise à jour de structure, on peut produire le même résultat avec moins de code, comme le montre l’encart 5-7. La syntaxe .. indique que les autres champs auxquels on ne donne pas explicitement de valeur devraient avoir la même valeur que dans l’instance précisée.
struct Utilisateur {
actif: bool,
pseudo: String,
email: String,
nombre_de_connexions: u64,
}
fn main() {
// -- partie masquée ici --
let utilisateur1 = Utilisateur {
email: String::from("quelquun@example.com"),
pseudo: String::from("pseudoquelconque123"),
actif: true,
nombre_de_connexions: 1,
};
let utilisateur2 = Utilisateur {
email: String::from("quelquundautre@example.com"),
..utilisateur1
};
}email value for a User instance but to use the rest of the values from user1Le code dans l’encart 5-7 crée aussi une instance dans utilisateur2 qui a une valeur différente pour email, mais qui a les mêmes valeurs pour les champs pseudo, actif et nombre_de_connexions que utilisateur1. Le ..utilisateur1 doit être inséré à la fin pour préciser que tous les champs restants obtiendront les valeurs des champs correspondants de utilisateur1, mais nous pouvons renseigner les valeurs des champs dans n’importe quel ordre, peu importe leur position dans la définition de la structure.
Veuillez notez que la syntaxe de mise à jour d’une structure utilise un = comme c’est le cas pour une assignation ; c’est parce que cela déplace les données, comme nous l’avons vu dans une des sections au chapitre 4. Dans cet exemple, nous ne pouvons plus utiliser utilisateur1 après avoir créé utilisateur2 car la String dans le champ pseudo de utilisateur1 a été déplacée dans utilisateur2. Si nous avions donné des nouvelles valeurs pour chacune des String email et pseudo, et que par conséquent nous aurions déplacé uniquement les valeurs de actif et de nombre_de_connexions à partir de utilisateur1, alors utilisateur1 resterait en vigueur après la création de utilisateur2. Les types de actif et de nombre_de_connexions implémentent tous deux le trait Copy, donc le comportement décrit dans la section à propos de copy aura lieu ici. Nous pouvons toujours utiliser utilisateur1.email dans cet exemple, car sa valeur n’a pas été déplacée hors de utilisateur1.
Création de différents types avec les structures tuples
Rust prend aussi en charge des structures qui ressemblent à des tuples, appelées structures tuples. La signification d’une structure tuple est donnée par son nom. En revanche, ses champs ne sont pas nommés ; on ne précise que leurs types. Les structures tuples servent lorsqu’on veut donner un nom à un tuple pour qu’il soit d’un type différent des autres tuples, et lorsque nommer chaque champ comme dans une structure classique serait trop verbeux ou redondant.
La définition d’une structure tuple commence par le mot-clé struct et le nom de la structure suivis des types des champs du tuple. Par exemple ci-dessous, nous définissons et utilisons deux structures tuples nommées Couleur et Point :
struct Couleur(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let noir = Couleur(0, 0, 0);
let origine = Point(0, 0, 0);
}Notez que les valeurs noir et origine sont de types différents parce que ce sont des instances de structures tuples différentes. Chaque structure que vous définissez constitue un type à part entière, même si les champs au sein de la structure peuvent être du même type. Par exemple, une fonction qui prend un paramètre de type Couleur ne peut pas prendre un argument de type Point à la place, bien que ces deux types soient tous les deux constitués de trois valeurs i32. Mis à part cela, les instances de stuctures tuples sont similaires aux tuples, en ce sens que vous pouvez les déstructurer en leurs éléments individuels, et vous pouvez utiliser un . suivi de l’indice pour accéder individuellement à une valeur, et ainsi de suite. Contrairement aux tuples, les structures tuples exigent que vous nommiez le type de la structure lorsque vous les déstructurez. Par exemple, on écrirait let Point(x, y, z) = origin; pour déstructurer les valeurs du point origin en variables nommées x, y et z.
Définition de structures unité
On peut aussi définir des structures qui n’ont pas de champ ! Cela s’appelle des structures unité parce qu’elles se comportent d’une façon analogue au type unité, (), que nous avons vu dans la section sur les tuples. Les structures unité sont utiles lorsqu’on doit implémenter un trait sur un type mais qu’on n’a aucune donnée à stocker dans le type en lui-même. Nous aborderons les traits au chapitre 10. Voici un exemple de déclaration et d’instanciation d’une structure unité ToujoursEgal :
struct ToujoursEgal;
fn main() {
let sujet = ToujoursEgal;
}Pour définir ToujoursEgal, nous utilisons le mot-clé struct, puis le nom que nous voulons lui donner, et enfin un point-virgule. Pas besoin d’accolades ou de parenthèses ! Ensuite, nous pouvons obtenir une instance de ToujourEgal dans la variable sujet de la même manière : utilisez le nom que vous avez défini, sans aucune accolade ou parenthèse. Imaginez que plus tard nous allons implémenter un comportement pour ce type pour que toutes les instances de ToujourEgal soient toujours égales à chaque instance de n’importe quel autre type, peut-être pour avoir un résultat connu pour des besoins de tests. Nous n’avons besoin d’aucune donnée pour implémenter ce comportement ! Vous verrez au chapitre 10 comment définir des traits et les implémenter sur n’importe quel type, y compris sur les structures unité.
La possession des données d’une structure
Dans la définition de la structure Utilisateur de l’encart 5-1, nous avions utilisé le type possédé String plutôt que le type de slice de chaîne de caractères &str. Il s’agit d’un choix délibéré puisque nous voulons que chacune des instances de cette structure possède ses données et que ces données restent valides tant que la structure tout entière est valide.
Il est aussi possible pour les structures de stocker des références vers des données possédées par autre chose, mais cela nécessiterait d’utiliser des durées de vie, une fonctionnalité de Rust que nous aborderons au chapitre 10. Les durées de vie assurent que les données référencées par une structure restent valides tant que la structure l’est aussi. Disons que vous essayez de stocker une référence dans une structure sans indiquer de durée de vie, comme ce qui suit, cela ne fonctionnera pas :
struct Utilisateur {
actif: bool,
pseudo: &str,
email: &str,
nombre_de_connexions: u64,
}
fn main() {
let utilisateur1 = Utilisateur {
actif: true,
pseudo: "pseudoquelconque123",
email: "quelquun@example.com",
nombre_de_connexions: 1,
};
}Le compilateur réclamera l’ajout des durées de vie :
$ cargo run
Compiling structs v0.1.0 (file:///projects/structs)
error[E0106]: missing lifetime specifier
--> src/main.rs:3:15
|
3 | pseudo: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct Utilisateur<'a> {
2 | actif: bool,
3 ~ pseudo: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:4:12
|
4 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct Utilisateur<'a> {
2 | actif: bool,
3 | pseudo: &str,
4 ~ email: &'a str,
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `structs` (bin "structs") due to 2 previous errors
Au chapitre 10, nous aborderons la façon de corriger ces erreurs pour qu’on puisse stocker des références dans des structures, mais pour le moment, nous résoudrons les erreurs comme celles-ci en utilisant des types possédés comme String plutôt que des références comme &str.
Un exemple de programme qui utilise des structures
Un exemple de programme qui utilise des structures
Pour comprendre dans quels cas nous voudrions utiliser des structures, écrivons un programme qui calcule l’aire d’un rectangle. Nous commencerons en utilisant de simples variables, puis nous remanierons le code jusqu’à utiliser des structures à la place.
Créons un nouveau projet binaire avec Cargo nommé rectangles qui prendra la largeur et la hauteur en pixels d’un rectangle et qui calculera l’aire de ce rectangle. L’encart 5-8 montre un petit programme qui effectue cette tâche d’une certaine manière dans le src/main.rs de notre projet.
fn main() {
let largeur1 = 30;
let hauteur1 = 50;
println!(
"L'aire du rectangle est de {} pixels carrés.",
aire(largeur1, hauteur1)
);
}
fn aire(largeur: u32, hauteur: u32) -> u32 {
largeur * hauteur
}Maintenant, lancez ce programme avec cargo run :
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
L'aire du rectangle est de 1500 pixels carrés.
Ce code arrive à déterminer l’aire du rectangle en appelant la fonction aire avec chaque dimension, mais on peut faire mieux pour clarifier ce code et le rendre plus lisible.
Le problème de ce code se voit dans la signature de aire :
fn main() {
let largeur1 = 30;
let hauteur1 = 50;
println!(
"L'aire du rectangle est de {} pixels carrés.",
aire(largeur1, hauteur1)
);
}
fn aire(largeur: u32, hauteur: u32) -> u32 {
largeur * hauteur
}La fonction aire est censée calculer l’aire d’un rectangle, mais la fonction que nous avons écrite a deux paramètres, et il n’est précisé nulle part dans notre programme à quoi sont liés les paramètres. Il serait plus lisible et plus gérable de regrouper ensemble la largeur et la hauteur. Nous avons déjà vu dans la section “Le type tuple” du chapitre 3 une façon qui nous permettrait de le faire : en utilisant des tuples.
Remanier le code avec des tuples
L’encart 5-9 nous montre une autre version de notre programme qui utilise des tuples.
fn main() {
let rect1 = (30, 50);
println!(
"L'aire du rectangle est de {} pixels carrés.",
aire(rect1)
);
}
fn aire(dimensions: (u32, u32)) -> u32 {
dimensions.0 * dimensions.1
}D’une certaine façon, ce programme est meilleur. Les tuples nous permettent de structurer un peu plus et nous ne passons plus qu’un seul argument. Mais d’une autre façon, cette version est moins claire : les tuples ne donnent pas de noms à leurs éléments, donc il faut accéder aux éléments du tuple via leur indice, ce qui rend plus compliqué notre calcul.
Le mélange de la largeur et de la hauteur n’est pas important pour calculer l’aire, mais si on voulait afficher le rectangle à l’écran, cela serait problématique ! Il nous faut garder à l’esprit que la largeur est l’élément à l’indice 0 du tuple et que la hauteur est l’élément à l’indice 1. Cela serait encore plus complexe à comprendre et à retenir pour une personne tierce qui viendrait à réutiliser notre code. Du fait qu’on n’a pas exprimé la signification de nos données dans notre code, il est alors plus facile de faire des erreurs.
Remanier le code avec des structures
On utilise des structures pour rendre les données plus expressives en leur donnant des noms. On peut transformer le tuple que nous avons utilisé en une structure nommée dont ses éléments sont aussi nommés, comme le montre l’encart 5-10.
struct Rectangle {
largeur: u32,
hauteur: u32,
}
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
println!(
"L'aire du rectangle est de {} pixels carrés.",
aire(&rect1)
);
}
fn aire(rectangle: &Rectangle) -> u32 {
rectangle.largeur * rectangle.hauteur
}Rectangle structIci, on a défini une structure et on l’a appelée Rectangle. Entre les accolades, on a défini les champs largeur et hauteur, tous deux du type u32. Puis dans main, on crée une instance de Rectangle de largeur 30 et de hauteur 50.
Notre fonction aire est désormais définie avec un unique paramètre, nommé rectangle, et dont le type est une référence immuable vers une instance de la structure Rectangle. Comme mentionné au chapitre 4, on préfère emprunter la structure au lieu d’en prendre possession. Ainsi, elle reste en possession de main qui peut continuer à utiliser rect1 ; c’est pourquoi on utilise le & dans la signature de la fonction ainsi que dans l’appel de fonction.
La fonction aire accède aux champs largeur et hauteur de l’instance de Rectangle (on note que l’accès aux champs d’une instance d’une structure empruntée ne déplace pas les valeurs de ces champs, ce qui explique pourquoi les emprunts de structures sont utilisés). Notre signature de fonction pour aire est enfin explicite : calculer l’aire d’un Rectangle en utilisant ses champs largeur et hauteur. Cela explique que la largeur et la hauteur sont liées entre elles, et cela donne des noms descriptifs aux valeurs plutôt que d’utiliser les valeurs du tuple avec les indices 0 et 1. On gagne en clarté.
Ajouter des fonctionnalités utiles avec les traits dérivés
Il serait pratique de pouvoir afficher une instance de Rectangle pendant qu’on débogue notre programme et de voir la valeur de chacun de ses champs. L’encart 5-11 essaye de le faire en utilisant la macro println! comme on l’a fait dans les chapitres précédents. Cependant, cela ne fonctionne pas.
struct Rectangle {
largeur: u32,
hauteur: u32,
}
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
println!("rect1 est {rect1}");
}Rectangle instanceLorsqu’on compile ce code, on obtient ce message d’erreur qui nous informe que Rectangle n’implémente pas le trait std::fmt::Display :
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
La macro println! peut faire toutes sortes de formatages textuels, et par défaut, les accolades demandent à println! d’utiliser le formatage appelé Display, pour convertir en texte destiné à être vu par l’utilisateur final. Les types primitifs qu’on a vus jusqu’ici implémentent Display par défaut puisqu’il n’existe qu’une seule façon d’afficher un 1 ou tout autre type primitif à l’utilisateur. Mais pour les structures, la façon dont println! devrait formater son résultat est moins claire car il y a plus de possibilités d’affichage : Voulez-vous des virgules ? Voulez-vous afficher les accolades ? Est-ce que tous les champs devraient être affichés ? À cause de ces ambiguïtés, Rust n’essaye pas de deviner ce qu’on veut, et les structures n’implémentent pas Display par défaut pour l’utiliser avec println! et les espaces réservés {}.
Si nous continuons à lire les erreurs, nous trouvons cette remarque utile :
| |`Rectangle` cannot be formatted with the default formatter
| required by this formatting parameter
Le compilateur nous informe que dans notre chaîne de formatage, on est peut-être en mesure d’utiliser {:?} (ou {:#?} pour un affichage plus élégant). Essayons cela ! L’appel de la macro println! ressemble maintenant à println!("rect1 est {rect1:?}");. Insérer le sélecteur :? entre les accolades permet d’indiquer à println! que nous voulons utiliser le formatage appelé Debug. Le trait Debug nous permet d’afficher notre structure d’une manière utile aux développeurs pour qu’on puisse voir sa valeur pendant qu’on débogue le code.
Compilez le code avec ce changement. Zut ! On a encore une erreur, nous informant cette fois-ci que Rectangle n’implémente pas std::fmt::Debug :
error[E0277]: `Rectangle` doesn't implement `Debug`
Mais une nouvelle fois, le compilateur nous fait une remarque utile :
| required by this formatting parameter
|
Il nous conseille d’ajouter #[derive(Debug)] ou d’implémenter manuellement std::fmt::Debug. Rust inclut bel et bien une fonctionnalité pour afficher des informations de débogage, mais nous devons l’activer explicitement pour la rendre disponible sur notre structure. Pour ce faire, on ajoute l’attribut externe #[derive(Debug)] juste avant la définition de la structure, comme le montre l’encart 5-12.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
println!("rect1 est {rect1:?}");
}Debug trait and printing the Rectangle instance using debug formattingMaintenant, quand nous exécutons le programme, nous n’avons plus d’erreurs et ce texte s’affiche à l’écran :
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 est Rectangle { largeur: 30, hauteur: 50 }
Super ! Ce n’est pas le plus beau des affichages, mais cela montre les valeurs de tous les champs de cette instance, ce qui serait assurément utile lors du débogage. Quand on a des structures plus grandes, il serait bien d’avoir un affichage un peu plus lisible ; dans ces cas-là, on pourra utiliser {:#?} au lieu de {:?} dans la chaîne de formatage. Dans cette exemple, l’utilisation du style {:#?} va afficher ceci :
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 est Rectangle {
largeur: 30,
hauteur: 50,
}
Une autre façon d’afficher une valeur en utilisant le format Debug est d’utiliser la macro dbg!, qui prend possession de l’expression (contrairement à println! qui prend une référence), affiche le nom du fichier et la ligne de votre code où se trouve cet appel à la macro dbg! ainsi que le résultat de cette expression, puis rend la possession de cette valeur.
Remarque : l’appel à la macro dbg! écrit dans le flux d’erreur standard de la console (stderr), contrairement à println! qui écrit dans le flux de sortie standard de la console (stdout). Nous reparlerons de stderr et de stdout dans la section “Écrire les erreurs sur la sortie d’erreur standard” du chapitre 12.
Voici un exemple dans lequel nous nous intéressons à la valeur assignée au champ largeur, ainsi que la valeur de toute la structure rect1 :
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
fn main() {
let echelle = 2;
let rect1 = Rectangle {
largeur: dbg!(30 * echelle),
hauteur: 50,
};
dbg!(&rect1);
}Nous pouvons placer le dbg! autour de l’expression 30 * echelle et, comme dbg! retourne la possession de la valeur issue de l’expression, le champ largeur va avoir la même valeur que si nous n’avions pas appelé dbg! ici. Nous ne voulons pas que dbg! prenne possession de rect1, donc nous donnons une référence à rect1 lors de son prochain appel. Voici à quoi ressemble la sortie de cet exemple :
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * echelle = 60
[src/main.rs:14:5] &rect1 = Rectangle {
largeur: 60,
hauteur: 50,
}
Nous pouvons constater que la première sortie provient de la ligne 10 de src/main.rs, où nous déboguons l’expression 30 * echelle, et son résultat est 60 (le formatage de Debug pour les entiers est d’afficher uniquement leur valeur). L’appel à dbg! à la ligne 14 de src/main.rs affiche la valeur de &rect1, qui est une structure Rectangle. La macro dbg! peut être très utile lorsque vous essayez de comprendre ce que fait votre code !
En plus du trait Debug, Rust nous offre d’autres traits pour que nous puissions les utiliser avec l’attribut derive pour ajouter des comportements utiles à nos propres types. Ces traits et leurs comportements sont listés à l’annexe C. Nous expliquerons comment implémenter ces traits avec des comportements personnalisés et comment créer vos propres traits au chapitre 10. Il existe aussi de nombreux attributs autres que derive ; pour en savoir plus, consultez la section “Attributs” de la référence de Rust.
Notre fonction aire est très spécifique : elle ne fait que calculer l’aire d’un rectangle. Il serait utile de lier un peu plus ce comportement à notre structure Rectangle, puisque cela ne fonctionnera pas avec un autre type. Voyons comment on peut continuer de remanier ce code en transformant la fonction aire en méthode aire définie sur notre type Rectangle.
Méthodes
Méthodes
Les méthodes sont similaires aux fonctions : nous les déclarons avec le mot-clé fn et un nom, elles peuvent avoir des paramètres et une valeur de retour, et elles contiennent du code qui est exécuté quand la méthode est appellée depuis un autre endroit. Contrairement aux fonctions, les méthodes sont définies dans le contexte d’une structure (ou d’une énumération ou d’un objet de trait, que nous aborderons respectivement aux chapitres 6 et 18) et leur premier paramètre est toujours self, un mot-clé qui représente l’instance de la structure sur laquelle on appelle la méthode.
La syntaxe des méthodes
Remplaçons la fonction aire qui prend une instance de Rectangle en paramètre par une méthode aire définie sur la structure Rectangle, comme dans l’encart 5-13.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn aire(&self) -> u32 {
self.largeur * self.hauteur
}
}
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
println!(
"L'aire du rectangle est de {} pixels carrés.",
rect1.aire()
);
}area method on the Rectangle structPour définir la fonction dans le contexte de Rectangle, nous démarrons un bloc impl (implémentation) pour Rectangle. Tout ce qui sera dans ce bloc impl sera lié au type Rectangle. Puis nous déplaçons la fonction aire entre les accolades du impl et nous remplaçons le premier paramètre (et dans notre cas, le seul) par self dans la signature et dans tout le corps. Dans main, où nous avons appelé la fonction aire et passé rect1 en argument, nous pouvons utiliser à la place la syntaxe des méthodes pour appeler la méthode aire sur notre instance de Rectangle. La syntaxe des méthodes se place après l’instance : on ajoute un point suivi du nom de la méthode et des parenthèses contenant les arguments s’il y en a.
Dans la signature de aire, nous utilisons &self à la place de rectangle: &Rectangle. Le &self est un raccourci pour self: &Self. Au sein d’un bloc impl, le type de Self est un alias pour le type sur lequel porte le impl. Les méthodes doivent avoir un paramètre self du type Self comme premier paramètre afin que Rust puisse vous permettre d’abréger en renseignant uniquement self en premier paramètre. Veuillez noter qu’il nous faut quand même utiliser le & devant le raccourci self, pour indiquer que cette méthode emprunte l’instance de Self, comme nous l’avions fait pour rectangle: &Rectangle. Les méthodes peuvent prendre possession de self, emprunter self de façon immuable comme nous l’avons fait ici, ou emprunter self de façon mutable, comme pour n’importe quel autre paramètre.
Nous avons choisi &self ici pour la même raison que nous avions utilisé &Rectangle quand il s’agissait d’une fonction ; nous ne voulons pas en prendre possession, et nous voulons seulement lire les données de la structure, pas les modifier. Si nous voulions que la méthode modifie l’instance sur laquelle on l’appelle, on utiliserait &mut self comme premier paramètre. Il est rare d’avoir une méthode qui prend possession de l’instance en utilisant uniquement self comme premier argument ; cette technique est généralement utilisée lorsque la méthode transforme self en quelque chose d’autre et que vous voulez empêcher le code appelant d’utiliser l’instance d’origine après la transformation.
La principale raison d’utiliser des méthodes plutôt que des fonctions est, en plus de l’application de la syntaxe des méthodes et de ne pas avoir à répéter le type de self dans la signature de chaque méthode, une question d’organisation. Nous avons mis tout ce qu’on pouvait faire avec une instance de notre type dans un bloc impl plutôt que d’imposer aux futurs utilisateurs de notre code de rechercher les fonctionnalités de Rectangle à divers endroits de la bibliothèque que nous fournissons.
Notez que nous pourrions faire en sorte qu’une méthode porte le même nom qu’un des champs de la structure. Par exemple, nous pourrions définir une méthode sur Rectangle qui s’appelle elle aussi largeur :
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn largeur(&self) -> bool {
self.largeur > 0
}
}
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
if rect1.largeur() {
println!("Le rectangle a une largeur non nulle ; elle vaut {}", rect1.largeur);
}
}Ici, nous avons défini la méthode largeur pour qu’elle retourne true si la valeur dans le champ largeur est supérieure à 0, et false si la valeur est 0 : nous pouvons utiliser un champ à l’intérieur d’une méthode du même nom, pour n’importe quel usage. Dans le main, lorsque nous ajoutons des parenthèses après rect1.largeur, Rust comprend que nous faisons référence à la méthode largeur. Lorsque nous n’utilisons pas les parenthèses, Rust sait que nous faisons référence au champ largeur.
Souvent, mais pas toujours, lorsque nous appellons une méthode avec le même nom qu’un champ, nous voulons qu’elle renvoie uniquement la valeur de ce champ et ne fasse rien d’autre. Ces méthodes sont appelées des accesseurs, et Rust ne les implémente pas automatiquement pour les champs des structures, comme le font certains langages. Les accesseurs sont utiles pour rendre le champ privé mais la méthode publique et ainsi donner un accès en lecture seule à ce champ dans l’API publique du type. Nous développerons les notions de public et privé et comment définir un champ ou une méthode publique ou privée au chapitre 7.
Où est l’opérateur -> ?
En C et en C++, deux opérateurs différents sont utilisés pour appeler les méthodes : on utilise . si on appelle une méthode directement sur l’objet et -> si on appelle la méthode sur un pointeur vers l’objet et qu’il faut d’abord déréférencer le pointeur. En d’autres termes, si objet est un pointeur, objet->methode() est similaire à (*objet).methode().
Rust n’a pas d’équivalent à l’opérateur -> ; à la place, Rust a une fonctionnalité appelée référencement et déréférencement automatiques. L’appel de méthodes est l’un des rares endroits de Rust où on retrouve ce comportement.
Voilà comment cela fonctionne : quand on appelle une méthode avec objet.methode(), Rust ajoute automatiquement le &, &mut ou * pour que objet corresponde à la signature de la méthode. Autrement dit, ces deux lignes sont identiques :
#![allow(unused)]
fn main() {
#[derive(Debug,Copy,Clone)]
struct Point {
x: f64,
y: f64,
}
impl Point {
fn distance(&self, other: &Point) -> f64 {
let x_squared = f64::powi(other.x - self.x, 2);
let y_squared = f64::powi(other.y - self.y, 2);
f64::sqrt(x_squared + y_squared)
}
}
let p1 = Point { x: 0.0, y: 0.0 };
let p2 = Point { x: 5.0, y: 6.5 };
p1.distance(&p2);
(&p1).distance(&p2);
}La première ligne semble bien plus propre. Ce comportement du (dé)référencement automatique fonctionne parce que les méthodes ont une cible claire : le type de self. Compte tenu du nom de la méthode et de l’instance sur laquelle elle s’applique, Rust peut déterminer de manière irréfutable si la méthode lit (&self), modifie (&mut self) ou consomme (self) l’instance. Le fait que Rust rend implicite l’emprunt pour les instances sur lesquelles on appelle les méthodes améliore significativement l’ergonomie de la possession.
Les méthodes avec davantage de paramètres
Entraînons-nous à utiliser des méthodes en implémentant une seconde méthode sur la structure Rectangle. Cette fois-ci, nous voulons qu’une instance de Rectangle prenne une autre instance de Rectangle et qu’on retourne true si le second Rectangle peut se dessiner intégralement à l’intérieur de self (le premier Rectangle) ; sinon, on renverra false. En d’autres termes, une fois qu’on aura défini la méthode peut_contenir, on veut pouvoir écrire le programme de l’encart 5-14.
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
let rect2 = Rectangle {
largeur: 10,
hauteur: 40,
};
let rect3 = Rectangle {
largeur: 60,
hauteur: 45,
};
println!("rect1 peut-il contenir rect2 ? {}", rect1.peut_contenir(&rect2));
println!("rect1 peut-il contenir rect3 ? {}", rect1.peut_contenir(&rect3));
}can_hold methodEt on s’attend à ce que le texte suivant s’affiche, puisque les deux dimensions de rect2 sont plus petites que les dimensions de rect1, mais rect3 est plus large que rect1 :
rect1 peut-il contenir rect2 ? true
rect1 peut-il contenir rect3 ? false
Nous voulons définir une méthode, donc elle doit se trouver dans le bloc impl Rectangle. Le nom de la méthode sera peut_contenir et elle prendra une référence immuable vers un autre Rectangle en paramètre. On peut déterminer le type du paramètre en regardant le code qui appelle la méthode : rect1.peut_contenir(&rect2) prend en argument &rect2, une référence immuable vers rect2, une instance de Rectangle. Cela est logique puisque nous voulons uniquement lire rect2 (plutôt que de la modifier, ce qui aurait nécessité une référence mutable) et nous souhaitons que main garde possession de rect2 pour qu’on puisse le réutiliser après avoir appelé la méthode peut_contenir. La valeur de retour de peut_contenir sera un booléen et l’implémentation de la méthode vérifiera si la largeur et la hauteur de self sont respectivement plus grandes que la largeur et la hauteur de l’autre Rectangle. Ajoutons la nouvelle méthode peut_contenir dans le bloc impl de l’encart 5-13, comme le montre l’encart 5-15.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn aire(&self) -> u32 {
self.largeur * self.hauteur
}
fn peut_contenir(&self, autre: &Rectangle) -> bool {
self.largeur > autre.largeur && self.hauteur > autre.hauteur
}
}
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
let rect2 = Rectangle {
largeur: 10,
hauteur: 40,
};
let rect3 = Rectangle {
largeur: 60,
hauteur: 45,
};
println!("rect1 peut-il contenir rect2 ? {}", rect1.peut_contenir(&rect2));
println!("rect1 peut-il contenir rect3 ? {}", rect1.peut_contenir(&rect3));
}can_hold method on Rectangle that takes another Rectangle instance as a parameterLorsque nous exécutons ce code avec la fonction main de l’encart 5-14, nous obtenons l’affichage attendu. Les méthodes peuvent prendre plusieurs paramètres qu’on peut ajouter à la signature après le paramètre self, et ces paramètres fonctionnent de la même manière que les paramètres des fonctions.
Les fonctions associées
Toutes les fonctions définies dans un bloc impl s’appellent des fonctions associées car elles sont associées au type renseigné après le impl. Nous pouvons aussi y définir des fonctions associées qui n’ont pas de self en premier paramètre (et donc ce ne sont pas des méthodes) car elles n’ont pas besoin d’une instance du type sur lequel elles travaillent. Nous avons déjà utilisé une fonction comme celle-ci : la fonction String::from qui est définie sur le type String.
Les fonctions associées qui ne ne sont pas des méthodes sont souvent utilisées comme constructeurs qui vont retourner une nouvelle instance de la structure. Elles sont souvent appelées new, mais new n’est pas un nom réservé et n’est pas intégré au langage. Par exemple, on pourrait écrire une fonction associée qui prend une unique dimension en paramètre et l’utilise à la fois pour la largeur et pour la hauteur, ce qui rend plus aisé la création d’un Rectangle carré plutôt que d’avoir à indiquer la même valeur deux fois :
Fichier : src/main.rs
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn carre(cote: u32) -> Self {
Self {
largeur: cote,
hauteur: cote
}
}
}
fn main() {
let mon_carre = Rectangle::carre(3);
}Les mot-clés Self dans le type de retour et dans le corps de la fonction sont des alias du type qui apparaît après le mot-clé impl, qui dans ce cas est Rectangle.
Pour appeler cette fonction associée, on utilise la syntaxe :: avec le nom de la structure ; let mon_carre = Rectangle::carre(3); en est un exemple. Cette fonction est cloisonnée dans l’espace de noms de la structure : la syntaxe :: s’utilise aussi bien pour les fonctions associées que pour les espaces de noms créés par des modules. Nous aborderons les modules au chapitre 7.
Plusieurs blocs impl
Chaque structure peut avoir plusieurs blocs impl. Par exemple, l’encart 5-15 est équivalent au code de l’encart 5-16, où chaque méthode est dans son propre bloc impl.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn aire(&self) -> u32 {
self.largeur * self.hauteur
}
}
impl Rectangle {
fn peut_contenir(&self, autre: &Rectangle) -> bool {
self.largeur > autre.largeur && self.hauteur > autre.hauteur
}
}
fn main() {
let rect1 = Rectangle {
largeur: 30,
hauteur: 50,
};
let rect2 = Rectangle {
largeur: 10,
hauteur: 40,
};
let rect3 = Rectangle {
largeur: 60,
hauteur: 45,
};
println!("rect1 peut-il contenir rect2 ? {}", rect1.peut_contenir(&rect2));
println!("rect1 peut-il contenir rect3 ? {}", rect1.peut_contenir(&rect3));
}impl blocksIl n’y a aucune raison de séparer ces méthodes dans plusieurs blocs impl dans notre exemple, mais c’est une syntaxe valide. Nous verrons un exemple de l’utilité d’avoir plusieurs blocs impl au chapitre 10, où nous aborderons les types génériques et les traits.
Résumé
Les structures vous permettent de créer des types personnalisés significatifs pour votre domaine. En utilisant des structures, on peut relier entre elles des données associées et nommer chaque donnée pour rendre le code plus clair. Dans des blocs impl, vous pouvez définir des fonctions qui sont associées à votre type, et les méthodes sont un genre de fonction associée qui vous permet de renseigner le comportement que doivent suivre les instances de votre structure.
Mais les structures ne sont pas le seul moyen de créer des types personnalisés : nous allons maintenant voir les énumérations de Rust, une fonctionnalité que vous pourrez bientôt ajouter à votre boîte à outils.
Les énumérations et le filtrage par motif
Dans ce chapitre, nous allons aborder les énumérations, aussi appelées enums. Les énumérations vous permettent de définir un type en énumérant ses variantes possibles. Pour commencer, nous allons définir et utiliser une énumération pour voir comment une énumération peut donner du sens aux données. Ensuite, nous examinerons une énumération particulièrement utile qui s’appelle Option et qui permet de décrire des situations où la valeur peut être soit quelque chose, soit rien. Ensuite, nous regarderons comment le filtrage par motif avec l’expression match peut faciliter l’exécution de codes différents pour chaque valeur d’une énumération. Enfin, nous analyserons pourquoi la construction if let est un autre outil commode et concis à disposition pour traiter les énumérations dans votre code.
Définir une énumération
Définir une énumération
Alors que les structures permettent de regrouper des champs et des données liés entre eux, comme un Rectangle avec ses propriétés largeur et hauteur, les énumérations permettent d’indiquer qu’une valeur fait partie d’un ensemble de valeurs possibles. Par exemple, on peut vouloir préciser que Rectangle fait partie d’un ensemble de formes possibles qui comprend également Cercle et Triangle. Pour ce faire, Rust nous permet d’encoder ces possibilités sous la forme d’une énumération.
Imaginons une situation que nous voudrions exprimer avec du code et regardons pourquoi les énumérations sont utiles et plus appropriées que les structures dans ce cas. Disons que nous avons besoin de travailler avec des adresses IP. Pour le moment, il existe deux normes principales pour les adresses IP : la version quatre et la version six. Comme ce seront les seules possibilités d’adresse IP que notre programme va rencontrer, nous pouvons énumérer toutes les variantes possibles, d’où vient le nom de l’énumération.
N’importe quelle adresse IP peut être soit une adresse en version quatre, soit en version six, mais pas les deux en même temps. Cette propriété des adresses IP est appropriée à la structure de données d’énumérations, car une valeur de l’énumération ne peut être qu’une de ses variantes. Les adresses en version quatre et six sont toujours fondamentalement des adresses IP, donc elles doivent être traitées comme étant du même type lorsque le code travaille avec des situations qui s’appliquent à n’importe quelle sorte d’adresse IP.
Nous pouvons exprimer ce concept dans le code en définissant une énumération SorteAdresseIp et en listant les différentes sortes possibles d’adresses IP qu’elle peut avoir, V4 et V6. Ce sont les variantes de l’énumération :
enum SorteAdresseIp {
V4,
V6,
}
fn main() {
let quatre = SorteAdresseIp::V4;
let six = SorteAdresseIp::V6;
router(SorteAdresseIp::V4);
router(SorteAdresseIp::V6);
}
fn router(sorte_ip: SorteAdresseIp) { }SorteAdresseIp est maintenant un type de données personnalisé que nous pouvons utiliser n’importe où dans notre code.
Les valeurs d’énumérations
Nous pouvons créer des instances de chacune des deux variantes de SorteAdresseIp de cette manière :
enum SorteAdresseIp {
V4,
V6,
}
fn main() {
let quatre = SorteAdresseIp::V4;
let six = SorteAdresseIp::V6;
router(SorteAdresseIp::V4);
router(SorteAdresseIp::V6);
}
fn router(sorte_ip: SorteAdresseIp) { }Remarquez que les variantes de l’énumération sont dans un espace de nom qui se situe avant leur nom, et nous utilisons un double deux-points pour les séparer tous les deux. C’est utile car maintenant les deux valeurs SorteAdresseIp::V4 et SorteAdresseIp::V6 sont du même type : SorteAdresseIp. Ensuite, nous pouvons, par exemple, définir une fonction qui accepte n’importe quelle SorteAdresseIp :
enum SorteAdresseIp {
V4,
V6,
}
fn main() {
let quatre = SorteAdresseIp::V4;
let six = SorteAdresseIp::V6;
router(SorteAdresseIp::V4);
router(SorteAdresseIp::V6);
}
fn router(sorte_ip: SorteAdresseIp) { }Et nous pouvons appeler cette fonction avec chacune des variantes :
enum SorteAdresseIp {
V4,
V6,
}
fn main() {
let quatre = SorteAdresseIp::V4;
let six = SorteAdresseIp::V6;
router(SorteAdresseIp::V4);
router(SorteAdresseIp::V6);
}
fn router(sorte_ip: SorteAdresseIp) { }L’utilisation des énumérations a encore plus d’avantages. En étudiant un peu plus notre type d’adresse IP, nous constatons que pour le moment, nous ne pouvons pas stocker la donnée de l’adresse IP ; nous savons seulement de quelle sorte elle est. Avec ce que vous avez appris au chapitre 5, vous pourriez être tenté de résoudre ce problème avec des structures comme dans l’encart 6-1.
fn main() {
enum SorteAdresseIp {
V4,
V6,
}
struct AdresseIp {
sorte: SorteAdresseIp,
adresse: String,
}
let local = AdresseIp {
sorte: SorteAdresseIp::V4,
adresse: String::from("127.0.0.1"),
};
let rebouclage = AdresseIp {
sorte: SorteAdresseIp::V6,
adresse: String::from("::1"),
};
}IpAddrKind variant of an IP address using a structAinsi, nous avons défini une structure AdresseIp qui a deux champs : un champ sorte qui est du type SorteAdresseIp (l’énumération que nous avons définie précédemment) et un champ adresse qui est du type String. Nous avons deux instances de cette structure. La première est local, et a la valeur SorteAdresseIp::V4 pour son champ sorte, associé à la donnée d’adresse qui est 127.0.0.1. La seconde instance est rebouclage. Elle a comme valeur de champ sorte l’autre variante de SorteAdresseIp, V6, et a l’adresse::1 qui lui est associée. Nous avons utilisé une structure pour relier ensemble la sorte et l’adresse, donc maintenant la variante est liée à la valeur.
Cependant, suivre le même principe en utilisant uniquement une énumération est plus concis : plutôt que d’utiliser une énumération dans une structure, nous pouvons insérer directement la donnée dans chaque variante de l’énumération. Cette nouvelle définition de l’énumération AdresseIp indique que chacune des variantes V4 et V6 auront des valeurs associées de type String :
fn main() {
enum AdresseIp {
V4(String),
V6(String),
}
let local = AdresseIp::V4(String::from("127.0.0.1"));
let rebouclage = AdresseIp::V6(String::from("::1"));
}Nous relions les données de chaque variante directement à l’énumération, donc il n’est pas nécessaire d’avoir une structure en plus. Ceci nous permet de voir plus facilement un détail de fonctionnement des énumérations : le nom de chaque variante d’énumération que nous définissons devient aussi une fonction qui construit une instance de l’énumération. Ainsi, AdresseIp::V4() est un appel de fonction qui prend une String en argument et qui retourne une instance du type AdresseIp. Nous obtenons automatiquement cette fonction de constructeur qui est définie lorsque nous définissons l’énumération.
Il y a un autre avantage à utiliser une énumération plutôt qu’une structure : chaque variante peut stocker des types différents, et aussi avoir une quantité différente de données associées. Les adresses IP version quatre vont toujours avoir quatre composantes numériques qui auront une valeur entre 0 et 255. Si nous voulions stocker les adresses V4 avec quatre valeurs de type u8 mais continuer à stocker les adresses V6 dans une String, nous ne pourrions pas le faire avec une structure. Les énumérations permettent de faire cela facilement :
fn main() {
enum AdresseIp {
V4(u8, u8, u8, u8),
V6(String),
}
let local = AdresseIp::V4(127, 0, 0, 1);
let rebouclage = AdresseIp::V6(String::from("::1"));
}Nous avons vu différentes manières de définir des structures de données pour enregistrer des adresses IP en version quatre et version six. Cependant, il s’avère que vouloir stocker des adresses IP et identifier de quelle sorte elles sont est si fréquent que la bibliothèque standard a une définition que nous pouvons utiliser ! Analysons comment la bibliothèque standard a défini IpAddr (l’équivalent de notre AdresseIp) : nous retrouvons la même énumération et les variantes que nous avons définies et utilisées, mais les données d’adresse sont stockées dans les variantes par deux structures, qui ont une définition différente pour chaque variante :
#![allow(unused)]
fn main() {
struct Ipv4Addr {
// -- partie masquée ici --
}
struct Ipv6Addr {
// -- partie masquée ici --
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}Ce code montre comment vous pouvez insérer n’importe quel type de données dans une variante d’énumération : des chaînes de caractères, des nombres ou des structures, par exemple. Vous pouvez même y intégrer d’autres énumérations ! Par ailleurs, les types de la bibliothèque standard ne sont parfois pas plus compliqués que ce que vous pourriez inventer.
Notez aussi que même si la bibliothèque standard embarque une définition de IpAddr, nous pouvons quand même créer et utiliser notre propre définition de ce type sans avoir de conflit de nom car nous n’avons pas importé cette définition de la bibliothèque standard dans la portée. Nous verrons plus en détail comment importer les types dans la portée au chapitre 7.
Analysons un autre exemple d’une énumération dans l’encart 6-2 : celle-ci a une grande diversité de types dans ses variantes.
enum Message {
Quitter,
Deplacer { x: i32, y: i32 },
Ecrire(String),
ChangerCouleur(i32, i32, i32),
}
fn main() {}Message enum whose variants each store different amounts and types of valuesCette énumération a quatre variantes avec des types différents :
Quitter: n’a pas du tout de donnée associée.Deplacer: a des champs nommés, à l’instar d’une structure.Ecrire: intègre une seuleString.ChangerCouleur: intègre trois valeurs de typei32.
Définir une énumération avec des variantes comme celles dans l’encart 6-2 ressemble à la définition de différentes sortes de structures, sauf que l’énumération n’utilise pas le mot-clé struct et que toutes les variantes sont regroupées ensemble sous le type Message. Les structures suivantes peuvent stocker les mêmes données que celles stockées par les variantes précédentes :
struct MessageQuitter; // une structure unité
struct MessageDeplacer {
x: i32,
y: i32,
}
struct MessageEcrire(String); // une structure tuple
struct MessageChangerCouleur(i32, i32, i32); // une structure tuple
fn main() {}Mais si nous utilisions les différentes structures, qui ont chacune leur propre type, nous ne pourrions pas définir facilement une fonction qui prend en paramètre toutes les sortes de messages, tel que nous pourrions le faire avec l’énumération Message que nous avons définie dans l’encart 6-2, qui est un seul type.
Il y a un autre point commun entre les énumérations et les structures : tout comme on peut définir des méthodes sur les structures en utilisant impl, on peut aussi définir des méthodes sur des énumérations. Voici une méthode appelée appeler que nous pouvons définir sur notre énumération Message :
fn main() {
enum Message {
Quitter,
Deplacer { x: i32, y: i32 },
Ecrire(String),
ChangerCouleur(i32, i32, i32),
}
impl Message {
fn appeler(&self) {
// le corps de la méthode sera défini ici
}
}
let m = Message::Ecrire(String::from("hello"));
m.appeler();
}Le corps de la méthode va utiliser self pour obtenir la valeur sur laquelle nous avons utilisé la méthode. Dans cet exemple, nous avons créé une variable m qui a la valeur Message::Ecrire(String::from("hello")), et cela sera ce que self aura comme valeur dans le corps de la méthode appeler quand nous lancerons m.appeler().
Regardons maintenant une autre énumération de la bibliothèque standard qui est très utilisée et utile : Option.
L’énumération Option
Cette section étudie le cas de Option, qui est une autre énumération définie dans la bibliothèque standard. Le type Option décrit un scénario très courant où une valeur peut être soit quelque chose, soit rien du tout.
Par exemple, si vous demandez le premier élément dans une liste non vide, vous devriez obtenir une valeur. Si vous demandez le premier élément d’une liste vide, vous ne devriez rien obtenir. Exprimer ce concept avec le système de types implique que le compilateur peut vérifier si vous avez géré tous les cas que vous pourriez rencontrer ; cette fonctionnalité peut éviter des bogues qui sont très courants dans d’autres langages de programmation.
La conception d’un langage de programmation est souvent pensée en fonction des fonctionnalités qu’on inclut, mais les fonctionnalités qu’on refuse sont elles aussi importantes. Rust n’a pas de fonctionnalité null qu’ont de nombreux langages. Null est une valeur qui signifie qu’il n’y a pas de valeur à cet endroit. Avec les langages qui utilisent null, les variables peuvent toujours être dans deux états : null ou non null.
Lors d’une conférence en 2009 “Null References: The Billion Dollar Mistake” (les références nulles : l’erreur à un milliard de dollars), Tony Hoare, l’inventeur du null, a dit ceci :
Je l’appelle mon erreur à un milliard de dollars. À cette époque, je concevais le premier système de type complet pour des références dans un langage orienté objet. Mon objectif était de garantir que toutes les utilisations des références soient totalement sûres, et soient vérifiées automatiquement par le compilateur. Mais je n’ai pas pu résister à la tentation d’inclure la référence nulle, simplement parce que c’était si simple à implémenter. Cela a conduit à d’innombrables erreurs, vulnérabilités, et pannes systèmes, qui ont probablement causé un milliard de dollars de dommages au cours des quarante dernières années.
Le problème avec les valeurs nulles, c’est que si vous essayez d’utiliser une valeur nulle comme si elle n’était pas nulle, vous obtiendrez une erreur d’une façon ou d’une autre. Comme cette propriété nulle ou non nulle est omniprésente, il est très facile de faire cette erreur.
Cependant, le concept que null essaye d’exprimer reste utile : une valeur nulle est une valeur qui est actuellement invalide ou absente pour une raison ou une autre.
Le problème ne vient pas vraiment du concept, mais de son implémentation. C’est pourquoi Rust n’a pas de valeurs nulles, mais il a une énumération qui décrit le concept d’une valeur qui peut être soit présente, soit absente. Cette énumération est Option<T>, et elle est définie dans la bibliothèque standard comme ci-dessous :
#![allow(unused)]
fn main() {
enum Option<T> {
None,
Some(T),
}
}L’énumération Option<T> est tellement utile qu’elle est intégrée dans l’étape préliminaire ; vous n’avez pas besoin de l’importer explicitement dans la portée. Ses variantes sont aussi intégrées dans l’étape préliminaire : vous pouvez utiliser directement Some (quelque chose) et None (rien) sans les préfixer par Option::. L’énumération Option<T> reste une énumération normale, et Some(T) ainsi que None sont toujours des variantes de type Option<T>.
La syntaxe <T> est une fonctionnalité de Rust que nous n’avons pas encore abordée. Il s’agit d’un paramètre de type générique, et nous verrons la généricité plus en détail au chapitre 10. Pour le moment, dites-vous que ce <T> signifie que la variante Some de l’énumération Option peut stocker un élément de donnée de n’importe quel type, et que chaque type concret qui est utilisé à la place du T transforme tout le type Option<T> en un type différent. Voici quelques exemples d’utilisation de valeurs de Option pour stocker des types de nombres et des types de caractères :
fn main() {
let un_nombre = Some(5);
let un_caractere = Some('e');
let nombre_absent: Option<i32> = None;
}La variable un_nombre est du type Option<i32>. Mais la variable un_caractere est du type Option<char>, qui est un tout autre type. Rust peut déduire ces types car nous avons renseigné une valeur dans la variante Some. Pour nombre_absent, Rust nécessite que nous annotions le type de tout le Option : le compilateur ne peut pas déduire le type qui devrait être stocké dans la variante Some à partir de la valeur None. Ici, nous avons renseigné à Rust que nous voulions que nombre_absent soit du type Option<i32>.
Lorsque nous avons une valeur Some, nous savons que la valeur est présente et que la valeur est stockée dans le Some. Lorsque nous avons une valeur None, en quelque sorte, cela veut dire la même chose que null : nous n’avons pas une valeur valide. Donc en quoi obtenir Option<T> est-il meilleur que d’avoir null ?
En bref, comme Option<T> et T (où T représente n’importe quel type) sont de types différents, le compilateur ne va pas nous autoriser à utiliser une valeur Option<T> comme si cela était bien une valeur valide. Par exemple, le code suivant ne se compile pas car il essaye d’additionner un i8 et une Option<i8> :
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let somme = x + y;
}Si nous lançons ce code, nous aurons un message d’erreur comme celui-ci :
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let somme = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Intense ! Effectivement, ce message d’erreur signifie que Rust ne comprend pas comment additionner un i8 et une Option<i8>, car ils sont de types différents. Quand nous avons une valeur d’un type comme i8 avec Rust, le compilateur va s’assurer que nous avons toujours une valeur valide. Nous pouvons continuer en toute confiance sans avoir à vérifier que cette valeur n’est pas nulle avant de l’utiliser. Ce n’est que lorsque nous avons une Option<i8> (ou tout autre type de valeur avec lequel nous travaillons) que nous devons nous inquiéter de ne pas avoir de valeur, et le compilateur va s’assurer que nous gérons ce cas avant d’utiliser la valeur.
Autrement dit, vous devez convertir une Option<T> en T pour pouvoir faire avec elle des opérations du type T. Généralement, cela permet de résoudre l’un des problèmes les plus courants avec null : supposer qu’une valeur n’est pas nulle alors qu’en réalité, elle l’est.
Éliminer le risque que des valeurs nulles puissent être mal gérées vous aide à être plus confiant en votre code. Pour avoir une valeur qui peut potentiellement être nulle, vous devez l’indiquer explicitement en déclarant que le type de cette valeur est Option<T>. Ensuite, quand vous utiliserez cette valeur, il vous faudra gérer explicitement le cas où cette valeur est nulle. Si vous utilisez une valeur qui n’est pas une Option<T>, alors vous pouvez considérer que cette valeur ne sera jamais nulle sans prendre de risques. Il s’agit d’un choix de conception délibéré de Rust pour limiter l’omniprésence de null et augmenter la sécurité du code en Rust.
Donc, comment récupérer la valeur de type T d’une variante Some quand vous avez une valeur de type Option<T> afin de l’utiliser ? L’énumération Option<T> a un large choix de méthodes qui sont plus ou moins utiles selon les cas ; vous pouvez les découvrir dans sa documentation. Se familiariser avec les méthodes de Option<T> peut être très utile dans votre aventure avec Rust.
De manière générale, pour pouvoir utiliser une valeur de Option<T>, votre code doit gérer chaque variante. On veut que du code soit exécuté uniquement quand on a une valeur Some(T), et que ce code soit autorisé à utiliser la valeur de type T à l’intérieur. On veut aussi qu’un autre code soit exécuté seulement si on a une valeur None, et ce code n’aura pas de valeur de type T de disponible. L’expression match est une structure de contrôle qui fait bien ceci lorsqu’elle est utilisée avec les énumérations : elle va exécuter du code différent en fonction de quelle variante de l’énumération elle obtient, et ce code pourra utiliser la donnée présente dans la valeur correspondante.
La structure de contrôle de flux match
La structure de contrôle de flux match
Rust a une structure de contrôle de flux très puissante appelée match qui vous permet de comparer une valeur avec une série de motifs et d’exécuter du code en fonction du motif qui correspond. Les motifs peuvent être constitués de valeurs littérales, de noms de variables, de jokers, parmi tant d’autres ; le chapitre 19 va couvrir tous les différents types de motifs et ce qu’ils font. Ce qui fait la puissance de match est l’expressivité des motifs et le fait que le compilateur vérifie que tous les cas possibles sont bien gérés.
Considérez l’expression match comme une machine à trier les pièces de monnaie : les pièces descendent le long d’une piste avec des trous de tailles différentes, et chaque pièce tombe dans le premier trou à sa taille qu’elle rencontre. De manière similaire, les valeurs parcourent tous les motifs dans un match, et au premier motif auquel la valeur “correspond”, la valeur va descendre dans le bloc de code correspondant afin d’être utilisée pendant son exécution.
En parlant des pièces, utilisons-les avec un exemple qui utilise match ! Nous pouvons écrire une fonction qui prend en paramètre une pièce inconnue des États-Unis d’Amérique et qui peut, de la même manière qu’une machine à trier, déterminer de quelle pièce il s’agit et retourner sa valeur en centimes, comme ci-dessous dans l’encart 6-3.
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter,
}
fn valeur_en_centimes(piece: PieceUs) -> u8 {
match piece {
PieceUs::Penny => 1,
PieceUs::Nickel => 5,
PieceUs::Dime => 10,
PieceUs::Quarter => 25,
}
}
fn main() {}match expression that has the variants of the enum as its patternsDécomposons le match dans la fonction valeur_en_centimes. En premier lieu, nous utilisons le mot-clé match suivi par une expression, qui dans notre cas est la valeur de piece. Cela ressemble beaucoup à une expression conditionnelle utilisée avec if, mais il y a une grosse différence : avec if, la condition doit être évaluée comme une valeur booléenne, mais ici, elle peut être de n’importe quel type. Dans cet exemple, piece est de type PieceUs, qui est l’énumération que nous avons définie à la première ligne.
Ensuite, nous avons les branches du match. Une branche a deux parties : un motif et du code. La première branche a ici pour motif la valeur PieceUs::Penny et ensuite l’opérateur => qui sépare le motif et le code à exécuter. Le code dans ce cas est uniquement la valeur 1. Chaque branche est séparée de la suivante par une virgule.
Lorsqu’une expression match est exécutée, elle compare la valeur de piece avec le motif de chaque branche, dans l’ordre. Si un motif correspond à la valeur, le code correspondant à ce motif est alors exécuté. Si ce motif ne correspond pas à la valeur, l’exécution passe à la prochaine branche, un peu comme dans une machine de tri de pièces. Nous pouvons avoir autant de branches que nécessaire : dans l’encart 6-3, notre match a quatre branches.
Le code correspondant à chaque branche est une expression, et la valeur qui résulte de l’expression dans la branche correspondante est la valeur qui sera retournée par l’expression match.
Habituellement, nous n’utilisons pas les accolades si le code de la branche correspondante est court, comme c’est le cas dans l’encart 6-3 où chaque branche retourne simplement une valeur. Si vous voulez exécuter plusieurs lignes de code dans une branche d’un match, vous devez utiliser les accolades, et la virgule après la branche est optionnelle. Par exemple, le code suivant va afficher “Un centime porte-bonheur !” à chaque fois que la méthode est appelée avec une valeur PieceUs::Penny, mais va continuer à retourner la dernière valeur du bloc, 1 :
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter,
}
fn valeur_en_centimes(piece: PieceUs) -> u8 {
match piece {
PieceUs::Penny => {
println!("Un centime porte-bonheur !");
1
}
PieceUs::Nickel => 5,
PieceUs::Dime => 10,
PieceUs::Quarter => 25,
}
}
fn main() {}Des motifs reliés à des valeurs
Une autre fonctionnalité intéressante des branches de match est qu’elles peuvent se lier aux valeurs qui correspondent au motif. C’est ainsi que nous pouvons extraire des valeurs d’une variante d’énumération.
En guise d’exemple, changeons une de nos variantes d’énumération pour stocker une donnée à l’intérieur. Entre 1999 et 2008, les États-Unis d’Amérique ont frappé un côté des quarters (pièces de 25 centimes) avec des dessins différents pour chacun des 50 États. Les autres pièces n’ont pas eu de dessins d’États, donc seul le quarter a cette valeur en plus. Nous pouvons ajouter cette information à notre enum en changeant la variante Quarter pour y ajouter une valeur EtatUs qui y sera stockée à l’intérieur, comme nous l’avons fait dans l’encart 6-4.
#[derive(Debug)] // pour pouvoir afficher l'État
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn main() {}Coin enum in which the Quarter variant also holds a UsState valueImaginons qu’un de vos amis essaye de collectionner tous les quarters des 50 États. Pendant que nous trions notre monnaie en vrac par type de pièce, nous mentionnerons aussi le nom de l’État correspondant à chaque quarter de sorte que si notre ami ne l’a pas, il puisse l’ajouter à sa collection.
Dans l’expression match de ce code, nous avons ajouté une variable etat au motif qui correspond à la variante PieceUs::Quarter. Quand on aura une correspondance PieceUs::Quarter, la variable etat sera liée à la valeur de l’État de cette pièce. Ensuite, nous pourrons utiliser etat dans le code de cette branche, comme ceci :
#[derive(Debug)]
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn valeur_en_centimes(piece: PieceUs) -> u8 {
match piece {
PieceUs::Penny => 1,
PieceUs::Nickel => 5,
PieceUs::Dime => 10,
PieceUs::Quarter(etat) => {
println!("Il s'agit d'un quarter de l'État de {etat:?} !");
25
}
}
}
fn main() {
valeur_en_centimes(PieceUs::Quarter(EtatUs::Alaska));
}Si nous appelons valeur_en_centimes(PieceUs::Quarter(EtatUs::Alaska)), piece vaudra PieceUs::Quarter(EtatUs::Alaska). Quand nous comparons cette valeur avec toutes les branches du match, aucune d’entre elles ne correspondra jusqu’à ce qu’on arrive à PieceUs::Quarter(etat). À partir de ce moment, la variable etat aura la valeur EtatUs::Alaska. Nous pouvons alors utiliser cette variable dans l’expression println!, ce qui nous permet d’afficher la valeur de l’État à l’intérieur de la variante Quarter de l’énumération PieceUs.
Le modèle match Option<T>
Dans la section précédente, nous voulions obtenir la valeur interne T dans le cas de Some lorsqu’on utilisait Option<T> ; nous pouvons aussi gérer les Option<T> en utilisant match comme nous l’avons fait avec l’énumération PieceUs ! Au lieu de comparer des pièces, nous allons comparer les variantes de Option<T>, mais la façon d’utiliser l’expression match reste la même.
Disons que nous voulons écrire une fonction qui prend une Option<i32> et qui, s’il y a une valeur à l’intérieur, ajoute 1 à cette valeur. S’il n’y a pas de valeur à l’intérieur, la fonction retournera la valeur None et ne va rien faire de plus.
Cette fonction est très facile à écrire, grâce à match, et ressemblera à l’encart 6-5.
fn main() {
fn plus_un(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let cinq = Some(5);
let six = plus_un(cinq);
let none = plus_un(None);
}match expression on an Option<i32>Examinons la première exécution de plus_un en détail. Lorsque nous appelons plus_un(cinq), la variable x dans le corps de plus_un aura la valeur Some(5). Ensuite, nous comparons cela à chaque branche du match.
fn main() {
fn plus_un(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let cinq = Some(5);
let six = plus_un(cinq);
let none = plus_un(None);
}La valeur Some(5) ne correspond pas au motif None, donc nous continuons à la branche suivante :
fn main() {
fn plus_un(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let cinq = Some(5);
let six = plus_un(cinq);
let none = plus_un(None);
}Est-ce que Some(5) correspond au motif Some(i) ? Bien sûr ! Nous avons la même variante. Le i va prendre la valeur contenue dans le Some, donc i prend la valeur 5. Le code dans la branche du match est exécuté, donc nous ajoutons 1 à la valeur de i et nous créons une nouvelle valeur Some avec notre résultat 6 à l’intérieur.
Maintenant, regardons le second appel à plus_un dans l’encart 6-5, où x vaut None. Nous entrons dans le match et nous le comparons à la première branche :
fn main() {
fn plus_un(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let cinq = Some(5);
let six = plus_un(cinq);
let none = plus_un(None);
}Cela correspond ! Il n’y a pas de valeur à additionner, donc le programme s’arrête et retourne la valeur None qui est dans le côté droit du =>. Comme la première branche correspond, les autres branches ne sont pas comparées.
La combinaison de match et des énumérations est utile dans de nombreuses situations. Vous allez revoir de nombreuses fois ce schéma dans du code Rust : utiliser match sur une énumération, récupérer la valeur qu’elle renferme, et exécuter du code en fonction de sa valeur. C’est un peu délicat au début, mais une fois que vous vous y êtes habitué, vous regretterez de ne pas l’avoir dans les autres langages. Cela devient toujours l’outil préféré de ses utilisateurs.
Les match sont toujours exhaustifs
Il y a un autre point de match que nous devons aborder : les motifs des branches doivent couvrir toutes les possibilités. Examinez cette version de notre fonction plus_un qui a un bogue et ne va pas se compiler :
fn main() {
fn plus_un(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let cinq = Some(5);
let six = plus_un(cinq);
let none = plus_un(None);
}Nous n’avons pas géré le cas du None, donc ce code va générer un bogue. Heureusement, c’est un bogue que Rust sait gérer. Si nous essayons de compiler ce code, nous allons obtenir cette erreur :
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:593:1
::: /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:597:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust sait que nous n’avons pas couvert toutes les possibilités et sait même quel motif nous avons oublié ! Les match de Rust sont exhaustifs : nous devons traiter toutes les possibilités afin que le code soit valide. C’est notamment le cas avec Option<T> : quand Rust nous empêche d’oublier de gérer explicitement le cas de None, il nous protège d’une situation où nous supposons que nous avons une valeur alors que nous pourrions avoir null, ce qui rend impossible l’erreur à un milliard de dollars que nous avons vue précédemment.
Les motifs génériques et le motif _
En utilisant les énumérations, nous pouvons aussi appliquer des actions spéciales pour certaines valeurs précises, mais une action par défaut pour toutes les autres valeurs. Imaginons que nous implémentons un jeu dans lequel, si vous obtenez une valeur de 3 sur un lancé de dé, votre joueur ne se déplace pas, mais à la place il obtient un nouveau chapeau fantaisie. Si vous obtenez un 7, votre joueur perd son chapeau fantaisie. Pour toutes les autres valeurs, votre joueur se déplace de ce nombre de cases sur le plateau du jeu. Voici un match qui implémente cette logique, avec le résultat du lancé de dé codé en dur plutôt qu’issu d’une génération aléatoire, et toute la logique des autres fonctions sont des corps vides car leur implémentation n’est pas le sujet de cet exemple :
fn main() {
let jete_de_de = 9;
match jete_de_de {
3 => ajouter_chapeau_fantaisie(),
7 => enleve_chapeau_fantaisie(),
autre => deplace_joueur(autre),
}
fn ajouter_chapeau_fantaisie() {}
fn enleve_chapeau_fantaisie() {}
fn deplace_joueur(nombre_cases: u8) {}
}Dans les deux premières branches, les motifs sont les valeurs littérales 3 et 7. La dernière branche couvre toutes les autres valeurs possibles, le motif est la variable autre. Le code qui s’exécute pour la branche autre utilise la variable en la passant dans la fonction deplacer_joueur.
Ce code se compile, même si nous n’avons pas listé toutes les valeurs possibles qu’un u8 puisse avoir, car le dernier motif va correspondre à toutes les valeurs qui ne sont pas spécifiquement listées. Ce motif générique répond à la condition qu’un match doive être exhaustif. Notez que nous devons placer la branche avec le motif générique en tout dernier, car les motifs sont évalués dans l’ordre. Si nous avions placé la branche avec un motif générique plus tôt, les autres branches ne seraient jamais vérifiées ; voilà pourquoi Rust va nous prévenir si nous ajoutons des branches après un motif générique !
Rust a aussi un motif que nous pouvons utiliser lorsque nous voulons un cas générique mais nous n’avons pas besoin d’utiliser la valeur dans le motif générique : _, qui est un motif spécial qui vérifie n’importe quelle valeur et ne récupère pas cette valeur. Ceci indique à Rust que nous n’allons pas utiliser la valeur, donc Rust ne va pas nous prévenir qu’il y a une variable non utilisée.
Changeons les règles du jeu : maintenant, si nous obtenons autre chose qu’un 3 ou un 7, nous devons jeter à nouveau le dé. Nous n’avons plus besoin d’utiliser la valeur dans ce cas, donc nous pouvons changer notre code pour utiliser _ au lieu de la variable autre :
fn main() {
let jete_de_de = 9;
match jete_de_de {
3 => ajouter_chapeau_fantaisie(),
7 => enleve_chapeau_fantaisie(),
_ => relancer(),
}
fn ajouter_chapeau_fantaisie() {}
fn enleve_chapeau_fantaisie() {}
fn relancer() {}
}Cet exemple répond bien aux critères d’exhaustivité car nous ignorons explicitement toutes les autres valeurs dans la dernière branche ; nous n’avons rien oublié.
Finalement, nous changeons à nouveau les règles du jeu, afin que rien se passe si vous obtenez autre chose qu’un 3 ou un 7, nous pouvons exprimer cela en utilisant la valeur unité (le type tuple vide que nous avons cité dans une section précédente) dans le code de la branche _ :
fn main() {
let jete_de_de = 9;
match jete_de_de {
3 => ajouter_chapeau_fantaisie(),
7 => enleve_chapeau_fantaisie(),
_ => (),
}
fn ajouter_chapeau_fantaisie() {}
fn enleve_chapeau_fantaisie() {}
}Ici, nous indiquons explicitement à Rust que nous n’allons pas utiliser d’autres valeurs qui ne correspondent pas à un motif des branches antérieures, et nous ne voulons lancer aucun code dans ce cas.
Il existe aussi d’autres motifs que nous allons voir dans le chapitre 19. Pour l’instant, nous allons voir l’autre syntaxe if let, qui peut se rendre utile dans des cas où l’expression match est trop verbeuse.
Gestion concise du flux d'éxécution avec if let et let...else
Gestion concise du flux d’éxécution avec if let et let...else
La syntaxe if let vous permet de combiner if et let afin de gérer les valeurs qui correspondent à un motif donné, tout en ignorant les autres. Imaginons le programme dans l’encart 6-6 qui fait un match sur la valeur Option<u8> de la variable config_max mais n’a besoin d’exécuter du code que si la valeur est la variante Some.
fn main() {
let config_max = Some(3u8);
match config_max {
Some(max) => println!("Le maximum est réglé sur {max}"),
_ => (),
}
}match that only cares about executing code when the value is SomeSi la valeur est un Some, nous affichons la valeur dans la variante Some en associant la valeur à la variable max dans le motif. Nous ne voulons rien faire avec la valeur None. Pour satisfaire l’expression match, nous devons ajouter _ => () après avoir géré une seule variante, ce qui est du code inutile.
À la place, nous pourrions écrire le même programme de manière plus concise en utilisant if let. Le code suivant se comporte comme le match de l’encart 6-6 :
fn main() {
let config_max = Some(3u8);
if let Some(max) = config_max {
println!("Le maximum est réglé sur {max}");
}
}La syntaxe if let prend un motif et une expression séparés par un signe égal. Elle fonctionne de la même manière qu’un match où l’expression est donnée au match et où le motif est sa première branche. Dans ce cas, le motif est Some(max), et le max est associé à la valeur dans le Some. Nous pouvons ensuite utiliser max dans le corps du bloc if let de la même manière que nous avons utilisé max dans la branche correspondante au match. Le code dans le bloc if let n’est exécuté que si la valeur correspond au motif.
Utiliser if let permet d’écrire moins de code, et de moins l’indenter. Cependant, vous perdez la vérification de l’exhaustivité imposée par match, qui garantit que vous n’oubliez aucun cas. Choisir entre match et if let dépend de la situation : à vous de choisir s’il vaut mieux être concis ou appliquer une vérification exhaustive.
Autrement dit, vous pouvez considérer le if let comme du sucre syntaxique pour un match qui exécute du code uniquement quand la valeur correspond à un motif donné et ignore toutes les autres valeurs.
Nous pouvons joindre un else à un if let. Le bloc de code qui va dans le else est le même que le bloc de code qui va dans le cas _ avec l’expression match. Souvenez-vous de la définition de l’énumération PieceUs de l’encart 6-4, où la variante Quarter stockait aussi une valeur EtatUs. Si nous voulions compter toutes les pièces qui ne sont pas des quarters que nous voyons passer, tout en affichant l’État des quarters, nous pourrions le faire avec une expression match comme ceci :
#[derive(Debug)]
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn main() {
let piece = PieceUs::Penny;
let mut compteur = 0;
match piece {
PieceUs::Quarter(etat) => println!("Il s'agit d'un quarter de l'État de {etat:?} !"),
_ => compteur += 1,
}
}Ou nous pourrions utiliser une expression if let/else comme ceci :
#[derive(Debug)]
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn main() {
let piece = PieceUs::Penny;
let mut compteur = 0;
if let PieceUs::Quarter(etat) = piece {
println!("Il s'agit d'un quarter de l'État de {etat:?} !");
} else {
compteur += 1;
}
}Rester sur la « voie royale » avec let...else
Un cas courant consiste à faire un calcul lorsqu’une valeur est présente et à renvoyer une valeur par défaut dans le cas contraire. Pour reprendre notre exemple des pièces de monnaie avec une valeur EtatUs, si nous voulions faire une remarque amusante en fonction de l’ancienneté de l’État figurant sur la pièces de 25 cents, nous pourrions ajouter une méthode dans EtatUs pour vérifier l’ancienneté d’un État, comme ceci :
#[derive(Debug)] // pour pouvoir afficher l'État
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
impl EtatUs {
fn existait_en(&self, annee: u16) -> bool {
match self {
EtatUs::Alabama => annee >= 1819,
EtatUs::Alaska => annee >= 1959,
// -- snip --
}
}
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn decrit_etat_quarter(piece: PieceUs) -> Option<String> {
if let PieceUs::Quarter(etat) = piece {
if etat.existait_en(1900) {
Some(format!("{etat:?} est assez vieux, pour le continent américain !"))
} else {
Some(format!("{etat:?} est assez jeune."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = decrit_etat_quarter(PieceUs::Quarter(EtatUs::Alaska)) {
println!("{desc}");
}
}Ensuite, nous pourrions utiliser if let afin d’effectuer une vérification en fonction du type de la pièces, en introduisant une variable etat dans le corps de la condition, comme montré dans l’encart 6-7 :
#[derive(Debug)] // pour pouvoir afficher l'État
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
impl EtatUs {
fn existait_en(&self, annee: u16) -> bool {
match self {
EtatUs::Alabama => annee >= 1819,
EtatUs::Alaska => annee >= 1959,
// -- snip --
}
}
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn decrit_etat_quarter(piece: PieceUs) -> Option<String> {
if let PieceUs::Quarter(etat) = piece {
if etat.existait_en(1900) {
Some(format!("{etat:?} est assez vieux, pour le continent américain !"))
} else {
Some(format!("{etat:?} est assez jeune."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = decrit_etat_quarter(PieceUs::Quarter(EtatUs::Alaska)) {
println!("{desc}");
}
}if letCela permet d’atteindre l’objectif, mais ça a déplacé le traitement dans le corps de l’instruction if let, et si le traitement à effectuer est plus complexe, il peut être difficile de suivre exactement les relations entre les branches de niveau supérieur. Nous pourrions aussi tirer parti du fait que les expressions produisent une valeur, soit pour générer etat depuis le if let, soit pour sortir prématurément, comme dans l’encart 6-8 (vous pourriez faire quelque chose de similaire avec une instruction match).
#[derive(Debug)] // pour pouvoir afficher l'État
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
impl EtatUs {
fn existait_en(&self, annee: u16) -> bool {
match self {
EtatUs::Alabama => annee >= 1819,
EtatUs::Alaska => annee >= 1959,
// -- snip --
}
}
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn decrit_etat_quarter(piece: PieceUs) -> Option<String> {
let state = if let Coin::Quarter(state) = coin {
state
} else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = decrit_etat_quarter(PieceUs::Quarter(EtatUs::Alaska)) {
println!("{desc}");
}
}if let to produce a value or return earlyC’est quand même assez déroutant à suivre, à sa manière ! L’une des branches du if let produit une valeur, et l’autre quitte purement et simplement la fonction.
Afin de rendre ce cas courant plus agréable à exprimer, Rust a la construction let...else. La syntaxe de let...else comprend un motif du côté gauche et une expression du côté droit, de manière très similaire à if let, mais sans avoir de branche if, seulement une branche else. Si le motif ne correspond pas, le programme partira dans la branche else, qui doit quitter la fonction.
Dans l’encart 6-9, vous pouvez voir à quoi ressemble l’encart 6-8 si on utilise let...else à la place de if let.
#[derive(Debug)] // pour pouvoir afficher l'État
enum EtatUs {
Alabama,
Alaska,
// -- partie masquée ici --
}
impl EtatUs {
fn existait_en(&self, annee: u16) -> bool {
match self {
EtatUs::Alabama => annee >= 1819,
EtatUs::Alaska => annee >= 1959,
// -- snip --
}
}
}
enum PieceUs {
Penny,
Nickel,
Dime,
Quarter(EtatUs),
}
fn decrit_etat_quarter(piece: PieceUs) -> Option<String> {
let Coin::Quarter(state) = coin else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = decrit_etat_quarter(PieceUs::Quarter(EtatUs::Alaska)) {
println!("{desc}");
}
}let...else to clarify the flow through the functionNotez bien qu’ainsi, on reste sur la « voie royale » dans le corps principal de la fonction, sans que le flux de contrôle diffère de manière significative entre les deux branches, contrairement à ce qui se passait avec if let.
Si vous trouvez que votre programme est alourdi par l’utilisation d’un match, souvenez-vous que if let et let...else sot aussi présents dans votre boîte à outils Rust.
Résumé
Nous avons désormais appris comment utiliser les énumérations pour créer des types personnalisés qui peuvent faire partie d’un jeu de valeurs recensées. Nous avons montré comment le type Option<T> de la bibliothèque standard vous aide à utiliser le système de types pour éviter les erreurs. Lorsque les valeurs d’énumération contiennent des données, vous pouvez utiliser match ou if let pour extraire et utiliser ces valeurs, à choisir en fonction du nombre de cas que vous voulez gérer.
Vos programmes Rust peuvent maintenant décrire des concepts métier à l’aide de structures et d’énumérations. Créer des types personnalisés à utiliser dans votre API assure la sécurité des types : le compilateur s’assurera que vos fonctions ne reçoivent que des valeurs du type attendu.
Afin de fournir une API bien organisée, simple à utiliser et qui n’expose que ce dont vos utilisateurs auront besoin, découvrons maintenant les modules de Rust.
Paquets, crates et modules
Lorsque vous commencerez à écrire des gros programmes, organiser votre code va devenir de plus en plus important car vous ne pourrez plus garder en tête l’intégralité de votre programme. En regroupant des fonctionnalités qui ont des points communs et en les séparant des autres fonctionnalités, vous clarifiez l’endroit où trouver le code qui implémente une fonctionnalité spécifique afin de pouvoir le relire ou le modifier.
Les programmes que nous avons écrits jusqu’à présent étaient dans un module au sein d’un seul fichier. À mesure que le projet grandit, vous devriez organiser votre code en le découpant en plusieurs modules et ensuite en plusieurs fichiers. Un paquet peut contenir plusieurs crates binaires et accessoirement une crate de bibliothèque. À mesure qu’un paquet grandit, vous pouvez en extraire des parties dans des crates séparées qui deviennent des dépendances externes. Ce chapitre va aborder toutes ces techniques. Pour un projet de très grande envergure qui a des paquets interconnectés qui évoluent ensemble, Cargo propose les espaces de travail, que nous découvrirons dans une section du chapitre 14.
Nous aborderons aussi le sujet de l’encapsulation des détails de l’implémentation d’une opération : vous pouvez écrire du code puis l’utiliser comme une abstraction à travers l’interface de programmation publique (API) du code sans vous soucier de connaître les détails de son implémentation. La façon dont vous écrivez votre code définit quelles parties sont publiques et donc utilisables par un autre code, et quelles parties sont des détails d’implémentation privés dont vous vous réservez le droit de modification. C’est un autre moyen de limiter le nombre d’éléments de l’API pour celui qui l’utilise.
Un concept qui lui est associé est la portée : le contexte dans lequel le code est écrit a un jeu de noms qui sont définis comme “dans la portée”. Quand ils lisent, écrivent et compilent du code, les développeurs et les compilateurs ont besoin de savoir ce que tel nom désigne à tel endroit, et s’il s’agit d’une variable, d’une fonction, d’une structure, d’une énumération, d’un module, d’une constante, etc. Vous pouvez créer des portées et décider quels noms sont dans la portée ou non. Vous ne pouvez pas avoir deux entités avec le même nom dans la même portée ; cependant, des outils existent pour résoudre les conflits de nom.
Rust a de nombreuses fonctionnalités qui vous permettent de gérer l’organisation de votre code, grâce à ce que la communauté Rust appelle le système de modules. Ce système définit quels sont les éléments qui sont accessibles depuis l’extérieur de la bibliothèque (notion de privé ou public), ainsi que leur portée. Ces fonctionnalités comprennent :
- les paquets : une fonctionnalité de Cargo qui vous permet de compiler, tester, et partager des crates ;
- les crates : une arborescence de modules qui fournit une bibliothèque ou un exécutable ;
- les modules et use : utilisés avec le mot-clé
use, les modules vous permettent de contrôler l’organisation, la portée et la visibilité des chemins ; - les chemins : une façon de nommer un élément, comme une structure, une fonction ou un module.
Dans ce chapitre, nous allons découvrir ces fonctionnalités, voir comment elles interagissent, et expliquer comment les utiliser pour gérer les portées. À l’issue de ce chapitre, vous aurez de solides connaissances sur le système de modules et vous pourrez travailler avec les portées comme un pro !
Les paquets et les crates
Les paquets et les crates
La première partie du système de modules que nous allons aborder concerne les paquets et les crates.
Une crate est la plus petite quantité de code que le compilateur Rust considère à la fois. Même si vous exécutez rustc au lieu de cargo et que vous passez un seul fichier source (comme nous l’avons fait dans la partie “Hello, World !” du chapitre 1), le compilateur considère ce fichier comme une crate. Les crates peuvent contenir des modules, et les modules peuvent être définis dans d’autres fichiers qui se trouveront compilés avec la crate, comme nous le verrons dans les prochaines sections.
Une crate peut se présenter sous l’une de ces deux formes : une crate binaire ou bien une crate de bibliothèque. Les crates binaires sont des programmes qui peuvent être compilés sous forme d’un exécutable qui peut être exécuté, comme un programme en ligne de commande ou encore un serveur. Chaque doit avoir une fonction appelée main qui définit ce qui se passe lorsque l’exécutable tourne. Toutes les crates que nous avons créé jusqu’ici sont des crates binaires.
Les crates de bibliothèque n’ont pas de fonction main, et elles ne se compilent pas en un exécutable. À la place, elles définissent des fonctionnalités destinées à être partagée par de multiples projets. Par exemple, la crate rand que nous avons utilisée dans le chapitre 2 fournit des fonctionnalités qui génèrent des nombres au hasard. La plupart du temps, quand les Rustacés parlent de « crate », ils font référence à une crate de bibliothèque, et ils utilisent le terme « crate » de manière interchangeable avec le concept général de « bibliothèque » en programmation.
La crate racine est un fichier source à partir duquel le compilateur Rust commence son travail et qui constitue le module racine de votre crate (nous verrons les modules plus en détail dans la section suivante.
Un paquet est un ensemble d’une ou plusieurs crates qui fournissent un ensemble de fonctionnalités. Un paquet continent un fichier Cargo.toml qui décrit comment construire ces crates. Cargo est en fait un paquet qui contient la crate binaire pour l’outil en ligne de commande que vous avez utilisé pour construire votre code. Le paquet Cargo contient aussi une crate de bibliothèque dont dépent la crate binaire. D’autres projets peuvent dépendre de la crate bibliothèque de Cargo pour utiliser la même logique que celle utilisée par l’outil en ligne de commande de Cargo.
Un paquet peut contenir autant de crates binaires que vous le souhaitez, mais au plus une crate de bibliothèque. Un paquet doit contenir au moins une crate, que ce soit une bibliothèque ou un binaire.
Découvrons ce qui se passe quand nous créons un paquet. D’abord, nous utilisons la commande cargo new :
$ cargo new mon-projet
Created binary (application) `mon-projet` package
$ ls mon-projet
Cargo.toml
src
$ ls mon-projet/src
main.rs
Après avoir lancé la commande cargo new mon-projet, nous utilisons ls pour voir ce que Cargo a créé. Dan le répertoire my-project, Cargo a créé un fichier Cargo.toml, qui définit un paquet. Si on regarde le contenu de Cargo.toml, le fichier src/main.rs n’est pas mentionné car Cargo obéit à une convention selon laquelle src/main.rs est la racine de la crate binaire portant le même nom que le paquet. De la même façon, Cargo sait que si le répertoire du paquet contient src/lib.rs, alors le paquet contient une crate de bibliothèque qui a le même nom que le paquet, et que src/lib.rs est sa racine. Cargo transmet les fichiers de la crate racine à rustc pour compiler la bibliothèque ou le binaire.
Dans notre cas, nous avons un paquet qui contient uniquement src/main.rs, ce qui veut dire qu’il contient uniquement une crate binaire qui s’appelle mon-projet. Si un paquet contient src/main.rs et src/lib.rs, il a deux crates : une binaire et une bibliothèque, chacune avec le même nom que le paquet. Un paquet peut avoir plusieurs crates binaires en ajoutant des fichiers dans le répertoire src/bin : chaque fichier sera une crate séparée.
Gestion de la portée et de la visibilité avec les modules
Gestion de la portée et de la visibilité avec les modules
Dans cette section, nous allons aborder les modules et les autres outils du système de modules, à savoir les chemins qui nous permettent de nommer les éléments ; l’utilisation du mot-clé use qui importe un chemin dans la portée ; et le mot-clé pub qui rend publics les éléments. Nous verrons aussi le mot-clé as, les paquets externes, et l’opérateur glob.
Aide-mémoire sur les modules
Avant de rentrer dans le vif du sujet des modules et des chemins, voyons un guide de référence rapide concernant le fonctionnement des modules, des chemins d’accès, des mot-clés use et pub dans le compilateur, et la manière dont la plupart des développeurs organisent leur code. Nous aborderons des exemples de chacune de ces règles tout au long de ce chapitre, mais ceci est un bon point de référence pour vous rappeler comment les modules fonctionnement.
- Commencez à partir de la crate racine : au moment de compiler une crate, le compilateur cherche dans le fichier de la crate racine (généralement src/lib.rs pour une crate de bibliothèque et src/main.rs pour une crate binaire) pour trouver le code à compiler.
- Déclaration des modules : dans le fichier de la crate racine, vous pouvez déclarer de nouveaux modules ; par exemple, si vous déclarez un module « jardin » avec
mod jardin;, le compilateur cherchera le code du module dans ces emplacements :“- en ligne, dans la paire d’accolades qui remplacent le point-virgule qui suit
mod jardin; - dans le fichier src/jardin.rs ;
- dans le fichier src/jardin/mod.rs.
- en ligne, dans la paire d’accolades qui remplacent le point-virgule qui suit
- Déclaration de sous-modules : dans tout fichier autre que la crate racine, vous pouvez déclarer des sous-modules. Par exemple, vous pouvez déclarer
mod legumes;dans src/garden.rs. Le compilateur cherchera le code du sous-module dans le répertoire portant le nom du module parent aux emplacements suivants :- en ligne, directement après
mod legumes, à l’intérieur des accolades à la place du point-virgule ; - dans le fichier src/jardin/legumes.rs ;
- dans le fichier src/jardin/legumes/mod.rs.
- en ligne, directement après
- Chemins d’accès au code dans les modules : une fois qu’un module fait partie de votre crate, vous pouvez faire référence au code de ce module à partir de n’importe quel autre endroit dans la même crate, du moment que les règles de visibilité le permettent, en utilisant le chemin d’accès au code. Par exemple, un type
Aspergedans le module jardin legumes se trouverait à l’adressecrate::jardin::legumes::Asperge. - Privé ou public : le code situé dans un module est par défaut privé vis-à-vis de ses modules parents. Pour rendre un module public, déclarez-le avec
pub modau lieu demod. Pour rendre publics les éléments d’un module public , utilisezpubavant leur déclaration. - Le mot-clé
use: à l’intérieur d’une portée, le mot-cléusecrée des raccourcis vers des éléments afin de réduire la répétition de longs chemins d’accès. Dans toute portée qui peut faire référence àcrate::jardin::legumes::Asperge, vous pouvez créer un raccourci avecuse crate::jardin::legumes::Aspergepour utiliser ce type dans cette portée.
Ici, nous allons créer une crate binaire nommée cour qui illustre ces règles. Le répertoire de la crate, aussi nommé cour, contient les fichiers et répertoires suivants :
cour
├── Cargo.lock
├── Cargo.toml
└── src
├── jardin
│ └── vegetables.rs
├── jardin.rs
└── main.rs
Le fichier de la crate racine est dans ce cas src/main.rs, et il contient :
use crate::jardin::legumes::Asperge;
pub mod jardin;
fn main() {
let plante = Asperge {};
println!("Je fais pousser {plante:?}!");
}La ligne pub mod jardin; dit au compilateur d’inclure le code qu’il trouve dans src/jardin.rs, lequel est :
pub mod legumes;Ici, pub mod legumes; signifie le code dans src/jardin/legumes.rs est également inclus. Ce code est :
#[derive(Debug)]
pub struct Asperge {}Voyons maintenant en détail ces règles et voyons leur application dans la pratique !
Regroupement de codes associés dans les modules
Les modules nous permettent d’organiser le code d’une crate, pour une meilleure lisibilité et pour la facilité de réutilisation. Les modules nous permettent aussi de gérer la visibilité des éléments car le code dans un module est privé par défaut. Les éléments privés sont des détails d’implémentations internes qui ne sont pas accessibles à l’extérieur. Nous pouvons choisir de rendre publics les modules ainsi que les éléments qu’ils contiennent, ce qui les expose afin de permettre à du code externe de les utiliser et d’en dépendre.
Voici un exemple : écrivons une crate de bibliothèque qui permet de simuler un restaurant. Nous allons définir les signatures des fonctions mais nous allons laisser leurs corps vides pour nous concentrer sur l’organisation du code, plutôt que de coder pour de vrai un restaurant.
Dans le secteur de la restauration, certaines parties d’un restaurant sont assimilées à la salle à manger et d’autres aux cuisines. La partie salle à manger est l’endroit où se trouvent les clients ; c’est l’endroit où les hôtes installent les clients, où les serveurs prennent les commandes et encaissent les clients, et où les barmans préparent des boissons. Dans la partie cuisines, nous retrouvons les chefs et les cuisiniers qui travaillent dans la cuisine, mais aussi les plongeurs qui nettoient la vaisselle et les gestionnaires qui s’occupent des tâches administratives.
Pour organiser notre crate de cette manière, nous pouvons organiser les fonctions avec des modules imbriqués. Créez une nouvelle bibliothèque qui s’appelle restaurant en utilisant cargo new restaurant --lib. Puis écrivez le code de l’encart 7-1 dans src/lib.rs afin de définir quelques modules et quelques signatures de fonctions ; ce code constitue la partie de la salle à manger.
mod salle_a_manger {
mod accueil {
fn ajouter_a_la_liste_attente() {}
fn installer_a_une_table() {}
}
mod service {
fn prendre_commande() {}
fn servir_commande() {}
fn encaisser() {}
}
}front_of_house module containing other modules that then contain functionsNous définissons un module avec le mot-clé mod suivi par le nom du module (dans notre cas, salle_a_manger). Le corps du module est ensuite placé à l’intérieur d’accolades. Dans les modules, nous pouvons avoir d’autres modules, comme dans notre cas avec les modules accueil et service. Les modules peuvent aussi contenir des définitions pour d’autres éléments, comme des structures, des énumérations, des constantes, des traits, ou des fonctions (comme c’est le cas dans l’encart 7-1).
Grâce aux modules, nous pouvons regrouper ensemble des définitions qui sont liées et donner un nom à ce lien. Les développeurs qui utiliseront ce code pourront parcourir le code en fonction des groupes plutôt que d’avoir à lire toutes les définitions, ce qui permet de trouver plus facilement les définitions dont ils ont besoin. Les développeurs qui veulent rajouter des nouvelles fonctionnalités à ce code sauront maintenant où placer le code tout en gardant le programme organisé.
Précédemment, nous avons dit que src/main.rs et src/lib.rs étaient des crates racines. Nous les appelons ainsi car le contenu de chacun de ces deux fichiers constitue un module qui s’appelle crate à la racine de l’arborescence du module.
L’encart 7-2 présente l’arborescence du module pour la structure de l’encart 7-1.
crate
└── salle_a_manger
├── accueil
│ ├── ajouter_a_la_liste_attente
│ └── installer_a_une_table
└── service
├── prendre_commande
├── servir_commande
└── encaisser
Cette arborescence montre comment les modules sont imbriqués entre eux ; par exemple, accueil est imbriqué dans salle_a_manger. L’arborescence montre aussi que certains modules sont les frères d’autres modules, ce qui veut dire qu’ils sont définis dans le même module ; accueil et service sont définis dans salle_a_manger. Pour prolonger la métaphore familiale, si le module A est contenu dans le module B, on dit que le module A est l’enfant du module B et que ce module B est le parent du module A. Notez aussi que le module implicite nommé crate est le parent de toute cette arborescence.
L’arborescence des modules peut rappeler les répertoires du système de fichiers de votre ordinateur ; et c’est une excellente comparaison ! Comme les répertoires dans un système de fichiers, vous utilisez les modules pour organiser votre code. Et comme pour les fichiers dans un répertoire, nous avons besoin d’un moyen de trouver nos modules.
Désigner un élément dans l'arborescence de modules
Désigner un élément dans l’arborescence de modules
Pour indiquer à Rust où trouver un élément dans l’arborescence de modules, nous utilisons un chemin à l’instar des chemins que nous utilisons lorsque nous naviguons dans un système de fichiers. Pour appeler une fonction, nous avons besoin de connaître son chemin.
Il existe deux types de chemins :
- Un chemin absolu est le chemin complet à partir d’une crate racine ; pour du code d’une crate externe, le chemin absolu commence par le nom de la crate, et pour le code de la crate courante, il commence avec le terme
crate. - Un chemin relatif commence à partir du module courant et utilise
self,super, ou un identificateur à l’intérieur du module.
Les chemins absolus et relatifs sont suivis par un ou plusieurs identificateurs séparés par ::.
En revenant à notre exemple de l’encart 7-1, disons que nous voulons appeler la fonction ajouter_a_la_liste_attente. Cela revient à se demander : quel est le chemin de la fonction ajouter_a_la_liste_attente ? L’encart 7-3 contient l’encart 7-1 avec quelques modules et fonctions qui ont été enlevés.
Nous allons voir deux façons d’appeler la fonction ajouter_a_la_liste_attente à partir d’une nouvelle fonction manger_au_restaurant définie dans la crate racine. Ces chemins sont corrects, mails il y a un autre problème qui empêche la compilation de ce programme tel quel. Nous allons en expliquer la raison un peu plus tard.
La fonction manger_au_restaurant fait partie de l’API publique de notre crate de bibliothèque, nous la marquons donc avec le mot-clé pub.
mod salle_a_manger {
mod accueil {
fn ajouter_a_la_liste_attente() {}
}
}
pub fn manger_au_restaurant() {
// Chemin absolu
crate::salle_a_manger::accueil::ajouter_a_la_liste_attente();
// Chemin relatif
salle_a_manger::accueil::ajouter_a_la_liste_attente();
}add_to_waitlist function using absolute and relative pathsAu premier appel de la fonction ajouter_a_la_liste_attente dans manger_au_restaurant, nous utilisons un chemin absolu. La fonction ajouter_a_la_liste_attente est définie dans la même crate que manger_au_restaurant, ce qui veut dire que nous pouvons utiliser le mot-clé crate pour démarrer un chemin absolu. Ensuite, nous ajoutons chacun des modules successifs jusqu’à ajouter_a_la_liste_attente. Nous pouvons faire l’analogie avec un système de fichiers qui aurait la même structure : nous pourrions utiliser le chemin /salle_a_manger/accueil/ajouter_a_la_liste_attente pour lancer le programme ajouter_a_la_liste_attente ; utiliser le nom crate pour partir de la racine de la crate revient à utiliser / pour partir de la racine de votre système de fichiers dans votre invite de commande.
Lors du second appel à ajouter_a_la_liste_attente dans manger_au_restaurant, nous utilisons un chemin relatif. Le chemin commence par salle_a_manger, le nom du module qui est défini au même niveau que manger_au_restaurant dans l’arborescence de modules. Ici, l’équivalent en terme de système de fichier serait le chemin salle_a_manger/accueil/ajouter_a_la_liste_attente. Commencer par un nom de module signifie que le chemin est relatif.
Choisir entre utiliser un chemin relatif ou absolu sera une décision que vous ferez en fonction de votre projet, cela dépendra de si vous êtes susceptible de déplacer la définition de l’élément souhaité séparément ou en même temps que le code qui l’utilise. Par exemple, si nous déplaçons le module salle_a_manger ainsi que la fonction manger_au_restaurant dans un module qui s’appelle experience_client, nous aurons besoin de mettre à jour le chemin absolu vers ajouter_a_la_liste_attente, mais le chemin relatif restera valide. Cependant, si nous avions déplacé uniquement la fonction manger_au_restaurant dans un module repas séparé, le chemin absolu de l’appel à ajouter_a_la_liste_attente restera le même, mais le chemin relatif aura besoin d’être mis à jour. Notre préférence est généralement d’utiliser un chemin absolu car il est plus facile de déplacer les définitions de code et les appels aux éléments indépendamment les uns des autres.
Essayons de compiler l’encart 7-3 et essayons de comprendre pourquoi il ne se compile pas pour le moment ! Les erreurs que nous obtenons sont affichées dans l’encart 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `accueil` is private
--> src/lib.rs:9:28
|
9 | crate::salle_a_manger::accueil::ajouter_a_la_liste_attente();
| ^^^^^^^ -------------------------- function `ajouter_a_la_liste_attente` is not publicly re-exported
| |
| private module
|
note: the module `accueil` is defined here
--> src/lib.rs:2:5
|
2 | mod accueil {
| ^^^^^^^^^^^
error[E0603]: module `accueil` is private
--> src/lib.rs:12:21
|
12 | salle_a_manger::accueil::ajouter_a_la_liste_attente();
| ^^^^^^^ -------------------------- function `ajouter_a_la_liste_attente` is not publicly re-exported
| |
| private module
|
note: the module `accueil` is defined here
--> src/lib.rs:2:5
|
2 | mod accueil {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Le message d’erreur nous rappelle que ce module accueil est privé. Autrement dit, nous avons des chemins corrects pour le module accueil et pour la fonction ajouter_a_la_liste_attente, mais Rust ne nous laisse pas les utiliser car il n’a pas accès aux sections privées. En Rust, tous les éléments (fonctions, méthodes, structures, énumérations, modules et constantes) sont privés pour leur module parent par défaut. Si vous voulez rendre privé un élément comme une fonction ou une structure, il vous suffit de le placer dans un module.
Les éléments dans un module parent ne peuvent pas utiliser les éléments privés dans les modules enfants, mais les éléments dans les modules enfants peuvent utiliser les éléments dans les modules parents. C’est parce que les modules enfants englobent et cachent les détails de leur implémentation, mais les modules enfants peuvent voir dans quel contexte ils sont définis. Pour continuer notre métaphore du restaurant, considérez que les règles de visibilité de Rust fonctionnent comme les cuisines d’un restaurant : ce qui s’y passe n’est pas connu des clients, mais les gestionnaires peuvent tout voir et tout faire dans le restaurant dans lequel ils travaillent.
Rust a décidé de faire fonctionner le système de modules de façon à ce que les détails d’implémentation interne sont cachés par défaut. Ainsi, vous savez quelles parties du code interne vous pouvez changer sans casser le code externe. Cependant, Rust vous permet d’avoir l’option d’exposer aux parents des parties internes des modules enfants en utilisant le mot-clé pub afin de les rendre publiques.
Exposer des chemins avec le mot-clé pub
Retournons à l’erreur de l’encart 7-4 qui nous informe que le module accueil est privé. Nous voulons que la fonction manger_au_restaurant du module parent ait accès à la fonction ajouter_a_la_liste_attente du module enfant, donc nous utilisons le mot-clé pub sur le module accueil, comme dans l’encart 7-5.
mod salle_a_manger {
pub mod accueil {
fn ajouter_a_la_liste_attente() {}
}
}
// -- partie masquée ici --
pub fn manger_au_restaurant() {
// Chemin absolu
crate::salle_a_manger::accueil::ajouter_a_la_liste_attente();
// Chemin relatif
salle_a_manger::accueil::ajouter_a_la_liste_attente();
}hosting module as pub to use it from eat_at_restaurantMalheureusement, il reste une erreur dans le code de l’encart 7-5, la voici dans l’encart 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `ajouter_a_la_liste_attente` is private
--> src/lib.rs:10:37
|
10 | crate::salle_a_manger::accueil::ajouter_a_la_liste_attente();
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ private function
|
note: the function `ajouter_a_la_liste_attente` is defined here
--> src/lib.rs:3:9
|
3 | fn ajouter_a_la_liste_attente() {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `ajouter_a_la_liste_attente` is private
--> src/lib.rs:13:30
|
13 | salle_a_manger::accueil::ajouter_a_la_liste_attente();
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ private function
|
note: the function `ajouter_a_la_liste_attente` is defined here
--> src/lib.rs:3:9
|
3 | fn ajouter_a_la_liste_attente() {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Que s’est-il passé ? Ajouter le mot-clé pub devant mod accueil rend public le module. Avec cette modification, si nous pouvons accéder à salle_a_manger, alors nous pouvons accéder à accueil. Mais le contenu de accueil reste privé ; rendre le module public ne rend pas son contenu public. Le mot-clé pub sur un module permet uniquement au code de ses parents d’y faire référence, pas d’accéder à son code interne. Comme les modules sont des conteneurs, le simple fait de rendre le module public ne suffit pas ; il faut aller plus loin et aussi choisir de rendre publics un ou plusieurs de ces éléments.
Les erreurs dans l’encart 7-6 nous informent que la fonction ajouter_a_la_liste_attente est privée. Les règles de visibilité s’appliquent aussi bien aux modules qu’aux structures, énumérations, fonctions et méthodes.
Rendons publique la fonction ajouter_a_la_liste_attente, en ajoutant le mot-clé pub devant sa définition, comme dans l’encart 7-7.
mod salle_a_manger {
pub mod accueil {
pub fn ajouter_a_la_liste_attente() {}
}
}
// -- partie masquée ici --
pub fn manger_au_restaurant() {
// Chemin absolu
crate::salle_a_manger::accueil::ajouter_a_la_liste_attente();
// Chemin relatif
salle_a_manger::accueil::ajouter_a_la_liste_attente();
}pub keyword to mod hosting and fn add_to_waitlist lets us call the function from eat_at_restaurant.Maintenant, le code va compiler ! Pour voir pourquoi l’ajout du mot-clé pub nous permet d’utiliser ces chemins dans manger_au_restaurant tout en respectant les règles de visibilité, analysons les chemins relatif et absolu.
Dans le chemin absolu, nous commençons avec crate, la racine de l’arborescence de modules de notre crate. Le module salle_a_manger est défini à la racine de la crate. Alors que le module salle_a_manger n’est pas public, car la fonction manger_au_restaurant est définie dans le même module que salle_a_manger (car manger_au_restaurant et salle_a_manger sont frères), nous pouvons utiliser salle_a_manger à partir de manger_au_restaurant. Ensuite, nous avons le module accueil, défini avec pub. Nous pouvons accéder au module parent de accueil, donc nous pouvons accéder à accueil. Enfin, la fonction ajouter_a_la_liste_attente est elle aussi définie avec pub et nous pouvons accéder à son module parent, donc au final cet appel à la fonction fonctionne bien !
Dans le chemin relatif, le fonctionnement est le même que le chemin absolu sauf pour la première étape : plutôt que de démarrer de la racine de la crate, le chemin commence à partir de salle_a_manger. Le module salle_a_manger est défini dans le même module que manger_au_restaurant, donc le chemin relatif qui commence à partir du module où est défini manger_au_restaurant fonctionne bien. Ensuite, comme accueil et ajouter_a_la_liste_attente sont définis avec pub, le reste du chemin fonctionne, et cet appel à la fonction est donc valide !
Si vous envisagez de partager votre crate de bibliothèque afin que d’autres projets puissent utiliser votre code, votre API publique constitue le contrat que vous concluez avec les utilisateurs de votre crate, contrat qui définit la manière dont ces utilisateurs peuvent interagir avec votre code. Il y a de nombreux aspects à prendre en compte en ce qui concerne la gestion des changements de votre API publique, afin de faciliter l’utilisation de votre crate. Ces aspects dépassent le cadre de cet ouvrage ; si ce sujet vous intéresse, consultez les directives relatives aux API Rust.
Bonnes pratiques pour les paquets comprenant un binaire et une bibliothèque
Nous avons mentionné le fait qu’un paquet peu contenir à la fois une crate binaire src/main.rs et une crate bibliothèque src/lib.rs, et que ces deux crates auront par défaut le nom du paquet. Généralement, les paquets qui suivent ce modèle, contenant à la fois une crate de bibliothèque et une crate binaire, ne contiennent dans la crate binaire que le code nécessaire pour démarrer un exécutable qui appelle le code défini dans la crate de bibliothèque. Ceci permet aux autres projets de bénéficier du maximum de fonctionnalités fournies par le paquet car le code de la crate de bibliothèque peut être partagé.
L’arborescence des modules doit être définie dans src/lib.rs. Ainsi, tout élément public peut être utilisé dans la crate binaire en commençant les chemins avec le nom du paquet. La crate binaire devient un utilisateur de la bibliothèque tout comme une crate complètement extérieure le ferait : elle ne peut utiliser que l’API publique. Ceci aide à mettre au point une bonne interface de programmation (API) ; non seulement vous êtes l’auteur, mais vous êtes également un client !
Dans le chapitre 12, nous montrerons cette pratique organisationnelle avec un programme en ligne de commande qui contiendra en même temps une crate binaire et une crate de bibliothèque.
Commencer les chemins relatifs avec super
Nous pouvons créer des chemins relatifs qui commencent à partir du module parent, au lieu du module courant ou de la crate racine, en utilisant super au début du chemin. C’est comme débuter un chemin dans un système de fichiers avec la syntaxe .., qui désigne le répertoire parent. Utiliser super nous permet de faire référence à un élément dont nous savons qu’il est situé dans le module parent, ce qui peut faciliter la réorganisation de l’arborescence de modules quand le module est étroitement lié au parent, mais que le parent peut éventuellement être déplacé ailleurs dans l’arborescence des modules.
Imaginons le code dans l’encart 7-8 qui représente le cas où le chef corrige une commande erronée et l’apporte personnellement au client pour s’excuser. La fonction corriger_commande_erronee définie dans le module cuisine appelle la fonction servir_commande définie dans le module parent en spécifiant le chemin vers servir_commande, en commençant par super.
fn servir_commande() {}
mod cuisines {
fn corriger_commande_erronee() {
cuisiner_commande();
super::servir_commande();
}
fn cuisiner_commande() {}
}superLa fonction corriger_commande_erronee est dans le module cuisines, donc nous pouvons utiliser super pour nous rendre au module parent de cuisines, qui dans notre cas est crate, la racine. De là, nous cherchons servir_commande et nous la trouvons. Avec succès ! Nous pensons que le module cuisines et la fonction servir_commande vont toujours garder la même relation et devront être déplacés ensemble si nous réorganisons l’arborescence de modules de la crate. Ainsi, nous avons utilisé super pour avoir moins de code à mettre à jour à l’avenir si ce code est déplacé dans un module différent.
Rendre publiques des structures et des énumérations
Nous pouvons aussi utiliser pub pour déclarer des structures et des énumérations publiquement, mais il y a d’autres points à prendre en compte concernant l’utilisation de pub avec des structures et des énumérations. Si nous utilisons pub avant la définition d’une structure, nous rendons la structure publique, mais les champs de la structure restent privés. Nous pouvons rendre chaque champ public ou non au cas par cas. Dans l’encart 7-9, nous avons défini une structure publique cuisines::PetitDejeuner avec un champ public tartine_grillee mais avec un champ privé fruit_de_saison. Cela simule un restaurant où le client peut choisir le type de pain qui accompagne le repas, mais le chef décide des fruits qui accompagnent le repas en fonction de la saison et ce qu’il y a en stock. Les fruits disponibles changent rapidement, donc les clients ne peuvent pas choisir le fruit ou même voir quel fruit ils obtiendront.
mod cuisines {
pub struct PetitDejeuner {
pub tartine_grillee: String,
fruit_de_saison: String,
}
impl PetitDejeuner {
pub fn en_ete(tartine_grillee: &str) -> PetitDejeuner {
PetitDejeuner {
tartine_grillee: String::from(tartine_grillee),
fruit_de_saison: String::from("pêches"),
}
}
}
}
pub fn manger_au_restaurant() {
// On commande un petit-déjeuner en été avec tartine grillée au seigle.
let mut repas = cuisines::PetitDejeuner::en_ete("seigle");
// On change d'avis sur le pain que nous souhaitons.
repas.tartine_grillee = String::from("blé");
println!( "Je voudrais une tartine grillée au {}, s'il vous plaît.",
repas.tartine_grillee);
// La prochaine ligne ne va pas se compiler si nous ne la commentons pas,
// car nous ne sommes pas autorisés à voir ou modifier le fruit de saison
// qui accompagne le repas.
// repas.fruit_de_saison = String::from("myrtilles");
}Comme le champ tartine_grillee est public dans la structure cuisines::PetitDejeuner, nous pouvons lire et écrire dans le champ tartine_grillee à partir de manger_au_restaurant en utilisant la notation .. Notez aussi que nous ne pouvons pas utiliser le champ fruit_de_saison dans manger_au_restaurant car fruit_de_saison est privé. Essayez de dé-commenter la ligne qui tente de modifier la valeur du champ fruit_de_saison et voyez l’erreur que vous obtenez !
Aussi, remarquez que comme cuisines::PetitDejeuner a un champ privé, la structure a besoin de fournir une fonction associée publique qui construit une instance de PetitDejeuner (que nous avons nommée en_ete ici). Si PetitDejeuner n’avait pas une fonction comme celle-ci, nous ne pourrions pas créer une instance de PetitDejeuner dans manger_au_restaurant car nous ne pourrions pas donner une valeur au champ privé fruit_de_saison dans manger_au_restaurant.
Par contre, si nous rendons publique une énumération, toutes ses variantes seront publiques. Nous avons simplement besoin d’un pub devant le mot-clé enum, comme dans l’encart 7-10.
mod cuisines {
pub enum AmuseBouche {
Soupe,
Salade,
}
}
pub fn manger_au_restaurant() {
let commande1 = cuisines::AmuseBouche::Soupe;
let commande2 = cuisines::AmuseBouche::Salade;
}Comme nous avons rendu l’énumération AmuseBouche publique, nous pouvons utiliser les variantes Soupe et Salade dans manger_au_restaurant.
Les énumérations ne sont pas très utiles si elles n’ont pas leurs variantes publiques ; et cela serait pénible d’avoir à marquer toutes les variantes de l’énumération avec pub, donc par défaut les variantes d’énumérations sont publiques. Les structures sont souvent utiles sans avoir de champs publics, donc les champs des structures sont tous privés par défaut, sauf si ces éléments sont marqués d’un pub.
Il y a encore une chose que nous n’avons pas abordée concernant pub, et c’est la dernière fonctionnalité du système de modules : le mot-clé use. Nous commencerons par parler de l’utilisation de use de manière générale, puis nous verrons comment combiner pub et use.
Importer des chemins dans la portée via le mot-clé use
Importer des chemins dans la portée via le mot-clé use
Devoir écrire les chemins pour appeller des fonctions peut paraître pénible et répétitif. Dans l’encart 7-7, que nous ayons choisi d’utiliser le chemin absolu ou relatif pour la fonction ajouter_a_la_liste_attente, nous aurions dû aussi écrire salle_a_manger et accueil à chaque fois que nous voulions appeler ajouter_a_la_liste_attente. Heureusement, il existe une solution pour simplifier ce cheminement : nous pouvons créer un raccourci vers un chemin avec le mot-clé use et ensuite utiliser le nom court partout ailleurs dans la portée.
Dans l’encart 7-11, nous importons le module crate::salle_a_manger::accueil dans la portée de la fonction manger_au_restaurant afin que nous n’ayons plus qu’à utiliser accueil::ajouter_a_la_liste_attente pour appeler la fonction ajouter_a_la_liste_attente dans manger_au_restaurant.
mod salle_a_manger {
pub mod accueil {
pub fn ajouter_a_la_liste_attente() {}
}
}
use crate::salle_a_manger::accueil;
pub fn manger_au_restaurant() {
accueil::ajouter_a_la_liste_attente();
}useDans une portée, utiliser un use et un chemin s’apparente à créer un lien symbolique dans le système de fichiers. Grâce à l’ajout de use crate::salle_a_manger::accueil à la racine de la crate, accueil est maintenant un nom valide dans cette portée, comme si le module accueil avait été défini à la racine de la crate. Les chemins importés dans la portée via use doivent respecter les règles de visibilité, tout comme les autres chemins.
Notez que use se contente de créer le raccourci uniquement pour la portée dans laquelle se trouve le use. L’encart 7-12 déplace la fonction manger_au_restaurant dans un nouveau module enfant appelé client, qui se trouve dans une portée différente de celle de l’instruction du use, de telle sorte que le corps de la fonction ne pourra pas être compilé.
mod salle_a_manger {
pub mod accueil {
pub fn ajouter_a_la_liste_attente() {}
}
}
use crate::salle_a_manger::accueil;
mod client {
pub fn manger_au_restaurant() {
accueil::ajouter_a_la_liste_attente();
}
}use statement only applies in the scope it’s in.L’erreur du compilateur montre que le raccourci ne s’applique plus à l’intérieur du module client :
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `accueil`
--> src/lib.rs:11:9
|
11 | accueil::ajouter_a_la_liste_attente();
| ^^^^^^^ use of unresolved module or unlinked crate `accueil`
|
= help: if you wanted to use a crate named `accueil`, use `cargo add accueil` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::accueil;
|
warning: unused import: `crate::salle_a_manger::accueil`
--> src/lib.rs:7:5
|
7 | use crate::salle_a_manger::accueil;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
Notez qu’il y a aussi un avertissement selon lequel le use n’est plus utilisé dans cette portée ! Pour solutionner ce problème, il faut aussi déplacer le use dans le module client, ou bien référencer le raccourci dans le module parent avec super::accueil dans le module enfant client.
Créer des chemins idéaux pour use
Dans l’encart 7-11, vous vous êtes peut-être demandé pourquoi nous avions utilisé use crate::salle_a_manger::accueil et appelé ensuite accueil::ajouter_a_la_liste_attente dans manger_au_restaurant plutôt que d’écrire le chemin du use jusqu’à la fonction ajouter_a_la_liste_attente pour avoir le même résultat, comme dans l’encart 7-13.
mod salle_a_manger {
pub mod accueil {
pub fn ajouter_a_la_liste_attente() {}
}
}
use crate::salle_a_manger::accueil::ajouter_a_la_liste_attente;
pub fn manger_au_restaurant() {
ajouter_a_la_liste_attente();
}add_to_waitlist function into scope with use, which is unidiomaticBien que l’encart 7-11 et 7-13 accomplissent la même tâche, l’encart 7-11 est la façon idéale d’importer une fonction dans la portée via use. L’import du module parent de la fonction dans notre portée avec use nécessite que nous ayons à préciser le module parent quand nous appelons la fonction. Renseigner le module parent lorsque nous appelons la fonction précise clairement que la fonction n’est pas définie localement, tout en minimisant la répétition du chemin complet. Nous ne pouvons pas repérer facilement là où est défini ajouter_a_la_liste_attente dans l’encart 7-13.
Cela dit, lorsque nous importons des structures, des énumérations et d’autres éléments avec use, il est idéal de préciser le chemin complet. L’encart 7-14 montre la manière idéale d’importer la structure HashMap de la bibliothèque standard dans la portée d’une crate binaire.
use std::collections::HashMap;
fn main() {
let mut table = HashMap::new();
map.insert(1, 2);
}HashMap into scope in an idiomatic wayIl n’y a pas de forte justification à cette pratique : c’est simplement une convention qui a germé, et les gens se sont habitués à lire et écrire du code Rust de cette façon.
Il y a une exception à cette pratique : nous ne pouvons pas utiliser l’instruction use pour importer deux éléments avec le même nom dans la portée, car Rust ne l’autorise pas. L’encart 7-15 nous montre comment importer puis utiliser deux types Result ayant le même nom mais dont les modules parents sont distincts.
use std::fmt;
use std::io;
fn fonction1() -> fmt::Result {
// -- partie masquée ici --
Ok(())
}
fn fonction2() -> io::Result<()> {
// -- partie masquée ici --
Ok(())
}Comme vous pouvez le constater, l’utilisation des modules parents permet de distinguer les deux types Result. Si nous avions utilisé use std::fmt::Result et use std::io::Result, nous aurions deux types nommés Result dans la même portée et donc Rust ne pourrait pas comprendre lequel nous voudrions utiliser en demandant Result.
Renommer des éléments avec le mot-clé as
Il y a une autre solution au fait d’avoir deux types du même nom dans la même portée à cause de use : après le chemin, nous pouvons rajouter as suivi d’un nouveau nom local, ou alias, sur le type. L’encart 7-16 nous montre une autre façon d’écrire le code de l’encart 7-15 en utilisant as pour renommer un des deux types Result.
use std::fmt::Result;
use std::io::Result as IoResult;
fn fonction1() -> Result {
// -- partie masquée ici --
Ok(())
}
fn fonction2() -> IoResult<()> {
// -- partie masquée ici --
Ok(())
}as keywordDans la seconde instruction use, nous avons choisi IoResult comme nouveau nom du type std::io::Result, qui n’est plus en conflit avec le Result de std::fmt que nous avons aussi importé dans la portée. Les encarts 7-15 et 7-16 sont idéaux, donc le choix vous revient !
Réexporter des éléments avec pub use
Lorsque nous importons un élément dans la portée avec le mot-clé use, son nom dans la portée dans laquelle nous l’avons importé est privé. Pour permettre à du code extérieur d’utiliser ce nom comme s’il était défini dans cette portée, nous pouvons associer pub et use. Cette technique est appelée réexporter car nous importons un élément dans la portée, mais nous rendons aussi cet élément disponible aux portées des autres.
L’encart 7-17 nous montre le code de l’encart 7-11 où le use du module racine a été remplacé par pub use.
mod salle_a_manger {
pub mod accueil {
pub fn ajouter_a_la_liste_attente() {}
}
}
pub use crate::salle_a_manger::accueil;
pub fn manger_au_restaurant() {
accueil::ajouter_a_la_liste_attente();
}pub useAvant ce changement, un code extérieur aurait dû appeler la fonction ajouter_a_la_liste_attente en utilisant le chemin restaurant::salle_a_manger::accueil::ajouter_a_la_liste_attente(), ce qui aurait aussi requis que le module salle_a_manger soit marqué comme pub. Maintenant que ce pub use a réexporté le module accueil depuis le module racine, le code extérieur peut utiliser le chemin restaurant::salle_a_manger::ajouter_a_la_liste_attente() à la place.
Réexporter est utile quand la structure interne de votre code est différente de la façon dont les développeurs qui utilisent votre code se la représentent. Par exemple, dans cette métaphore du restaurant, les personnes qui font fonctionner le restaurant se structurent en fonction de la “salle à manger” et des “cuisines”. Mais les clients qui utilisent le restaurant ne vont probablement pas voir les choses ainsi. Avec pub use, nous pouvons écrire notre code selon une certaine organisation, mais l’exposer avec une organisation différente. En faisant ainsi, la bibliothèque est bien organisée autant pour les développeurs qui travaillent sur la bibliothèque que pour les développeurs qui utilisent la bibliothèque. Nous verrons un autre exemple de pub use et comment il affecte la documentation de la crate dans « Exporter une API publique conviviale » dans le chapitre 14.
Utiliser des paquets externes
Dans le chapitre 2, nous avions développé un projet de jeu du plus ou du moins qui utilisait le paquet externe rand afin d’obtenir des nombres aléatoires. Pour pouvoir utiliser rand dans notre projet, nous avions ajouté cette ligne dans Cargo.toml :
rand = "0.8.5"
L’ajout de rand comme dépendance dans Cargo.toml demande à Cargo de télécharger le paquet rand et toutes ses dépendances à partir de crates.io et rend disponible rand pour notre projet.
Ensuite, pour importer les définitions de rand dans la portée de notre paquet, nous avions ajouté une ligne use qui commence avec le nom de la crate, rand, et nous avions listé les éléments que nous voulions importer dans notre portée. Dans la section “Générer le nombre secret” du chapitre 2, nous avions importé le trait Rng dans la portée, puis nous avions appelé la fonction rand::thread_rng :
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
}Les membres de la communauté Rust ont mis à disposition de nombreux paquets sur crates.io, et utiliser l’un d’entre eux dans votre paquet implique toujours ces mêmes étapes : les lister dans le fichier Cargo.toml de votre paquet et utiliser use pour importer certains éléments de ces crates dans la portée.
Notez que la bibliothèque standard std est aussi une crate qui est externe à notre paquet. Comme la bibliothèque standard est livrée avec le langage Rust, nous n’avons pas à modifier le Cargo.toml pour y inclure std. Mais nous devons utiliser use pour importer les éléments qui se trouvent dans la portée de notre paquet. Par exemple, pour HashMap, nous pourrions utiliser cette ligne :
#![allow(unused)]
fn main() {
use std::collections::HashMap;
}C’est un chemin absolu qui commence par std, le nom de la crate de la bibliothèque standard.
Utiliser des chemins imbriqués pour simplifier les listes de use
Si vous utilisez de nombreux éléments définis dans une même crate ou dans un même module, lister chaque élément sur sa propre ligne prendra beaucoup d’espace vertical dans vos fichiers. Par exemple, ces deux instructions use, que nous avions dans le jeu du plus ou du moins dans l’encart 2-4, importaient des éléments de std dans la portée :
use rand::Rng;
// -- partie masquée ici --
use std::cmp::Ordering;
use std::io;
// -- partie masquée ici --
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
println!("Votre nombre : {supposition}");
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => println!("Vous avez gagné !"),
}
}À la place, nous pouvons utiliser des chemins imbriqués afin d’importer ces mêmes éléments dans la portée en une seule ligne. Nous pouvons faire cela en indiquant la partie commune du chemin, suivi d’un double deux-points, puis d’accolades autour d’une liste des éléments qui diffèrent entre les chemins, comme dans l’encart 7-18 :
use rand::Rng;
// -- partie masquée ici --
use std::{cmp::Ordering, io};
// -- partie masquée ici --
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: u32 = supposition.trim().parse().expect("Veuillez entrer un nombre !");
println!("Votre nombre : {supposition}");
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => println!("Vous avez gagné !"),
}
}Pour des programmes plus gros, importer plusieurs éléments dans la portée depuis la même crate ou module en utilisant des chemins imbriqués peut réduire considérablement le nombre de use utilisés !
Nous pouvons utiliser un chemin imbriqué à tous les niveaux d’un chemin, ce qui peut être utile lorsqu’on utilise deux instructions use qui partagent un sous-chemin. Par exemple, l’encart 7-19 nous montre deux instructions use : une qui importe std::io dans la portée et une autre qui importe std::io::Write dans la portée.
use std::io;
use std::io::Write;use statements where one is a subpath of the otherLa partie commune entre ces deux chemins est std::io, et c’est le premier chemin complet. Pour imbriquer ces deux chemins en une seule instruction use, nous pouvons utiliser self dans le chemin imbriqué, comme dans l’encart 7-20.
use std::io::{self, Write};use statementCette ligne importe std::io et std::io::Write dans la portée.
Import d’éléments avec l’opérateur global
Si nous voulons importer, dans la portée, tous les éléments publics définis dans un chemin, nous pouvons indiquer ce chemin suivi par l’opérateur global * :
#![allow(unused)]
fn main() {
use std::collections::*;
}Cette instruction use va importer tous les éléments publics définis dans std::collections dans la portée courante. Mais soyez prudent quand vous utilisez l’opérateur global ! L’utilisation de l’opérateur global peut rendre difficile l’identification des noms dans la portée et là où un élément utilisé dans notre programme a été défini.
L’opérateur global est souvent utilisé lorsque nous écrivons des tests, pour importer tout ce qu’il y a à tester dans le module tests ; nous verrons cela dans une section du chapitre 11. L’opérateur global est parfois aussi utilisé pour l’étape préliminaire : rendez-vous dans la documentation de la bibliothèque standard pour plus d’informations sur cela.
Séparer les modules dans différents fichiers
Séparer les modules dans différents fichiers
Jusqu’à présent, tous les exemples de ce chapitre ont défini plusieurs modules dans un seul fichier. Quand les modules vont grossir, vous allez probablement vouloir déplacer leurs définitions dans un fichier séparé pour faciliter le parcours de votre code.
Prenons par exemple le code de l’encart 7-17 qui avait plusieurs modules de restauration. Nous allons extraire les modules dans des fichiers, au lieu d’avoir tous les modules définis dans le fichier de la crate racine. Dans notre cas, le fichier de la crate racine est src/lib.rs, mais cette procédure fonctionne aussi avec les crates binaires dans lesquelles le fichier de la crate racine est src/main.rs.
Tout d’abord, nous allons extraire le module salle_a_manger vers son propre fichier. Nous enlevons le code entre parenthèses du module salle_a_manger, en ne laissant que la déclaration mod salle_a_manger;, de sorte que src/lib.rs` corresponde au code de l’encart 7-21.
mod front_of_house;
pub use crate::salle_a_manger::accueil;
pub fn manger_au_restaurant() {
accueil::ajouter_a_la_liste_attente();
}front_of_house module whose body will be in src/front_of_house.rsEnsuite, plaçons le code qui était entre parenthèses dans un nouveau fichier nommé src/front_of_house.rs, comme dans l’encart 7-22. Le compilateur sait qu’il doit lire ce fichier car il a croisé la déclaration de module dans la crate racine avec le nom salle_a_manger.
pub mod accueil {
pub fn ajouter_a_la_liste_attente() {}
}front_of_house module in src/front_of_house.rsNotez que vous devez charger un fichier avec une déclaration mod une seule fois dans votre arborescence de modules. Une fois que le compilateur sait que le fichier fait partie du projet (et qu’il sait où son code réside dans l’arborescence des modules, ce qui dépend d’où vous avez mis l’instruction mod), les autres fichiers de votre projet devraient faire référence au code des fichiers chargés en utilisant un chemin vers l’endroit où il a été déclaré, comme vu dans la section « Désigner un élément dans l’arborescence de modules ». En d’autres termes, mod n’est pas l’équivalent d’un « include » que vous avez pu voir dans d’autres langages.
Ensuite, nous allons extraire le module accueil dans son propre fichier. Le processus est un peu différent, car accueil est un sous-module de salle_a_manger, pas du module racine. Nous mettrons le fichier pour accueil dans un nouveau sous-répertoire qui sera nommé selon ses ancêtres dans l’arborescence des modules, dans ce cas src/salle_a_manger.
Pour commencer à déplacer accueil, nous changeons src/salle_a_mange.rs de manière à ce qu’il ne contienne que la déclaration du module accueil :
pub mod hosting;Ensuite, nous créons un répertoire src/salle_a_manger et un fichier accueil.rs_ qui contiendra les définitions du module accueil :
pub fn add_to_waitlist() {}Si, au lieu de cela, nous avions mis hosting.rs dans le répertoire src, le compilateur se serait attendu à ce que le code de hosting.rs se trouve dans un module accueil déclaré dans la crate racine, et comme un sous-module du module salle_a_manger. Les règles du compilateur, qui déterminent quels fichiers vérifier pour le code de quels modules, font en sorte que les répertoires et fichiers correspondent davantage à l’arborescence des modules.
Autres chemins d’accès aux fichiers
Jusqu’ici, nous avons traité des chemins d’accès les plus courants utilisés par le compilateur Rust, mais Rust prend également en charge un style plus ancien de chemin d’accès. Pour un module nommé salle_a_manger déclaré dans la crate racine, le compilateur cherchera le code du module dans :
- src/salle_a_manger.rs (ce que nous venons de voir)
- src/salle_a_manger/mod.rs (style plus ancien, chemin toujours supporté)
Pour un module nommé accueil qui est un sous-module de salle_a_manger, le compilateur cherchera le code du module dans :
- src/salle_a_manger/accueil.rs (what we covered)
- src/salle_a_manger/accueil/mod.rs (style plus ancien, toujours supporté)
Si vous utilisez les deux styles pour le même module, vous obtiendrez une erreur à la compilation. Il est possible d’utiliser un mélange des deux styles pour différents modules au sein d’un même projet, mais cela peut prêter à confusion pour les personnes qui liront votre projet.
Le principal inconvénient du style qui utilise des fichiers nommés mod.rs est que votre projet peut arriver à de nombreux fichiers nommés mod.rs, ce qui peut prêter à confusion quand les avez ouverts en même temps dans votre éditeur.
Nous avons déplacé le code de chaque module vers un fichier séparé, et l’arborescence des modules reste identique. Les appels aux fonctions de manger_au_restaurant vont continuer à fonctionner sans aucune modification, même si les définitions se retrouvent dans des fichiers différents. Cette technique vous permet de déplacer des modules dans de nouveaux fichiers au fur et à mesure qu’ils s’agrandissent.
Remarquez que l’instruction pub use crate::salle_a_manger::accueil dans src/lib.rs n’a pas changé, et que use n’a aucun impact sur quels fichiers sont compilés pour constituer la crate. Le mot-clé mod déclare un module, et Rust recherche un fichier de code qui porte le nom dudit module.
Résumé
Rust vous permet de découper un paquet en plusieurs crates et une crate en modules afin que vous puissiez réutiliser vos éléments d’un module à un autre. Vous pouvez faire cela en utilisant des chemins absolus ou relatifs. Ces chemins peuvent être importés dans la portée avec l’instruction use pour pouvoir utiliser l’élément plusieurs fois dans la portée avec un chemin plus court. Le code du module est privé par défaut, mais vous pouvez rendre publiques des définitions en ajoutant le mot-clé pub.
Au prochain chapitre, nous allons nous intéresser à quelques collections de structures de données de la bibliothèque standard que vous pourrez utiliser dans votre code soigneusement organisé.
Les collections standard
La bibliothèque standard de Rust apporte quelques structures de données très utiles appelées collections. La plupart des autres types de données représentent une seule valeur précise, mais les collections peuvent contenir plusieurs valeurs. Contrairement aux tableaux et aux tuples, les données que ces collections contiennent sont stockées sur le tas, ce qui veut dire que la quantité de données n’a pas à être connue au moment de la compilation et peut augmenter ou diminuer pendant l’exécution du programme. Chaque type de collection a ses avantages et ses inconvénients, et en choisir un qui répond à votre besoin sur le moment est une aptitude que vous allez développer avec le temps. Dans ce chapitre, nous allons découvrir trois collections qui sont très utilisées dans les programmes Rust :
- Le vecteur qui vous permet de stocker un nombre variable de valeurs les unes à côté des autres.
- La String, qui est une collection de caractères. Nous avons déjà aperçu le type
Stringprécédemment, mais dans ce chapitre, nous allons l’étudier en détail. - La table de hachage qui vous permet d’associer une valeur à une clé précise. C’est une implémentation spécifique d’une structure de données plus générique : le tableau associatif.
Pour en savoir plus sur les autres types de collections fournies par la bibliothèque standard, allez voir la documentation.
Nous allons voir comment créer et modifier les vecteurs, les Strings et les tables de hachage, et étudier leurs différences.
Stocker des listes de valeurs avec des vecteurs
Stocker des listes de valeurs avec des vecteurs
Le premier type de collection que nous allons voir est Vec<T>, aussi appelé vecteur. Les vecteurs vous permettent de stocker plus d’une valeur dans une seule structure de données qui stocke les valeurs les unes à côté des autres dans la mémoire. Les vecteurs peuvent stocker uniquement des valeurs du même type. Ils sont utiles lorsque vous avez une liste d’éléments, tels que les lignes de texte provenant d’un fichier ou les prix des articles d’un panier d’achat.
Créer un nouveau vecteur
Pour créer un nouveau vecteur vide, nous appelons la fonction Vec::new, comme dans l’encart 8-1.
fn main() {
let v: Vec<i32> = Vec::new();
}i32Remarquez que nous avons ajouté ici une annotation de type. Comme nous n’ajoutons pas de valeurs dans ce vecteur, Rust ne sait pas quel type d’éléments nous souhaitons stocker. C’est une information importante. Les vecteurs sont implémentés avec la généricité ; nous verrons comment utiliser la généricité sur vos propres types au chapitre 10. Pour l’instant, sachez que le type Vec<T> qui est fourni par la bibliothèque standard peut stocker n’importe quel type. Lorsque nous créons un vecteur pour stocker un type précis, nous pouvons renseigner ce type entre des chevrons. Dans l’encart 8-1, nous précisons à Rust que le Vec<T> dans v va stocker des éléments de type i32.
Le plus souvent, vous allez créer un Vec<T> avec des valeurs initiales et Rust va deviner le type de la valeur que vous souhaitez stocker, donc vous n’aurez pas souvent besoin de faire cette annotation de type. Rust propose la macro très pratique vec!, qui va créer un nouveau vecteur qui stockera les valeurs que vous lui donnerez. L’encart 8-2 crée un nouveau Vec<i32> qui stocke les valeurs 1, 2 et 3. Le type d’entier est i32 car c’est le type d’entier par défaut, comme nous l’avons évoqué dans la section “Les types de données” du chapitre 3.
fn main() {
let v = vec![1, 2, 3];
}Comme nous avons donné des valeurs initiales i32, Rust peut en déduire que le type de v est Vec<i32>, et l’annotation de type n’est plus nécessaire. Maintenant, nous allons voir comment modifier un vecteur.
Modifier un vecteur
Pour créer un vecteur et ensuite lui ajouter des éléments, nous pouvons utiliser la méthode push, comme dans l’encart 8-3.
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}push method to add values to a vectorComme pour toute variable, si nous voulons pouvoir modifier sa valeur, nous devons la rendre mutable en utilisant le mot-clé mut, comme nous l’avons vu au chapitre 3. Les nombres que nous ajoutons dedans sont tous du type i32, et Rust le devine à partir des données, donc nous n’avons pas besoin de l’annotation Vec<i32>.
Lire les éléments des vecteurs
Il existe deux façons de désigner une valeur enregistrée dans un vecteur : via les indices ou en utilisant la méthode get. Dans les exemples suivants, nous avons précisé les types des valeurs qui sont retournées par ces fonctions pour plus de clarté.
L’encart 8-5 nous montre les deux façons d’accéder à une valeur d’un vecteur, via la syntaxe d’indexation et avec la méthode get.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let troisieme: &i32 = &v[2];
println!("Le troisième élément est {troisieme}");
let troisieme: Option<&i32> = v.get(2);
match troisieme {
Some(troisieme) => println!("Le troisième élément est {troisieme}"),
None => println!("Il n'y a pas de troisième élément."),
}
}get method to access an item in a vectorIl y a quelques détails à remarquer ici. Nous avons utilisé l’indice 2 pour obtenir le troisième élément car les vecteurs sont indexés par des nombres, qui commencent à partir de zéro. L’utilisation de & et [] nous donne une référence à l’élément se trouvant à l’indice voulu. Quand nous utilisons la méthode get avec l’indice passé en argument, nous obtenons une Option<&T> que nous pouvons ensuite utiliser avec match.
Rust offre ces deux manières d’obtenir une référence vers un élement de façon à vous permettre de choisir le comportement du programme lorsque vous essayez d’utiliser une valeur dont l’indice est à l’extérieur de la plage des éléments existants. Par exemple, voyons dans l’encart 8-5 ce qui se passe lorsque nous avons un vecteur de cinq éléments et qu’ensuite nous essayons d’accéder à un élément à l’indice 100 avec chaque technique.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let existe_pas = &v[100];
let existe_pas = v.get(100);
}Lorsque nous exécutons ce code, la première méthode [] va faire paniquer le programme car il demande un élément non existant. Cette méthode doit être favorisée lorsque vous souhaitez que votre programme plante s’il y a une tentative d’accéder à un élément après la fin du vecteur.
Lorsque nous passons un indice en dehors de l’intervalle du vecteur à la méthode get, elle retourne None sans paniquer. Vous devriez utiliser cette méthode s’il peut arriver occasionnellement de vouloir accéder à un élément en dehors de l’intervalle du vecteur en temps normal. Votre code va ensuite devoir gérer les deux valeurs Some(&element) ou None, comme nous l’avons vu au chapitre 6. Par exemple, l’indice peut provenir d’une saisie utilisateur. Si par accident il saisit un nombre qui est trop grand et que le programme obtient une valeur None, vous pouvez alors dire à l’utilisateur combien il y a d’éléments dans le vecteur courant et lui donner une nouvelle chance de saisir une valeur valide. Cela sera plus convivial que de faire planter le programme à cause d’une faute de frappe !
Lorsque le programme obtient une référence valide, le vérificateur d’emprunt va faire appliquer les règles de possession et d’emprunt (que nous avons vues au chapitre 4) pour s’assurer que cette référence ainsi que toutes les autres références au contenu de ce vecteur restent valides. Souvenez-vous de la règle qui dit que vous ne pouvez pas avoir des références mutables et immuables dans la même portée. Cette règle s’applique à l’encart 8-6, où nous obtenons une référence immuable vers le premier élément d’un vecteur et nous essayons d’ajouter un élément à la fin. Ce programme ne fonctionnera pas si nous essayons aussi d’utiliser cet élément plus tard dans la fonction :
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let premier = &v[0];
v.push(6);
println!("Le premier élément est : {premier}");
}Compiler ce code va nous mener à cette erreur :
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let premier = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("Le premier élément est : {premier}");
| ------- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Le code dans l’encart 8-6 semble pourtant marcher : pourquoi une référence au premier élément devrait se soucier de ce qui se passe à la fin du vecteur ? Cette erreur s’explique par la façon dont les vecteurs fonctionnent : comme les vecteurs ajoutent les valeurs les unes à côté des autres dans la mémoire, l’ajout d’un nouvel élément à la fin du vecteur peut nécessiter d’allouer un nouvel espace mémoire et de copier tous les anciens éléments dans ce nouvel espace, s’il n’y a pas assez de place pour placer tous les éléments les uns à côté des autres dans l’emplacemen mémoire où est actuellement stocké le vecteur. Dans ce cas, la référence au premier élément pointerait vers de la mémoire désallouée. Les règles d’emprunt évitent aux programmes de se retrouver dans cette situation.
Remarque : pour plus de détails sur l’implémentation du type Vec<T>, consultez le “Rustonomicon”.
Itérer sur les valeurs d’un vecteur
Pour accéder à chaque élément d’un vecteur chacun son tour, nous devrions itérer sur tous les éléments plutôt que d’utiliser individuellement les indices. L’encart 8-7 nous montre comment utiliser une boucle for pour obtenir des références immuables pour chacun des éléments dans un vecteur de i32, et les afficher.
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{i}");
}
}for loopNous pouvons aussi itérer avec des références mutables pour chacun des éléments d’un vecteur mutable afin de modifier tous les éléments. La boucle for de l’encart 8-8 va ajouter 50 à chacun des éléments.
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}Afin de changer la valeur vers laquelle pointe la référence mutable, nous devons utiliser l’opérateur de déréférencement * pour obtenir la valeur dans i avant que nous puissions utiliser l’opérateur +=. Nous verrons plus en détail l’opérateur de déréférencement dans une section du chapitre 15.
Itérer sur un vecteur, de manière immuable ou mutable, est sans risque grâce aux règles du vérificateur d’emprunt. Si nous tentions d’insérer ou de supprimer des éléments dans le corps des boucles for des encarts 8-7 et 8-8, nous obtiendrions une erreur de compilation similaire à celle obtenue avec le code du l’encart 8-6. La référence au vecteur détenue par la boucle for empêche toute modification simultanée de l’ensemble du vecteur.
Utiliser une énumération pour stocker différents types
Les vecteurs ne peuvent stocker que des valeurs du même type. Cela peut être un problème ; il y a forcément des cas où on a besoin de stocker une liste d’éléments de types différents. Heureusement, les variantes d’une énumération sont définies sous le même type d’énumération, donc lorsque nous avons besoin d’un type pour représenter des éléments de types différents, nous pouvons définir et utiliser une énumération !
Par exemple, imaginons que nous voulions obtenir les valeurs d’une ligne d’une feuille de calcul dans laquelle quelques colonnes sont des entiers, d’autres des nombres à virgule flottante, et quelques chaînes de caractères. Nous pouvons définir une énumération dont les variantes vont avoir les différents types, de sorte que toutes les variantes de l’énumération seront du même type : celui de l’énumération. Ensuite, nous pouvons créer un vecteur pour stocker cette énumération et ainsi, au final, le vecteur stocke différents types. La démonstration de cette technique est dans l’encart 8-9.
fn main() {
enum Cellule {
Int(i32),
Float(f64),
Texte(String),
}
let row = vec![
Cellule::Int(3),
Cellule::Texte(String::from("bleu")),
Cellule::Float(10.12),
];
}Rust a besoin de savoir quel type de donnée sera stocké dans le vecteur au moment de la compilation afin de connaître la quantité de mémoire nécessaire pour stocker chaque élément sur le tas. Nous devons être précis sur les types autorisés dans ce vecteur. Si Rust avait permis qu’un vecteur stocke n’importe quel type, il aurait pu y avoir un risque qu’un ou plusieurs des types provoquent une erreur avec les manipulations effectuées sur les éléments du vecteur. L’utilisation d’une énumération ainsi qu’une expression match permettent à Rust de garantir, au moment de la compilation, que tous les cas possibles sont traités, comme nous l’avons appris au chapitre 6.
Si vous n’avez pas une liste exhaustive des types que votre programme va stocker dans un vecteur, la technique de l’énumération ne va pas fonctionner. À la place, vous pouvez utiliser un objet trait, que nous verrons au chapitre 18.
Maintenant que nous avons vu les manières les plus courantes d’utiliser les vecteurs, prenez le temps de consulter la documentation de l’API pour découvrir toutes les méthodes très utiles définies dans la bibliothèque standard pour Vec<T>. Par exemple, en plus de push, nous avons une méthode pop qui retire et retourne le dernier élément.
Libérer un vecteur libère aussi ses éléments
Comme toutes les autres structures, un vecteur est libéré quand il sort de la portée, comme précisé dans l’encart 8-10.
fn main() {
{
let v = vec![1, 2, 3, 4];
// on fait des choses avec v
} // <- v sort de la portée et est libéré ici
}Lorsque le vecteur est libéré, tout son contenu est aussi libéré, ce qui veut dire que les nombres entiers qu’il stocke vont être effacés de la mémoire. Le vérificateur d’emprunt s’assure que toute référence à du contenu d’un vecteur n’est utilisée que tant que le vecteur lui-même est valide.
Intéressons-nous maintenant au prochain type de collection : la String !
Stocker du texte encodé en UTF-8 avec les Strings
Stocker du texte encodé en UTF-8 avec les Strings
Nous avons déjà parlé des chaînes de caractères dans le chapitre 4, mais nous allons à présent les analyser plus en détail. Les nouveaux Rustacés bloquent souvent avec les chaînes de caractères pour trois raisons : la tendance de Rust à prévenir les erreurs, le fait que les chaînes de caractères sont des structures de données plus compliquées que ne le pensent la plupart des développeurs, et l’UTF-8. Ces raisons cumulées rendent les choses compliquées lorsque vous venez d’un autre langage de programmation.
Nous avons présenté les chaînes de caractères comme des collections car les chaînes de caractères sont en réalité des suites d’octets, avec quelques méthodes supplémentaires qui sont utiles lorsque ces octets sont considérés comme du texte. Dans cette section, nous allons voir les points communs entre le fonctionnement des String et celui des autres collections, comme la création, la modification et la lecture. Nous verrons les raisons pour lesquelles les String sont différentes des autres collections, en particulier pourquoi l’indexation d’une String est compliquée à cause des différences entre la façon dont les gens et les ordinateurs interprètent les données d’une String.
Définition des chaînes de caractères
Nous allons d’abord définir ce que nous entendons par le terme chaîne de caractères. Rust a un seul type de chaînes de caractères dans le noyau du langage, qui est la slice de chaîne de caractères str qui est habituellement utilisée sous sa forme empruntée, &str. Dans le chapitre 4, nous avons abordé les slices de chaînes de caractères, qui sont des références à des données d’une chaîne de caractères encodée en UTF-8 qui sont stockées autre part. Les littéraux de chaînes de caractères, par exemple, sont stockés dans le binaire du programme et sont des slices de chaînes de caractères.
Le type String, qui est fourni par la bibliothèque standard de Rust plutôt que d’être intégré au noyau du langage, est un type de chaîne de caractères encodé en UTF-8 qui peut s’agrandir, être mutable, et être possédé. Lorsque les Rustacés parlent de “chaînes de caractères” en Rust, ils entendent soit le type String, soit le type de slice de chaînes de caractères &str, et non pas un seul de ces types. Bien que cette section traite essentiellement de String, ces deux types sont utilisés massivement dans la bibliothèque standard de Rust, et tous les deux sont encodés en UTF-8.
Créer une nouvelle String
De nombreuses opérations disponibles avec Vec<T> sont aussi disponibles avec String car String est en fait implémenté comme un conteneur autour d’un vecteur d’octets avec quelques garanties, restrictions et fonctionnalités supplémentaires. Un exemple d’une fonction qui se comporte de la même manière avec Vec<T> et String est la fonction new function qui permet de créer une instance, comme illustré dans l’encart 8-11.
fn main() {
let mut s = String::new();
}StringCette ligne crée une nouvelle String vide qui s’appelle s, dans laquelle nous pouvons ensuite charger des données. Souvent, nous aurons quelques données initiales que nous voudrions ajouter dans la String. Pour cela, nous utilisons la méthode to_string, qui est disponible sur tous les types qui implémentent le trait Display, comme le font les littéraux de chaînes de caractères. L’encart 8-12 nous montre deux exemples.
fn main() {
let donnee = "contenu initial";
let s = donnee.to_string();
// Cette méthode fonctionne aussi directement sur un
// littéral de chaîne de caractères :
let s = "contenu initial".to_string();
}to_string method to create a String from a string literalCe code crée une chaîne de caractères qui contient contenu initial.
Nous pouvons aussi utiliser la fonction String::from pour créer une String à partir d’un littéral de chaîne. Le code dans l’encart 8-13 est équivalent au code dans l’encart 8-12 qui utilisait to_string.
fn main() {
let s = String::from("contenu initial");
}String::from function to create a String from a string literalComme les chaînes de caractères sont utilisées pour de nombreuses choses, nous pouvons utiliser beaucoup d’API génériques pour les chaînes de caractères. Certaines d’entre elles peuvent paraître redondantes, mais elles ont toutes leur place ! Dans notre cas, String::from et to_string font la même chose, donc votre choix est une question de goût et de lisibilité.
Souvenez-vous que les chaînes de caractères sont encodées en UTF-8, donc nous pouvons y intégrer n’importe quelle donnée valide, comme nous le voyons dans l’encart 8-14.
fn main() {
let bonjour = String::from("السلام عليكم");
let bonjour = String::from("Dobrý den");
let bonjour = String::from("Hello");
let bonjour = String::from("שלום");
let bonjour = String::from("नमस्ते");
let bonjour = String::from("こんにちは");
let bonjour = String::from("안녕하세요");
let bonjour = String::from("你好");
let bonjour = String::from("Olá");
let bonjour = String::from("Здравствуйте");
let bonjour = String::from("Hola");
}Toutes ces chaînes sont des valeurs String valides.
Modifier une String
Une String peut s’agrandir et son contenu peut changer, exactement comme le contenu d’un Vec<T>, si on y ajoute des données. De plus, vous pouvez aisément utiliser l’opérateur + ou la macro format! pour concaténer des valeurs String.
Ajouter du texte à une chaîne avec push_str et push
Nous pouvons agrandir une String en utilisant la méthode push_str pour ajouter une slice de chaîne de caractères, comme dans l’encart 8-15.
fn main() {
let mut s = String::from("foo");
s.push_str("bar");
}String using the push_str methodÀ l’issue de ces deux lignes, s va contenir foobar. La méthode push_str prend une slice de chaîne de caractères car nous ne souhaitons pas forcément prendre possession du paramètre. Par exemple, dans le code de l’encart 8-16, nous voulons pouvoir utiliser s2 après avoir ajouté son contenu dans s1.
fn main() {
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 est {s2}");
}StringSi la méthode push_str prenait possession de s2, à la dernière ligne, nous ne pourrions pas afficher sa valeur. Cependant, ce code fonctionne comme nous l’espérions !
La méthode push prend un seul caractère en paramètre et l’ajoute à la String. L’encart 8-17 ajoute la lettre l à une String en utilisant la méthode push.
fn main() {
let mut s = String::from("lo");
s.push('l');
}String value using pushAprès l’exécution, s contiendra lol.
Concaténation avec + ou format!
Souvent, vous aurez besoin de combiner deux chaînes de caractères existantes. Une façon de faire cela est d’utiliser l’opérateur +, comme dans l’encart 8-18.
fn main() {
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // notez que s1 a été déplacé ici
// et ne pourra plus être utilisé
}+ operator to combine two String values into a new String valueLa chaîne de caractères s3 va contenir Hello, world!. La raison pour laquelle s1 n’est plus utilisable après avoir été ajouté, et pour laquelle nous utilisons une référence vers s2, est la signature de la méthode qui est appelée lorsque nous utilisons l’opérateur +. L’opérateur + utilise la méthode add, dont la signature ressemble à ceci :
fn add(self, s: &str) -> String {Dans la bibliothèque standard, vous pouvez constater que add est défini en utilisant des génériques et des types associés. Ici, nous avons remplacé ces types génériques par des types concrets, ce qui se produit lorsque nous appelons cette méthode avec des valeurs de type String. Nous aborderons la généricité au chapitre 10. Cette signature nous donne les éléments dont nous avons besoin pour comprendre les subtilités de l’opérateur +.
Premièrement, s2 a un &, ce qui veut dire que nous ajoutons une référence vers la seconde chaîne de caractères à la première chaîne. C’est à cause du paramètre s de la fonction add : nous pouvons seulement ajouter une slice de chaîne de caractères à une String ; nous ne pouvons pas ajouter deux valeurs de type String ensemble. Mais attendez — le type de &s2 est &String, et non pas &str, comme c’est écrit dans le second paramètre de add. Alors pourquoi est-ce que le code de l’encart 8-18 se compile ?
La raison pour laquelle nous pouvons utiliser &s2 dans l’appel à add est que le compilateur peut extrapoler l’argument &String en un &str. Lorsque nous appelons la méthode add, Rust va utiliser une extrapolation de déréférencement, qui transforme ici &s2 en &s2[..]. Nous verrons plus en détail l’extrapolation de déréférencement au chapitre 15. Comme add ne prend pas possession du paramètre s, s2 sera toujours une String valide après cette opération.
Ensuite, nous pouvons constater que la signature de add prend possession de self, car self n’a pas de &. Cela signifie que s1 dans l’encart 8-18 va être déplacé dans l’appel à add et ne sera plus en vigueur après cela. Donc bien que let s3 = s1 + &s2 semble copier les deux chaînes de caractères pour en créer une nouvelle, cette instruction va en réalité prendre possession de s1, y ajouter une copie du contenu de s2 et nous redonner la possession du résultat. Autrement dit, cela semble faire beaucoup de copies mais en réalité non ; son implémentation est plus efficace que la copie.
Si nous avons besoin de concaténer plusieurs chaînes de caractères, le comportement de l’opérateur + devient difficile à utiliser :
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
}Au final, s vaudra tic-tac-toe. Avec tous les caractères + et ", il est difficile de visualiser ce qui se passe. Pour des combinaisons plus complexes de chaînes de caractères, nous pouvons utiliser à la place la macro format! :
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{s1}-{s2}-{s3}");
}Ce code assigne lui aussi à s la valeur tic-tac-toe. La macro format! fonctionne comme println!, mais au lieu d’afficher son résultat à l’écran, elle retourne une String avec son contenu. La version du code qui utilise format! est plus facile à lire, et le code généré par la macro format! utilise des références afin qu’il ne prenne pas possession de ses paramètres.
L’indexation des Strings
Dans de nombreux autres langages de programmation, l’accès individuel aux caractères d’une chaîne de caractères en utilisant leur indice est une opération valide et courante. Cependant, si vous essayez d’accéder à des éléments d’une String en utilisant la syntaxe d’indexation avec Rust, vous allez avoir une erreur. Nous tentons cela dans le code invalide de l’encart 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}StringCe code va produire l’erreur suivante :
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
L’erreur et la remarque nous expliquent le problème : les String de Rust n’acceptent pas l’utilisation des indices. Mais pourquoi ? Pour répondre à cette question, nous avons besoin de savoir comment Rust enregistre les chaînes de caractères dans la mémoire.
Représentation interne
Une String est une surcouche de Vec<u8>. Revenons sur certains exemples de chaînes de caractères correctement encodées en UTF-8 que nous avions dans l’encart 8-14. Premièrement, celle-ci :
fn main() {
let bonjour = String::from("السلام عليكم");
let bonjour = String::from("Dobrý den");
let bonjour = String::from("Hello");
let bonjour = String::from("שלום");
let bonjour = String::from("नमस्ते");
let bonjour = String::from("こんにちは");
let bonjour = String::from("안녕하세요");
let bonjour = String::from("你好");
let bonjour = String::from("Olá");
let bonjour = String::from("Здравствуйте");
let bonjour = String::from("Hola");
}Dans ce cas-ci, len vaudra 4, ce qui veut dire que le vecteur qui stocke la chaîne “Hola” a une taille de 4 octets. Chacune des lettres prend 1 octet lorsqu’elles sont encodées en UTF-8. Cependant, la ligne suivante peut surprendre. (Notez que cette chaîne de caractères commence avec la lettre majuscule cyrillique Zé, et non pas le chiffre arabe 3.)
fn main() {
let bonjour = String::from("السلام عليكم");
let bonjour = String::from("Dobrý den");
let bonjour = String::from("Hello");
let bonjour = String::from("שלום");
let bonjour = String::from("नमस्ते");
let bonjour = String::from("こんにちは");
let bonjour = String::from("안녕하세요");
let bonjour = String::from("你好");
let bonjour = String::from("Olá");
let bonjour = String::from("Здравствуйте");
let bonjour = String::from("Hola");
}Si on vous demandait la longueur de la chaîne de caractères, vous répondriez probablement 12. En réalité, la réponse de Rust sera 24 : c’est le nombre d’octets nécessaires pour encoder “Здравствуйте” en UTF-8, car chaque valeur scalaire Unicode dans cette chaîne de caractères prend 2 octets en mémoire. Par conséquent, un indice dans les octets de la chaîne de caractères ne correspondra pas forcément à une valeur scalaire Unicode valide. Pour démontrer cela, utilisons ce code Rust invalide :
let bonjour = "Здравствуйте";
let reponse = &bonjour[0];Vous savez déjà que reponse ne vaudra pas З, la première lettre. Lorsqu’il est encodé en UTF-8, le premier octet de З est 208 et le second est 151, donc on dirait que reponse vaudrait 208, mais 208 n’est pas un caractère valide à lui seul. Retourner 208 n’est pas ce qu’un utilisateur attend s’il demande la première lettre de cette chaîne de caractères ; cependant, c’est la seule valeur que Rust a à l’indice 0 des octets. Les utilisateurs ne souhaitent généralement pas obtenir la valeur d’un octet, même si la chaîne de caractères contient uniquement des lettres latines : si &"hi"[0] était un code valide qui retournait la valeur de l’octet, il retournerait 104 et non pas h.
La solution est donc, pour éviter de retourner une valeur inattendue et générer des bogues qui ne seraient pas découverts immédiatement, que Rust ne va pas compiler ce code et va ainsi éviter des erreurs dès le début du processus de développement.
Octets, valeurs scalaires et groupes de graphèmes
Un autre problème avec l’UTF-8 est qu’il a en fait trois manières pertinentes de considérer les chaînes de caractères avec Rust : comme des octets, comme des valeurs scalaires ou comme des groupes de graphèmes (ce qui se rapproche le plus de ce que nous pourrions appeler des lettres).
Si l’on considère le mot hindi “नमस्ते” écrit en écriture devanagari, il est stocké comme un vecteur de valeurs u8 qui sont les suivantes :
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Cela fait 18 octets et c’est ainsi que les ordinateurs stockeront cette donnée. Si nous les voyons comme des valeurs scalaires Unicode, ce qu’est le type char de Rust, ces octets seront les suivants :
['न', 'म', 'स', '्', 'त', 'े']
Nous avons six valeurs char ici, mais les quatrième et sixième valeurs ne sont pas des lettres : ce sont des signes diacritiques qui n’ont pas de sens employés seuls. Enfin, si nous les voyons comme des groupes de graphèmes, on obtient ce qu’on pourrait appeler les quatre lettres qui constituent le mot hindi :
["न", "म", "स्", "ते"]
Rust fournit différentes manières d’interpréter les données brutes des chaînes de caractères que les ordinateurs stockent afin que chaque programme puisse choisir l’interprétation dont il a besoin, peu importe la langue dans laquelle sont les données.
Une dernière raison pour laquelle Rust ne nous autorise pas à indexer une String pour récupérer un caractère est que les opérations d’indexation sont censées prendre un temps constant (O(1)). Mais il n’est pas possible de garantir cette performance avec une String, car Rust devrait parcourir le contenu depuis le début jusqu’à l’indice pour déterminer combien il y a de caractères valides.
Les slices de chaînes de caractères
L’indexation sur une chaîne de caractères est souvent une mauvaise idée car le type de retour de l’opération n’est pas toujours évident : un octet, un caractère, un groupe de graphèmes ou une slice de chaîne de caractères ? Si vous avez vraiment besoin d’utiliser des indices pour créer des slices de chaînes, Rust vous demande plus de précisions.
Plutôt que d’utiliser [] avec un nombre seul, vous pouvez utiliser [] avec un intervalle d’indices pour créer une slice de chaîne contenant des octets bien précis, plutôt que d’utiliser [] avec un seul nombre :
#![allow(unused)]
fn main() {
let bonjour = "Здравствуйте";
let s = &bonjour[0..4];
}Ici, s sera un &str qui contiendra les 4 premiers octets de la chaîne de caractères. Précédemment, nous avions mentionné que chacun de ces caractères était encodé sur 2 octets, ce qui veut dire que s vaudra Зд.
Si vous essayons de produire une slice d’une partie des octets d’un caractère avec quelquechose comme &bonjour[0..1], Rust va paniquer au moment de l’exécution de la même façon que si nous utilisions un indice invalide pour accéder à un élément d’un vecteur :
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Vous devriez faire attention quand vous créez des slices de chaînes de caractères avec des intervalles, car cela peut provoquer un plantage de votre programme.
Parcours de chaînes de caractères
La meilleure manière de travailler sur des parties de chaînes de caractères est d’exprimer clairement si vous voulez travailler avec des caractères ou des octets. Pour les valeurs scalaires Unicode une par une, utilisez la méthode chars. Appeler chars sur “Зд” sépare et retourne deux valeurs de type char, et vous pouvez itérer sur le résultat pour accéder à chaque élément :
#![allow(unused)]
fn main() {
for c in "Зд".chars() {
println!("{c}");
}
}Ce code va afficher ceci :
З
д
Aussi, la méthode bytes va retourner chaque octet brut, ce qui sera peut-être plus utile selon ce que vous voulez faire :
#![allow(unused)]
fn main() {
for b in "Зд".bytes() {
println!("{b}");
}
}Ce code va afficher les 4 octets qui constituent cette String :
208
151
208
180
Rappelez-vous bien que des valeurs scalaires Unicode peuvent être constituées de plus d’un octet.
L’obtention des groupes de graphèmes à partir de chaînes de caractères, comme dans l’écriture Devanagari, est complexe, donc cette fonctionnalité n’est pas fournie par la bibliothèque standard. Des crates sont disponibles sur crates.io si c’est la fonctionnalité dont vous avez besoin.
Gérer la complexité des chaînes de caractères
Pour résumer, les chaînes de caractères sont complexes. Les différents langages de programmation ont fait différents choix sur la façon de présenter cette complexité aux développeurs. Rust a choisi d’appliquer par défaut la gestion rigoureuse des données de String pour tous les programmes Rust, ce qui veut dire que les développeurs doivent réfléchir davantage à la gestion des données UTF-8. Ce compromis révèle davantage la complexité des chaînes de caractères par rapport à ce que les autres langages de programmation laissent paraître, mais vous évite d’avoir à gérer plus tard dans votre cycle de développement des erreurs à cause de caractères non ASCII.
La bonne nouvelle, c’est que la bibliothèque standard propose de nombreuses fonctionnalités reposant sur les chaînes String et &str pour vous aider à gérer correctement ces situations complexes. Assurez-vous de consulter la documentation pour découvrir des méthodes utiles telles que contains, qui permet d’effectuer une recherche dans une chaîne, et replace, qui permet de remplacer des parties d’une chaîne par une autre chaîne.
Passons maintenant à quelque chose de moins complexe : les tables de hachage !
Stocker des clés associées à des valeurs dans des tables de hachage
Stocker des clés associées à des valeurs dans des tables de hachage
La dernière des collections les plus courantes est la table de hachage (hash map). Le type HashMap<K, V> stocke une association de clés de type K à des valeurs de type V en utilisant une fonction de hachage, qui détermine comment elle va ranger ces clés et valeurs dans la mémoire. De nombreux langages de programmation prennent en charge ce genre de structure de données, mais elles ont souvent un nom différent, tel que hash, map, objet, table d’association, dictionnaire ou tableau associatif, pour n’en nommer que quelques-uns.
Les tables de hachage sont utiles lorsque vous voulez rechercher des données non pas en utilisant des indices, comme vous pouvez le faire avec les vecteurs, mais en utilisant une clé qui peut être de n’importe quel type. Par exemple, dans un jeu, vous pouvez consigner le score de chaque équipe dans une table de hachage dans laquelle chaque clé est le nom d’une équipe et la valeur est le score de l’équipe. Si vous avez le nom d’une équipe, vous pouvez récupérer son score.
Nous allons passer en revue l’API de base des tables de hachage dans cette section, mais bien d’autres fonctionnalités se cachent dans les fonctions définies sur HashMap<K, V> par la bibliothèque standard. Comme d’habitude, consultez la documentation de la bibliothèque standard pour plus d’informations.
Créer une nouvelle table de hachage
Une façon de créer une table de hachage vide est d’utiliser new et d’ajouter des éléments avec insert. Dans l’encart 8-20, nous consignons les scores de deux équipes qui s’appellent Bleu et Jaune. L’équipe Bleu commence avec 10 points, et l’équipe Jaune commence avec 50.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Bleu"), 10);
scores.insert(String::from("Jaune"), 50);
}Notez que nous devons d’abord importer HashMap via use depuis la partie des collections de la bibliothèque standard. De nos trois collections courantes, cette dernière est la moins utilisée, donc elle n’est pas présente dans les fonctionnalités importées automatiquement dans la portée par l’étape préliminaire. Les tables de hachage sont aussi moins gérées par la bibliothèque standard ; il n’y a pas de macro intégrée pour les construire, par exemple.
Exactement comme les vecteurs, les tables de hachage stockent leurs données sur le tas. Cette HashMap a des clés de type String et des valeurs de type i32. Et comme les vecteurs, les tables de hachage sont homogènes : toutes les clés doivent être du même type, et toutes les valeurs doivent aussi être du même type.
Accéder aux valeurs dans une table de hachage
Nous pouvons obtenir une valeur d’une table de hachage en passant sa clé à la méthode get, comme dans l’encart 8-21.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Bleu"), 10);
scores.insert(String::from("Jaune"), 50);
let nom_equipe = String::from("Bleu");
let score = scores.get(&nom_equipe).copied().unwrap_or(0);
}Dans notre cas, score aura la valeur qui est associée à l’équipe Bleu, et le résultat sera 10. La méthode get retourne une Option<&V> : s’il n’y a pas de valeur pour cette clé dans la table de hachage, get va retourner None. Ce programme gère cette Option en appelant copied pour obtenir un Option<i32> plutôt qu’un Option<&i32>, puis unwrap_or pour mettre score à zéro si scores n’a pas d’entrée pour cette clé.
Nous pouvons itérer sur chaque paire de clé-valeur dans une table de hachage de la même manière que nous le faisons avec les vecteurs, en utilisant une boucle for :
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Bleu"), 10);
scores.insert(String::from("Jaune"), 50);
for (cle, valeur) in &scores {
println!("{cle} : {valeur}");
}
}Ce code va afficher chaque paire dans un ordre arbitraire :
Jaune : 50
Bleu : 10
Gestion de la possession dans les tables de hachage
Pour les types qui implémentent le trait Copy, comme i32, les valeurs sont copiées dans la table de hachage. Pour les valeurs qui sont possédées comme String, les valeurs seront déplacées et la table de hachage sera la propriétaire de ces valeurs, comme démontré dans l’encart 8-22.
fn main() {
use std::collections::HashMap;
let nom_champ = String::from("Couleur favorite");
let valeur_champ = String::from("Bleu");
let mut table = HashMap::new();
table.insert(nom_champ, valeur_champ);
// nom_champ et valeur_champ ne sont plus en vigueur à partir d'ici,
// essayez de les utiliser et vous verrez l'erreur du compilateur que
// vous obtiendrez !
}Nous ne pouvons plus utiliser les variables nom_champ et valeur_champ après qu’elles ont été déplacées dans la table de hachage lors de l’appel à insert.
Si nous insérons dans la table de hachage des références vers des valeurs, ces valeurs ne seront pas déplacées dans la table de hachage. Les valeurs vers lesquelles les références pointent doivent rester en vigueur au moins aussi longtemps que la table de hachage. Nous verrons ces problématiques dans la section “La conformité des références avec les durées de vies” du chapitre 10.
Modifier une table de hachage
Bien que le nombre de paires de clé-valeur puisse augmenter, chaque clé unique ne peut être associée qu’à une seule valeur à la fois (mais la réciproque n’est pas vraie : par exemple, les équipes Bleu et Jaune pourraient toutes deux avoir la valeur 10 stockée dans la table de hachage scores).
Lorsque vous souhaitez modifier les données d’une table de hachage, vous devez choisir comment gérer le cas où une clé a déjà une valeur qui lui est associée. Vous pouvez remplacer l’ancienne valeur avec la nouvelle valeur, en ignorant complètement l’ancienne valeur. Vous pouvez garder l’ancienne valeur et ignorer la nouvelle valeur, en insérant la nouvelle valeur uniquement si la clé n’a pas déjà une valeur. Ou vous pouvez fusionner l’ancienne valeur et la nouvelle. Découvrons dès maintenant comment faire chacune de ces actions !
Réécrire une valeur
Si nous ajoutons une clé et une valeur dans une table de hachage et que nous ajoutons à nouveau la même clé avec une valeur différente, la valeur associée à cette clé sera remplacée. Même si le code dans l’encart 8-23 appelle deux fois insert, la table de hachage contiendra une seule paire de clé/valeur car nous ajoutons la valeur pour l’équipe Bleu à deux reprises.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Bleu"), 10);
scores.insert(String::from("Bleu"), 25);
println!("{scores:?}");
}Ce code va afficher {"Bleu": 25}. La valeur initiale 10 a été remplacée.
Ajouter une valeur seulement si la clé n’a pas déjà de valeur
Il est courant de vérifier si une clé spécifique existe déjà dans la table de hachage avec une valeur, et ensuite de procéder aux actions suivantes : si la clé existe dans la table de hachage, la valeur existante doit rester telle quelle ; si la clé n’existe pas, l’insérer avec une valeur associée.
Les tables de hachage ont une API spécifique pour ce cas-là qui s’appelle entry et qui prend en paramètre la clé que vous voulez vérifier. La valeur de retour de la méthode entry est une énumération qui s’appelle Entry qui représente une valeur qui existe ou non. Imaginons que nous souhaitons vérifier si la clé pour l’équipe Jaune a une valeur qui lui est associée. Si ce n’est pas le cas, nous voulons lui associer la valeur 50, et faire de même pour l’équipe Bleu. En utilisant l’API entry, ce code va ressembler à l’encart 8-24.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Bleu"), 10);
scores.entry(String::from("Jaune")).or_insert(50);
scores.entry(String::from("Bleu")).or_insert(50);
println!("{scores:?}");
}entry method to only insert if the key does not already have a valueLa méthode or_insert sur Entry est conçue pour retourner une référence mutable vers la valeur correspondant à la clé du Entry si cette clé existe, et sinon, d’ajouter son paramètre comme nouvelle valeur pour cette clé et retourner une référence mutable vers la nouvelle valeur. Cette technique est plus propre que d’écrire la logique nous-mêmes et, de plus, elle fonctionne mieux avec le vérificateur d’emprunt.
L’exécution du code de l’encart 8-24 va afficher {"Jaune": 50, "Bleu": 10}. Le premier appel à entry va ajouter la clé pour l’équipe Jaune avec la valeur 50 car l’équipe Jaune n’a pas encore de valeur. Le second appel à entry ne va pas changer la table de hachage car l’équipe Bleu a déjà la valeur 10.
Modifier une valeur en fonction de l’ancienne valeur
Une autre utilisation courante avec les tables de hachage est de regarder la valeur d’une clé et ensuite la modifier en fonction de l’ancienne valeur. Par exemple, l’encart 8-25 contient du code qui compte combien de fois chaque mot apparaît dans du texte. Nous utilisons une table de hachage avec les mots comme clés et nous incrémentons la valeur pour compter combien de fois nous avons vu ce mot. Si c’est la première fois que nous voyons un mot, nous allons d’abord insérer la valeur 0.
fn main() {
use std::collections::HashMap;
let texte = "bonjour le monde magnifique monde";
let mut table = HashMap::new();
for mot in texte.split_whitespace() {
let compteur = table.entry(mot).or_insert(0);
*compteur += 1;
}
println!("{table:?}");
}Ce code va afficher {"monde": 2, "bonjour": 1, "magnifique": 1, "le": 1}. Il se peut que vous voyez les mêmes paires clé-valeurs ordonnées différemment : rappelez-vous du paragraphe “Accéder aux valeurs dans une table de hachage”, l’itération sur une table de hachage se fait dans un ordre aléatoire.
La méthode split_whitespace renvoie un itérateur sur les sous-slices, séparées par des espaces vides, sur la valeur dans texte. La méthode or_insert retourne une référence mutable (&mut V) vers la valeur de la clé spécifiée. Nous stockons ici la référence mutable dans la variable compteur, donc pour affecter une valeur, nous devons d’abord déréférencer compteur en utilisant l’astérisque (*). La référence mutable sort de la portée à la fin de la boucle for, donc tous ces changements sont sûrs et autorisés par les règles d’emprunt.
Fonctions de hachage
Par défaut, HashMap utilise une fonction de hachage nommée SipHash qui résiste aux attaques par déni de service (DoS) envers les tables de hachage1. Ce n’est pas l’algorithme de hachage le plus rapide qui existe, mais le compromis entre une meilleure sécurité et la baisse de performances en vaut la peine. Si vous analysez la performance de votre code et que vous vous rendez compte que la fonction de hachage par défaut est trop lente pour vos besoins, vous pouvez la remplacer par une autre fonction en spécifiant un hacheur différent. Un hacheur est un type qui implémente le trait BuildHasher. Nous verrons les traits et comment les implémenter au chapitre 10. Vous n’avez pas forcément besoin d’implémenter votre propre hacheur à partir de zéro ; crates.io héberge des bibliothèques partagées par d’autres utilisateurs de Rust qui fournissent de nombreux algorithmes de hachage répandus.
Résumé
Les vecteurs, Strings, et tables de hachage vont vous apporter de nombreuses fonctionnalités nécessaires à vos programmes lorsque vous aurez besoin de stocker, accéder, et modifier des données. Voici quelques exercices que vous devriez maintenant être en mesure de résoudre :
- À partir d’une liste d’entiers, utiliser un vecteur et retourner la médiane (la valeur au milieu lorsque la liste est triée) et le mode (la valeur qui apparaît le plus souvent ; une table de hachage sera utile dans ce cas) de la liste.
- Convertir des chaînes de caractères dans une variante du louchébem. La consonne initiale de chaque mot est remplacée par la lettre
let est rétablie à la fin du mot suivie du suffixe argotique “em” ; ainsi, “bonjour” devient “l_onjour_bem”. Si le mot commence par une voyelle, ajouter unlau début du mot et ajouter à la fin le suffixe “muche”. Et gardez en tête les détails à propos de l’encodage UTF-8 ! - En utilisant une table de hachage et des vecteurs, créez une interface textuelle pour permettre à un utilisateur d’ajouter des noms d’employés dans un département d’une entreprise. Par exemple, “Ajouter Sally au bureau d’études” ou “Ajouter Amir au service commercial”. Ensuite, donnez la possibilité à l’utilisateur de récupérer une liste de toutes les personnes dans un département, ou tout le monde dans l’entreprise trié par département, et classés dans l’ordre alphabétique dans tous les cas.
La documentation de l’API de la bibliothèque standard décrit les méthodes qu’ont les vecteurs, chaînes de caractères et tables de hachage, ce qui vous sera bien utile pour mener à bien ces exercices !
Nous nous lançons dans des programmes de plus en plus complexes dans lesquels les opérations peuvent échouer, c’est donc le moment idéal pour voir comment bien gérer les erreurs. C’est ce que nous allons faire au prochain chapitre !
La gestion des erreurs
Les erreurs font partie de la vie des programmes informatiques, c’est pourquoi Rust a des fonctionnalités pour gérer les situations dans lesquelles quelque chose dérape. Dans de nombreux cas, Rust exige que vous anticipiez les erreurs possibles et que vous preniez des dispositions avant de pouvoir compiler votre code. Cette exigence rend votre programme plus résilient en s’assurant que vous détectez et gérez les erreurs correctement avant même que vous ne déployiez votre code en production !
Rust classe les erreurs dans deux catégories principales : les erreurs récupérables et irrécupérables. Pour les erreurs récupérables, comme l’erreur le fichier n’a pas été trouvé, nous préférons probablement signaler le problème à l’utilisateur et relancer l’opération. Les erreurs irrécupérables sont toujours des symptômes de bogues, comme par exemple essayer d’accéder à un élément en dehors de l’intervalle de données d’un tableau : dans un tel cas, nous voulons arrêter immédiatement l’exécution du programme.
La plupart des langages de programmation ne font pas de distinction entre ces deux types d’erreurs et les gèrent de la même manière, en utilisant des fonctionnalités comme les exceptions. Rust n’a pas d’exception. À la place, il a les types Result<T, E> pour les erreurs récupérables, et la macro panic! qui arrête l’exécution quand le programme se heurte à des erreurs irrécupérables. Nous allons commencer ce chapitre par expliquer l’utilisation de panic!, puis nous allons voir les valeurs de retour Result<T, E>. Enfin, nous allons voir les éléments à prendre en compte pour décider si nous devons essayer de rattraper une erreur ou alors arrêter l’exécution.
Les erreurs irrécupérables avec panic!
Les erreurs irrécupérables avec panic!
Parfois, des choses se passent mal dans votre code, et vous ne pouvez rien y faire. Pour ces cas-là, Rust a la macro panic!. En pratique, il y a deux manières de déclencher une panique : soit en effectuant une action qui va faire paniquer notre code (comme l’accès à un tableau au-delà de sa fin), soit en appelant explicitement la macro panic!. Dans les deux cas, nous provoquons une panique dans notre programme. Par défaut, ces paniques affichent un message d’erreur, déroulent et nettoient la pile d’appels, et terminent le programme. À l’aide d’une variable d’environnement, vous pouvez faire en sorte que Rust affiche la pile d’appels quand une panique se produit, afin de faciliter la recherche de la source à l’origine de la panique.
Dérouler la pile ou abandonner suite à un panic!
Par défaut, quand un panic se produit, le programme se met à dérouler, ce qui veut dire que Rust retourne en arrière dans la pile et nettoie les données de chaque fonction qu’il rencontre sur son passage. Cependant, cette marche arrière et ce nettoyage demandent beaucoup de travail. Toutefois, Rust vous permet de choisir l’alternative d’abandonner immédiatement, ce qui arrête le programme sans nettoyage.
La mémoire qu’utilisait le programme devra ensuite être nettoyée par le système d’exploitation. Si dans votre projet vous avez besoin de construire un exécutable le plus petit possible, vous pouvez passer du déroulage à l’abandon lors d’un panic en ajoutant panic = 'abort' aux sections [profile] appropriées dans votre fichier Cargo.toml. Par exemple, si vous souhaitez abandonner lors d’un panic en mode publication (release), ajoutez ceci :
[profile.release]
panic = 'abort'
Essayons d’appeler panic! dans un programme simple :
fn main() {
panic!("Je me plante lamentablement!");
}Lorsque vous lancez le programme, vous allez voir quelque chose comme ceci :
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
Je me plante lamentablement!
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
L’appel à panic! déclenche le message d’erreur présent dans les deux dernières lignes. La première ligne affiche notre message associé au panic et l’emplacement dans notre code source où se produit le panic : src/main.rs:2:5 indique que c’est à la seconde ligne et au cinquième caractère de notre fichier src/main.rs.
Dans cet exemple, la ligne indiquée fait partie de notre code, et si nous allons voir cette ligne, nous verrons l’appel à la macro panic!. Dans d’autres cas, l’appel de panic! pourrait se produire dans du code que notre code utilise. Le nom du fichier et la ligne indiquée par le message d’erreur seront alors ceux du code de quelqu’un d’autre où la macro panic! est appelée, et non pas la ligne de notre code qui nous a mené à cet appel de panic!.
Nous pouvons utiliser le retraçage des fonctions qui ont appelé panic! pour repérer la partie de notre code qui pose problème. Pour comprendre comment utiliser la trace de pile panic!, analysons un autre exemple pour voir ce qui se passe lors d’un appel de panic! qui se produit dans une bibliothèque à cause d’un bogue dans notre code plutôt qu’un appel à la macro directement. L’encart 9-1 montre du code qui essaye d’accéder à un indice d’un vecteur en dehors de l’intervalle des indices valides.
fn main() {
let v = vec![1, 2, 3];
v[99];
}panic!Ici, nous essayons d’accéder au centième élément de notre vecteur (qui est à l’indice 99 car l’indexation commence à zéro), mais le vecteur a seulement trois éléments. Dans ce cas, Rust va paniquer. Utiliser [] est censé retourner un élément, mais si vous lui donnez un indice invalide, Rust ne pourra pas retourner un élément acceptable dans ce cas.
En C, tenter de lire au-delà de la fin d’une structure de données suit un comportement indéfini. Vous pourriez récupérer la valeur à l’emplacement mémoire qui correspondrait à l’élément demandé de la structure de données, même si cette partie de la mémoire n’appartient pas à cette structure de données. C’est ce qu’on appelle une lecture hors limites et cela peut mener à des failles de sécurité si un attaquant a la possibilité de contrôler l’indice de telle manière qu’il puisse lire les données qui ne devraient pas être lisibles en dehors de la structure de données.
Afin de protéger votre programme de ce genre de vulnérabilité, si vous essayez de lire un élément à un indice qui n’existe pas, Rust va arrêter l’exécution et refuser de continuer. Essayez et vous verrez :
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Cette erreur mentionne la ligne 4 de notre fichier main.rs où on essaie d’accéder à l’indice 99.
La ligne commençant par note: nous informe que nous pouvons régler la variable d’environnement RUST_BACKTRACE pour obtenir le retraçage de ce qui s’est exactement passé pour mener à cette erreur. Un retraçage consiste à lister toutes les fonctions qui ont été appelées pour arriver jusqu’à ce point. En Rust, le retraçage fonctionne comme dans d’autres langages : le secret pour lire le retraçage est de commencer d’en haut et lire jusqu’à ce que vous voyiez les fichiers que vous avez écrits. C’est l’endroit où s’est produit le problème. Les lignes avant cet endroit est du code qui a été appelé par votre propre code ; les lignes qui suivent représentent le code qui a appelé votre code. Ces lignes “avant et après” peuvent être du code du cœur de Rust, du code de la bibliothèque standard, ou des crates que vous utilisez. Essayons d’obtenir un retraçage en réglant la variable d’environnement RUST_BACKTRACE à n’importe quelle valeur autre que 0. L’encart 9-2 nous montre un retour similaire à ce que vous devriez voir :
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
panic! displayed when the environment variable RUST_BACKTRACE is setCela fait beaucoup de contenu ! Ce que vous voyez sur votre machine peut être différent en fonction de votre système d’exploitation et de votre version de Rust. Pour avoir le retraçage avec ces informations, les symboles de débogage doivent être activés. Les symboles de débogage sont activés par défaut quand on utilise cargo build ou cargo run sans le drapeau --release, comme c’est le cas ici.
Dans l’encart 9-2, la ligne 6 du retraçage nous montre la ligne de notre projet qui provoque le problème : la ligne 4 de src/main.rs. Si nous ne voulons pas que notre programme panique, le premier endroit que nous devrions inspecter est l’emplacement cité par la première ligne qui mentionne du code que nous avons écrit. Dans l’encart 9-1, où nous avons délibérément écrit du code qui panique, la solution pour ne pas paniquer est de ne pas demander un élément en dehors de l’intervalle des indices du vecteur. À l’avenir, quand votre code paniquera, vous aurez besoin de prendre des dispositions dans votre code pour les valeurs qui font paniquer et de coder quoi faire lorsque cela se produit.
Nous reviendrons sur le cas du panic! et sur les cas où nous devrions et ne devrions pas utiliser panic! pour gérer les conditions d’erreur plus tard à la fin de ce chapitre. Pour le moment, nous allons voir comment gérer une erreur en utilisant Result.
Des erreurs récupérables avec Result
Des erreurs récupérables avec Result
La plupart des erreurs ne sont pas assez graves au point d’arrêter complètement le programme. Parfois, lorsqu’une fonction échoue, c’est pour une raison que vous pouvez facilement comprendre et pour laquelle vous pouvez agir en conséquence. Par exemple, si vous essayez d’ouvrir un fichier et que l’opération échoue parce que le fichier n’existe pas, vous pourriez vouloir créer le fichier plutôt que d’arrêter le processus.
Souvenez-vous de la section “Gérer les erreurs potentielles avec le type Result” du chapitre 2 que l’énumération Result possède deux variantes, Ok et Err, comme ci-dessous :
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}Le T et le E sont des paramètres de type génériques : nous parlerons plus en détail de la généricité au chapitre 10. Tout ce que vous avez besoin de savoir pour le moment, c’est que T représente le type de valeur imbriquée dans la variante Ok qui sera retournée dans le cas d’un succès, et E représente le type d’erreur imbriquée dans la variante Err qui sera retournée dans le cas d’un échec. Comme Result a ces paramètres de type génériques, nous pouvons utiliser le type Result et les fonctions associées dans différentes situations où la valeur de succès et la valeur d’erreur peuvent varier.
Utilisons une fonction qui retourne une valeur de type Result car la fonction peut échouer. Dans l’encart 9-3, nous essayons d’ouvrir un fichier :
use std::fs::File;
fn main() {
let resultat_fichier_salut = File::open("hello.txt");
}Le type de retour de File::open est un Result<T, E>. Le paramètre générique T a été renseigné par l’implémentation deFile::open avec le type de la valeur qui a réussi, std::fs::File, qui est un descripteur de fichier. Le E utilisé pour la valeur d’erreur est du type std::io::Error. Ce type de retour signifie que l’appel à File::open peut réussir et renvoyer un descripteur de fichier qui peut nous permettre de le lire ou d’y écrire. L’appel de fonction peut également échouer : par exemple, le fichier peut ne pas exister, ou nous pourrions ne pas avoir les autorisations requises pour accéder au fichier. La fonction File::open doit avoir un moyen de nous dire si son utilisation a réussi ou échoué et en même temps nous fournir soit le manipulateur de fichier, soit des informations sur l’erreur. Ce sont exactement ces informations que l’énumération Result se charge de nous transmettre.
Dans le cas où File::open réussit, la valeur que nous obtiendrons dans la variable resultat_fichier_salut sera une instance de Ok qui contiendra un manipulateur de fichier. Dans le cas où cela échoue, la valeur dans resultat_fichier_salut sera une instance de Err qui contiendra plus d’information sur le type d’erreur qui a eu lieu.
Nous avons besoin d’ajouter différentes actions dans le code de l’encart 9-3 en fonction de la valeur que File::open retourne. L’encart 9-4 montre une façon de gérer le Result en utilisant un outil basique, l’expression match que nous avons vue au chapitre 6.
use std::fs::File;
fn main() {
let resultat_fichier_salut = File::open("hello.txt");
let resultat_fichier_salut = match resultat_fichier_salut {
Ok(fichier) => fichier,
Err(erreur) => panic!("Erreur d'ouverture du fichier : {erreur:?}"),
};
}match expression to handle the Result variants that might be returnedRemarquez que, tout comme l’énumération Option, l’énumération Result et ses variantes ont été importées par l’étape préliminaire, donc vous n’avez pas besoin de préciser Result:: devant les variantes Ok et Err dans les branches du match.
Lorsque le résultat est Ok, ce code va retourner la valeur fichier contenue dans la variante Ok, et nous assignons ensuite cette valeur à la variable resultat_fichier_salut. Après le match, nous pourrons ensuite utiliser le manipulateur de fichier pour lire ou écrire.
L’autre branche du bloc match gère le cas où nous obtenons un Err à l’appel de File::open. Dans cet exemple, nous avons choisi de faire appel à la macro panic!. S’il n’y a pas de fichier qui s’appelle hello.txt dans notre répertoire actuel et que nous exécutons ce code, nous allons voir la sortie suivante suite à l’appel de la macro panic! :
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Erreur d'ouverture du fichier : Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Comme d’habitude, cette sortie nous explique avec précision ce qui s’est mal passé.
Gérer les différentes erreurs
Le code dans l’encart 9-4 va faire un panic! peu importe la raison de l’échec de File::open. Cependant, nous voulons réagir différemment en fonction de différents cas d’erreurs : si File::open a échoué parce que le fichier n’existe pas, nous voulons créer le fichier et retourner le manipulateur de fichier pour ce nouveau fichier. Si File::open échoue pour toute autre raison, par exemple si nous n’avons pas l’autorisation d’ouvrir le fichier, nous voulons quand même que le code lance un panic! de la même manière qu’il l’a fait dans l’encart 9-4. C’est pourquoi nous avons ajouté dans l’encart 9-5 une expression match imbriquée :
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let resultat_fichier_salut = File::open("hello.txt");
let resultat_fichier_salut = match resultat_fichier_salut {
Ok(fichier) => fichier,
Err(erreur) => match erreur.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Erreur de création du fichier : {e:?}"),
},
_ => {
panic!("Erreur d'ouverture du fichier : {erreur:?}");
}
},
};
}La valeur de retour de File::open logée dans la variante Err est de type io::Error, qui est une structure fournie par la bibliothèque standard. Cette structure a une méthode kind que nous pouvons appeler pour obtenir une valeur de type io::ErrorKind. L’énumération io::ErrorKind est fournie elle aussi par la bibliothèque standard et a des variantes qui représentent les différents types d’erreurs qui pourraient résulter d’une opération provenant du module io. La variante que nous voulons utiliser est ErrorKind::NotFound, qui indique que le fichier que nous essayons d’ouvrir n’existe pas encore. Donc nous utilisons match sur resultat_fichier_salut, mais nous avons dans celle-ci un autre match sur erreur.kind().
Nous souhaitons vérifier dans le match interne si la valeur de retour de error.kind() est la variante NotFound de l’énumération ErrorKind. Si c’est le cas, nous essayons de créer le fichier avec File::create. Cependant, comme File::create peut aussi échouer, nous avons besoin d’une seconde branche dans le match interne. Lorsque le fichier ne peut pas être créé, un message d’erreur différent est affiché. La seconde branche du match principal reste inchangée, donc le programme panique lorsqu’on rencontre une autre erreur que l’absence de fichier.
D’autres solutions pour utiliser match avec Result<T, E>
Cela commence à faire beaucoup de match ! L’expression match est très utile mais elle est aussi assez rudimentaire. Dans le chapitre 13, vous en apprendrez plus sur les fermetures, qui sont utilisées avec de nombreuses méthodes définies sur Result<T, E>. Ces méthodes peuvent s’avérer être plus concises que l’utilisation de match lorsque vous travaillez avec des valeurs Result<T, E> dans votre code.
Par exemple, voici une autre manière d’écrire la même logique que celle dans l’encart 9-5, cette fois en utilisant les fermetures et la méthode unwrap_or_else :
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let resultat_fichier_salut = File::open("hello.txt").unwrap_or_else(|erreur| {
if erreur.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|erreur| {
panic!("Erreur de création du fichier : {erreur:?}");
})
} else {
panic!("Erreur d'ouverture du fichier : {erreur:?}");
}
});
}Bien que ce code ait le même comportement que celui de l’encart 9-5, il ne contient aucune expression match et est plus facile à lire. Revenez sur cet exemple après avoir lu le chapitre 13, et renseignez-vous sur la méthode unwrap_or_else dans la documentation de la bibliothèque standard. De nombreuses méthodes de ce type peuvent clarifier de grosses expressions match imbriquées lorsque vous traitez les erreurs.
Raccourcis pour faire un panic lors d’une erreur : unwrap et expect
L’utilisation de match fonctionne assez bien, mais elle peut être un peu verbeuse et ne communique pas forcément bien son intention. Le type Result<T, E> a de nombreuses méthodes qui lui ont été définies pour différents cas. La méthode unwrap est une méthode de raccourci implémentée comme l’expression match que nous avons écrite dans l’encart 9-4. Si la valeur de Result est la variante Ok, unwrap va retourner la valeur contenue dans le Ok. Si le Result est la variante Err, unwrap va appeler la macro panic! pour nous. Voici un exemple de unwrap en action :
use std::fs::File;
fn main() {
let fichier_salut = File::open("hello.txt").unwrap();
}Si nous exécutons ce code alors qu’il n’y a pas de fichier hello.txt, nous allons voir un message d’erreur suite à l’appel à panic! que la méthode unwrap a fait :
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
De la même manière, la méthode expect nous donne la possibilité de définir le message d’erreur du panic!. Utiliser expect plutôt que unwrap et lui fournir un bon message d’erreur permet de mieux exprimer le problème et faciliter la recherche de la source d’un panic. La syntaxe de expect est la suivante :
use std::fs::File;
fn main() {
let fichier_salut = File::open("hello.txt")
.expect("hello.txt doit être inclus dans ce projet");
}Nous utilisons expect de la même manière que unwrap : pour retourner le manipulateur de fichier ou appeler la macro panic!. Le message d’erreur utilisé par expect lors de son appel à panic! sera le paramètre que nous avons passé à expect, plutôt que le message par défaut de panic! qu’utilise unwrap. Voici ce que cela donne :
thread 'main' panicked at src/main.rs:5:10:
hello.txt doit être inclus dans ce projet: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Dans du code destiné à de la production, la plupart des Rustacés choisissent expect plutôt que unwrap et fournissent davantage de d’informations concernant les raisons pour lesquelles l’opération est supposée toujours aboutir. De la sorte, si vos hypothèses s’avèrent erronées, vous avez plus d’informations à utiliser pour le débogage.
Propager les erreurs
Lorsque l’implémentation d’une fonction utilise quelque chose qui peut échouer, au lieu de gérer l’erreur directement dans cette fonction, vous pouvez retourner cette erreur au code qui l’appelle pour que ce dernier décide que faire. C’est ce que l’on appelle propager l’erreur et donne ainsi plus de contrôle au code qui appelle la fonction, dans lequel il peut y avoir plus d’informations ou d’instructions pour traiter l’erreur que dans le contexte de votre code.
Par exemple, l’encart 9-6 montre une fonction qui lit un pseudo à partir d’un fichier. Si ce fichier n’existe pas ou ne peut pas être lu, cette fonction va retourner ces erreurs au code qui a appelé la fonction.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn lire_pseudo_depuis_fichier() -> Result<String, io::Error> {
let resultat_fichier_pseudo = File::open("hello.txt");
let mut fichier_pseudo = match resultat_fichier_pseudo {
Ok(fichier) => fichier,
Err(e) => return Err(e),
};
let mut pseudo = String::new();
match fichier_pseudo.read_to_string(&mut pseudo) {
Ok(_) => Ok(pseudo),
Err(e) => Err(e),
}
}
}matchCette fonction peut être écrite de façon plus concise, mais nous avons décidé de commencer par faire un maximum de choses manuellement pour découvrir la gestion d’erreurs ; à la fin, nous verrons comment raccourcir le code. Commençons par regarder le type de retour de la fonction : Result<String, io::Error>. Cela signifie que la fonction retourne une valeur de type Result<T, E> où le paramètre générique T a été remplacé par le type String et le paramètre générique E a été remplacé par le type io::Error.
Si cette fonction réussit sans problème, le code appellant va obtenir une valeur Ok qui contient une String, le pseudo que cette fonction lit dans le fichier. Si cette fonction rencontre un problème, le code qui appelle cette fonction va obtenir une valeur Err qui contient une instance de io::Error qui donne plus d’informations sur la raison du problème. Nous avons choisi io::Error comme type de retour de cette fonction parce qu’il se trouve que c’est le type d’erreur de retour pour les deux opérations qui peuvent échouer que l’on utilise dans le corps de cette fonction : la fonction File::open et la méthode read_to_string.
Le corps de la fonction commence par appeler la fonction File::open. Ensuite, nous gérons la valeur du Result avec un match similaire au match de l’encart 9-4. Si le File::open est un succès, le manipulateur de fichier dans la variable fichier du motif devient la valeur dans la variable mutable fichier_pseudo et la fonction continue son déroulement. Dans le cas d’un Err, au lieu d’appeler panic!, nous utilisons return pour sortir prématurément de toute la fonction et en passant la valeur du File::open, désormais dans la variable e, au code appelant comme valeur de retour de cette fonction.
Donc, si nous avons un manipulateur de fichier dans fichier_pseudo, la fonction crée ensuite une nouvelle String dans la variable pseudo et nous appelons la méthode read_to_string sur le manipulateur de fichier fichier_pseudo pour extraire le contenu du fichier dans pseudo. La méthode read_to_string retourne aussi un Result car elle peut échouer, même si File::open a réussi. Nous avons donc besoin d’un nouveau match pour gérer ce Result : si read_to_string réussit, alors notre fonction a réussi, et nous retournons le pseudo que nous avons extrait du fichier qui est maintenant intégré dans un Ok, lui-même stocké dans pseudo. Si read_to_string échoue, nous retournons la valeur d’erreur de la même façon que nous avons retourné la valeur d’erreur dans le match qui gérait la valeur de retour de File::open. Cependant, nous n’avons pas besoin d’écrire explicitement return, car c’est la dernière expression de la fonction.
Le code qui appelle ce code va devoir ensuite gérer les cas où il récupère une valeur Ok qui contient un pseudo, ou une valeur Err qui contient une io::Error. Il revient au code appelant de décider que faire avec ces valeurs. Si le code appelant obtient une valeur Err, il peut appeler panic! et faire planter le programme, utiliser un pseudo par défaut, ou chercher le pseudo autre part que dans ce fichier, par exemple. Nous n’avons pas assez d’informations sur ce que le code appelant a l’intention de faire, donc nous remontons toutes les informations de succès ou d’erreur pour qu’elles soient gérées correctement.
Cette façon de propager les erreurs est si courante en Rust que Rust fournit l’opérateur point d’interrogation ? pour faciliter ceci.
L’opérateur raccourci ?
L’encart 9-7 montre une implémentation de lire_pseudo_depuis_fichier qui a les mêmes fonctionnalités que dans l’encart 9-6, mais cette implémentation utilise l’opérateur point d’interrogation ? :
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn lire_pseudo_depuis_fichier() -> Result<String, io::Error> {
let mut fichier_pseudo = File::open("hello.txt")?;
let mut pseudo = String::new();
fichier_pseudo.read_to_string(&mut pseudo)?;
Ok(pseudo)
}
}? operatorLe ? placé après une valeur Result est conçu pour fonctionner presque de la même manière que les expressions match que nous avons définies pour gérer les valeurs Result dans l’encart 9-6. Si la valeur du Result est un Ok, la valeur dans le Ok sera retournée par cette expression et le programme continuera. Si la valeur est un Err, le Err sera retourné par la fonction comme si nous avions utilisé le mot-clé return afin que la valeur d’erreur soit propagée au code appelant.
Il y a une différence entre ce que fait l’expression match de l’encart 9-6 et ce que fait l’opérateur ? : les valeurs d’erreurs sur lesquelles est utilisé l’opérateur ? passent par la fonction from, définie dans le trait From de la bibliothèque standard, qui est utilisée pour convertir les erreurs d’un type à un autre. Lorsque l’opérateur ? appelle la fonction from, le type d’erreur reçu est converti dans le type d’erreur déclaré dans le type de retour de la fonction concernée. C’est utile lorsqu’une fonction retourne un type d’erreur qui peut couvrir tous les cas d’échec de la fonction, même si certaines de ses parties peuvent échouer pour différentes raisons. À partir du moment où il y a un impl From<AutreErreur> for ErreurRetournee pour expliquer la conversion dans la fonction from du trait, l’opérateur ? se charge d’appeler la fonction from automatiquement.
Par exemple, nous pourrions changer la fonction lire_pseudo_depuis_fichier de l’encart 9-7 pour renvoyer un type d’erreur personnalisé nommé NotreErreur que nous définissons. Si nous définissons aussi impl From<io::Error> for NotreErreur pour construire une instance de NotreErreur à partir d’un io::Error, alors l’appel à l’opérateur ? dans le corps de lire_pseudo_depuis_fichier appellera from et convertira les types d’erreur sans qu’il soit nécessaire d’ajouter plus de code à cette fonction.
Dans le cas de l’encart 9-7, le ? à la fin de l’appel à File::open va retourner la valeur à l’intérieur d’un Ok à la variable fichier_pseudo. Si une erreur se produit, l’opérateur ? va quitter prématurément la fonction et retourner une valeur Err au code appelant. La même chose se produira au ? à la fin de l’appel à read_to_string.
L’opérateur ? allège l’écriture de code et facilite l’implémentation de la fonction. Nous pouvons même encore plus réduire ce code en enchaînant immédiatement les appels aux méthodes après le ? comme dans l’encart 9-8 :
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn lire_pseudo_depuis_fichier() -> Result<String, io::Error> {
let mut pseudo = String::new();
File::open("hello.txt")?.read_to_string(&mut pseudo)?;
Ok(pseudo)
}
}? operatorNous avons déplacé la création de la nouvelle String dans pseudo au début de la fonction ; cette partie n’a pas changé. Au lieu de créer la variable fichier_pseudo, nous enchaînons directement l’appel à read_to_string sur le résultat de File::open("hello.txt")?. Nous avons toujours le ? à la fin de l’appel à read_to_string, et nous retournons toujours une valeur Ok contenant le pseudo dans pseudo lorsque File::open et read_to_string réussissent toutes les deux plutôt que de retourner des erreurs. Cette fonctionnalité est toujours la même que dans l’encart 9-6 et l’encart 9-7 ; c’est juste une façon différente et plus ergonomique de l’écrire.
L’encart 9-9 nous montre comment encore plus raccourcir tout ceci en utilisant fs::read_to_string.
#![allow(unused)]
fn main() {
use std::fs;
use std::io;
fn lire_pseudo_depuis_fichier() -> Result<String, io::Error> {
fs::read_to_string("hello.txt")
}
}fs::read_to_string instead of opening and then reading the fileRécupérer le contenu d’un fichier dans une String est une opération assez courante, donc la bibliothèque standard fournit la fonction assez pratique fs::read_to_string, qui ouvre le fichier, crée une nouvelle String, lit le contenu du fichier, insère ce contenu dans cette String, et la retourne. Évidemment, l’utilisation de fs:read_to_string ne nous offre pas l’occasion d’expliquer toute la gestion des erreurs, donc nous avons d’abord utilisé la manière la plus longue.
Où l’opérateur ? peut-il être utilisé
L’opérateur ? peut uniquement être utilisé dans des fonctions dont le type de retour est compatible avec ce sur quoi le ? est utilisé. C’est parce que l’opérateur ? est conçu pour retourner prématurément une valeur de la fonction, de la même manière que le faisait l’expression match que nous avons définie dans l’encart 9-6. Dans l’encart 9-6, le match utilisait une valeur de type Result, et la branche de retour prématuré retournait une valeur de type Err(e). Le type de retour de cette fonction doit être un Result afin d’être compatible avec ce return.
Dans l’encart 9-10, découvrons l’erreur que nous allons obtenir si nous utilisons l’opérateur ? dans une fonction main qui a un type de retour incompatible avec le type de valeur sur laquelle nous utilisons ? :
use std::fs::File;
fn main() {
let fichier_salut = File::open("hello.txt")?;
}? in the main function that returns () won’t compile.Ce code ouvre un fichier, ce qui devrait échouer. L’opérateur ? est placé derrière la valeur de type Result retournée par File::open, mais cette fonction main a un type de retour () et non pas Result. Lorsque nous compilons ce code, nous obtenons le message d’erreur suivant :
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let fichier_salut = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let fichier_salut = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
Cette erreur explique que nous sommes autorisés à utiliser l’opérateur ? uniquement dans une fonction qui retourne Result, Option, ou un autre type qui implémente FromResidual.
Pour corriger l’erreur, vous avez deux choix. Le premier est de changer le type de retour de votre fonction pour être compatible avec la valeur avec lequel vous utilisez l’opérateur ?, si vous pouvez le faire. L’autre solution est d’utiliser un match ou une des méthodes de Result<T, E> pour gérer le Result<T, E> de la manière la plus appropriée.
Le message d’erreur indique également que ? peut aussi être utilisé avec des valeurs de type Option<T>. Comme pour pouvoir utiliser ? sur un Result, vous devez utiliser ? sur Option uniquement dans une fonction qui retourne une Option. Le comportement de l’opérateur ? sur une Option<T> est identique au comportement sur un Result<T, E> : si la valeur est None, le None sera retourné prématurément à la fonction dans laquelle il est utilisé. Si la valeur est Some, la valeur dans le Some sera la valeur résultante de l’expression et la fonction continuera son déroulement. L’encart 9-11 est un exemple de fonction qui trouve le dernier caractère de la première ligne dans le texte qu’on lui fournit :
fn dernier_caractere_de_la_premiere_ligne(texte: &str) -> Option<char> {
texte.lines().next()?.chars().last()
}
fn main() {
assert_eq!(
dernier_caractere_de_la_premiere_ligne("Et bonjour\nComment ca va, aujourd'hui ?"),
Some('r')
);
assert_eq!(dernier_caractere_de_la_premiere_ligne(""), None);
assert_eq!(dernier_caractere_de_la_premiere_ligne("
salut"), None);
}? operator on an Option<T> valueCette fonction retourne un type Option<char> car il est possible qu’il y ait un caractère à cet endroit, mais il est aussi possible qu’il n’y soit pas. Ce code prend l’argument texte slice de chaîne de caractère et appelle sur elle la méthode lines, qui retourne un itérateur des lignes dans la chaîne. Comme cette fonction veut traiter la première ligne, elle appelle next sur l’itérateur afin d’obtenir la première valeur de cet itérateur. Si texte est une chaîne vide, cet appel à next va retourner None, et dans ce cas nous utilisons ? pour arrêter le déroulement de la fonction et retourner None. Si texte n’est pas une chaîne vide, next va retourner une valeur de type Some contenant une slice de chaîne de caractères de la première ligne de texte.
Le ? extrait la slice de la chaîne de caractères, et nous pouvons ainsi appeller chars sur cette slice de chaîne de caractères afin d’obtenir un itérateur de ses caractères. Nous nous intéressons au dernier caractère de cette première ligne, donc nous appelons last pour retourner le dernier élément dans l’itérateur. C’est une Option car il est possible que la première ligne soit une chaîne de caractères vide, par exemple si texte commence par une ligne vide mais a des caractères sur les autres lignes, comme par exemple "\nhi". Cependant, s’il y a un caractère à la fin de la première ligne, il sera retourné dans la variante Some. L’opérateur ? au milieu nous donne un moyen concret d’exprimer cette logique, nous permettant d’implémenter la fonction en une ligne. Si nous n’avions pas pu utiliser l’opérateur ? sur Option, nous aurions dû implémenter cette logique en utilisant plus d’appels à des méthodes ou des expressions match.
Notez bien que vous pouvez utiliser l’opérateur ? sur un Result dans une fonction qui retourne Result, et vous pouvez utiliser l’opérateur ? sur une Option dans une fonction qui retourne une Option, mais vous ne pouvez pas mélanger les deux. L’opérateur ? ne va pas convertir un Result en Option et vice-versa ; dans ce cas, vous pouvez utiliser des méthodes comme la méthode ok sur Result ou la méthode ok_or sur Option pour faire explicitement la conversion.
Jusqu’ici, toutes les fonctions main que nous avons utilisées retournent (). La fonction main est spéciale car c’est le point d’entrée et de sortie des programmes exécutables, et il y a quelques limitations sur ce que peut être le type de retour pour que les programmes se comportent correctement.
Heureusement, main peut aussi retourner un Result<(), E>. L’encart 9-12 reprend le code de l’encart 9-10 mais nous avons changé le type de retour du main pour être Result<(), Box<dyn Error>> et nous avons ajouté la valeur de retour Ok(()) à la fin. Ce code devrait maintenant pouvoir se compiler :
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let fichier_salut = File::open("hello.txt")?;
Ok(())
}main to return Result<(), E> allows the use of the ? operator on Result values.Le type Box<dyn Error> est un objet trait, que nous verrons dans une section du chapitre 18. Pour l’instant, vous pouvez interpréter Box<dyn Error> en “tout type d’erreur”. L’utilisation de ? sur une valeur type Result dans la fonction main avec le type Box<dyn Error> est donc permise, car cela permet à n’importe quelle valeur de type Err d’être retournée prématurément. Bien que le corps de la fonction main ne renvoie jamais que des erreurs de type std::io::Error, en spécifiant Box<dyn Error>, cette signature restera correcte même si du code renvoyant d’autres erreurs venait à être ajouté au corps de main.
Lorsqu’une fonction main retourne un Result<(), E>, l’exécutable va terminer son exécution avec une valeur de 0 si le main retourne Ok(()) et va se terminer avec une valeur différente de zéro si main retourne une valeur Err. Les exécutables écrits en C retournent des entiers lorsqu’ils se terminent : les programmes qui se terminent avec succès retournent l’entier 0, et les programmes qui sont en erreur retournent un entier autre que 0. Rust retourne également des entiers avec des exécutables pour être compatible avec cette convention.
La fonction main peut retourner n’importe quel type qui implémente le trait std::process::Termination, lequel contient une fonction report qui renvoie un ExitCode. Pour plus d’information concernant l’implémentation du trait Termination, reportez-vous à la documentation de la bibliothèque standard
Maintenant que nous avons vu les détails pour utiliser panic! ou retourner Result, voyons maintenant comment choisir ce qu’il faut faire en fonction des cas.
Paniquer ou ne pas paniquer, telle est la question
Paniquer ou ne pas paniquer, telle est la question
Comment décider si vous devez utiliser panic! ou si vous devez retourner un Result ? Quand un code panique, il n’y a pas de moyen de récupérer la situation. Vous pourriez utiliser panic! pour n’importe quelle situation d’erreur, peu importe s’il est possible de récupérer la situation ou non, mais vous prenez alors la décision de tout arrêter à la place du code appellant. Lorsque vous choisissez de retourner une valeur Result, vous donnez le choix au code appelant. Le code appelant peut choisir d’essayer de récupérer l’erreur de manière appropriée à la situation, ou il peut décider que dans ce cas une valeur Err est irrécupérable, et va donc utiliser panic! et transformer votre erreur récupérable en erreur irrécupérable. Ainsi, retourner Result est un bon choix par défaut lorsque vous définissez une fonction qui peut échouer.
Dans certains cas comme les exemples, les prototypes et les tests, il est plus approprié d’écrire du code qui panique plutôt que de retourner un Result. Nous allons voir pourquoi, puis nous verrons des situations dans lesquelles vous savez en tant qu’humain qu’un code ne peut pas échouer, mais que le compilateur ne peut pas le déduire par lui-même. Enfin, nous allons conclure le chapitre par quelques lignes directrices générales pour décider s’il faut paniquer dans le code d’une bibliothèque.
Les exemples, les prototypes et les tests
Lorsque vous écrivez un exemple pour illustrer un concept, y rajouter un code de gestion des erreurs très résilient peut nuire à la clarté de l’exemple. Dans les exemples, il est courant d’utiliser une méthode comme unwrap (qui peut faire un panic!) pour remplacer le code de gestion de l’erreur que vous utiliseriez en temps normal dans votre application, et qui peut changer en fonction de ce que le reste de votre code va faire.
De la même manière, les méthodes unwrap et expect sont très pratiques pour coder des prototypes, avant même de décider comment gérer les erreurs. Ce sont des indicateurs clairs dans votre code pour plus tard quand vous serez prêt à rendre votre code plus résilient aux échecs.
Si l’appel à une méthode échoue dans un test, nous voulons que tout le test échoue, même si cette méthode n’est pas la fonctionnalité que nous testons. Puisque c’est panic! qui indique qu’un test a échoué, utiliser unwrap ou expect est exactement ce qu’il faut faire.
Les cas où vous avez plus d’informations que le compilateur
Vous pouvez utiliser expect lorsque vous avez une certaine logique qui garantit que le Result sera toujours une valeur Ok, mais que ce n’est pas le genre de logique que le compilateur arrive à comprendre. Vous aurez quand même une valeur Result à gérer : l’opération que vous utilisez peut échouer de manière générale, même si dans votre cas c’est logiquement impossible. Si en inspectant manuellement le code vous vous rendez compte que vous n’aurez jamais une variante Err, vous pouvez tout à fait utiliser expect en documentant dans le texte de l’argument la raison pour laquelle vous pensez qu’il n’y aura jamais de variante Err. Voici un exemple :
fn main() {
use std::net::IpAddr;
let home: IpAddr = "127.0.0.1"
.parse()
.expect("Hardcoded IP address should be valid");
}Nous créons une instance de IpAddr en interprétant une chaîne de caractères codée en dur dans le code. Nous savons que 127.0.0.1 est une adresse IP valide, donc il est acceptable d’utiliser expect ici. Toutefois, avoir une chaîne de caractères valide et codée en dur ne change pas le type de retour de la méthode parse : nous obtenons toujours une valeur de type Result et le compilateur va nous demander de gérer le Result comme si on pouvait obtenir la variante Err, car le compilateur n’est pas suffisamment intelligent pour comprendre que cette chaîne de caractères est toujours une adresse IP valide. Si la chaîne de l’adresse IP provient de l’utilisateur au lieu d’être codée en dur dans le programme et donc qu’il y a désormais une possibilité d’erreur, alors nous devrions gérer le Result d’une manière plus rigoureuse. En partant du principe que cette adresse IP est codée en dur, cela nous incitera à remplacer expect par un code permettant une meilleure gestion des erreurs si, à l’avenir, nous devons récupérer l’adresse IP à partir d’une autre source.
Recommandations pour gérer les erreurs
Il est recommandé de faire paniquer votre code dès qu’il risque d’aboutir à un état invalide. Dans ce contexte, un état invalide est lorsqu’un postulat, une garantie, un contrat ou un invariant a été rompu, comme des valeurs invalides, contradictoires ou manquantes qui sont fournies à votre code, ainsi qu’un ou plusieurs des éléments suivants :
- L’état invalide est quelque chose qui est inattendu, contrairement à quelque chose qui devrait arriver occasionnellement, comme par exemple un utilisateur qui saisit une donnée dans un mauvais format.
- Après cette instruction, votre code a besoin de ne pas être dans cet état invalide, plutôt que d’avoir à vérifier le problème à chaque étape.“
- Il n’y a pas de bonne façon d’encoder cette information dans les types que vous utilisez. Nous allons pratiquer ceci via un exemple dans la partie “Implémenter les états et les comportements avec des types” du chapitre 18.
Si une personne utilise votre bibliothèque et lui fournit des valeurs qui n’ont pas de sens, il vaut mieux si possible renvoyer une erreur de manière à ce que l’utilisateur de votre bibliothèque puisse décider ce qui doit être fait dans pareil cas. Toutefois, dans les cas où continuer l’exécution pourrait être dangereux ou néfaste, la meilleure des choses à faire est d’utiliser panic! et d’avertir cette personne du bogue dans son code afin qu’elle le règle pendant la phase de développement. De la même manière, panic! est parfois approprié si vous appelez du code externe sur lequel vous n’avez pas la main, et qu’il retourne un état invalide que vous ne pouvez pas corriger.
Cependant, si l’on s’attend à rencontrer des échecs, il est plus approprié de retourner un Result plutôt que de faire appel à panic!. Il peut s’agir par exemple d’un interpréteur qui reçoit des données erronées, ou une requête HTTP qui retourne un statut qui indique que vous avez atteint une limite de débit. Dans ces cas-là, vous devriez indiquer qu’il est possible que cela puisse échouer en retournant un Result afin que le code appelant puisse décider quoi faire pour gérer le problème.
Lorsque votre code effectue une opération qui peut mettre l’utilisateur en danger si elle est appelée avec des valeurs invalides, votre code devrait d’abord vérifier que ces valeurs sont valides, et faire un panic! si les valeurs ne sont pas correctes. C’est essentiellement pour des raisons de sécurité : tenter de travailler avec des données invalides peut exposer votre code à des vulnérabilités. C’est la principale raison pour laquelle la bibliothèque standard va appeler panic! si vous essayez d’accéder à la mémoire hors limite : essayer d’accéder à de la mémoire qui n’appartient pas à la structure de données actuelle est un problème de sécurité fréquent. Les fonctions ont souvent des contrats : leur comportement est garanti uniquement si les données d’entrée remplissent des conditions particulières. Paniquer lorsque le contrat est violé est justifié, car une violation de contrat signifie toujours un bogue du côté de l’appelant, et ce n’est pas le genre d’erreur que vous voulez que le code appelant gère explicitement. En fait, il n’y a aucun moyen rationnel pour que le code appelant se corrige : le développeur du code appelant doit corriger le code. Les contrats d’une fonction, en particulier lorsqu’une violation va causer un panic!, doivent être expliqués dans la documentation de l’API de ladite fonction.
Cependant, avoir beaucoup de vérifications d’erreurs dans toutes vos fonctions serait verbeux et pénible. Heureusement, vous pouvez utiliser le système de types de Rust (et donc la vérification de type que fait le compilateur) pour assurer une partie des vérifications à votre place. Si votre fonction a un paramètre d’un type précis, vous pouvez continuer à écrire votre code en sachant que le compilateur s’est déjà assuré que vous avez une valeur valide. Par exemple, si vous obtenez un type de valeur plutôt qu’une Option, votre programme s’attend à obtenir quelque chose plutôt que rien. Votre code n’a donc pas à gérer les deux cas de variantes Some et None : la seule possibilité est qu’il y a une valeur. Du code qui essaye de ne rien fournir à votre fonction ne compilera même pas, donc votre fonction n’a pas besoin de vérifier ce cas-là lors de l’exécution. Un autre exemple est d’utiliser un type d’entier non signé comme u32, qui garantit que le paramètre n’est jamais strictement négatif.
Types personnalisés pour la vérification
Allons plus loin dans l’idée d’utiliser le système de types de Rust pour s’assurer d’avoir une valeur valide en créant un type personnalisé pour la vérification. Souvenez-vous du jeu du plus ou du moins du chapitre 2 dans lequel notre code demandait à l’utilisateur de deviner un nombre entre 1 et 100. Nous n’avons jamais validé que le nombre saisi par l’utilisateur était entre ces nombres avant de le comparer à notre nombre secret ; nous avons seulement vérifié que le nombre était positif. Dans ce cas, les conséquences ne sont pas très graves : notre résultat “C’est plus !” ou “C’est moins !” sera toujours correct. Mais ce serait une amélioration utile pour aider un utilisateur à faire des suppositions valides et pour avoir un comportement différent selon qu’un utilisateur propose un nombre en dehors des limites ou qu’il saisit, par exemple, des lettres à la place.
Une façon de faire cela serait de stocker le nombre saisi dans un i32 plutôt que dans un u32 afin de permettre d’obtenir potentiellement des nombres négatifs, et ensuite vérifier que le nombre est dans la plage autorisée, comme ceci :
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
loop {
// -- partie masquée ici --
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: i32 = match supposition.trim().parse() {
Ok(nombre) => nombre,
Err(_) => continue,
};
if supposition < 1 || supposition > 100 {
println!("Le nombre secret est entre 1 et 100.");
continue;
}
match supposition.cmp(&nombre_secret) {
// -- partie masquée ici --
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => {
println!("Vous avez gagné !");
break;
}
}
}
}L’expression if vérifie si la valeur est en dehors des limites et informe l’utilisateur du problème le cas échéant, puis utilise continue pour passer à la prochaine itération de la boucle et ainsi demander de saisir une nouvelle supposition. Après l’expression if, nous pouvons continuer avec la comparaison entre supposition et le nombre secret tout en sachant que supposition est entre 1 et 100.
Cependant, ce n’est pas une solution idéale : s’il était absolument critique que le programme ne travaille qu’avec des valeurs entre 1 et 100 et qu’il y avait de nombreuses fonctions qui reposent sur cette condition, cela pourrait être fastidieux (et cela impacterait potentiellement la performance) de faire une vérification comme celle-ci dans chacune de ces fonctions.
À la place, nous pourrions construire un nouveau type dans un module dédié et intégrer les vérifications dans une fonction qui crée une instance de ce type, plutôt que de répéter partout les vérifications. Il est ainsi plus sûr pour les fonctions d’utiliser ce nouveau type dans leurs signatures et d’utiliser avec confiance les valeurs qu’elles reçoivent. L’encart 9-13 montre une façon de définir un type Supposition qui ne créera une instance de Supposition que si la fonction new reçoit une valeur entre 1 et 100 :
#![allow(unused)]
fn main() {
pub struct Supposition {
valeur: i32,
}
impl Supposition {
pub fn new(valeur: i32) -> Supposition {
if valeur < 1 || valeur > 100 {
panic!("La valeur doit être comprise entre 1 and 100, on a {valeur}.");
}
Supposition { valeur }
}
pub fn valeur(&self) -> i32 {
self.valeur
}
}
}Guess type that will only continue with values between 1 and 100Notez que ce code, dans src/guessing_game.rs, dépend de la déclaration d’un module mod jeu_du_plus_ou_du_moins; dans src/lib.rs que nous n’avons pas montré ici. Dans ce nouveau fichier de module, nous définissons une structure qui s’appelle Supposition qui a un champ valeur qui contient un i32. C’est dans ce dernier que le nombre sera stocké.
Ensuite, nous implémentons une fonction associée new sur Supposition qui crée des instances de Supposition. La fonction new est conçue pour recevoir un paramètre valeur de type i32 et retourner une Supposition. Le code dans le corps de la fonction new teste valeur pour s’assurer qu’elle est bien entre 1 et 100. Si valeur échoue à ce test, nous faisons appel à panic!, qui alertera le développeur qui écrit le code appelant qu’il a un bogue qu’il doit régler, car créer une Supposition avec valeur en dehors de cette plage va violer le contrat sur lequel s’appuie Supposition::new. Les conditions dans lesquelles Supposition::new va paniquer devraient être expliquées dans la documentation publique de l’API ; nous verrons les conventions pour indiquer l’éventualité d’un panic! dans la documentation de l’API que vous créerez au chapitre 14. Si valeur passe le test, nous créons une nouvelle Supposition avec son champ valeur qui prend la valeur du paramètre valeur et retourne cette Supposition.
Enfin, nous implémentons une méthode valeur qui emprunte self, n’a aucun autre paramètre, et retourne un i32. Ce genre de méthode est parfois appelé un accesseur, car son rôle est d’accéder aux données des champs et de les retourner. Cette méthode publique est nécessaire car le champ valeur de la structure Supposition est privé. Il est important que le champ valeur soit privé pour que le code qui utilise la structure Supposition ne puisse pas directement assigner une valeur à valeur : le code en dehors du module doit utiliser la fonction Supposition::new pour créer une instance de Supposition, ce qui permet d’empêcher la création d’une Supposition avec un champ valeur qui n’a pas été vérifié par les conditions dans la fonction Supposition:new.
Une fonction qui prend en paramètre ou qui retourne des nombres uniquement entre 1 et 100 peut ensuite déclarer dans sa signature qu’elle prend en paramètre ou qu’elle retourne une Supposition plutôt qu’un i32 et n’aura pas besoin de faire de vérifications supplémentaires dans son corps.
Résumé
Les fonctionnalités de gestion d’erreurs de Rust sont conçues pour vous aider à écrire du code plus résilient. La macro panic! signale que votre programme est dans un état qu’il ne peut pas gérer et vous permet de dire au processus de s’arrêter au lieu d’essayer de continuer avec des valeurs invalides ou incorrectes. L’énumération Result utilise le système de types de Rust pour signaler que des opérations peuvent échouer de telle façon que votre code puisse rattraper l’erreur. Vous pouvez utiliser Result pour dire au code qui appelle votre code qu’il a besoin de gérer le résultat et aussi les potentielles erreurs. Utiliser panic! et Result de manière appropriée rendra votre code plus fiable face à des problèmes inévitables.
Maintenant que vous avez vu la façon dont la bibliothèque standard tire parti de la généricité avec les énumérations Option et Result, nous allons voir comment la généricité fonctionne et comment vous pouvez l’utiliser dans votre code.
Les types génériques, les traits et les durées de vie
Tous les langages de programmation ont des outils pour gérer la duplication des concepts. En Rust, un de ces outils est la généricité : ce sont des représentations abstraites de types concrets ou d’autres propriétés. Nous pouvons exprimer le comportement des génériques, ou comment ils interagissent avec d’autres génériques, sans savoir ce qu’il y aura à leur place lors de la compilation et de l’exécution du code.
Les fonctions peuvent prendre des paramètres d’un type générique plutôt que d’un type concret comme i32 ou String, de la même manière qu’une fonction prend des paramètres avec des valeurs inconnues pour exécuter le même code sur plusieurs valeurs concrètes. En fait, nous avons déjà utilisé des types génériques au chapitre 6 avec Option<T>, au chapitre 8 avec Vec<T> et HashMap<K, V>, et au chapitre 9 avec Result<T, E>. Dans ce chapitre, nous allons voir comment définir nos propres types, fonctions et méthodes utilisant des types génériques !
Pour commencer, nous allons examiner comment construire une fonction pour réduire la duplication de code. Ensuite, nous utiliserons la même technique pour construire une fonction générique à partir de deux fonctions qui se distinguent uniquement par le type de leurs paramètres. Nous expliquerons aussi comment utiliser les types génériques dans les définitions de structures et d’énumérations.
Ensuite, vous apprendrez comment utiliser les traits pour définir un comportement de manière générique. Vous pouvez combiner les traits avec des types génériques pour contraindre un type générique à n’accepter que certains types qui ont un comportement particulier, et non pas accepter n’importe quel type.
Enfin, nous verrons les durées de vie, un genre de générique qui indique au compilateur comment les références s’articulent entre elles. Les durées de vie nous permettent de fournir au compilateur suffisamment d’informations au sujet des valeurs empruntées pour qu’il puisse garantir la validité des références dans plus de situations qu’il ne le pourrait sans notre aide.
Supprimer les doublons en construisant une fonction
Les génériques nous permettent de remplacer des types spécifiques par un substitut qui représente plusieurs types, afin d’éviter la duplication de code. Avant de plonger dans la syntaxe des génériques, nous allons regarder comment supprimer les doublons sans avoir recours aux types génériques en extrayant une fonction qui remplace des valeurs spécifiques par un emplacement réservé qui représente de multiples valeurs. Ensuite, nous allons appliquer cette technique pour construire une fonction générique ! En voyant comment reconnaître du code dupliqué que vous pouvez extraire dans une fonction, vous allez commencer à reconnaître du code dupliqué qui peut utiliser la généricité.
Nous allons commencer avec le petit programme de l’encart 10-1 qui trouve le nombre le plus grand dans une liste.
fn main() {
let liste_de_nombres = vec![34, 50, 25, 100, 65];
let mut le_plus_grand = &liste_de_nombres[0];
for nombre in &liste_de_nombres {
if nombre > le_plus_grand {
le_plus_grand = nombre;
}
}
println!("Le nombre le plus grand est {le_plus_grand}");
assert_eq!(*le_plus_grand, 100);
}Nous stockons une liste de nombres entiers dans la variable liste_de_nombres et plaçons une référence vers le premier nombre de la liste dans une variable appellée le_plus_grand. Ensuite, nous parcourons tous les nombres dans la liste, et si le nombre courant est plus grand que le nombre stocké dans le_plus_grand, nous remplaçons le nombre dans cette variable. Cependant, si le nombre courant est plus petit ou égal au nombre le plus grand trouvé précédemment, la variable ne change pas, et le code passe au nombre suivant de la liste. Après avoir parcouru tous les nombres de la liste, le_plus_grand devrait stocker le plus grand nombre, qui est 100 dans notre cas.
Il nous a maintenant été demandé de trouver le nombre le plus grand dans deux listes de nombres différentes. Pour ce faire, nous pourrions choisir de dupliquer le code de l’encart 10-1 et suivre la même logique à deux endroits différents du programme, comme dans l’encart 10-2.
fn main() {
let liste_de_nombres = vec![34, 50, 25, 100, 65];
let mut le_plus_grand = &liste_de_nombres[0];
for nombre in &liste_de_nombres {
if nombre > le_plus_grand {
le_plus_grand = nombre;
}
}
println!("Le nombre le plus grand est {le_plus_grand}");
let liste_de_nombres = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let mut le_plus_grand = &liste_de_nombres[0];
for nombre in &liste_de_nombres {
if nombre > le_plus_grand {
le_plus_grand = nombre;
}
}
println!("Le nombre le plus grand est {le_plus_grand}");
}Bien que ce code fonctionne, la duplication de code est fastidieuse et source d’erreurs. Nous devons aussi penser à mettre à jour le code à plusieurs endroits si nous souhaitons le modifier.
Pour éviter cette duplication, nous pouvons créer un niveau d’abstraction en définissant une fonction qui travaille avec n’importe quelle liste de nombres entiers qu’on lui passe comme un paramètre. Cette solution rend notre code plus clair et nous permet d’exprimer le concept de trouver le nombre le plus grand dans une liste de manière abstraite.
Dans l’encart 10-3, nous extrayons le code qui trouve le nombre le plus grand dans une fonction qui s’appelle le_plus_grand. Puis nous appellons cette fonction pour trouver le plus grand nombre dans les deux listes de l’encart 10-2. Nous pourrions aussi utiliser cette fonction sur n’importe quelle autre liste de valeurs i32 que nous pourrions rencontrer à l’avenir.
fn le_plus_grand(liste: &[i32]) -> &i32 {
let mut le_plus_grand = &liste[0];
for element in liste {
if element > le_plus_grand {
le_plus_grand = element;
}
}
le_plus_grand
}
fn main() {
let liste_de_nombres = vec![34, 50, 25, 100, 65];
let resultat = le_plus_grand(&liste_de_nombres);
println!("Le nombre le plus grand est {resultat}");
assert_eq!(*resultat, 100);
let liste_de_nombres = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let resultat = le_plus_grand(&liste_de_nombres);
println!("Le nombre le plus grand est {resultat}");
assert_eq!(*resultat, 6000);
}La fonction le_plus_grand a un paramètre qui s’appelle liste, qui représente n’importe quelle slice concrète de valeurs i32 que nous pouvons passer à la fonction. Au final, lorsque nous appelons la fonction, le code s’exécute sur les valeurs précises que nous lui avons fournies.
En résumé, voici les étapes que nous avons suivies pour changer le code de l’encart 10-2 pour obtenir celui de l’encart 10-3 :
- Identification du code dupliqué.
- Extraction du code dupliqué dans le corps de la fonction et ajout de précisions sur les entrées et les valeurs de retour de ce code dans la signature de la fonction.
- Remplacement des deux instances du code dupliqué par des appels à la fonction.
Ensuite, nous allons utiliser les mêmes étapes avec la généricité pour réduire la duplication de code. De la même manière que le corps d’une fonction peut opérer sur une liste abstraite plutôt que sur des valeurs spécifiques, la généricité permet de travailler sur des types abstraits.
Par exemple, imaginons que nous ayons deux fonctions : une qui trouve l’élément le plus grand dans une slice de valeurs i32 et une qui trouve l’élément le plus grand dans une slice de valeurs char. Comment pourrions-nous éviter la duplication ? Voyons cela dès maintenant !
Les types de données génériques
Les types de données génériques
Nous utilisons la généricité pour créer des définitions pour des éléments comme les signatures de fonctions ou les structures, que nous pouvons ensuite utiliser sur de nombreux types de données concrets. Commençons par regarder comment définir des fonctions, des structures, des énumérations et des méthodes en utilisant la généricité. Ensuite nous verrons comment la généricité impacte la performance du code.
Dans la définition d’une fonction
Lorsque nous définissons une fonction en utilisant la généricité, nous utilisons des types génériques dans la signature de la fonction là où nous précisons habituellement les types de données des paramètres et de la valeur de retour. Faire ainsi rend notre code plus flexible et apporte plus de fonctionnalités au code appelant notre fonction, tout en évitant la duplication de code.
Pour continuer avec notre fonction le_plus_grand, l’encart 10-4 nous montre deux fonctions qui trouvent toutes les deux la valeur la plus grande dans une slice. Nous allons les regrouper en une seule fonction qui utilise les génériques.
fn le_plus_grand_i32(liste: &[i32]) -> &i32 {
let mut le_plus_grand = &liste[0];
for element in liste {
if element > le_plus_grand {
le_plus_grand = element;
}
}
le_plus_grand
}
fn le_plus_grand_caractere(liste: &[char]) -> &char {
let mut le_plus_grand = &liste[0];
for element in liste {
if element > le_plus_grand {
le_plus_grand = element;
}
}
le_plus_grand
}
fn main() {
let liste_de_nombres = vec![34, 50, 25, 100, 65];
let resultat = le_plus_grand_i32(&liste_de_nombres);
println!("Le nombre le plus grand est {resultat}");
assert_eq!(*resultat, 100);
let liste_de_caracteres = vec!['y', 'm', 'a', 'q'];
let resultat = le_plus_grand_caractere(&liste_de_caracteres);
println!("Le plus grand caractère est {resultat}");
assert_eq!(*resultat, 'y');
}La fonction le_plus_grand_i32 est celle que nous avons construite à l’encart 10-3 lorsqu’elle trouvait le plus grand i32 dans une slice. La fonction le_plus_grand_caractere recherche le plus grand char dans une slice. Les corps des fonctions ont le même code, donc essayons d’éviter cette duplication en utilisant un paramètre de type générique dans une seule et unique fonction.
Pour paramétrer les types dans une nouvelle fonction unique, nous avons besoin de donner un nom au paramètre de type, comme nous l’avons fait pour les paramètres de valeur des fonctions. Vous pouvez utiliser n’importe quel identificateur pour nommer le paramètre de type. Mais ici nous allons utiliser T car, par convention, les noms de paramètres en Rust sont courts, souvent même une seule lettre, et la convention de nommage des types en Rust est d’utiliser le UpperCamelCase. Et puisque la version courte de type est T, c’est le choix par défaut de nombreux développeurs Rust.
Lorsqu’on utilise un paramètre dans le corps de la fonction, nous devons déclarer le nom du paramètre dans la signature afin que le compilateur puisse savoir à quoi réfère ce nom. De la même manière, lorsqu’on utilise un nom de paramètre de type dans la signature d’une fonction, nous devons déclarer le nom du paramètre de type avant de pouvoir l’utiliser. Pour déclarer la fonction générique le_plus_grand, il faut placer la déclaration du nom du type entre des chevrons <>, le tout entre le nom de la fonction et la liste des paramètres, comme ceci :
fn le_plus_grand<T>(liste: &[T]) -> &T {Cette définition se lit comme ceci : la fonction le_plus_grand est générique en fonction du type T. Cette fonction a un paramètre qui s’appelle liste, qui est une slice de valeurs de type T. Cette fonction le_plus_grand va retourner une référence à une valeur du même type T.
L’encart 10-5 nous montre la combinaison de la définition de la fonction le_plus_grand avec le type de données générique présent dans sa signature. L’encart montre aussi que nous pouvons appeler la fonction avec une slice soit de valeurs i32, soit de valeurs char. Notez que ce code ne se compile pas encore.
fn le_plus_grand<T>(liste: &[T]) -> &T {
let mut le_plus_grand = &liste[0];
for element in liste {
if element > le_plus_grand {
le_plus_grand = element;
}
}
le_plus_grand
}
fn main() {
let liste_de_nombres = vec![34, 50, 25, 100, 65];
let resultat = le_plus_grand(&liste_de_nombres);
println!("Le nombre le plus grand est {resultat}");
let liste_de_caracteres = vec!['y', 'm', 'a', 'q'];
let resultat = le_plus_grand(&liste_de_caracteres);
println!("Le plus grand caractère est {resultat}");
}largest function using generic type parameters; this doesn’t compile yetSi nous essayons de compiler ce code dès maintenant, nous aurons l’erreur suivante :
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if element > le_plus_grand {
| ------- ^ ------------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn le_plus_grand<T: std::cmp::PartialOrd>(liste: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Le texte d’aide cite std::cmp::PartialOrd, qui est un trait, et nous allons voir les traits dans la prochaine section. Pour le moment, retenez que cette erreur nous informe que le corps de le_plus_grand ne va pas fonctionner pour tous les types possibles que T peut représenter. Comme nous voulons comparer des valeurs de type T dans le corps, nous pouvons utiliser uniquement des types dont les valeurs peuvent être triées dans l’ordre. Pour effectuer des comparaisons, la bibliothèque standard propose le trait std::cmp::PartialOrd que vous pouvez implémenter sur des types (voir l’annexe C pour en savoir plus sur ce trait). Pour réparer l’encart 10-5, nous pouvons suivre la suggestion du texte d’aide et restreindre les types valides pour T aux seuls types qui implémentent PartialOrd. Ensuite, le code se compilera, car la bibliothèque standard implémente PartialOrd à la fois sur i32 et sur char.
Dans la définition des structures
Nous pouvons aussi définir des structures en utilisant des paramètres de type génériques dans un ou plusieurs champs en utilisant la syntaxe <>. L’encart 10-6 nous montre comment définir une structure Point<T> pour stocker des valeurs de coordonnées x et y de n’importe quel type.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let entiers = Point { x: 5, y: 10 };
let flottants = Point { x: 1.0, y: 4.0 };
}Point<T> struct that holds x and y values of type TLa syntaxe pour l’utilisation des génériques dans les définitions de structures est similaire à celle utilisée dans les définitions de fonctions. D’abord, nous déclarons le nom du paramètre de type entre des chevrons juste après le nom de la structure. Ensuite, nous utilisons le type générique dans la définition de la structure là où on indiquerait en temps normal des types de données concrets.
Notez que comme nous n’avons utilisé qu’un seul type générique pour définir Point<T>, cette définition dit que la structure Point<T> est générique en fonction d’un type T, et les champs x et y sont tous les deux de ce même type, quel qu’il soit. Si nous créons une instance de Point<T> qui a des valeurs de types différents, comme dans l’encart 10-7, notre code ne va pas se compiler.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let ne_fonctionnera_pas = Point { x: 5, y: 4.0 };
}x and y must be the same type because both have the same generic data type T.Dans cet exemple, lorsque nous assignons l’entier 5 à x, nous laissons entendre au compilateur que le type générique T sera un entier pour cette instance de Point<T>. Ensuite, lorsque nous assignons 4.0 à y, que nous avons défini comme ayant le même type que x, nous obtenons une erreur d’incompatibilité de type comme celle-ci :
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let ne_fonctionnera_pas = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Pour définir une structure Point où x et y sont tous les deux génériques mais peuvent avoir des types différents, nous pouvons utiliser plusieurs paramètres de types génériques différents. Par exemple, dans l’encart 10-8, nous changeons la définition de Point pour être générique en fonction des types T et U où x est de type T et y est de type U.
struct Point<T, U> {
x: T,
y: U,
}
fn main() {
let deux_entiers = Point { x: 5, y: 10 };
let deux_flottants = Point { x: 1.0, y: 4.0 };
let un_entier_et_un_flottant = Point { x: 5, y: 4.0 };
}Point<T, U> generic over two types so that x and y can be values of different typesMaintenant, toutes les instances de Point montrées ici sont valides ! Vous pouvez utiliser autant de paramètres de type génériques que vous souhaitez dans la déclaration de la définition, mais en utiliser plus de quelques-uns rend votre code difficile à lire. Si vous vous apercevez que vous avez besoin de nombreux types génériques dans votre code, cela peut être un signe que votre code a besoin d’être remanié en éléments plus petits.
Dans les définitions d’énumérations
Comme nous l’avons fait avec les structures, nous pouvons définir des énumérations qui utilisent des types de données génériques dans leurs variantes. Commençons par regarder à nouveau l’énumération Option<T> que fournit la bibliothèque standard, et que nous avons utilisée au chapitre 6 :
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}Cette définition devrait désormais avoir plus de sens pour vous. Comme vous pouvez le constater, Option<T> est une énumération qui est générique en fonction du type T et a deux variantes : Some, qui contient une valeur de type T, et une variante None qui ne contient aucune valeur. En utilisant l’énumération Option<T>, nous pouvons exprimer le concept abstrait d’avoir une valeur optionnelle, et comme Option<T> est générique, nous pouvons utiliser cette abstraction peu importe le type de la valeur optionnelle.
Les énumérations peuvent aussi utiliser plusieurs types génériques. La définition de l’énumération Result que nous avons utilisée au chapitre 9 en est un exemple :
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}L’énumération Result est générique en fonction de deux types, T et E, et a deux variantes : Ok, qui contient une valeur de type T, et Err, qui contient une valeur de type E. Cette définition rend possible l’utilisation de l’énumération Result partout où nous avons une opération qui peut réussir (et retourner une valeur du type T) ou échouer (et retourner une erreur du type E). En fait, c’est ce qui est utilisé pour ouvrir un fichier dans l’encart 9-3, où T contenait un type std::fs::File lorsque le fichier était ouvert avec succès et E contenait un type std::io::Error lorsqu’il y avait des problèmes pour ouvrir le fichier.
Lorsque vous reconnaîtrez des cas dans votre code où vous aurez plusieurs définitions de structures ou d’énumérations qui se distinguent uniquement par le type de valeurs qu’elles stockent, vous pourrez éviter les doublons en utilisant des types génériques à la place.
Dans les définitions des méthodes
Nous pouvons implémenter des méthodes sur des structures et des énumérations (comme nous l’avons fait dans le chapitre 5) et aussi utiliser des types génériques dans leurs définitions. L’encart 10-9 montre la structure Point<T> que nous avons définie dans l’encart 10-6 avec une méthode qui s’appelle x implémentée sur cette dernière.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}x on the Point<T> struct that will return a reference to the x field of type TIci, nous avons défini une méthode qui s’appelle x sur Point<T> qui retourne une référence à la donnée présente dans le champ x.
Notez que nous devons déclarer T juste après impl afin de pouvoir utiliser T pour préciser que nous implémentons des méthodes sur le type Point<T>. En déclarant T comme un type générique après impl, Rust peut comprendre que le type entre les chevrons dans Point est un type générique plutôt qu’un type concret. Nous aurions pu choisir un nom différent pour ce paramètre générique plutôt que de réutiliser le même nom que dans la définition de la structure, mais c’est devenu une convention d’utiliser le même nom. Si vous écrivez une méthode dans un impl qui déclare un type générique, cette méthode sera définie sur n’importe quelle instance du type, peu importe quel type concret sera substitué dans le type générique.
Nous pouvons aussi ajouter des contraintes sur des types génériques au moment de définir les méthodes du type. Nous pouvons par exemple implémenter des méthodes uniquement sur des instances de Point<f32> plutôt que sur des instances de n’importe quel type Point<T>. Dans l’encart 10-10, nous utilisons le type concret f32, ce qui veut dire que nous n’avons pas besoin de déclarer un type après impl.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
fn distance_depuis_lorigine(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}impl block that only applies to a struct with a particular concrete type for the generic type parameter TCe code signifie que le type Point<f32> va avoir une méthode distance_depuis_lorigine ; les autres instances de Point<T> où T n’est pas du type f32 ne pourront pas appeler cette méthode. Cette méthode calcule la distance entre notre point et la coordonnée (0.0, 0.0) et utilise des opérations mathématiques qui ne sont disponibles que pour les types de flottants.
Les paramètres de type génériques dans la définition d’une structure ne sont pas toujours les mêmes que ceux qui sont utilisés dans la signature des méthodes de cette même structure. Par exemple, l’encart 10-11 utilise les types génériques X1 et Y1 pour la structure Point, ainsi que X2 et Y2 pour la signature de la méthode melange pour rendre l’exemple plus clair. La méthode crée une nouvelle instance de Point avec la valeur de x provenant du Point self (de type X1) et la valeur de y provenant du Point en paramètre (de type Y2).
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn melange<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c' };
let p3 = p1.melange(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}Dans le main, nous avons défini un Point qui a un i32 pour x (avec la valeur 5) et un f64 pour y (avec la valeur 10.4). La variable p2 est une structure Point qui a une slice de chaîne de caractères pour x (avec la valeur "Hello") et un caractère char pour y (avec la valeur c). L’appel à melange sur p1 avec l’argument p2 nous donne p3, qui aura un i32 pour x, car x provient de p1. La variable p3 aura un caractère char pour y, car y provient de p2. L’appel à la macro println! va afficher p3.x = 5, p3.y = c.
Le but de cet exemple est de montrer une situation dans laquelle des paramètres génériques sont déclarés avec impl et d’autres sont déclarés dans la définition de la méthode. Ici, les paramètres génériques X1 et Y1 sont déclarés après impl, car ils sont liés à la définition de la structure. Les paramètres génériques X2 et Y2 sont déclarés après fn melange, car ils ne sont liés qu’à cette méthode.
Performance du code utilisant les génériques
Vous vous demandez peut-être s’il y a un coût à l’exécution lorsque vous utilisez des paramètres de type génériques. La bonne nouvelle est que l’utilisation de types génériques ne rendra pas votre programme plus lent que s’il utilisait les types concrets.
Rust accomplit cela en pratiquant la monomorphisation à la compilation du code qui utilise les génériques. La monomorphisation est le processus qui transforme du code générique en code spécifique en définissant au moment de la compilation les types concrets utilisés dans le code. Dans ce processus, le compilateur fait l’inverse des étapes que nous avons suivies pour créer la fonction générique de l’encart 10-5 : le compilateur cherche tous les endroits où le code générique est utilisé et génère du code pour les types concrets avec lesquels le code générique est appelé.
Regardons comment cela fonctionne en utilisant l’énumération générique Option<T> de la bibliothèque standard :
#![allow(unused)]
fn main() {
let entier = Some(5);
let flottant = Some(5.0);
}Lorsque Rust compile ce code, il applique la monomorphisation. Pendant ce processus, le compilateur lit les valeurs qui ont été utilisées dans les instances de Option<T> et en déduit les deux sortes de Option<T> : l’une est i32 et l’autre est f64. Ainsi, il décompose la définition générique de Option<T> en deux définitions spécialisées pour Option_i32 et Option_f64, remplaçant ainsi la définition générique par deux définitions concrètes.
La version monomorphe du code ressemble à ce qui suit. Le Option<T> générique est remplacé par deux définitions concrètes créées par le compilateur :
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let entier = Option_i32::Some(5);
let flottant = Option_f64::Some(5.0);
}Comme Rust compile le code générique dans du code qui précise le type dans chaque instance, l’utilisation des génériques n’a pas de conséquence sur les performances de l’exécution. Quand le code s’exécute, il fonctionne comme il devrait le faire si nous avions dupliqué chaque définition à la main. Le processus de monomorphisation rend les génériques de Rust très performants au moment de l’exécution.
Définir des comportements partagés avec les traits
Définir des comportements partagés avec les traits
Un trait définit une fonctionnalité qu’a un type particulier et qu’il peut partager avec d’autres types. Nous pouvons utiliser les traits pour définir un comportement partagé de manière abstraite. Nous pouvons lier ces traits à un type générique pour exprimer le fait qu’il puisse être de n’importe quel type à condition qu’il ait un comportement donné.
Remarque : les traits sont similaires à ce qu’on appelle parfois les interfaces dans d’autres langages, malgré quelques différences.
Définir un trait
Le comportement d’un type s’exprime via les méthodes que nous pouvons appeler sur ce type. Différents types peuvent partager le même comportement si nous pouvons appeler les mêmes méthodes sur tous ces types. Définir un trait est une manière de regrouper des signatures de méthodes pour définir un comportement nécessaire pour accomplir un objectif.
Par exemple, imaginons que nous avons plusieurs structures qui stockent différents types et quantités de texte : une structure ArticleDePresse, qui contient un reportage dans un endroit donné et un Tweet qui peut avoir jusqu’à 280 caractères maximum et des métadonnées qui indiquent s’il s’agit d’une nouvelle publication, d’une republication, ou une réponse à une publication.
Nous voulons construire une crate de bibliothèque agregateur pour des agrégateurs de médias qui peut afficher le résumé des données stockées dans une instance de ArticleDePresse ou de Tweet. Pour cela, il nous faut un résumé pour chaque type, et nous allons demander ce résumé en appelant la méthode resumer sur une instance. L’encart 10-12 nous montre la définition d’un trait public Resumable qui décrit ce comportement.
pub trait Resumable {
fn resumer(&self) -> String;
}Summary trait that consists of the behavior provided by a summarize methodIci, nous déclarons un trait en utilisant le mot-clé trait et ensuite le nom du trait, qui est Resumable dans notre cas. Nous déclarons aussi le trait comme pub afin que les crates qui dépendent de cette crate puissent aussi utiliser ce trait, comme nous allons le voir dans quelques exemples. Entre les accolades, nous déclarons la signature de la méthode qui décrit le comportement des types qui implémentent ce trait, qui est dans notre cas fn resumer(&self) -> String.
À la fin de la signature de la méthode, au lieu de renseigner une implémentation entre des accolades, nous utilisons un point-virgule. Chaque type qui implémente ce trait doit renseigner son propre comportement dans le corps de la méthode. Le compilateur va s’assurer que tous les types qui ont le trait Resumable auront la méthode resumer définie avec cette signature précise.
Un trait peut avoir plusieurs méthodes dans son corps : les signatures des méthodes sont ajoutées ligne par ligne et chaque ligne se termine avec un point-virgule.
Implémenter un trait sur un type
Maintenant que nous avons défini les signatures souhaitées des méthodes du trait Resumable, nous pouvons maintenant l’implémenter sur les types de notre agrégateur de médias. L’encart 10-13 montre une implémentation du trait Resumable sur la structure ArticleDePresse qui utilise le titre, le nom de l’auteur et le lieu pour créer la valeur de retour de resumer. Pour la structure Tweet, nous définissons resumer avec le nom d’utilisateur suivi par le texte entier de la publication, en supposant que le contenu de la publication est déjà limité à 280 caractères.
pub trait Resumable {
fn resumer(&self) -> String;
}
pub struct ArticleDePresse {
pub titre: String,
pub lieu: String,
pub auteur: String,
pub contenu: String,
}
impl Resumable for ArticleDePresse {
fn resumer(&self) -> String {
format!("{}, par {} ({})", self.titre, self.auteur, self.lieu)
}
}
pub struct Tweet {
pub nom_utilisateur: String,
pub contenu: String,
pub reponse: bool,
pub republication: bool,
}
impl Resumable for Tweet {
fn resumer(&self) -> String {
format!("{} : {}", self.nom_utilisateur, self.contenu)
}
}Summary trait on the NewsArticle and SocialPost typesL’implémentation d’un trait sur un type est similaire à l’implémentation d’une méthode classique. La différence est que nous ajoutons le nom du trait que nous voulons implémenter après le impl, et que nous utilisons ensuite le mot-clé for suivi du nom du type sur lequel nous souhaitons implémenter le trait. À l’intérieur du bloc impl, nous ajoutons les signatures des méthodes présentes dans la définition du trait. Au lieu d’ajouter un point-virgule après chaque signature, nous plaçons les accolades et nous remplissons le corps de la méthode avec le comportement spécifique que nous voulons que les méthodes du trait suivent pour le type en question.
Maintenant que la bibliothèque a implémenté le trait Resumable sur ArticleDePresse et Tweet, les utilisateurs de cette crate peuvent appeler les méthodes de l’instance de ArticleDePresse et Tweet comme si elles étaient des méthodes classiques. La seule différence est que l’utilisateur doit introduire le trait dans la portée, tout comme les types, pour obtenir les méthodes de trait additionnelles. Voici un exemple de comment la crate binaire pourra utiliser notre crate de bibliothèque agregateur :
use agregateur::{Tweet, Resumable};
fn main() {
let publication = Tweet {
nom_utilisateur: String::from("jean"),
contenu: String::from(
"Bien sûr, les amis, comme vous le savez probablement déjà",
),
reponse: false,
republication: false,
};
println!("1 nouveau tweet : {}", publication.resumer());
}Ce code affichera 1 nouveau tweet : jean : Bien sûr, les amis, comme vous le savez probablement déjà.
Les autres crates qui dépendent de la crate agregateur peuvent aussi importer dans la portée le trait Resumable afin d’implémenter Resumable sur leurs propres types. Il y a une limitation à souligner, c’est que nous ne pouvons implémenter un trait sur un type que si le trait, le type, ou les deux, sont définis localement dans notre crate. Par exemple, nous pouvons implémenter des traits de la bibliothèque standard comme Display sur un type personnalisé comme Tweet comme une fonctionnalité de notre crate agregateur, car le type Tweet est défini localement dans notre crate agregateur. Nous pouvons aussi implémenter Resumable sur Vec<T> dans notre crate agregateur, car le trait Resumable est défini localement dans notre crate agregateur.
Mais nous ne pouvons pas implémenter des traits externes sur des types externes. Par exemple, nous ne pouvons pas implémenter le trait Display sur Vec<T> à l’intérieur de notre crate agregateur, car Display et Vec<T> sont tous deux définis dans la bibliothèque standard et ne sont donc pas définis localement dans notre crate agregateur. Cette limitation fait partie d’une propriété appelée la cohérence, et plus précisément la règle de l’orphelin, qui s’appelle ainsi car le type parent n’est pas présent. Cette règle s’assure que le code des autres personnes ne casse pas votre code et réciproquement. Sans cette règle, deux crates pourraient implémenter le même trait sur le même type, et Rust ne saurait pas quelle implémentation utiliser.
Implémentations par défaut
Il est parfois utile d’avoir un comportement par défaut pour toutes ou une partie des méthodes d’un trait plutôt que de demander l’implémentation de toutes les méthodes sur chaque type. Ainsi, si nous implémentons le trait sur un type particulier, nous pouvons garder ou réécrire le comportement par défaut de chaque méthode.
Dans l’encart 10-14, nous indiquons une chaîne de caractères par défaut pour la méthode resumer du trait Resumable plutôt que de définir uniquement la signature de la méthode, comme nous l’avons fait dans l’encart 10-12.
pub trait Resumable {
fn resumer(&self) -> String {
String::from("(En savoir plus...)")
}
}
pub struct ArticleDePresse {
pub titre: String,
pub lieu: String,
pub auteur: String,
pub contenu: String,
}
impl Resumable for ArticleDePresse {}
pub struct Tweet {
pub nom_utilisateur: String,
pub contenu: String,
pub reponse: bool,
pub republication: bool,
}
impl Resumable for Tweet {
fn resumer(&self) -> String {
format!("{} : {}", self.nom_utilisateur, self.contenu)
}
}Summary trait with a default implementation of the summarize methodPour utiliser l’implémentation par défaut pour résumer des instances de ArticleDePresse, nous mettons un bloc impl vide avec impl Resumable for ArticleDePresse {}.
Même si nous ne définissons plus directement la méthode resumer sur ArticleDePresse, nous avons fourni une implémentation par défaut et précisé que ArticleDePresse implémente le trait Resumable. Par conséquent, nous pouvons toujours appeler la méthode resumer sur une instance de ArticleDePresse, comme ceci :
use agregateur::{self, ArticleDePresse, Resumable};
fn main() {
let article = ArticleDePresse {
titre: String::from("Les Penguins ont remporté la Coupe Stanley !"),
lieu: String::from("Pittsburgh, PA, USA"),
auteur: String::from("Iceburgh"),
contenu: String::from(
"Les Penguins de Pittsburgh sont une nouvelle fois la meilleure \
équipe de hockey de la LNH.",
),
};
println!("Nouvel article disponible ! {}", article.resumer());
}Ce code va afficher Nouvel article disponible ! (En savoir plus...).
La création d’une implémentation par défaut pour resumer n’a pas besoin que nous modifiions quelque chose dans l’implémentation de Resumable sur Tweet dans l’encart 10-13. C’est parce que la syntaxe pour réécrire l’implémentation par défaut est la même que la syntaxe pour implémenter une méthode qui n’a pas d’implémentation par défaut.
Les implémentations par défaut peuvent appeler d’autres méthodes du même trait, même si ces autres méthodes n’ont pas d’implémentation par défaut. Ainsi, un trait peut fournir de nombreuses fonctionnalités utiles et n’exiger du développeur qui l’utilise que d’en implémenter une petite partie. Par exemple, nous pouvons définir le trait Resumable comme ayant une méthode resumer_auteur dont l’implémentation est nécessaire, et ensuite définir une méthode resumer qui a une implémentation par défaut qui appelle la méthode resumer_auteur :
pub trait Resumable {
fn resumer_auteur(&self) -> String;
fn resumer(&self) -> String {
format!("(Lire plus d'éléments de {} ...)", self.resumer_auteur())
}
}
pub struct Tweet {
pub nom_utilisateur: String,
pub contenu: String,
pub reponse: bool,
pub republication: bool,
}
impl Resumable for Tweet {
fn resumer_auteur(&self) -> String {
format!("@{}", self.nom_utilisateur)
}
}Pour pouvoir utiliser cette version de Resumable, nous avons seulement besoin de définir resumer_auteur lorsqu’on implémente le trait sur le type :
pub trait Resumable {
fn resumer_auteur(&self) -> String;
fn resumer(&self) -> String {
format!("(Lire plus d'éléments de {} ...)", self.resumer_auteur())
}
}
pub struct Tweet {
pub nom_utilisateur: String,
pub contenu: String,
pub reponse: bool,
pub republication: bool,
}
impl Resumable for Tweet {
fn resumer_auteur(&self) -> String {
format!("@{}", self.nom_utilisateur)
}
}Après avoir défini resumer_auteur, nous pouvons appeler resumer sur des instances de la structure Tweet, et l’implémentation par défaut de resumer va appeler resumer_auteur, que nous avons défini. Comme nous avons implémenté resumer_auteur, le trait Resumable nous a donné le comportement de la méthode resumer sans nous obliger à écrire une ligne de code supplémentaire. Voici à quoi cela ressemble :
use agregateur::{self, Tweet, Resumable};
fn main() {
let publication = Tweet {
nom_utilisateur: String::from("jean"),
contenu: String::from(
"Bien sûr, les amis, comme vous le savez probablement déjà",
),
reponse: false,
republication: false,
};
println!("1 nouveau tweet : {}", publication.resumer());
}Ce code affichera 1 nouveau tweet : (Lire plus d'éléments de @jean ...).
Notez qu’il n’est pas possible d’appeler l’implémentation par défaut à partir d’une réécriture de cette même méthode.
Utilisation des traits comme paramètres
Maintenant que vous savez comment définir et implémenter les traits, nous pouvons regarder comment utiliser les traits pour définir des fonctions qui acceptent plusieurs types différents. Nous utiliserons le trait Resumable que nous avons implémenté sur les types ArticleDePresse et Tweet dans l’encart 10-13, pour définir une fonction notifier qui va appeler la méthode resumer sur son paramètre element, qui est d’un type qui implémente le trait Resumable. Pour ce faire, nous pouvons utiliser la syntaxe impl Trait, comme ceci :
pub trait Resumable {
fn resumer(&self) -> String;
}
pub struct ArticleDePresse {
pub titre: String,
pub lieu: String,
pub auteur: String,
pub contenu: String,
}
impl Resumable for ArticleDePresse {
fn resumer(&self) -> String {
format!("{}, par {} ({})", self.titre, self.auteur, self.lieu)
}
}
pub struct Tweet {
pub nom_utilisateur: String,
pub contenu: String,
pub reponse: bool,
pub republication: bool,
}
impl Resumable for Tweet {
fn resumer(&self) -> String {
format!("{} : {}", self.nom_utilisateur, self.contenu)
}
}
pub fn notifier(element: &impl Resumable) {
println!("Flash info ! {}", element.resumer());
}Au lieu d’un type concret pour le paramètre element, nous précisons le mot-clé impl et le nom du trait. Ce paramètre accepte n’importe quel type qui implémente le trait spécifié. Dans le corps de notifier, nous pouvons appeler toutes les méthodes sur element qui proviennent du trait Resumable, comme resumer. Nous pouvons appeler notifier et passer une instance de ArticleDePresse ou de Tweet. Le code qui appellera la fonction avec un autre type, comme une String ou un i32, ne va pas se compiler car ces types n’implémentent pas Resumable.
La syntaxe du trait lié
La syntaxe impl Trait fonctionne bien pour des cas simples, mais est en réalité du sucre syntaxique pour une forme plus longue connue sous le nom de trait lié, qui ressemble à ceci :
pub fn notifier<T: Resumable>(element: &T) {
println!("Flash info ! {}", element.resumer());
}Cette forme plus longue est équivalente à l’exemple dans la section précédente, mais est plus verbeuse. Nous plaçons les traits liés dans la déclaration des paramètres de type génériques après un deux-point entre des chevrons.
La syntaxe impl Trait est pratique pour rendre du code plus concis dans des cas simples, alors que la syntaxe du trait lié exprime plus de complexité dans d’autres cas. Par exemple, nous pouvons avoir deux paramètres qui implémentent Resumable. En utilisant la syntaxe impl Trait, nous aurons ceci :
pub fn notifier(element1: &impl Resumable, element2: &impl Resumable) {L’utilisation de impl Trait est pertinente si nous voulons que cette fonction permette à element1 et element2 d’avoir des types différents (tant que chacun de ces types implémente Resumable). Toutefois, si nous souhaitons forcer les deux paramètres à avoir le même type, nous devons utiliser un trait lié, comme ceci :
pub fn notifier<T: Resumable>(element1: &T, element2: &T) {Le type générique T renseigné comme type des paramètres element1 et element2 contraint la fonction de manière à ce que les types concrets des valeurs passées en arguments pour element1 et element2 soient identiques.
Plusieurs traits liés avec la syntaxe +
Nous pouvons aussi préciser que nous attendons plus d’un trait lié. Imaginons que nous souhaitons que notifier utilise le formatage d’affichage ainsi que la méthode resumersur element : nous indiquons dans la définition de notifier que element doit implémenter à la fois Display et Resumable. Nous pouvons faire ceci avec la syntaxe + :
pub fn notifier(element: &(impl Resumable + Display)) {La syntaxe + fonctionne aussi avec les traits liés sur des types génériques :
pub fn notifier<T: Resumable + Display>(element: &T) {Avec les deux traits liés renseignés, le corps de notifier va appeler resumer et utiliser {} pour formater element.
Des traits liés plus clairs avec la clause where
L’utilisation de trop nombreux traits liés a aussi ses désavantages. Chaque type générique a ses propres traits liés, donc les fonctions avec plusieurs paramètres de type génériques peuvent aussi avoir de nombreuses informations de traits liés entre le nom de la fonction et la liste de ses paramètres, ce qui rend la signature de la fonction difficile à lire. Pour cette raison, Rust a une syntaxe alternative pour renseigner les traits liés, dans une clause where après la signature de la fonction. Donc, au lieu d’écrire ceci …
fn une_fonction<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {… nous pouvons utiliser la clause where, comme ceci :
fn une_fonction<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}La signature de cette fonction est moins encombrée : le nom de la fonction, la liste des paramètres et le type de retour sont plus proches les uns des autres, comme une fonction sans traits liés.
Retourner des types qui implémentent des traits
Nous pouvons aussi utiliser la syntaxe impl Trait à la place du type de retour afin de retourner une valeur d’un type qui implémente un trait, comme ci-dessous :
pub trait Resumable {
fn resumer(&self) -> String;
}
pub struct ArticleDePresse {
pub titre: String,
pub lieu: String,
pub auteur: String,
pub contenu: String,
}
impl Resumable for ArticleDePresse {
fn resumer(&self) -> String {
format!("{}, par {} ({})", self.titre, self.auteur, self.lieu)
}
}
pub struct Tweet {
pub nom_utilisateur: String,
pub contenu: String,
pub reponse: bool,
pub republication: bool,
}
impl Resumable for Tweet {
fn resumer(&self) -> String {
format!("{} : {}", self.nom_utilisateur, self.contenu)
}
}
fn retourne_resumable() -> impl Resumable {
Tweet {
nom_utilisateur: String::from("jean"),
contenu: String::from(
"Bien sûr, les amis, comme vous le savez probablement déjà",
),
reponse: false,
republication: false,
}
}En utilisant impl Resumable pour le type de retour, nous indiquons que la fonction retourne_resumable retourne un type qui implémente le trait Resumable sans avoir à écrire le nom du type concret. Dans notre cas, retourne_resumable retourne un Tweet, mais le code qui appellera cette fonction n’a pas besoin de le savoir.
La capacité de spécifier un type de retour uniquement par le trait qu’il implémente est tout particulièrement utile dans le cas des fermetures et des itérateurs, que nous verrons au chapitre 13. Les fermetures et les itérateurs créent des types que seul le compilateur est en mesure de comprendre ou alors des types qui sont très longs à définir. La syntaxe impl Trait vous permet de renseigner de manière concise qu’une fonction retourne un type particulier qui implémente le trait Iterator sans avoir à écrire un très long type.
Cependant, vous pouvez seulement utiliser impl Trait si vous retournez un seul type possible. Par exemple, ce code va retourner soit un ArticleDePresse, soit un Tweet, alors que le type de retour avec impl Resumable ne va pas fonctionner :
pub trait Resumable {
fn resumer(&self) -> String;
}
pub struct ArticleDePresse {
pub titre: String,
pub lieu: String,
pub auteur: String,
pub contenu: String,
}
impl Resumable for ArticleDePresse {
fn resumer(&self) -> String {
format!("{}, par {} ({})", self.titre, self.auteur, self.lieu)
}
}
pub struct Tweet {
pub nom_utilisateur: String,
pub contenu: String,
pub reponse: bool,
pub republication: bool,
}
impl Resumable for Tweet {
fn resumer(&self) -> String {
format!("{} : {}", self.nom_utilisateur, self.contenu)
}
}
fn retourne_resumable(estArticle: bool) -> impl Resumable {
if estArticle {
ArticleDePresse {
titre: String::from(
"Les Penguins ont remporté la Coupe Stanley !"
),
lieu: String::from("Pittsburgh, PA, USA"),
auteur: String::from("Iceburgh"),
contenu: String::from(
"Les Penguins de Pittsburgh sont une nouvelle fois la \
meilleure équipe de hockey de la LNH."
),
}
} else {
Tweet {
nom_utilisateur: String::from("jean"),
contenu: String::from(
"Bien sûr, les amis, comme vous le savez probablement déjà",
),
reponse: false,
republication: false,
}
}
}Retourner soit un ArticleDePresse, soit un Tweet n’est pas autorisé à cause des restrictions sur la façon dont la syntaxe impl Trait est implémentée dans le compilateur. Nous verrons comment écrire une fonction avec ce comportement dans la section “Utiliser les objets traits qui permettent des valeurs de types différents” du chapitre 18.
Utiliser les traits liés pour conditionner l’implémentation des méthodes
En utilisant un trait lié avec un bloc impl qui utilise les paramètres de type génériques, nous pouvons implémenter des méthodes en fonction des types qui implémentent des traits particuliers. Par exemple, le type Paire<T> de l’encart 10-15 implémente toujours la fonction new pour retourner une nouvelle instance de Paire<T> (pour rappel dans la section ”Définir des méthodes” du chapitre 5 que Self est un alias de type pour le type du bloc impl, qui est dans ce cas le Paire<T>). Mais dans le bloc impl suivant, Paire<T> implémente la méthode afficher_comparaison uniquement si son type interne T implémente le trait PartialOrd qui active la comparaison et le trait Display qui permet l’affichage.
use std::fmt::Display;
struct Paire<T> {
x: T,
y: T,
}
impl<T> Paire<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Paire<T> {
fn afficher_comparaison(&self) {
if self.x >= self.y {
println!("Le plus grand élément est x = {}", self.x);
} else {
println!("Le plus grand élément est y = {}", self.y);
}
}
}Nous pouvons également implémenter un trait sur tout type qui implémente un autre trait en particulier. L’implémentation d’un trait sur n’importe quel type qui a un trait lié est appelée implémentation générale et est largement utilisée dans la bibliothèque standard Rust. Par exemple, la bibliothèque standard implémente le trait ToString sur tous les types qui implémentent le trait Display. Le bloc impl de la bibliothèque standard ressemble au code suivant :
impl<T: Display> ToString for T {
// -- partie masquée ici --
}Comme la bibliothèque standard a cette implémentation générale, nous pouvons appeler la méthode to_string définie par le trait ToString sur n’importe quel type qui implémente le trait Display. Par exemple, nous pouvons transformer les nombres entiers en leur équivalent dans une String comme ci-dessous car les entiers implémentent Display :
#![allow(unused)]
fn main() {
let s = 3.to_string();
}Les implémentations générales sont décrites dans la documentation du trait, dans la section “Implementors”.
Les traits et les traits liés nous permettent d’écrire du code qui utilise des paramètres de type génériques pour réduire la duplication de code, mais aussi pour indiquer au compilateur que nous voulons que le type générique ait un comportement particulier. Le compilateur peut ensuite utiliser les informations liées aux traits pour vérifier que tous les types concrets utilisés dans notre code suivent le comportement souhaité. Dans les langages typés dynamiquement, nous aurions une erreur à l’exécution si nous appelions une méthode sur un type qui n’implémenterait pas la méthode. Mais Rust décale l’apparition de ces erreurs au moment de la compilation afin de nous forcer à résoudre les problèmes avant même que notre code soit capable de s’exécuter. De plus, nous n’avons pas besoin d’écrire un code qui vérifie le comportement lors de l’exécution car nous l’avons déjà vérifié au moment de la compilation. Cela permet d’améliorer les performances sans avoir à sacrifier la flexibilité des types génériques.
La conformité des références avec les durées de vies
La conformité des références avec les durées de vies
Une autre sorte de générique que nous avons déjà utilisée est la durée de vie. Plutôt que de s’assurer qu’un type a le comportement que nous voulons, la durée de vie s’assure que les références sont en vigueur aussi longtemps que nous avons besoin qu’elles le soient.
Il reste un détail que nous n’avons pas abordé dans la section “Les références et l’emprunt” du chapitre 4, c’est que toutes les références ont une durée de vie dans Rust, qui est la portée pour laquelle chaque référence est en vigueur. La plupart du temps, les durées de vies sont implicites et sont déduites automatiquement, comme pour la plupart du temps les types sont déduits. Nous avons seulement besoin de renseigner le type lorsque plusieurs types sont possibles. De la même manière, nous devons renseigner les durées de vie lorsque les durées de vies des références peuvent être déduites de différentes manières. Rust nécessite que nous renseignons ces relations en utilisant des paramètres de durée de vie génériques pour s’assurer que les références utilisées au moment de la compilation restent bien en vigueur.
L’annotation de la durée de vie n’est pas un concept présent dans la plupart des langages de programmation, donc cela n’est pas très familier. Bien que nous ne puissions couvrir l’intégralité de la durée de vie dans ce chapitre, nous allons voir les cas les plus courants où vous allez rencontrer la syntaxe de la durée de vie, afin que vous puissiez vous familiariser avec ces concepts.
Les références pendouillantes
L’objectif principal des durées de vies est d’éviter les références pendouillantes qui, si elles étaient autorisées, feraient en sorte qu’un programme pointe des données autres que celles sur lesquelles il était censé pointer. Soit le programme de l’encart 10-16, qui a une portée externe et une portée interne.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Remarque : Les exemples dans les encarts 10-17, 10-18 et 10-24 déclarent des variables sans initialiser leur valeur, donc les noms de ces variables existent dans la portée externe. À première vue, cela semble être en conflit avec le fonctionnement de Rust qui n’utilise pas les valeurs nulles. Cependant, si nous essayons d’utiliser une variable avant de lui donner une valeur, nous aurons une erreur au moment de la compilation, qui confirme que Rust n’autorise pas les valeurs nulles.
La portée externe déclare une variable r sans valeur initiale, et la portée interne déclare une variable x avec la valeur initiale à 5. Au sein de la portée interne, nous essayons d’assigner la valeur de r comme étant une référence à x. Puis la portée interne se ferme, et nous essayons d’afficher la valeur dans r. Ce code ne va pas se compiler car la valeur r se réfère à quelque chose qui est sorti de la portée avant que nous essayons de l’utiliser. Voici le message d’erreur :
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Le message d’erreur dit que la variable x n’existe plus (“does not live long enough”). La raison à cela est que x est sortie de la portée lorsque la portée interne s’est fermée à la ligne 7. Mais r reste en vigueur dans la portée externe ; car sa portée est plus grande, on dit qu’il “vit plus longtemps”. Si Rust avait permis à ce code de s’exécuter, r pointerait sur de la mémoire désallouée dès que x est sortie de la portée, ainsi tout ce que nous pourrions faire avec r ne fonctionnerait pas correctement. Mais comment Rust détecte que ce code est invalide ? Il utilise le vérificateur d’emprunt.
Le vérificateur d’emprunt
Le compilateur de Rust embarque un vérificateur d’emprunt (borrow checker) qui compare les portées pour déterminer si les emprunts sont valides. L’encart 10-17 montre le même code que l’encart 10-16, mais avec des commentaires qui montrent les durées de vies des variables.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+r and x, named 'a and 'b, respectivelyIci, nous avons montré la durée de vie de r avec 'a et la durée de vie de x avec 'b. Comme vous pouvez le constater, le bloc interne 'b est bien plus petit que le bloc externe 'a. Au moment de la compilation, Rust compare les tailles des deux durées de vies et constate que r a la durée de vie 'a mais fait référence à de la mémoire qui a une durée de vie de 'b. Ce programme est refusé car 'b est plus court que 'a : l’élément pointé par la référence n’existe pas aussi longtemps que la référence.
L’encart 10-18 résout le code afin qu’il n’ait plus de référence pendouillante et qu’il se compile sans erreur.
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {r}"); // | |
// --+ |
} // ----------+Ici, x a la durée de vie 'b, qui est plus grande dans ce cas que 'a. Cela signifie que r peut référencer x car Rust sait que la référence présente dans r sera toujours valide tant que x est valide.
Maintenant que vous savez où se situent les durées de vie des références et comment Rust analyse les durées de vies pour s’assurer que les références soient toujours en vigueur, découvrons les durées de vies génériques des paramètres et des valeurs de retour dans le cas des fonctions.
Les durées de vies génériques dans les fonctions
Nous allons écrire une fonction qui retourne la plus longue des slices d’une chaîne de caractères. Cette fonction va prendre en argument deux slices de chaînes de caractères et retourner une seule slice d’une chaîne de caractères. Après avoir implémenté la fonction la_plus_longue, le code de l’encart 10-19 devrait afficher La plus grande chaîne est abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let resultat = la_plus_longue(string1.as_str(), string2);
println!("La plus grande chaîne est {resultat}");
}main function that calls the longest function to find the longer of two string slicesRemarquez que nous souhaitons que la fonction prenne deux slices de chaînes de caractères, qui sont des références, plutôt que des chaînes, car nous ne voulons pas que la fonction la_plus_longue prenne possession de ses paramètres. Rendez-vous à la section “Les slices de chaînes de caractères en paramètres” du chapitre 4 pour savoir pourquoi nous utilisons ce type de paramètres dans l’encart 10-19.
Si nous essayons d’implémenter la fonction la_plus_longue comme dans l’encart 10-20, cela ne va pas se compiler.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let resultat = la_plus_longue(string1.as_str(), string2);
println!("La plus grande chaîne est {resultat}");
}
fn la_plus_longue(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}longest function that returns the longer of two string slices but does not yet compileÀ la place, nous obtenons l’erreur suivante qui nous parle de durées de vie :
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn la_plus_longue(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn la_plus_longue<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
La partie “help” nous explique que le type de retour a besoin d’un paramètre de durée de vie générique car Rust ne sait pas si la référence retournée est liée à x ou à y. Pour le moment, nous ne le savons pas nous non plus, car le bloc if dans le corps de cette fonction retourne une référence à x et le bloc else retourne une référence à y !
Lorsque nous définissons cette fonction, nous ne connaissons pas les valeurs concrètes qui vont passer dans cette fonction, donc nous ne savons pas si nous allons exécuter le cas du if ou du else. Nous ne connaissons pas non plus les durées de vie des références qui vont passer dans la fonction, donc nous ne pouvons pas vérifier les portées comme nous l’avons fait dans les encarts 10-17 et 10-18 pour déterminer si la référence que nous allons retourner sera toujours en vigueur. Le vérificateur d’emprunt ne va pas pouvoir non plus déterminer cela, car il ne sait comment les durées de vie de x et de y sont reliées à la durée de vie de la valeur de retour. Pour résoudre cette erreur, nous allons ajouter des paramètres de durée de vie génériques qui définissent la relation entre les références, afin que le vérificateur d’emprunt puisse faire cette analyse.
Syntaxe d’annotation de durées de vie
Les annotations de durée de vie ne modifient pas la durée de vie des références. Elles décrivent plutôt les relations entre les durées de vie de plusieurs références sans les modifier. Tout comme les fonctions peuvent accepter n’importe quel type lorsque leur signature spécifie un paramètre de type générique, les fonctions peuvent accepter des références avec n’importe quelle durée de vie en spécifiant un paramètre de durée de vie générique.
L’annotation des durées de vies a une syntaxe un peu inhabituelle : le nom des paramètres de durées de vies doit commencer par une apostrophe (') et est habituellement en minuscule et très court, comme les types génériques. La plupart des personnes utilisent le nom 'a pour la première annotation de durée de vie. Nous plaçons le paramètre de type après le & d’une référence, en utilisant un espace pour séparer l’annotation du type de la référence.
Voici quelques exemples : une référence à un i32 sans paramètre de durée de vie, une référence à un i32 qui a un paramètre de durée de vie 'a, et une référence mutable à un i32 qui a aussi la durée de vie 'a :
&i32 // une référence
&'a i32 // une référence avec une durée de vie explicite
&'a mut i32 // une référence mutable avec une durée de vie expliciteUne annotation de durée de vie toute seule n’a pas vraiment de sens, car les annotations sont faites pour indiquer à Rust quels paramètres de durée de vie génériques de plusieurs références sont liés aux autres. Voyons comment les annotations de durée de vie s’articulent entre elles dans le contexte de la fonction la_plus_longue.
Dans les signatures des fonctions
Pour utiliser les annotations de durée de vie dans les signatures de fonctions, nous devons déclarer les paramètres de durée de vie génériques entre chevrons, entre le nom de la fonction et la liste des paramètres, comme nous l’avons fait avec les paramètres de type génériques.
Nous voulons que la signature exprime la contrainte suivante : la référence retournée doit être valide tant que les deux paramètres sont valides. Ceci est la relation entre les durées de vie des paramètres et la valeur retournée. Nous nommerons la durée de vie 'a et nous l’ajouterons à chaque référence, comme montré dans l’encart 10-21.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let resultat = la_plus_longue(string1.as_str(), string2);
println!("La plus grande chaîne est {resultat}");
}
fn la_plus_longue<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}longest function definition specifying that all the references in the signature must have the same lifetime 'aLe code devrait se compiler et devrait produire le résultat que nous souhaitions lorsque nous l’utilisions dans la fonction main de l’encart 10-19.
La signature de la fonction indique maintenant à Rust que pour la durée de vie 'a, la fonction prend deux paramètres, les deux étant des slices de chaînes de caractères qui vivent aussi longtemps que la durée de vie 'a. La signature de la fonction indique également à Rust que la slice de chaîne de caractères qui est retournée par la fonction vivra au moins aussi longtemps que la durée de vie 'a. Dans la pratique, cela veut dire que la durée de vie de la référence retournée par la fonction la_plus_longue est la même que celle de la plus petite des durées de vies des valeurs référencées par les arguments de la fonction. Ces relations sont ce que nous voulons que Rust mette en place lorsqu’il analysera ce code.
Souvenez-vous, lorsque nous précisons les paramètres de durée de vie dans la signature de cette fonction, nous ne changeons pas les durées de vies des valeurs qui lui sont envoyées ou qu’elle retourne. Ce que nous faisons, c’est plutôt indiquer au vérificateur d’emprunt qu’il doit rejeter toute valeur qui ne répond pas à ces conditions. Notez que la fonction la_plus_longue n’a pas besoin de savoir exactement combien de temps x et y vont exister, mais seulement que cette portée peut être substituée par 'a, qui satisfera cette signature.
Lorsqu’on précise les durées de vie dans les fonctions, les annotations se placent dans la signature de la fonction, pas dans le corps de la fonction. Les annotations de durée de vie sont devenues partie intégrante du contrat de la fonction, tout comme les types dans la signature. Avoir des signatures de fonction qui intègrent la durée de vie signifie que l’analyse que va faire le compilateur Rust sera plus simple. S’il y a un problème avec la façon dont la fonction est annotée ou appelée, les erreurs de compilation peuvent pointer plus précisément sur la partie de notre code qui impose ces contraintes. Mais si au contraire, le compilateur Rust avait dû faire plus de suppositions sur ce que nous voulions créer comme lien de durée de vie, le compilateur n’aurait pu qu’évoquer une utilisation de notre code bien plus éloignée de la véritable raison du problème.
Lorsque nous donnons une référence concrète à la_plus_longue, la durée de vie concrète qui est modélisée par 'a est la partie de la portée de x qui se chevauche avec la portée de y. Autrement dit, la durée vie générique 'a aura la durée de vie concrète qui est égale à la plus petite des durées de vies entre x et y. Comme nous avons marqué la référence retournée avec le même paramètre de durée de vie 'a, la référence retournée sera toujours en vigueur pour la durée de la plus petite des durées de vies de x et de y.
Regardons comment les annotations de durée de vie restreignent la fonction la_plus_longue en y passant des références qui ont des durées de vies concrètement différentes. L’encart 10-22 en est un exemple.
fn main() {
let string1 = String::from("une longue chaîne est longue");
{
let string2 = String::from("xyz");
let resultat = la_plus_longue(string1.as_str(), string2.as_str());
println!("La chaîne la plus longue est {resultat}");
}
}
fn la_plus_longue<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}longest function with references to String values that have different concrete lifetimesDans cet exemple, string1 est en vigueur jusqu’à la fin de la portée externe, string2 n’est valide que jusqu’à la fin de la portée interne, et resultat est une référence vers quelque chose qui est en vigueur jusqu’à la fin de la portée interne. Lorsque vous lancez ce code, vous constaterez que le vérificateur d’emprunt accepte ce code ; il va se compiler et afficher La chaîne la plus longue est une longue chaîne est longue.
Maintenant, essayons un exemple qui fait en sorte que la durée de vie de la référence dans resultat sera plus petite que celles des deux arguments. Nous allons déplacer la déclaration de la variable resultat à l’extérieur de la portée interne mais nous allons laisser l’affectation de la valeur de la variable resultat à l’intérieur de la portée de string2. Nous allons ensuite déplacer le println!, qui utilise resultat, à l’extérieur de la portée interne, après que la portée soit terminée. Le code de l’encart 10-23 ne va pas se compiler.
fn main() {
let string1 = String::from("une longue chaîne est longue");
let resultat;
{
let string2 = String::from("xyz");
resultat = la_plus_longue(string1.as_str(), string2.as_str());
}
println!("La plus grande chaîne est {resultat}");
}
fn la_plus_longue<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}result after string2 has gone out of scopeLorsque nous essayons de compiler ce code, nous obtenons cette erreur.
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | resultat = la_plus_longue(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("La plus grande chaîne est {resultat}");
| -------- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
L’erreur explique que pour que resultat soit en vigueur pour l’instruction println!, string2 doit toujours être valide jusqu’à la fin de la portée externe. Rust a déduit cela car nous avons précisé les durées de vie des paramètres de la fonction et des valeurs de retour en utilisant le même paramètre de durée de vie 'a.
En tant qu’humain, nous pouvons lire ce code et constater que string1 est plus grand que string2 et ainsi que resultat contiendra une référence vers string1. Comme string1 n’est pas encore sorti de portée, une référence vers string1 sera toujours valide pour l’instruction println!. Cependant, le compilateur ne peut pas déduire que la référence est valide dans notre cas. Nous avons dit à Rust que la durée de vie de la référence qui est retournée par la fonction la_plus_longue est la même que la plus petite des durées de vie des références qu’on lui passe en argument. C’est pourquoi le vérificateur d’emprunt rejette le code de l’encart 10-23 car il a potentiellement une référence invalide.
Essayez d’expérimenter d’autres situations en variant les valeurs et durées de vie des références passées en argument de la fonction la_plus_longue, et aussi pour voir comment on utilise la référence retournée. Faites des hypothèses pour savoir si ces situations vont passer ou non le vérificateur d’emprunt avant que vous ne compiliez ; et vérifiez ensuite si vous aviez raison !
Relations
La façon dont vous avez à préciser les paramètres de durées de vie dépend de ce que fait votre fonction. Par exemple, si nous changions l’implémentation de la fonction la_plus_longue pour qu’elle retourne systématiquement le premier paramètre plutôt que la slice de chaîne de caractères la plus longue, nous n’aurions pas besoin de renseigner une durée de vie sur le paramètre y. Le code suivant se compile :
fn main() {
let string1 = String::from("abcd");
let string2 = "efghijklmnopqrstuvwxyz";
let resultat = la_plus_longue(string1.as_str(), string2);
println!("La plus grande chaîne est {resultat}");
}
fn la_plus_longue<'a>(x: &'a str, y: &str) -> &'a str {
x
}Nous avons précisé un paramètre de durée de vie 'a sur le paramètre x et sur le type de retour, mais pas sur le paramètre y, car la durée de vie de y n’a pas de lien avec la durée de vie de x ou de la valeur de retour.
Lorsqu’on retourne une référence à partir d’une fonction, le paramètre de la durée de vie pour le type de retour doit correspondre à une des durées de vie des paramètres. Si la référence retournée ne se réfère pas à un de ses paramètres, elle se réfère probablement à une valeur créée à l’intérieur de cette fonction. Toutefois, elle deviendra une référence pendouillante car sa valeur va sortir de la portée à la fin de la fonction. Imaginons cette tentative d’implémentation de la fonction la_plus_longue qui ne se compile pas :
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let resultat = la_plus_longue(string1.as_str(), string2);
println!("La plus grande chaîne est {resultat}");
}
fn la_plus_longue<'a>(x: &str, y: &str) -> &'a str {
let resultat = String::from("très longue chaîne");
resultat.as_str()
}Ici, même si nous avons précisé un paramètre de durée de vie 'a sur le type de retour, cette implémentation va échouer à la compilation car la durée de vie de la valeur de retour n’est pas du tout liée à la durée de vie des paramètres. Voici le message d’erreur que nous obtenons :
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `resultat`
--> src/main.rs:11:5
|
11 | resultat.as_str()
| --------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `resultat` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Le problème est que resultat sort de la portée et est effacée à la fin de la fonction la_plus_longue. Nous avons aussi essayé de retourner une référence vers resultat à partir de la fonction. Il n’existe aucune façon d’écrire les paramètres de durée de vie de telle manière que cela changerait la référence pendouillante, et Rust ne nous laissera pas créer une référence pendouillante. Dans notre cas, la meilleure solution consiste à retourner un type de donnée dont on va prendre possession plutôt qu’une référence, ainsi le code appelant sera responsable du nettoyage de la valeur.
Enfin, la syntaxe de la durée de vie sert à interconnecter les durées de vie de plusieurs paramètres ainsi que les valeurs de retour des fonctions. Une fois celles-ci interconnectées, Rust a assez d’informations pour autoriser les opérations sécurisées dans la mémoire et refuser les opérations qui pourraient créer des pointeurs pendouillants ou alors enfreindre la sécurité de la mémoire.
Dans la définition des structures
Jusqu’à présent, les structures que nous avons définies contiennent toutes des types possédés. Nous pouvons définir des structures pour contenir des références, mais dans ce cas nous devons préciser une durée de vie sur chaque référence dans la définition de la structure. L’encart 10-24 montre une structure ExtraitImportant qui stocke une slice de chaîne de caractères.
struct ExtraitImportant<'a> {
partie: &'a str,
}
fn main() {
let roman = String::from("Appelez-moi Ismaël. Il y a quelques années...");
let premiere_phrase = roman.split('.').next().unwrap();
let i = ExtraitImportant {
partie: premiere_phrase,
};
}Cette structure a un unique champ partie qui stocke une slice de chaîne de caractères, qui est une référence. Comme pour les types de données génériques, nous déclarons le nom du paramètre de durée de vie générique entre des chevrons après le nom de la structure pour que nous puissions utiliser le paramètre de durée de vie dans le corps de la définition de la structure. Cette annotation signifie qu’une instance de ExtraitImportant ne peut pas vivre plus longtemps que la référence qu’elle stocke dans son champ partie.
La fonction main crée ici une instance de la structure ExtraitImportant qui stocke une référence vers la première phrase de la String possédée par la variable roman. Les données dans roman existent avant que l’instance de ExtraitImportant soit crée. De plus, roman ne sort pas de la portée avant que l’instance de ExtraitImportant sorte de la portée, donc la référence dans l’instance de ExtraitImportant est toujours valide.
L’élision des durées de vie
Vous avez appris que toute référence a une durée de vie et que vous devez renseigner des paramètres de durée de vie sur des fonctions ou des structures qui utilisent des références. Cependant, dans le chapitre 4 nous avions une fonction dans l’encart 4-9, qui est montrée à nouveau dans l’encart 10-25, qui compilait sans informations de durée de vie.
fn premier_mot(s: &str) -> &str {
let octets = s.as_bytes();
for (i, &element) in octets.iter().enumerate() {
if element == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let ma_string = String::from("hello world");
// premier_mot travaille sur des slices de `String`s
let mot = premier_mot(&ma_string[..]);
let mon_litteral_de_chaine = "hello world";
// premier_mot travaille sur des slices de littéraux de chaîne
let mot = premier_mot(&mon_litteral_de_chaine[..]);
// Comme les littéraux de chaîne *sont* déjà des slices de chaînes,
// cela fonctionne aussi, sans la syntaxe de slice !
let mot = premier_mot(mon_litteral_de_chaine);
}La raison pour laquelle cette fonction se compile sans annotation de durée de vie est historique : dans les premières versions de Rust (avant la 1.0), ce code ne se serait pas compilé parce que chaque référence devait avoir une durée de vie explicite. À l’époque, la signature de la fonction devait être écrite ainsi :
fn premier_mot<'a>(s: &'a str) -> &'a str {Après avoir écrit une grande quantité de code Rust, l’équipe de Rust s’est rendu compte que les développeurs Rust saisissaient toujours les mêmes durées de vie encore et encore dans des situations spécifiques. Ces situations étaient prévisibles et suivaient des schémas prédéterminés. Les développeurs ont programmé ces schémas dans le code du compilateur afin que le vérificateur d’emprunt puisse deviner les durées de vie dans ces situations et n’aie plus besoin d’annotations explicites.
Cette partie de l’histoire de Rust est intéressante car il est possible que d’autres modèles prédéterminés émergent et soient ajoutés au compilateur. À l’avenir, il est possible qu’encore moins d’annotations de durée de vie soient nécessaires.
Les schémas programmés dans l’analyse des références de Rust s’appellent les règles d’élision des durées de vie. Ce ne sont pas des règles que les développeurs doivent suivre ; c’est un jeu de cas particuliers que le compilateur va essayer de comparer à votre code, et s’il y a une correspondance alors vous n’aurez pas besoin d’écrire explicitement les durées de vie.
Les règles d’élision ne permettent pas de faire des déductions complètes. S’il existe toujours une ambiguïté quant à la durée de vie des références après que Rust ait appliqué ces règles, le compilateur ne devinera pas quelle devrait être la durée de vie des autres références. Dans ce cas, au lieu de tenter de deviner, le compilateur va vous afficher une erreur que vous pourrez résoudre en ajoutant les annotations de durée de vie.
Les durées de vies sur les fonctions ou les paramètres des fonctions sont appelées les durées de vie des entrées, et les durées de vie sur les valeurs de retour sont appelées les durées de vie des sorties.
Le compilateur utilise trois règles pour déterminer quelles devraient être les durées de vie des références si cela n’est pas indiqué explicitement. La première règle s’applique sur les durées de vie des entrées, et les deuxième et troisième règles s’appliquent sur les durées de vie des sorties. Si le compilateur arrive à la fin des trois règles et qu’il y a encore des références pour lesquelles il ne peut pas savoir leur durée de vie, le compilateur s’arrête avec une erreur. Ces règles s’appliquent sur les définitions des fn ainsi que sur celles des blocs impl.
La première règle dit que le compilateur affecte un paramètre de durée de vie à chaque paramètre qui est une référence. Autrement dit, une fonction avec un seul paramètre va avoir un seul paramètre de durée de vie : fn foo<'a>(x: &'a i32) ; une fonction avec deux paramètres va avoir deux paramètres de durée de vie séparés : fn foo<'a, 'b>(x: &'a i32, y: &'b i32) ; et ainsi de suite.
La deuxième règle dit que s’il y a exactement un seul paramètre de durée de vie d’entrée, cette durée de vie est assignée à tous les paramètres de durée de vie des sorties : fn foo<'a>(x: &'a i32) -> &'a i32.
La troisième règle est que lorsque nous avons plusieurs paramètres de durée de vie, mais qu’un d’entre eux est &self ou &mut self parce que c’est une méthode, la durée de vie de self sera associée à tous les paramètres de durée de vie des sorties. Cette troisième règle rend les méthodes plus faciles à lire et à écrire car il y a moins de caractères nécessaires.
Imaginons que nous soyons le compilateur. Nous allons appliquer ces règles pour déduire quelles seront les durées de vie des références dans la signature de la fonction premier_mot de l’encart 10-25.
fn premier_mot(s: &str) -> &str {Le compilateur applique alors la première règle, qui dit que chaque référence a sa propre durée de vie. Appellons-la 'a comme d’habitude, donc maintenant la signature devient ceci :
fn premier_mot<'a>(s: &'a str) -> &str {La deuxième règle s’applique car il y a exactement une durée de vie d’entrée ici. La deuxième règle dit que la durée de vie du seul paramètre d’entrée est affectée à la durée de vie des sorties, donc la signature est maintenant ceci :
fn premier_mot<'a>(s: &'a str) -> &'a str {Maintenant, toutes les références de cette signature de fonction ont des durées de vie, et le compilateur peut continuer son analyse sans avoir besoin que le développeur renseigne les durées de vie dans cette signature de fonction.
Voyons un autre exemple, qui utilise cette fois la fonction la_plus_longue qui n’avait pas de paramètres de durée de vie lorsque nous avons commencé à l’utiliser dans l’encart 10-20 :
fn la_plus_longue(x: &str, y: &str) -> &str {Appliquons la première règle : chaque référence a sa propre durée de vie. Cette fois, nous avons avons deux références au lieu d’une seule, donc nous avons deux durées de vie :
fn la_plus_longue<'a, 'b>(x: &'a str, y: &'b str) -> &str {Vous pouvez constater que la deuxième règle ne s’applique pas car il y a plus d’une seule durée de vie. La troisième ne s’applique pas non plus, car la_plus_longue est une fonction et pas une méthode, donc aucun de ses paramètres n’est self. Après avoir utilisé ces trois règles, nous n’avons pas pu en déduire la durée de vie de la valeur de retour. C’est pourquoi nous obtenons une erreur en essayant de compiler le code dans l’encart 10-20 : le compilateur a utilisé les règles d’élision des durées de vie mais n’est pas capable d’en déduire toutes les durées de vie des références présentes dans la signature.
Comme la troisième règle ne s’applique que sur les signatures des méthodes, nous allons examiner les durées de vie dans ce contexte pour comprendre pourquoi la troisième règle signifie que nous n’avons pas souvent besoin d’annoter les durées de vie dans les signatures des méthodes.
Dans les définitions des méthodes
Lorsque nous implémentons des méthodes sur une structure avec des durées de vie, nous utilisons la même syntaxe que celle des paramètres de type génériques, comme nous l’avons vu dans l’encart 10-11. L’endroit où nous déclarons et utilisons les paramètres de durée de vie dépend de s’ils sont reliés aux champs des structures ou aux paramètres de la méthode et aux valeurs de retour.
Les noms des durées de vie pour les champs de structure ont toujours besoin d’être déclarés après le mot-clé impl et sont ensuite utilisés après le nom de la structure, car ces durées de vie font partie du type de la structure.
Sur les signatures des méthodes à l’intérieur du bloc impl, les références peuvent être liées à la durée de vie des références de champs de la structure, ou elles peuvent être indépendantes. De plus, les règles d’élision des durées de vie font parfois en sorte que l’ajout de durées de vie n’est parfois pas nécessaire dans les signatures des méthodes. Voyons quelques exemples en utilisant la structure ExtraitImportant que nous avons définie dans l’encart 10-24.
Premièrement, nous allons utiliser une méthode niveau dont le seul paramètre est une référence à self et dont la valeur de retour sera un i32, qui n’est pas une référence :
struct ExtraitImportant<'a> {
partie: &'a str,
}
impl<'a> ExtraitImportant<'a> {
fn niveau(&self) -> i32 {
3
}
}
impl<'a> ExtraitImportant<'a> {
fn annoncer_et_retourner_partie(&self, annonce: &str) -> &str {
println!("Votre attention s'il vous plaît : {annonce}");
self.partie
}
}
fn main() {
let roman = String::from("Appelez-moi Ismaël. Il y a quelques années...");
let premiere_phrase = roman.split('.').next().unwrap();
let i = ExtraitImportant {
partie: premiere_phrase,
};
}La déclaration du paramètre de durée de vie après impl et son utilisation après le nom du type sont nécessaires, mais grâce à la première règle d’élision, nous n’avons pas à préciser la durée de vie de la référence à self.
Voici un exemple où la troisième règle d’élision des durées de vie s’applique :
struct ExtraitImportant<'a> {
partie: &'a str,
}
impl<'a> ExtraitImportant<'a> {
fn niveau(&self) -> i32 {
3
}
}
impl<'a> ExtraitImportant<'a> {
fn annoncer_et_retourner_partie(&self, annonce: &str) -> &str {
println!("Votre attention s'il vous plaît : {annonce}");
self.partie
}
}
fn main() {
let roman = String::from("Appelez-moi Ismaël. Il y a quelques années...");
let premiere_phrase = roman.split('.').next().unwrap();
let i = ExtraitImportant {
partie: premiere_phrase,
};
}Il y a deux durées de vies des entrées, donc Rust applique la première règle d’élision des durées de vie et donne à &self et annonce leur propre durée de vie. Ensuite, comme un des paramètres est &self, le type de retour obtient la durée de vie de &self, de sorte que toutes les durées de vie ont été calculées.
La durée de vie statique
Une durée de vie particulière que nous devons aborder est 'static, qui indique que la référence concernée peut vivre pendant la totalité de la durée du programme. Tous les littéraux de chaînes de caractères ont la durée de vie 'static, que nous pouvons écrire comme ceci :
#![allow(unused)]
fn main() {
let s: &'static str = "J'ai une durée de vie statique.";
}Le texte de cette chaîne de caractères est stocké directement dans le binaire du programme, qui est toujours disponible. C’est pourquoi la durée de vie de tous les littéraux de chaînes de caractères est 'static.
Il se peut que voyiez dans les messages d’erreur des suggestions pour utiliser la durée de vie 'static. Mais avant d’utiliser 'static comme durée de vie pour une référence, demandez-vous si la référence en question vit bien pendant toute la vie de votre programme, ou non, et si c’est réellement ce que vous voulez. La plupart du temps, un message d’erreur suggérant une durée de vie 'static résulte d’une tentative de création d’une référence pendouillante ou d’une inadéquation des durées de vie disponibles. Dans ces cas-là, la solution consiste à résoudre ces problèmes, et pas à renseigner la durée de vie comme étant 'static.
Les paramètres de type génériques, les traits liés, et les durées de vie
Regardons brièvement la syntaxe pour renseigner tous les paramètres de type génériques, les traits liés, et les durées de vie sur une seule fonction !
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let resultat = la_plus_longue_avec_annonce(
string1.as_str(),
string2,
"Aujourd'hui, c'est l'anniversaire de quelqu'un !",
);
println!("La plus grande chaîne est {resultat}");
}
use std::fmt::Display;
fn la_plus_longue_avec_annonce<'a, T>(
x: &'a str,
y: &'a str,
ann: T,
) -> &'a str
where
T: Display,
{
println!("Annonce ! {ann}");
if x.len() > y.len() { x } else { y }
}C’est la fonction la_plus_longue de l’encart 10-21 qui retourne la plus grande de deux slices de chaînes de caractères. Mais maintenant elle a un paramètre supplémentaire ann de type générique T, qui peut être remplacé par n’importe quel type qui implémente le trait Display comme le précise la clause where. Ce paramètre supplémentaire sera affiché avec {}, c’est pourquoi le trait lié Display est nécessaire. Comme les durées de vie sont un type de génériques, les déclarations du paramètre de durée de vie 'a et le paramètre de type générique T vont dans la même liste à l’intérieur des chevrons après le nom de la fonction.
Résumé
Nous avons vu beaucoup de choses dans ce chapitre ! Maintenant que vous en savez plus sur les paramètres de type génériques, les traits et les traits liés, ainsi que sur les paramètres de durée de vie génériques, vous pouvez maintenant écrire du code en évitant les doublons qui va bien fonctionner dans de nombreuses situations. Les paramètres de type génériques vous permettent d’appliquer du code à différents types. Les traits et les traits liés s’assurent que bien que les types soient génériques, ils auront un comportement particulier sur lequel le code peut compter. Vous avez appris comment utiliser les indications de durée de vie pour vous assurer que ce code flexible n’aura pas de références pendouillantes. Et toutes ces vérifications se font au moment de la compilation, ce qui n’influe pas sur les performances au moment de l’exécution du programme !
Croyez-le ou non, mais il y a encore des choses à apprendre sur les sujets que nous avons traités dans ce chapitre : le chapitre 18 expliquera les objets de trait, qui est une façon d’utiliser les traits. Il existe aussi des situations plus complexes impliquant des indications de durée de vie dont vous n’aurez besoin que dans certains cas de figure très avancés; pour ces cas-là, vous devriez consulter la Référence de Rust. Maintenant, nous allons voir au chapitre suivant comment écrire des tests en Rust afin que vous puissiez vous assurer que votre code fonctionne comme il devrait le faire.
Écrire des tests automatisés
Dans son essai de 1972 “The Humble Programmer”, Edsger W. Dijkstra a dit qu’un “test de programme peut être une manière très efficace de prouver la présence de bogues, mais qu’il est totalement inadéquat pour prouver leur absence”. Mais cela ne veut pas dire que nous ne devrions pas tester notre programme autant que faire se peut !
L’exactitude de nos programmes est le niveau de conformité de notre code par rapport à ce que nous voulons qu’il fasse. Rust est conçu dans un grand souci d’exactitude des programmes, mais l’exactitude est complexe et difficile à confirmer. Le système de type de Rust endosse une grande partie de cette charge, mais le système de type ne peut pas tout détecter. Ainsi, Rust embarque des fonctionnalités pour écrire des tests automatisés de logiciels à l’intérieur du langage.
Imaginons que nous écrivions une fonction ajouter_deux qui ajoute 2 à n’importe quel nombre qu’on lui envoie. La signature de cette fonction prend un entier en paramètre et retourne un entier comme résultat. Lorsque nous implémentons et compilons cette fonction, Rust fait toutes les vérifications de type et d’emprunt que vous avez apprises précédemment afin de s’assurer que, par exemple, nous ne passions pas une valeur de type String ou une référence invalide à cette fonction. Mais Rust ne peut pas vérifier que cette fonction va faire précisément ce que nous avions prévu qu’elle fasse, qui en l’occurence est de retourner le paramètre incrémenté de 2 plutôt que d’ajouter 10 ou d’enlever 50, par exemple ! C’est pour cette situation que les tests sont utiles.
Nous pouvons écrire des tests qui vérifient, par exemple, que lorsque nous donnons 3 à la fonction ajouter_deux, elle retourne bien 5. Nous pouvons lancer ces tests à chaque fois que nous modifions notre code pour nous assurer qu’aucun comportement existant et satisfaisant n’a changé.
Les tests restent une discipline complexe : bien que nous ne puissions couvrir en un seul chapitre chaque détail sur l’écriture de bons tests, nous allons découvrir les mécanismes des outils de test de Rust. Nous allons voir les annotations et les macros que vous pourrez utiliser lorsque vous écrirez vos tests, le comportement par défaut et les options disponibles pour lancer vos tests, et comment organiser les tests en tests unitaires et tests d’intégration.
Comment écrire des tests
Comment écrire des tests
Les tests sont des fonctions Rust qui vérifient que le code qui n’est pas un test se comporte bien de la manière attendue. Les corps des fonctions de test effectuent généralement ces trois actions :
- Initialiser toutes les données ou les états.
- Lancer le code que vous voulez tester.
- Vérifier que les résultats correspondent bien à ce que vous souhaitez.
Découvrons les fonctionnalités spécifiques qu’offre Rust pour écrire des tests qui font ces actions, dont l’attribut test, quelques macros et l’attribut should_panic.
Structuration des fonctions de test
Dans la forme la plus simple, un test en Rust est une fonction qui est marquée avec l’attribut test. Les attributs sont des métadonnées sur des parties de code Rust ; un exemple est l’attribut derive que nous avons utilisé sur les structures au chapitre 5. Pour transformer une fonction en une fonction de test, il faut ajouter #[test] dans la ligne avant le fn. Lorsque vous lancez vos tests avec la commande cargo test, Rust construit un binaire d’exécution de tests qui exécute les fonctions marquées avec l’attribut test et fait un rapport sur quelles fonctions ont réussi ou échoué.
Chaque fois que nous créons une nouvelle bibliothèque avec Cargo, un module de tests qui contient une fonction de test est automatiquement créé pour nous. Ce module vous fournit un modèle pour l’écriture de vos tests afin que vous n’ayez pas à chercher la structure et la syntaxe exacte d’une fonction de test à chaque fois que vous débutez un nouveau projet. Vous pouvez ajouter autant de fonctions de test et autant de modules de tests que vous le souhaitez !
Nous allons découvrir quelques aspects du fonctionnement des tests en expérimentant avec le modèle de tests avant de réellement tester du code. Ensuite, nous écrirons quelques tests plus proches de la réalité, qui utiliseront du code que nous avons écrit et qui valideront son bon comportement.
Commençons par créer un nouveau projet de bibliothèque que nous appellerons addition qui additionnera deux nombres :
$ cargo new addition --lib
Created library `addition` project
$ cd addition
Le contenu de votre fichier src/lib.rs dans votre bibliothèque addition devrait ressembler à l’encart 11-1.
pub fn additionne(gauche: u64, droite: u64) -> u64 {
gauche + droite
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn cela_fonctionne() {
let resultat = additionne(2, 2);
assert_eq!(resultat, 4);
}
}cargo newLe fichier commence par un exemple de fonction additionne, de façon à ce que nous ayons quelque chose à tester.
Pour l’instant, concentrons-nous sur la fonction cela_fonctionne. Remarquez l’annotation #[test] avant la ligne fn : cet attribut indique que c’est une fonction de test, donc l’exécuteur de tests sait qu’il doit considérer cette fonction comme étant un test. Nous pourrions aussi avoir des fonctions qui ne font pas de tests dans le module tests afin de configurer des scénarios communs ou exécuter des opérations communes, c’est pourquoi nous devons toujours indiquer quelles fonctions sont des tests en utilisant l’attribut #[test].
Le corps de la fonction utilise la macro assert_eq! pour vérifier que resultat, qui contient le résultat de l’appel de additionne avec 2 et 2, vaut bien 4. Cette vérification sert d’exemple pour expliquer le format d’un test classique. Lançons-le pour vérifier si ce test est validé.
La commande cargo test lance tous les tests présents dans votre projet, comme le montre l’encart 11-2.
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::cela_fonctionne ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo a compilé et lancé le test. Après les lignes Compiling, Finished, et Running, on trouve la ligne running 1 test. La ligne suivante montre le nom de la fonction de test tests::cela_fonctionne, et le résultat de l’exécution de ce test, qui est ok. Le résumé général test result: ok. signifie que tous les tests ont réussi, et la partie 1 passed; 0 failed compte le nombre total de tests qui ont réussi ou échoué.
Il est possible de marquer un test comme ignoré afin qu’il ne soit pas exécuté dans une instance donnée ; nous aborderons ce sujet dans la section “Ignorer certains tests sauf s’ils sont demandés explicitement” plus loin dans ce chapitre. Comme nous n’avons pas fait cela ici, le résumé affiche 0 ignored. Nous pouvons également passer un argument à la commande cargo test pour n’exécuter que les tests dont le nom correspond à une chaîne de caractères ; c’est ce qui s’appelle le filtrage, nous aborderons ce sujet dans la section “Exécuter un sous-ensemble de tests en fonction de son nom”. Ici, nous n’avons pas filtré les tests qui ont été exécutés, donc la fin du résumé affiche 0 filtered out.
La statistique 0 measured sert pour des tests de benchmark qui mesurent les performances. Les tests de benchmark ne sont disponibles pour le moment que dans la version expérimentale de Rust (nightly), au moment de la rédaction. Rendez-vous sur [la documentation sur les tests de benchmark][bench] pour en savoir plus.
La partie suivante du résultat des tests, qui commence par Doc-tests addition, concerne les résultats de tous les tests présents dans la documentation. Nous n’avons pas de tests dans la documentation pour le moment, mais Rust peut compiler tous les exemples de code qui sont présents dans la documentation de notre API. Cette fonctionnalité nous aide à garder synchronisés notre documentation et notre code ! Nous verrons comment écrire nos tests dans la documentation dans la section “Les commentaires de documentation pour faire des tests” du chapitre 14. Pour le moment, nous allons ignorer la partie Doc-tests du résultat.
Commençons à adapters le test à nos propres besoins. Changeons d’abord le nom de la fonction cela_fonctionne pour un nom différent, comme exploration, comme ci-dessous :
Fichier : src/lib.rs
pub fn additionne(gauche: u64, droite: u64) -> u64 {
gauche + droite
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let resultat = additionne(2, 2);
assert_eq!(resultat, 4);
}
}Lancez ensuite à nouveau cargo test. Le résultat affiche désormais exploration plutôt que it_works :
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ajoutons maintenant un autre test, mais cette fois nous allons construire un test qui échoue ! Les tests échouent lorsque quelque chose dans la fonction de test panique. Chaque test est lancé dans une nouvelle tâche, et lorsque la tâche principale voit qu’une tâche de test a été interrompue par panique, le test est considéré comme ayant échoué. Au chapitre 9, Nous avons vu que la façon la plus simple de faire paniquer consiste à appeler la macro panic!. Ecrivez ce nouveau test, un_autre, de sorte que votre fichier src/lib.rs ressemble à ceci :
pub fn additionne(gauche: u64, droite: u64) -> u64 {
gauche + droite
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let resultat = additionne(2, 2);
assert_eq!(resultat, 4);
}
#[test]
fn un_autre() {
panic!("Fait échouer ce test");
}
}panic! macroLancez à nouveau les tests en utilisant cargo test. Le résultat devrait ressembler à l’encart 11-4, qui va afficher que notre test exploration a réussi et que un_autre a échoué.
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::un_autre ... FAILED
test tests::exploration ... ok
failures:
---- tests::un_autre stdout ----
thread 'tests::un_autre' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::un_autre
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
À la place du ok, la ligne test tests:un_autre affiche FAILED. Deux nouvelles sections apparaissent entre la liste des tests et le résumé : la première section affiche la raison détaillée de chaque échec de test. Dans notre cas, nous obtenons les détails indiquant que un_autre a échoué car il a paniqué avec le message ‘Fait échouer ce test’, qui est placé à la ligne 17 du fichier src/lib.rs. La partie suivante liste simplement les noms de tous les tests qui ont échoué, ce qui est utile lorsqu’il y a de nombreux tests et beaucoup de détails provenant des tests qui échouent. Nous pouvons utiliser le nom d’un test qui échoue pour lancer uniquement ce test afin de déboguer plus facilement ; nous allons voir plus de façons de lancer des tests dans la section suivante “Gérer l’exécution des tests”.
La ligne de résumé s’affiche à la fin : au final, le résultat de nos tests est au statut FAILED (échoué). Nous avons un test réussi et un test échoué.
Maintenant que vous avez vu à quoi ressemblent les résultats de tests dans différents scénarios, voyons d’autres macros que panic! qui nous seront utiles pour les tests.
Vérifier les résultats avec assert!
La macro assert!, fournie par la bibliothèque standard, est utile lorsque vous voulez vous assurer qu’une condition dans un test vaut true. Nous fournissons à la macro assert! un argument qui donne un Booléen une fois interprété. Si la valeur est true, rien ne se passe et le test est réussi. Si la valeur est false, la macro assert! appelle panic!, qui fait échouer le test. L’utilisation de la macro assert! nous aide à vérifier que notre code fonctionne bien comme nous le souhaitions.
Dans le chapitre 5, dans l’encart 5-15, nous avons utilisé une structure Rectangle et une méthode peut_contenir, qui sont recopiés dans l’encart 11-5 ci-dessous. Ajoutons ce code dans le fichier src/lib.rs, puis écrivons quelques tests en utilisant la macro assert!.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn peut_contenir(&self, autre: &Rectangle) -> bool {
self.largeur > autre.largeur && self.hauteur > autre.hauteur
}
}Rectangle struct and its can_hold method from Chapter 5La méthode peut_contenir retourne un Booléen, ce qui veut dire que c’est un cas parfait pour tester la macro assert!. Dans l’encart 11-6, nous écrivons un test qui s’applique sur la méthode peut_contenir en créant une instance de Rectangle qui a une largeur de 8 et une hauteur de 7, et qui vérifie qu’il peut contenir une autre instance de Rectangle qui a une largeur de 6 et une hauteur de 1.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn peut_contenir(&self, autre: &Rectangle) -> bool {
self.largeur > autre.largeur && self.hauteur > autre.hauteur
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_grand_peut_contenir_un_petit() {
let le_grand = Rectangle {
largeur: 8,
hauteur: 7,
};
let le_petit = Rectangle {
largeur: 5,
hauteur: 1,
};
assert!(le_grand.peut_contenir(&le_petit));
}
}can_hold that checks whether a larger rectangle can indeed hold a smaller rectangleRemarquez la présence de la ligne use super::*; à l’intérieur du module tests. Le module tests est un module classique qui suit les règles de visibilité que nous avons vues au chapitre 7 dans la section “Les chemins pour désigner un élément dans l’arborescence de module”. Comme le module tests est un module interne, nous avons besoin de ramener le code à tester qui se trouve dans son module parent dans la portée interne du module. Nous utilisons ici un opérateur global afin que tout ce que nous avons défini dans le module parent soit disponible dans le module tests.
Nous avons nommé notre test un_grand_peut_contenir_un_petit, et nous avons créé les deux instances Rectangle dont nous avons besoin. Ensuite, nous avons appelé la macro assert! et nous lui avons passé le résultat de l’appel à le_grand.peut_contenir(&le_petit). Cette expression est censée retourner true, donc notre test devrait réussir. Vérifions cela !
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::un_grand_peut_contenir_un_petit ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Il a réussi ! Ajoutons maintenant un autre test, qui vérifie cette fois qu’un petit rectangle ne peut contenir un rectangle plus grand :
Fichier : src/lib.rs
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
impl Rectangle {
fn peut_contenir(&self, autre: &Rectangle) -> bool {
self.largeur > autre.largeur && self.hauteur > autre.hauteur
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_grand_peut_contenir_un_petit() {
// -- partie masquée ici --
let le_grand = Rectangle {
largeur: 8,
hauteur: 7,
};
let le_petit = Rectangle {
largeur: 5,
hauteur: 1,
};
assert!(le_grand.peut_contenir(&le_petit));
}
#[test]
fn un_petit_ne_peut_pas_contenir_un_plus_grand() {
let le_grand = Rectangle {
largeur: 8,
hauteur: 7,
};
let le_petit = Rectangle {
largeur: 5,
hauteur: 1,
};
assert!(!le_petit.peut_contenir(&le_grand));
}
}Comme le résultat correct de la fonction peut_contenir dans ce cas doit être false, nous devons faire un négatif de cette fonction avant de l’envoyer à la macro assert!. Cela aura pour effet de faire réussir notre test si peut_contenir retourne false :
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::un_grand_peut_contenir_un_petit ... ok
test tests::un_petit_ne_peut_pas_contenir_un_plus_grand ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Voilà deux tests qui réussissent ! Maintenant, voyons ce qui se passe dans les résultats de nos tests lorsque nous introduisons un bogue dans notre code. Changeons l’implémentation de la méthode peut_contenir en remplaçant l’opérateur plus grand que (>) par un plus petit que (<) au moment de la comparaison des largeurs :
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
// -- partie masquée ici --
impl Rectangle {
fn peut_contenir(&self, autre: &Rectangle) -> bool {
self.largeur < autre.largeur && self.hauteur > autre.hauteur
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_grand_peut_contenir_un_petit() {
let le_grand = Rectangle {
largeur: 8,
hauteur: 7,
};
let le_petit = Rectangle {
largeur: 5,
hauteur: 1,
};
assert!(le_grand.peut_contenir(&le_petit));
}
#[test]
fn un_petit_ne_peut_pas_contenir_un_plus_grand() {
let le_grand = Rectangle {
largeur: 8,
hauteur: 7,
};
let le_petit = Rectangle {
largeur: 5,
hauteur: 1,
};
assert!(!le_petit.peut_contenir(&le_grand));
}
}Le lancement des tests donne maintenant le résultat suivant :
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::un_grand_peut_contenir_un_petit ... FAILED
test tests::un_petit_ne_peut_pas_contenir_un_plus_grand ... ok
failures:
---- tests::un_grand_peut_contenir_un_petit stdout ----
thread 'tests::un_grand_peut_contenir_un_petit' panicked at src/lib.rs:28:9:
assertion failed: le_grand.peut_contenir(&le_petit)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::un_grand_peut_contenir_un_petit
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nos tests ont repéré le bogue ! Comme le_grand.largeur est 8 et le_petit.largeur est 5, la comparaison des largeurs dans peut_contenir retourne maintenant false : 8 n’est pas plus petit que 5.
Tester l’égalité avec assert_eq! et assert_ne!
Une façon courante de vérifier une fonctionnalité est de tester l’égalité entre le résultat du code à tester et une valeur que vous souhaitez que le code retourne. Vous pouvez faire cela avec la macro assert!, en lui passant une expression qui utilise l’opérateur ==. Cependant, c’est un test si courant que la bibliothèque standard fournit une paire de macros (assert_eq! et assert_ne!) pour procéder à ce test plus facilement. Les macros comparent respectivement l’égalité ou la non égalité de deux arguments. Elles vont aussi afficher les deux valeurs si la vérification échoue, ce qui va nous aider à comprendre pourquoi le test a échoué ; paradoxalement, la macro assert! indique seulement qu’elle a obtenu une valeur false de l’expression avec le ==, mais n’affiche pas les valeurs qui l’ont menée à la valeur false.
Dans l’encart 11-7, nous écrivons une fonction ajouter_deux qui ajoute 2 à son paramètre, et ensuite nous testons cette fonction en utilisant la macro assert_eq!.
pub fn ajouter_deux(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn cela_ajoute_deux() {
let resultat = ajouter_deux(2);
assert_eq!(resultat, 4);
}
}add_two using the assert_eq! macroVérifions si cela fonctionne !
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Nous créons une variable nommée resultat qui contient le résultat de l’appel ajouter_deux(2). Ensuite, nous passons resultat et 4 comme arguments à la macro assert_eq!. La ligne de sortie correspondant à ce test est test tests::cela_ajoute_deux ... ok, et le texte ok indique que notre test a réussi !
Ajoutons un bogue dans notre code pour voir ce que retourne assert_eq! quand il échoue. Changez l’implémentation de la fonction ajouter_deux pour ajouter plutôt 3 :
pub fn ajouter_deux(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn cela_ajoute_deux() {
let resultat = ajouter_deux(2);
assert_eq!(resultat, 4);
}
}Lancez à nouveau les tests :
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::cela_ajoute_deux ... FAILED
failures:
---- tests::cela_ajoute_deux stdout ----
thread 'tests::cela_ajoute_deux' panicked at src/lib.rs:12:9
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::cela_ajoute_deux
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Notre test a détecté le bogue ! Le test tests::cela_ajoute_deux a échoué, et le message nous informant que l’assertion a échoué est (left == right) et ce qu’il y a dans les valeurs left et right. Ce message nous aide à commencer le débogage : l’argument left, où nous avions le résultat de l’appel à ajouter_deux(2), valait 5, mais l’argument right valait 4. Vous imaginez aisément que ceci doit être particulièrement utile quand il y a de nombreux tests.
Notez que dans certains langages et environnements de test, les paramètres des fonctions qui vérifient que deux valeurs soient égales sont appelés attendu et effectif, et l’ordre dans lesquels nous renseignons les arguments est important. Cependant, dans Rust, on les appelle gauche et droite, et l’ordre dans lesquels nous renseignons la valeur que nous attendons et la valeur que produit le code à tester n’est pas important. Nous pouvons écrire la vérification de ce test sous la forme assert_eq!(ajouter_deux(2), 4), ce qui donnera un message d’échec qui affichera assertion `(left == right)` failed.
La macro assert_ne! va réussir si les deux valeurs que nous lui donnons ne sont pas égales et va échouer si elles sont égales. Cette macro est utile dans les cas où nous ne sommes pas sûrs de ce que devrait valoir une valeur, mais que nous savons ce que la valeur ne devrait surtout pas être. Par exemple, si nous testons une fonction qui doit transformer sa valeur d’entrée de manière à ce qu’elle dépende du jour de la semaine où nous lançons nos tests, la meilleure façon de vérifier serait que la sortie de la fonction ne soit pas égale à son entrée.
Sous le capot, les macros assert_eq! et assert_ne! utilisent respectivement les opérateurs == et !=. Lorsque les vérifications échouent, ces macros affichent leurs arguments en utilisant le formatage de débogage, ce qui veut dire que les valeurs comparées doivent implémenter les traits PartialEq et Debug. Tous les types primitifs et la plupart des types de la bibliothèque standard implémentent ces traits. Concernant les structures et les énumérations que vous définissez, vous allez avoir besoin de leur implémenter PartialEq pour vérifier les égalités de ces types. Vous aurez aussi besoin d’implémenter Debug pour afficher les valeurs lorsque les vérifications échouent. Du fait que ces traits sont des traits dérivables, comme nous l’avons évoqué dans l’encart 5-12 du chapitre 5, il suffit généralement de simplement ajouter l’annotation #[derive(PartialEq, Debug)] sur les définitions de vos structures ou énumérations. Rendez-vous à l’annexe C pour en savoir plus sur ces derniers et les autres traits dérivables.
Ajouter des messages d’échec personnalisés
Vous pouvez aussi ajouter un message personnalisé qui peut être affiché avec le message d’échec comme un argument optionnel aux macros assert!, assert_eq!, et assert_ne!. Tous les arguments renseignés après les arguments obligatoires sont envoyés à la macro format! (que nous avons vue dans la section “Concaténation avec + ou format!” du chapitre 8, ainsi vous pouvez passer une chaîne de caractères de formatage qui contient des espaces réservés {} et les valeurs iront dans ces espaces réservés. Les messages personnalisés sont utiles pour documenter ce que fait une vérification ; lorsqu’un test échoue, vous aurez une idée plus précise du problème avec ce code.
Par exemple, disons que nous avons une fonction qui accueille les gens par leur nom et que nous voulons tester que le nom que nous envoyons à la fonction apparaît dans le résultat :
Fichier : src/lib.rs
pub fn accueil(nom: &str) -> String {
format!("Salut, {nom} !")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn accueil_contient_le_nom() {
let resultat = accueil("Carole");
assert!(resultat.contains("Carole"));
}
}Les spécifications de ce programme n’ont pas été validées entièrement pour le moment, et on est quasiment sûr que le texte Salut au début va changer. Nous avons décidé que nous ne devrions pas à avoir à changer le test si les spécifications changent, donc plutôt que de vérifier l’égalité exacte de la valeur retournée par la fonction accueil, nous allons uniquement vérifier que le résultat contient le texte correspondant au paramètre d’entrée de la fonction.
Introduisons maintenant un bogue dans ce code en changeant accueil pour ne pas ajouter nom afin de voir ce que donne l’échec de ce test :
pub fn accueil(nom: &str) -> String {
String::from("Salut !")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn accueil_contient_le_nom() {
let resultat = accueil("Carole");
assert!(resultat.contains("Carole"));
}
}L’exécution du test va donner ceci :
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::accueil_contient_le_nom ... FAILED
failures:
---- tests::accueil_contient_le_nom stdout ----
thread 'tests::accueil_contient_le_nom' panicked at src/lib.rs:12:9:
assertion failed: resultat.contains("Carole")'
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::accueil_contient_le_nom
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Ce résultat indique simplement que la vérification a échoué, et à quel endroit. Le message d’échec serait plus utile dans notre cas s’il affichait la valeur que nous obtenons de la fonction accueil. Ajoutons un message d’erreur personnalisé composé d’une chaîne de caractères de formatage avec un espace réservé qui contiendra la valeur que nous avons obtenue de la fonction accueil :
pub fn accueil(nom: &str) -> String {
String::from("Salut !")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn accueil_contient_le_nom() {
let resultat = accueil("Carole");
assert!(
resultat.contains("Carole"),
"Le message d'accueil ne contient pas le nom, il vaut `{resultat}`"
);
}
}Maintenant, lorsque nous lançons à nouveau le test, nous obtenons un message d’échec plus explicite :
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::accueil_contient_le_nom ... FAILED
failures:
---- tests::accueil_contient_le_nom stdout ----
thread 'tests::accueil_contient_le_nom' panicked at src/lib.rs:12:9:
Le message d'accueil ne contient pas le nom, il vaut `Salut !`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::accueil_contient_le_nom
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nous pouvons voir la valeur que nous avons obtenue lors de la lecture du résultat du test, ce qui va nous aider à déboguer ce qui s’est passé à la place de ce que nous voulions qu’il se passe.
Vérifier le fonctionnement des paniques avec should_panic
En plus de vérifier les valeurs retournées, il est important de vérifier que notre code gère bien les cas d’erreurs comme nous le souhaitons. Par exemple, utilisons le type Supposition que nous avons créé au chapitre 9, dans l’encart 9-13. Les autres codes qui utilisent Supposition reposent sur la garantie que les instances de Supposition contiennent uniquement des valeurs entre 1 et 100. Nous pouvons écrire un test qui s’assure que la création d’une instance de Supposition avec une valeur en dehors de cette intervalle va faire paniquer le programme.
Nous allons vérifier cela en ajoutant l’attribut should_panic à notre fonction de test. Le test réussit si le code à l’intérieur de la fonction fait paniquer ; le test va échouer si le code à l’intérieur de la fonction ne panique pas.
L’encart 11-8 nous montre un test qui vérifie que les conditions d’erreur de Supposition::new fonctionne bien comme nous l’avons prévu.
pub struct Supposition {
valeur: i32,
}
impl Supposition {
pub fn new(valeur: i32) -> Supposition {
if valeur < 1 || valeur > 100 {
panic!("La valeur doit être comprise entre 1 and 100, on a {valeur}.");
}
Supposition { valeur }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn plus_grand_que_100() {
Supposition::new(200);
}
}panic!Nous plaçons l’attribut #[should_panic] après l’attribut #[test] et avant la fonction de test sur laquelle il s’applique. Voyons le résultat lorsque ce test réussit :
$ cargo test
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::plus_grand_que_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests jeu_du_plus_ou_du_moins
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ca fonctionne ! Maintenant, ajoutons un bogue dans notre code en enlevant la condition dans laquelle la fonction new panique lorsque la valeur est plus grande que 100 :
pub struct Supposition {
valeur: i32,
}
// -- partie masquée ici --
impl Supposition {
pub fn new(valeur: i32) -> Supposition {
if valeur < 1 {
panic!("La valeur doit être comprise entre 1 and 100, on a {valeur}.");
}
Supposition { valeur }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn plus_grand_que_100() {
Supposition::new(200);
}
}Lorsque nous lançons le test de l’encart 11-8, il va échouer :
$ cargo test
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::plus_grand_que_100 - should panic ... FAILED
failures:
---- tests::plus_grand_que_100 stdout ----
note: test did not panic as expected at src/lib.rs:21:8
failures:
tests::plus_grand_que_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Dans ce cas, nous n’obtenons pas de message très utile, mais lorsque nous regardons la fonction de test, nous constatons qu’elle est marquée avec #[should_panic]. L’échec que nous obtenons signifie que le code dans la fonction de test n’a pas fait paniquer.
Les tests qui utilisent should_panic ne sont parfois pas assez explicites. Un test should_panic peut réussir, même si le test panique pour une raison différente de celle que nous attendions. Pour rendre les tests should_panic plus précis, nous pouvons ajouter un paramètre optionnel expected à l’attribut should_panic. Le système de test va s’assurer que le message d’échec contient bien le texte renseigné. Par exemple, imaginons le code modifié de Supposition dans l’encart 11-9 où la fonction new panique avec des messages différents si la valeur est trop petite ou trop grande.
pub struct Supposition {
valeur: i32,
}
// -- partie masquée ici --
impl Supposition {
pub fn new(valeur: i32) -> Supposition {
if valeur < 1 {
panic!(
"La supposition doit être plus grande ou égale à 1, et nous avons {valeur}."
);
} else if valeur > 100 {
panic!(
"La supposition doit être plus petite ou égale à 100, et nous avons {valeur}."
);
}
Supposition { valeur }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "inférieur ou égal à 100")]
fn plus_grand_que_100() {
Supposition::new(200);
}
}panic! with a panic message containing a specified substringCe test va réussir car la valeur que nous insérons dans l’attribut expected de should_panic est une partie du message de panique de la fonction Supposition::new. Nous aurions pu renseigner le message de panique en entier que nous attendions, qui dans ce cas est La supposition doit être plus petite ou égale à 100, et nous avons 200.. Ce que vous choisissez de renseigner dépend de la mesure dans laquelle le message de panique est unique ou dynamique et de la précision de votre test que vous souhaitez appliquer. Dans ce cas, un extrait du message de panique est suffisant pour s’assurer que le code de la fonction de test s’exécute dans le cas du else if valeur > 100.
Pour voir ce qui se passe lorsqu’un test should_panic qui a un message expected qui échoue, essayons à nouveau d’introduire un bogue dans notre code en permutant les corps des blocs de if valeur < 1 et de else if valeur > 100 :
pub struct Supposition {
valeur: i32,
}
impl Supposition {
pub fn new(valeur: i32) -> Supposition {
if valeur < 1 {
panic!(
"La supposition doit être plus petite ou égale à 100, et nous avons {valeur}."
);
} else if valeur > 100 {
panic!(
"La supposition doit être plus grande ou égale à 1, et nous avons {valeur}."
);
}
Supposition { valeur }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "inférieur ou égal à 100")]
fn plus_grand_que_100() {
Supposition::new(200);
}
}Cette fois, lorsque nous lançons le test avec should_panic, il devrait échouer :
$ cargo test
Compiling jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::plus_grand_que_100 - should panic ... FAILED
failures:
---- tests::plus_grand_que_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
La supposition doit être plus grande ou égale à 1, et nous avons 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"La supposition doit être plus grande ou égale à 1, et nous avons 200."`,
expected substring: "inférieur ou égal à 100"
failures:
tests::plus_grand_que_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Le message d’échec nous informe que ce test a paniqué comme prévu, mais que le message de panique n’inclut pas la chaîne de caractères prévue 'inférieur ou égal à 100'. Le message de panique que nous avons obtenu dans ce cas était La supposition doit être plus grande ou égale à 1, et nous avons 200.. Maintenant, on comprend mieux où est le bogue !
Utiliser Result<T, E> dans les tests
Jusqu’ici, tous nos tests paniquent lorsqu’ils échouent. Nous pouvons également écrire des tests qui utilisent Result<T, E> ! Voici le test de l’encart 11-1, réécrit pour utiliser Result<T, E> et retourner une Err au lieu de paniquer :
pub fn additionne(gauche: u64, droite: u64) -> u64 {
gauche + droite
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn cela_fonctionne() -> Result<(), String> {
let resultat = additionne(2, 2);
if resultat == 4 {
Ok(())
} else {
Err(String::from("deux plus deux ne vaut pas quatre"))
}
}
}La fonction cela_fonctionne a maintenant le type de retour Result<(), String>. Dans le corps de la fonction, plutôt que d’appeler la macro assert_eq!, nous retournons Ok(()) lorsque le test réussit et une Err avec une String à l’intérieur lorsque le test échoue.
Écrire vos tests afin qu’ils retournent un Result<T, E> vous permet d’utiliser l’opérateur point d’interrogation dans le corps des tests, ce qui est un outil facile à utiliser pour écrire des tests qui peuvent échouer si n’importe quelle opération en son sein retourne une variante de Err.
Vous ne pouvez pas utiliser l’annotation #[should_panic] sur les tests qui utilisent Result<T, E>. Pour vérifier qu’une opération retourne une variante Err, n’utilisez pas l’opérateur “point d’interrogation” sur la valeur de type Result<T, E>. À la place, utilisez plutôt assert!(valeur.is_err()).
Maintenant que vous avez appris différentes manières d’écrire des tests, voyons ce qui se passe lorsque nous lançons nos tests et explorons les différentes options que nous pouvons utiliser avec cargo test.
Gérer l'exécution des tests
Gérer l’exécution des tests
Comme cargo run qui compile votre code et qui exécute ensuite le binaire qui en résulte, cargo test compile votre code en mode test et lance le binaire de tests qu’il produit. Le comportement par défaut des binaires produits par cargo test est de lancer tous les tests en parallèle et de capturer la sortie pendant l’exécution des tests, ce qui lui évite d’être affichée sur l’écran pendant ce temps, facilitant la lecture des messages relatifs aux résultats de l’exécution des tests. Vous pouvez cependant rajouter des options en ligne de commande pour changer ce comportement par défaut.“
Certaines options de la ligne de commande s’appliquent à cargo test, et certaines au binaire de tests qui en résulte. Pour séparer ces types d’arguments, il faut lister les arguments qui s’appliquent à cargo test, suivis du séparateur --, puis ajouter ceux qui s’appliquent au binaire de tests. L’exécution de cargo test --help affiche les options que vous pouvez utiliser sur cargo test, et l’exécution de cargo test -- --help affiche les options que vous pouvez utiliser après le séparateur --. Ces options sont également décrites dans la section “Tests” du Livre de rustc.
Lancer les tests en parallèle ou en séquence
Lorsque vous lancez de nombreux tests, par défaut ils s’exécutent en parallèle dans des tâches (fils d’exécution, ou threads), ce qui veut dire que tous les tests vont finir de s’exécuter plus rapidement, et que vous avez des retours plus tôt. Comme les tests s’exécutent en même temps, il faut vous assurer qu’ils ne dépendent pas les uns des autres ou d’un état partagé, y compris un environnement partagé, comme le répertoire de travail actuel ou des variables d’environnement.
Par exemple, disons que chacun de vos tests exécute du code qui crée un fichier test-sortie.txt sur le disque dur et qu’il écrit quelques données dans ce fichier. Ensuite, chaque test lit les données de ce fichier et vérifie que le fichier contient une valeur précise, qui est différente dans chaque test. Comme les tests sont lancés en même temps, un test risque d’écraser le contenu du fichier entre le moment où un autre test lit et écrit sur ce fichier. Le second test va ensuite échouer, non pas parce que le code est incorrect mais parce que les tests se sont perturbés mutuellement pendant qu’ils s’exécutaient en parallèle. Une solution serait de s’assurer que chaque test écrit dans un fichier différent ; une autre serait de lancer les tests les uns après les autres.
Si vous ne souhaitez pas exécuter les tests en parallèle ou si vous voulez un contrôle plus précis du nombre de tâches utilisées, vous pouvez utiliser l’option --test-threads suivie du nombre de tâches que vous souhaitez que le binaire de test exécute en parallèle. Regardez cet exemple :
$ cargo test -- --test-threads=1
Nous avons réglé le nombre de tâches à 1, ce qui indique au programme de ne pas utiliser le parallélisme. Exécuter ces tests en n’effectuant qu’une seule tâche à la fois va prendre plus de temps que de les lancer en parallèle, mais cela assure que les tests ne vont pas s’influencer mutuellement s’ils partagent le même état.
Afficher la sortie de la fonction
Par défaut, si un test réussit, la bibliothèque de test de Rust récupère tout ce qui est affiché sur la sortie standard. Par exemple, si nous appelons println! dans un test et que le test réussit, nous ne verrons pas la sortie correspondant au println! dans le terminal ; on verra seulement la ligne qui indique que le test a réussi. Si un test échoue, nous verrons ce qui a été affiché sur la sortie standard avec le reste des messages d’erreur.
Par exemple, l’encart 11-10 a une fonction stupide qui affiche la valeur de ses paramètres et retourne 10, ainsi qu’un test qui réussit et un test qui échoue.
fn affiche_et_retourne_10(a: i32) -> i32 {
println!("J'ai obtenu la valeur {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ce_test_reussit() {
let valeur = affiche_et_retourne_10(4);
assert_eq!(valeur, 10);
}
#[test]
fn ce_test_echoue() {
let valeur = affiche_et_retourne_10(8);
assert_eq!(valeur, 5);
}
}println!Lorsque nous lançons ces tests avec cargo test, nous voyons cette sortie :
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::ce_test_echoue ... FAILED
test tests::ce_test_reussit ... ok
failures:
---- tests::ce_test_echoue stdout ----
J'ai obtenu la valeur 8
thread 'tests::ce_test_echoue' panicked at src/lib.rs:19:9
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::ce_test_echoue
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Remarquez que nous n’avons jamais vu J'ai obtenu la valeur 4 dans cette sortie, qui est affichée lors de l’exécution du test qui réussit. Cette sortie a été capturée. La sortie pour le test qui a échoué, J'ai obtenu la valeur 8, s’affiche dans la section de la sortie correspondante au résumé des tests, qui affiche aussi les causes de l’échec du test.
Si nous voulons aussi voir les valeurs affichées pour les tests réussis, nous pouvons demander à Rust d’afficher également la sortie des tests fructueux en lui rajoutant --show-output.
$ cargo test -- --show-output
Lorsque nous lançons à nouveau les tests de l’encart 11-10 avec l’option --show-output, nous voyons la sortie suivante :
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::ce_test_echoue ... FAILED
test tests::ce_test_reussit ... ok
successes:
---- tests::ce_test_reussit stdout ----
J'ai obtenu la valeur 4
successes:
tests::ce_test_reussit
failures:
---- tests::ce_test_echoue stdout ----
J'ai obtenu la valeur 8
thread 'tests::ce_test_echoue' panicked at src/lib.rs:19:9
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::ce_test_echoue
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Exécuter un sous-ensemble de tests en fonction de son nom
Lancer une suite de tests entière peut parfois prendre beaucoup de temps. Si vous travaillez sur du code d’un périmètre bien défini, vous pourriez avoir besoin d’exécuter uniquement les tests relatifs à ce code. Vous pouvez choisir quels tests exécuter en envoyant le ou les noms du ou des tests que vous souhaitez exécuter en argument de cargo test.
Dans le but de démontrer comment lancer un sous-ensemble de tests, nous allons commencer par créer trois tests pour notre fonction ajouter_deux dans l’encart 11-11, et choisir lesquels nous allons exécuter.
pub fn ajouter_deux(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ajouter_deux_a_deux() {
let resultat = ajouter_deux(2);
assert_eq!(resultat, 4);
}
#[test]
fn ajouter_deux_a_trois() {
let resultat = ajouter_deux(3);
assert_eq!(resultat, 5);
}
#[test]
fn cent() {
let resultat = ajouter_deux(100);
assert_eq!(resultat, 102);
}
}Si nous exécutons les tests sans ajouter d’arguments, comme nous l’avons vu précédemment, tous les tests vont s’exécuter en parallèle :
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::ajouter_deux_a_trois ... ok
test tests::ajouter_deux_a_deux ... ok
test tests::cent ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Exécuter des tests individuellement
Nous pouvons donner le nom de n’importe quelle fonction de test à cargo test afin d’exécuter uniquement ce test :
$ cargo test cent
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::cent ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Le test avec le nom cent est le seul exécuté ; les deux autres tests ne correspondent pas à ce nom. La sortie du test nous indique que nous avons d’autres tests qui n’ont pas tourné en affichant 2 filtered out à la fin de la ligne de résumé.
Nous ne pouvons pas renseigner plusieurs noms de tests de cette manière ; il n’y a que la première valeur fournie à cargo test qui sera utilisée. Mais il existe un moyen d’exécuter plusieurs tests.
Filtrer pour exécuter plusieurs tests
Nous pouvons ne renseigner qu’une partie d’un nom de test, et tous les tests dont les noms correspondent à cette valeur vont être exécutés. Par exemple, comme deux de nos noms de tests contiennent ajouter, nous pouvons exécuter ces deux en lançant cargo test ajouter :
$ cargo test ajouter
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::ajouter_deux_a_trois ... ok
test tests::ajouter_deux_a_deux ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Cette commande a lancé tous les tests qui contiennent ajouter dans leur nom et a filtré le test cent. Notez aussi que le module dans lequel un test est présent fait partie du nom du test, ainsi nous pouvons exécuter tous les tests d’un module en filtrant avec le nom du module.
Ignorer des tests sauf s’ils sont demandés explicitement
Parfois, certains tests spécifiques peuvent prendre beaucoup de temps à s’exécuter, de sorte que vous voulez les exclure de la majorité des exécutions de cargo test. Plutôt que de lister en argument tous les tests que vous souhaitez exécuter, vous pouvez plutôt faire une annotation sur les tests qui prennent du temps en utilisant l’attribut ignore pour les exclure, comme ci-dessous :
Fichier : src/lib.rs
pub fn additionne(gauche: u64, droite: u64) -> u64 {
gauche + droite
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn cela_fonctionne() {
let resultat = additionne(2, 2);
assert_eq!(resultat, 4);
}
#[test]
#[ignore]
fn test_long() {
// du code qui prend une heure à s'exécuter
}
}Après #[test], nous avons ajouté la ligne #[ignore] pour le test que nous souhaitons exclure. Maintenant lorsque nous exécutons nos tests, it_works s’exécute, mais pas test_long :
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test test_long ... ignored
test tests::cela_fonctionne ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
La fonction test_long est listée comme ignored. Si nous voulons exécuter uniquement les tests ignorés, nous pouvons utiliser cargo test -- --ignored :
$ cargo test -- --ignored
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::test_long ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
En gérant quels tests sont exécutés, vous pouvez vous assurer que vos résultats de cargo test seront renvoyés rapidement. Lorsque vous arrivez à un stade où il est justifié de vérifier le résultat des tests ignored et que vous avez le temps d’attendre ces résultats, vous pouvez lancer à la place cargo test -- --ignored. Si vous voulez exécuter tous les tests, qu’ils soient ignorés ou non, vous pouvez lancer cargo test -- --include-ignored.
L'organisation des tests
L’organisation des tests
Comme nous l’avons évoqué au début du chapitre, le test est une discipline complexe, et différentes personnes utilisent des terminologies et organisations différentes. La communauté Rust a conçu les tests dans deux catégories principales : les tests unitaires et les tests d’intégration. Les tests unitaires sont petits et plus précis, testent un module isolé à la fois, et peuvent tester les interfaces privées. Les tests d’intégration sont uniquement externes à notre bibliothèque et consomment notre code exactement de la même manière que tout autre code externe le ferait, en utilisant uniquement l’interface publique et éventuellement en utilisant plusieurs modules dans un test.
L’écriture de ces deux types de tests est importante pour s’assurer que chaque élément de notre bibliothèque fait bien ce que vous attendez d’eux, de manière isolée et conjuguée avec d’autres.
Les tests unitaires
Le but des tests unitaires est de tester chaque élément du code de manière séparée du reste du code pour identifier rapidement où le code fonctionne ou non comme prévu. Vous devriez insérer les tests unitaires dans le répertoire src dans chaque fichier, à côté du code qu’ils testent. La convention est de créer un module tests dans chaque fichier qui contient les fonctions de test et de marquer le module avec cfg(test).
Les modules tests et #[cfg(test)]
L’annotation #[cfg(test)] sur les modules tests indique à Rust de compiler et d’exécuter le code de test seulement lorsque vous lancez cargo test, et non pas lorsque vous lancez cargo build. Cela diminue la durée de compilation lorsque vous souhaitez uniquement compiler la bibliothèque et cela réduit la taille dans l’artéfact compilé qui en résulte car les tests n’y sont pas intégrés. Vous verrez plus tard que comme les tests d’intégration se placent dans un répertoire différent, ils n’ont pas besoin de l’annotation #[cfg(test)]. Cependant, comme les tests unitaires vont dans les mêmes fichiers que le code, vous devriez utiliser #[cfg(test)] pour marquer qu’ils ne devraient pas être inclus dans les résultats de compilation.
Souvenez-vous, lorsque nous avons généré le nouveau projet addition dans la première section de ce chapitre, Cargo a généré ce code pour nous :
Fichier : src/lib.rs
pub fn additionne(gauche: u64, droite: u64) -> u64 {
gauche + droite
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn cela_fonctionne() {
let resultat = additionne(2, 2);
assert_eq!(resultat, 4);
}
}Dans le module tests généré automatiquement, l’attribut cfg est l’abréviation de configuration et indique à Rust que l’élément suivant ne doit être intégré que lorsqu’une certaine option de configuration est donnée. Dans ce cas, l’option de configuration est test, qui est fournie par Rust pour la compilation et l’exécution des tests. En utilisant l’attribut cfg, Cargo compile notre code de tests uniquement si nous avons exécuté les tests avec cargo test. Cela inclut toutes les fonctions auxiliaires qui pourraient se trouver dans ce module, en plus des fonctions marquées d’un #[test].
Tests de fonctions privées
Il existe un débat dans la communauté des testeurs au sujet de la nécessité ou non de tester directement les fonctions privées, et d’autres langages rendent difficile, voire impossible, de tester les fonctions privées. Quelle que soit votre approche des tests, les règles de protection de Rust vous permettent de tester des fonctions privées. Imaginons le code de l’encart 11-12 qui contient la fonction privée addition_interne.
pub fn ajouter_deux(a: u64) -> u64 {
addition_interne(a, 2)
}
fn addition_interne(gauche: u64, droite: u64) -> u64 {
gauche + droite
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn interne() {
let resultat = addition_interne(2, 2);
assert_eq!(resultat, 4);
}
}Remarquez que la fonction addition_interne n’est pas marquée comme pub. Les tests sont uniquement du code Rust, et le module test est simplement un autre module. Comme nous l’avons vu dans la section “Désigner un élément dans l’arborescence de modules”, les éléments dans les modules enfants peuvent utiliser les éléments dans leurs modules parents. Dans ce test, nous importons dans la portée tous les éléments appartenant au parent du module test grâce à use super::*;, permettant ensuite au test de faire appel à addition_interne. Si vous pensez qu’une fonction privée ne doit pas être testée, il n’y a rien qui vous y force avec Rust.
Les tests d’intégration
En Rust, les tests d’intégration sont exclusivement externes à votre bibliothèque. Ils consomment votre bibliothèque de la même manière que n’importe quel autre code, ce qui signifie qu’ils ne peuvent appeler que les fonctions qui font partie de l’interface de programmation applicative (API) publique de votre bibliothèque. Leur but est de tester si les multiples parties de votre bibliothèque fonctionnent correctement ensemble. Les portions de code qui fonctionnent bien toutes seules pourraient rencontrer des problèmes une fois imbriquées avec d’autres, donc les tests qui couvrent l’intégration du code sont tout aussi importants. Pour créer des tests d’intégration, vous avez d’abord besoin d’un répertoire tests.
Le répertoire tests
Nous créons un répertoire tests au niveau le plus haut de notre répertoire projet, juste à côté de src. Cargo sait qu’il doit rechercher les fichiers de test d’intégration dans ce répertoire. Nous pouvons ensuite y construire autant de fichiers de test que nous le souhaitons, et Cargo va compiler chacun de ces fichiers comme une crate individuelle.
Commençons à créer un test d’intégration. Avec le code de l’encart 11-12 toujours présent dans le fichier src/lib.rs, créez un répertoire tests, puis un nouveau fichier tests/test_integration.rs et insérez-y le code de l’encart 11-13. Votre structure de répertoires doit ressembler à ceci :
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Entrez le code de l’encart 11-13 dans le fichier tests/integration_test.rs.
use addition::ajouter_deux;
#[test]
fn cela_ajoute_deux() {
let resultat = ajouter_deux(2);
assert_eq!(resultat, 4);
}adder crateChaque fichier dans le répertoire tests est une crate séparée, donc nous devons importer notre bibliothèque dans la portée de chaque crate de test. Pour cette raison, nous avons ajouté use addition en haut du code, ce que nous n’avions pas besoin de faire dans les tests unitaires.
Nous n’avons pas besoin de marquer du code avec #[cfg(test)] dans tests/test_integration.rs. Cargo traite le répertoire tests de manière particulière et compile les fichiers présents dans ce répertoire uniquement si nous lançons cargo test. Lancez dès maintenant cargo test :
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::interne ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test cela_ajoute_deux ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Les trois sections de la sortie concernent les tests unitaires, les tests d’intégration et les tests de documentation. Notez que si le moindre test d’une section échoue, les sections suivantes ne seront pas exécutées. Par exemple, si un test unitaire échoue, il n’y aura aucun résultat pour les tests d’intégration et les tests de documentation, car ces tests ne sont exécutés que si tous les tests unitaires ont réussi.
La première section relative aux tests unitaires est la même que celle que nous avons déjà vue : une ligne pour chaque test unitaire (celui qui s’appelle interne que nous avons inséré dans l’encart 11-12) suivie d’une ligne de résumé des tests unitaires.
La section des tests d’intégration commence avec la ligne Running tests/integration_test.rs. Ensuite, il y a une ligne pour chaque fonction de test présente dans ce test d’intégration et une ligne de résumé pour les résultats des tests d’intégration, juste avant que la section Doc-tests addition ne commence.
Chaque test d’intégration a sa propre section ; ainsi si nous ajoutons d’autres fichiers dans le répertoire tests, il y aura plus de sections de tests d’intégration.
Nous pouvons toujours exécuter une fonction de test d’intégration précise en utilisant le nom de la fonction de test comme argument à cargo test. Pour exécuter tous les tests d’un fichier de tests d’intégration précis, utilisez l’argument --test de cargo test suivi du nom du fichier :
$ cargo test --test integration_test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test cela_ajoute_deux ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cette commande exécute seulement les tests dans le fichier tests/test_integration.rs.
Les sous-modules des tests d’intégration
Au fur et à mesure que vous ajouterez des tests d’intégration, vous pourriez avoir besoin de les diviser en plusieurs fichiers dans le répertoire tests pour vous aider à les organiser. Comme mentionné précédemment, chaque fichier dans le répertoire tests est compilé comme étant sa propre crate séparée de toutes les autres, ce qui est utile pour créer des portées séparées qui imitent mieux la manière dont les développeurs vont utiliser votre crate. Cependant, cela veut aussi dire que les fichiers dans le répertoire tests ne partagent pas le même comportement que les fichiers dans src, comme vous l’avez appris au chapitre 7 à propos de la manière de séparer le code dans des modules et des fichiers.
Le comportement différent des fichiers dans le répertoire tests est encore plus notable lorsque vous avez un jeu de fonctions d’aide à utiliser dans plusieurs fichiers de test d’intégration et que vous essayez de suivre les étapes de la section “Séparer les modules dans différents fichiers” du chapitre 7 afin de les extraire dans un module en commun. Par exemple, si nous créons tests/commun.rs et que nous y plaçons une fonction parametrage à l’intérieur, nous pourrions ajouter du code à parametrage que nous voudrions appeler à partir de différentes fonctions de test dans différents fichiers de test :
Fichier : tests/commun.rs
pub fn setup() {
// code de paramétrage spécifique à vos tests de votre bibliothèque ici
}Lorsque nous lançons les tests à nouveau, nous allons voir une nouvelle section dans la sortie des tests, correspondant au fichier commun.rs, même si ce fichier ne contient aucune fonction de test et que nous n’avons utilisé nulle part la fonction parametrage :
$ cargo test
Compiling addition v0.1.0 (file:///projects/addition)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::interne ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/commun.rs (target/debug/deps/commun-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test cela_ajoute_deux ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addition
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Nous ne voulons pas que commun apparaisse dans les résultats, ni que cela affiche running 0 tests. Nous voulons juste partager du code avec les autres fichiers de test d’intégration. Pour éviter que commun s’affiche sur la sortie de test, au lieu de créer le fichier tests/commun.rs, nous allons créer tests/commun/mod.rs. Le répertoire du projet ressemble maintenant à ceci :
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── commun
│ └── mod.rs
└── integration_test.rs
C’est là l’ancienne convention de nommage que Rust comprend, que nous avons mentionnée dans “Séparer les modules dans différents fichiers” au chapitre 7. Nommer le fichier ainsi indique à Rust de ne pas traiter le module commun comme un fichier de test d’intégration. Lorsque nous déplaçons le code de la fonction parametrage dans tests/commun/mod.rs et que nous supprimons le fichier tests/commun.rs, la section dans la sortie des tests ne va plus s’afficher. Les fichiers dans les sous-répertoires du répertoire tests ne seront pas compilés comme étant une crate séparée et n’auront pas de sections dans la sortie des tests.
Après avoir créé tests/commun/mod.rs, nous pouvons l’utiliser à partir de n’importe quel fichier de test d’intégration comme un module. Voici un exemple d’appel à la fonction parametrage à partir du test cela_ajoute_deux dans tests/test_integration.rs :
Filename: tests/integration_test.rs
use addition::ajouter_deux;
mod commun;
#[test]
fn cela_ajoute_deux() {
commun::parametrage();
let resultat = ajouter_deux(2);
assert_eq!(resultat, 4);
}Remarquez que la déclaration mod commun; est la même que la déclaration d’un module que nous avons montrée dans l’encart 7-21. Ensuite, dans la fonction de tests, nous pouvons appeler la fonction commun::parametrage.
Tests d’intégration pour les crates binaires
Si notre projet est une crate binaire qui contient uniquement un fichier src/main.rs et n’a pas de fichier src/lib.rs, nous ne pouvons pas créer de tests d’intégration dans le répertoire tests et importer les fonctions définies dans le fichier src/main.rs dans notre portée avec une instruction use. Seules les crates de bibliothèque exposent des fonctions que les autres crates peuvent utiliser ; les crates binaires sont conçues pour être exécutées de manière isolée.
C’est une des raisons pour lesquelles les projets Rust qui fournissent un binaire ont un simple fichier src/main.rs qui fait appel à la logique présente dans le fichier src/lib.rs. En utilisant cette structure, les tests d’intégration peuvent tester la crate de bibliothèque avec le use pour pouvoir accéder à la fonctionnalité importante. Si la fonctionnalité importante fonctionne, la petite portion de code dans le fichier src/main.rs va fonctionner, et cette petite partie de code n’a pas besoin d’être testée.
Résumé
Les fonctionnalités de test de Rust permettent de spécifier comment le code doit fonctionner pour garantir qu’il va continuer à fonctionner comme vous le souhaitez, même si vous faites des changements. Les tests unitaires permettent de tester séparément différentes parties d’une bibliothèque et peuvent tester l’implémentation des éléments privés. Les tests d’intégration vérifient que de nombreuses parties de la bibliothèque fonctionnent correctement ensemble, et ils utilisent l’API publique de la bibliothèque pour tester le code, de la même manière que le ferait du code externe qui l’utiliserait. Même si le système de type de Rust et les règles de possession aident à empêcher certains types de bogues, les tests restent toujours importants pour réduire les bogues de logique concernant le comportement attendu de votre code.
Et maintenant, combinons le savoir que vous avez accumulé dans ce chapitre et dans les chapitres précédents en travaillant sur un nouveau projet !
Un projet d’entrée/sortie : construire un programme en ligne de commande
Ce chapitre est un résumé de toutes les nombreuses compétences que vous avez apprises précédemment et une découverte de quelques fonctionnalités supplémentaires de la bibliothèque standard. Nous allons construire un outil en ligne de commande qui interagit avec des fichiers et les entrées/sorties de la ligne de commande pour mettre en pratique certains concepts Rust dont vous avez maintenant connaissance.
Sa rapiditié, ses fonctionnalités de sécurité, sa sortie binaire unifiée et sa prise en charge de multiples plateformes font de Rust le langage idéal pour créer des outils en ligne de commande, donc pour notre projet, nous allons construire notre version de l’outil de recherche en ligne de commande grep (qui signifie globally search a regular expression and print, soit recherche globale et affichage d’une expression régulière). Dans des cas d’usage très simples, grep recherche une chaîne de caractères précise dans un fichier précis. Pour ce faire, grep prend en argument un chemin de nom de fichier et une chaîne de caractères. Ensuite, il lit le fichier, trouve les lignes de ce fichier qui contiennent la chaîne de caractères passée en argument, puis affiche ces lignes.
En chemin, nous allons vous montrer comment faire en sorte que notre outil en ligne de commande utilise les fonctionnalités du terminal que de nombreux outils en ligne de commande utilisent. Nous allons lire la valeur d’une variable d’environnement pour permettre à l’utilisateur de configurer le comportement de notre outil. Nous allons aussi afficher des messages d’erreur vers le flux d’erreur standard de la console (stderr) plutôt que vers la sortie standard (stdout), pour, par exemple, que l’utilisateur puisse rediriger la sortie fructueuse vers un fichier, tout en affichant les messages d’erreur à l’écran.
Un membre de la communauté Rust, Andrew Gallant, a déjà créé une version complète et très performante de grep, qu’il a appelée ripgrep. En comparaison, notre version de grep sera plutôt simple, mais ce chapitre va vous donner les connaissances de base dont vous avez besoin pour appréhender un projet réel comme ripgrep.
Notre projet grep va combiner un certain nombre de concepts que vous avez déjà acquis à ce stade :
- Organiser le code (en utilisant ce que vous avez appris sur les modules au chapitre 7)
- Utiliser les vecteurs et les chaînes de caractères (les collections du chapitre 8)
- Gérer les erreurs (chapitre 9)
- Utiliser les traits et les durées de vie lorsque c’est approprié (chapitre 10)
- Écrire les tests (chapitre 11)
Nous vous présenterons aussi brièvement les fermetures, les itérateurs et les objets de trait, que le chapitre 13 et le chapitre 17 traiteront en détail.
Récupérer les arguments de la ligne de commande
Récupérer les arguments de la ligne de commande
Créons un nouveau projet comme à l’accoutumée avec cargo new. Appelons notre projet minigrep pour le distinguer de l’outil grep que vous avez probablement déjà sur votre système :
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
La première tâche est de faire en sorte que minigrep utilise ses deux arguments en ligne de commande : le chemin avec le nom du fichier et la chaîne de caractères à rechercher. Autrement dit, nous voulons pouvoir exécuter notre programme avec cargo run, deux tirets pour indiquer que les arguments suivants sont pour notre programme et non pas pour cargo, une chaîne de caractères à rechercher, et un chemin vers un fichier dans lequel chercher, comme ceci :
$ cargo run -- chaine_a_chercher fichier-exemple.txt
Pour l’instant, le programme généré par cargo new ne peut pas traiter les arguments que nous lui donnons. Certaines bibliothèques qui existent sur crates.io peuvent vous aider à écrire un programme qui prend des arguments en ligne de commande, mais comme vous apprenez juste ce concept, implémentons cette capacité par nous-mêmes.
Lire les valeurs des arguments
Pour permettre à minigrep de lire les valeurs des arguments de la ligne de commande que nous lui envoyons, nous allons avoir besoin de la fonction std::env::args fournie par la bibliothèque standard de Rust. Cette fonction retourne un itérateur des arguments de la ligne de commande qui ont été donnés à minigrep. Nous verrons les itérateurs plus précisément au chapitre 13. Pour l’instant, vous avez juste à savoir deux choses à propos des itérateurs : les itérateurs engendrent une série de valeurs, et nous pouvons appeler la méthode collect sur un itérateur pour le transformer en collection, comme les vecteurs, qui contient tous les éléments qu’un itérateur engendre.
Le code de l’encart 12-1 permet à votre programme minigrep de lire tous les arguments qui lui sont envoyés et ensuite collecter les valeurs dans un vecteur.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
dbg!(args);
}D’abord, nous importons le module std::env dans la portée avec une instruction use afin que nous puissions utiliser sa fonction args. Notez que la fonction std::env::args est imbriquée sur deux niveaux de modules. Comme nous l’avons vu dans le chapitre 7, il est courant d’importer le module parent dans la portée plutôt que la fonction. En faisant ainsi, nous pouvons facilement utiliser les autres fonctions de std::env. C’est aussi moins ambigu que d’importer uniquement std::env::args et ensuite d’appeler la fonction avec seulement args, car args peut facilement être confondu avec une fonction qui est définie dans le module courant.
La fonction args et l’unicode invalide
Notez que std::env::args va paniquer si un des arguments contient de l’unicode invalide. Si votre programme a besoin d’utiliser des arguments qui contiennent de l’unicode invalide, utilisez plutôt std::env::args_os à la place. Cette fonction retourne un itérateur qui engendre des valeurs OsString plutôt que des valeurs String. Nous avons choisi d’utiliser ici std::env::args par simplicité, car les valeurs OsString diffèrent selon la plateforme et qu’elles sont plus complexes à traiter que les valeurs de type String.
Dans la première ligne du main, nous appelons env::args, et nous utilisons immédiatement collect pour retourner un itérateur dans un vecteur qui contient toutes les valeurs engendrées par l’itérateur. Nous pouvons utiliser la fonction collect pour créer n’importe quel genre de collection, donc nous avons annoté explicitement le type de args pour préciser que nous attendions un vecteur de chaînes de caractères. Bien que nous n’ayons que très rarement besoin d’annoter les types en Rust, collect est une fonction que vous aurez souvent besoin d’annoter car Rust n’est pas capable de déduire le type de collection que vous attendez.
Enfin, nous affichons le vecteur en utilisant la macro debug. Essayons d’abord de lancer le code sans arguments, puis ensuite avec deux arguments :
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- aiguille botte_de_foin
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep aiguille botte_de_foin`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"aiguille",
"botte_de_foin",
]
Remarquez que la première valeur dans le vecteur est "target/debug/minigrep", qui est le nom de notre binaire. Cela correspond au fonctionnement de la liste d’arguments en C, qui laissent les programmes utiliser le nom sous lequel ils ont été invoqués dans leur exécution. C’est parfois pratique pour avoir accès au nom du programme dans le cas où vous souhaitez l’afficher dans des messages, ou changer le comportement du programme en fonction de ce que l’alias de la ligne de commande utilise pour invoquer le programme. Mais pour les besoins de ce chapitre, nous allons l’ignorer et récupérer uniquement les deux arguments dont nous avons besoin.
Enregistrer les valeurs des arguments dans des variables
Le programme peut avoir accès aux valeurs envoyées en arguments d’une ligne de commande. Maintenant, nous avons besoin d’enregistrer les valeurs des deux arguments dans des variables afin que nous puissions utiliser les valeurs pour le reste du programme. C’est que nous faisons dans l’encart 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let recherche = &args[1];
let chemin_fichier = &args[2];
println!("On recherche : {recherche}");
println!("Dans le fichier : {chemin_fichier}");
}Comme nous l’avons vu lorsque nous avons affiché le vecteur, le nom du programme prend la première valeur dans le vecteur, dans args[0], donc nous allons commencer les arguments à l’indice 1. Le premier argument que prend minigrep est la chaîne de caractères que nous recherchons, donc nous insérons la référence vers le premier argument dans la variable recherche. Le second argument sera le chemin d’accès avec le nom du fichier, donc nous insérons une référence vers le second argument dans la variable chemin_fichier.
Nous affichons temporairement les valeurs de ces variables pour prouver que le code fonctionne bien comme nous le souhaitons. Lançons à nouveau ce programme avec les arguments test et example.txt :
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test exemple.txt`
On recherche : test
Dans le fichier : exemple.txt
Très bien, notre programme fonctionne ! Les valeurs des arguments dont nous avons besoin sont enregistrées dans les bonnes variables. Plus tard, nous allons ajouter de la gestion d’erreurs pour pallier aux potentielles situations d’erreurs, comme lorsque l’utilisateur ne fournit pas d’arguments ; pour le moment, nous allons ignorer ces situations et continuer à travailler pour l’ajout d’une capacité de lecture de fichier, à la place.
Lire un fichier
Lire un fichier
Maintenant, nous allons ajouter une fonctionnalité pour lire le fichier qui est renseigné dans l’argument chemin_fichier. D’abord, nous avons besoin d’un fichier d’exemple pour le tester : nous utiliserons un fichier avec une petite quantité de texte sur plusieurs lignes avec quelques mots répétés. L’encart 12-3 présente un poème en Anglais de Emily Dickinson qui fonctionnera bien pour ce test ! Créez un fichier poem.txt à la racine de votre projet, et saisissez ce poème “I’m Nobody! Who are you?”.
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Une fois ce texte enregistré, éditez le src/main.rs et ajoutez-y le code pour lire le fichier, comme indiqué dans l’encart 12-4.
use std::env;
use std::fs;
fn main() {
// -- partie masquée ici --
let args: Vec<String> = env::args().collect();
let recherche = &args[1];
let chemin_fichier = &args[2];
println!("On recherche : {recherche}");
println!("Dans le fichier : {chemin_fichier}");
let contenu = fs::read_to_string(chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
println!("Dans le texte :\n{contenu}");
}Premièrement, nous importons une partie significative de la bibliothèque standard avec une instruction use : nous avons besoin de std::fs pour manipuler les fichiers.
Dans le main, la nouvelle instruction fs::read_to_string prend le chemin_fichier, ouvre ce fichier, et retourne un Result<String> du contenu du fichier.
Après cela, nous ajoutons à nouveau une instruction println! qui affiche la valeur de contenu après la lecture de ce fichier, afin que nous puissions vérifier que ce programme fonctionne correctement.
Exécutons ce code avec n’importe quelle chaîne de caractères dans le premier argument de la ligne de commande (car nous n’avons pas encore implémenté la partie de recherche pour l’instant), ainsi que le fichier poem.txt en second argument :
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
On recherche : the
Dans le fichier : poem.txt
Dans le texte :
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Très bien ! Notre code a lu et a ensuite affiché le contenu du fichier. Mais le code a quelques défauts. En cet instant, la fonction main a plusieurs responsabilités : généralement, les fonctions sont plus claires et faciles à maintenir si chaque fonction est en charge d’une seule tâche. L’autre problème est que nous ne gérons pas les erreurs correctement. Le programme est encore très modeste, donc ces imperfections ne sont pas un gros problème, mais dès que le programme va grossir, il sera plus difficile de les corriger proprement. Le remaniement du code très tôt lors du développement d’un logiciel est une bonne pratique, car c’est beaucoup plus facile de remanier des petites portions de code. C’est ce que nous allons faire dès maintenant.
Remanier le code pour améliorer sa modularité et la gestion des erreurs
Remanier le code pour améliorer sa modularité et la gestion des erreurs
Pour améliorer notre programme, nous allons résoudre quatre problèmes liés à la structure du programme et à la façon dont il gère de potentielles erreurs. Premièrement, notre fonction main assure deux tâches : elle interprète les arguments et elle lit des fichiers. Au fur et à mesure que notre programme grossit, le nombre des différentes tâches qu’assure la fonction main va continuer à s’agrandir. Plus une fonction assure des tâches différentes, plus cela devient difficile de la comprendre, de la tester, et d’y faire des changements sans casser ses autres constituants. Il est largement préférable de séparer les fonctionnalités afin que chaque fonction n’assure qu’une seule tâche.
Cette problématique est aussi liée au deuxième problème : bien que recherche et chemin_fichier soient des variables de configuration de notre programme, les variables telles que contenu sont utilisées pour appuyer la logique du programme. Plus main est grand, plus nous aurons des variables à importer dans la portée ; plus nous avons des variables dans notre portée, plus il sera difficile de se souvenir à quoi elles servent. Il est préférable de regrouper les variables de configuration dans une structure pour clarifier leur usage.
Le troisième problème est que nous avons utilisé expect pour afficher un message d’erreur lorsque la lecture du fichier échoue, mais le message affiche uniquement Quelque chose s'est mal passé lors de la lecture du fichier. Lire un fichier peut échouer pour de nombreuses raisons : par exemple, le fichier peut ne pas exister, ou parce que nous n’avons pas le droit de l’ouvrir. Pour le moment, quelle que soit la raison, nous affichons le même message d’erreur pour tout, ce qui ne donne aucune information à l’utilisateur !
Quatrièmement, nous utilisons expect pour gérer une erreur, et si l’utilisateur lance notre programme sans renseigner d’arguments, il va avoir une erreur index out of bounds provenant de Rust, qui n’explique pas clairement le problème. Il serait plus judicieux que tout le code de gestion des erreurs se trouve au même endroit afin que les futurs mainteneurs n’aient qu’un seul endroit à consulter dans le code si la logique de gestion des erreurs doit être modifiée. Avoir tout le code de gestion des erreurs dans un seul endroit va aussi garantir que nous affichons des messages qui ont du sens pour les utilisateurs.
Corrigeons ces quatre problèmes en remaniant notre projet.
Séparation des tâches des projets de binaires
Le problème de l’organisation de la répartition des tâches multiples dans la fonction main est commun à de nombreux projets binaires. En conséquence, de nombreux développeurs Rust trouvent utile de séparer les tâches d’un programme binaire lorsque main commence à grossir. Ce processus se décompose selon les étapes suivantes :
- Diviser votre programme dans un fichier main.rs et un fichier lib.rs et déplacer la logique de votre programme dans lib.rs.
- Tant que votre logique d’interprétation de la ligne de commande reste petite, elle peut rester dans la fonction
main. - Lorsque la logique d’interprétation de la ligne de commande commence à devenir compliquée, il faut la déplacer de la fonction
mainvers d’autres fonctions ou types.
Les fonctionnalités qui restent dans la fonction main après cette procédure seront les suivantes :
- Appeler la logique d’interprétation de ligne de commande avec les valeurs des arguments
- Régler toutes les autres configurations
- Appeler une fonction
runde lib.rs - Gérer l’erreur si
runretourne une erreur
Cette méthode permet de séparer les responsabilités : main.rs se charge de lancer le programme, et lib.rs renferme toute la logique des tâches à accomplir. Comme vous ne pouvez pas directement tester la fonction main, cette structure vous permet de tester toute la logique de votre programme en la déplaçant en-dehors de la fonction main. Le seul code qui restera dans la fonction mainsera suffisamment petit pour s’assurer qu’il soit correct en le lisant. Lançons-nous dans le remaniement de notre programme en suivant cette procédure.
Extraction de l’interpréteur des arguments
Nous allons déplacer la fonctionnalité de l’interprétation des arguments dans une fonction que main va appeler. L’encart 12-5 montre le nouveau début de la fonction main qui appelle une nouvelle fonction interpreter_config, que nous allons définir dans src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (recherche, chemin_fichier) = interpreter_config(&args);
// -- partie masquée ici --
println!("On recherche : {recherche}");
println!("Dans le fichier : {chemin_fichier}");
let contenu = fs::read_to_string(chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
println!("Dans le texte :\n{contenu}");
}
fn interpreter_config(args: &[String]) -> (&str, &str) {
let recherche = &args[1];
let chemin_fichier = &args[2];
(recherche, chemin_fichier)
}parse_config function from mainNous continuons à récupérer les arguments de la ligne de commande dans un vecteur, mais au lieu d’assigner la valeur de l’argument d’indice 1 à la variable recherche et la valeur de l’argument d’indice 2 à la variable chemin_fichier dans la fonction main, nous passons le vecteur entier à la fonction interpreter_config. La fonction interpreter_config renferme la logique qui détermine quel argument va dans quelle variable et renvoie les valeurs au main. Nous continuons à créer les variables recherche et chemin_fichier dans le main, mais main n’a plus la responsabilité de déterminer quelles sont les variables qui correspondent aux arguments de la ligne de commande.
Ce remaniement peut sembler excessif pour notre petit programme, mais nous remanions de manière incrémentale par de petites étapes. Après avoir fait ces changements, lancez à nouveau le programme pour vérifier que l’envoi des arguments fonctionne toujours. C’est une bonne chose de vérifier souvent lorsque vous avancez, pour vous aider à mieux identifier les causes de problèmes lorsqu’ils apparaissent.
Grouper les valeurs de configuration
Nous pouvons appliquer une nouvelle petite étape pour améliorer la fonction interpreter_config. Pour le moment, nous retournons un tuple, mais ensuite nous divisons immédiatement ce tuple à nouveau en plusieurs éléments. C’est un signe que nous n’avons peut-être pas la bonne approche.
Un autre signe qui indique qu’il y a encore de la place pour de l’amélioration est la partie config de interpreter_config qui sous-entend que les deux valeurs que nous retournons sont liées et font partie d’une même valeur de configuration. Or, à ce stade, nous ne tenons pas compte de cela dans la structure des données que nous utilisons si ce n’est en regroupant les deux valeurs dans un tuple ; à la place, nous mettrons les deux valeurs dans une seule structure et donnerons un nom significatif à chacun des champs de la structure. Faire ainsi permet de faciliter la compréhension du code par les futurs développeurs de ce code pour mettre en évidence le lien entre les deux valeurs et leurs rôles respectifs.
L’encart 12-6 montre les améliorations apportées à la fonction interpreter_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = interpreter_config(&args);
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
let contenu = fs::read_to_string(config.chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
// -- partie masquée ici --
println!("Dans le texte :\n{contenu}");
}
struct Config {
recherche: String,
chemin_fichier: String,
}
fn interpreter_config(args: &[String]) -> Config {
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Config { recherche, chemin_fichier }
}parse_config to return an instance of a Config structNous avons ajouté une structure Config qui a deux champs recherche et chemin_fichier. La signature de interpreter_config indique maintenant qu’elle retourne une valeur Config. Dans le corps de interpreter_config, où nous retournions une slice de chaînes de caractères qui pointaient sur des valeurs String présentes dans args, nous définissons maintenant la structure Config pour contenir des valeurs String qu’elle possède. La variable args du main est la propriétaire des valeurs des arguments et permet uniquement à la fonction interpreter_config de les emprunter, ce qui signifie que nous violons les règles d’emprunt de Rust si Config essaye de prendre possession des valeurs provenant de args.
Il y a plusieurs manières de gérer les données String, mais la façon la plus facile, bien que non optimisée, est d’appeler la méthode clone sur les valeurs. Cela va produire une copie complète des données pour que l’instance de Config puisse se les approprier, ce qui va prendre plus de temps et de mémoire que de stocker une référence vers les données de la chaîne de caractères. Cependant le clonage des données rend votre code très simple car nous n’avons pas à gérer les durées de vie des références ; dans ces circonstances, sacrifier un peu de performances pour gagner en simplicité est un compromis qui en vaut la peine.
Les contreparties de l’utilisation de clone
Il y a une tendance chez les Rustacés de s’interdire l’utilisation de clone pour régler les problèmes d’appartenance à cause de son coût à l’exécution. Dans le chapitre 13, vous allez apprendre à utiliser des méthodes plus efficaces dans ce genre de situation. Mais pour le moment, ce n’est pas un problème de copier quelques chaînes de caractères pour continuer à progresser car vous allez le faire une seule fois et les chaînes de caractères chemin_fichier et recherche sont très courtes. Il est plus important d’avoir un programme fonctionnel qui n’est pas très optimisé plutôt que d’essayer d’optimiser à outrance le code dès sa première écriture. Plus vous deviendrez expérimenté en Rust, plus il sera facile de commencer par la solution la plus performante, mais pour le moment, il est parfaitement acceptable de faire appel à clone.
Nous avons actualisé main pour qu’il utilise l’instance de Config retournée par interpreter_config dans une variable config, et nous avons rafraîchi le code qui utilisait les variables séparées recherche et chemin_fichier pour qu’il utilise maintenant les champs de la structure Config à la place.
Maintenant, notre code indique clairement que recherche et chemin_fichier sont reliés et que leur but est de configurer le fonctionnement du programme. N’importe quel code qui utilise ces valeurs sait comment les retrouver dans les champs de l’instance config grâce à leurs noms donnés à cet effet.
Créer un constructeur pour Config
Pour l’instant, nous avons extrait la logique en charge d’interpréter les arguments de la ligne de commande à partir du main et nous l’avons placé dans la fonction interpreter_config. Cela nous a aidé à découvrir que les valeurs recherche et chemin_fichier étaient liées et que ce lien devait être retranscrit dans notre code. Nous avons ensuite créé une structure Config afin de donner un nom au rôle apparenté à recherche et à chemin_fichier, et pour pouvoir retourner les noms des valeurs sous la forme de noms de champs à partir de la fonction interpreter_config.
Maintenant que le but de la fonction interpreter_config est de créer une instance de Config, nous pouvons transformer interpreter_config d’une simple fonction à une fonction new qui est associée à la structure Config. Ce changement rendra le code plus familier. Habituellement, nous créons des instances de types de la bibliothèque standard, comme String, en appelant String::new. Si on change le interpreter_config en une fonction new associée à Config, nous pourrons créer de la même façon des instances de Config en appelant Config::new. L’encart 12-7 nous montre les changements que nous devons faire pour cela.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
let contenu = fs::read_to_string(config.chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
println!("Dans le texte :\n{contenu}");
// -- partie masquée ici --
}
// -- partie masquée ici --
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Config { recherche, chemin_fichier }
}
}parse_config into Config::newNous avons actualisé le main où nous appelions interpreter_config pour appeler à la place le Config::new. Nous avons changé le nom de interpreter_config par new et nous l’avons déplacé dans un bloc impl, ce qui relie la fonction new à Config. Essayez à nouveau de compiler ce code pour vous assurer qu’il fonctionne.
Corriger la gestion des erreurs
Maintenant, nous allons nous pencher sur la correction de la gestion des erreurs. Rappellez-vous que la tentative d’accéder aux valeurs dans le vecteur args aux indices 1 ou 2 va faire paniquer le programme si le vecteur contient moins de trois éléments. Essayez de lancer le programme sans aucun argument ; cela donnera quelque chose comme ceci :
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
La ligne index out of bounds: the len is 1 but the index is 1 est un message d’erreur destiné aux développeurs. Il n’aidera pas nos utilisateurs finaux à comprendre ce qu’ils devraient faire à la place. Corrigeons cela dès maintenant.
Améliorer le message d’erreur
Dans l’encart 12-8, nous ajoutons une vérification dans la fonction new, qui va vérifier que le slice est suffisamment grand avant d’accéder aux indices 1 et 2. Si le slice n’est pas suffisamment grand, le programme va paniquer et afficher un meilleur message d’erreur.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
let contenu = fs::read_to_string(config.chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
println!("Dans le texte :\n{contenu}");
}
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
// -- partie masquée ici --
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("il n'y a pas assez d'arguments");
}
// -- partie masquée ici --
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Config { recherche, chemin_fichier }
}
}Ce code est similaire à la fonction Supposition::new que nous avons écrite dans l’encart 9-13, dans laquelle nous appelions panic! lorsque l’argument valeur était hors de l’intervalle des valeurs valides. Plutôt que de vérifier un intervalle de valeurs dans le cas présent, nous vérifions que la taille de args est au moins de 3 et que le reste de la fonction puisse fonctionner en s’appuyant sur l’affirmation que cette condition a bien été remplie. Si args avait moins de trois éléments, cette condition serait true, et nous appellerions alors la macro panic! pour mettre fin au programme immédiatement.
Avec ces quelques lignes de code en plus dans new, lançons le programme sans aucun argument à nouveau pour voir à quoi ressemble désormais l’erreur :
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
il n'y a pas assez d'arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Cette sortie est meilleure : nous avons maintenant un message d’erreur compréhensible. Cependant, nous avons aussi des informations superflues que nous ne souhaitons pas afficher à nos utilisateurs. Peut-être que la technique que nous avons utilisée dans l’encart 9-13 n’est pas la plus appropriée dans ce cas : un appel à panic! est plus approprié pour un problème de développement qu’un problème d’utilisation, comme nous l’avons appris au chapitre 9. À la place, nous pourrions utiliser une autre technique que vous avez apprise au chapitre 9 — retourner un Result qui indique si c’est un succès ou une erreur.
Retourner un Result plutôt que d’appeler panic!
Nous pouvons à la place retourner une valeur Result qui contiendra une instance de Config dans le cas d’un succès et va décrire le problème dans le cas d’une erreur. Nous allons aussi changer le nom de la fonction de new à build car de nombreux programmeurs s’attendent à ce que les fonctions new n’échouent jamais. Lorsque Config::build communiquera avec main, nous pourrons utiliser le type de Result pour signaler où il y a un problème. Ensuite, nous pourrons changer le main pour convertir une variante de Err dans une erreur plus pratique pour nos utilisateurs sans avoir le texte à propos de thread 'main' et de RUST_BACKTRACE qui sont provoqués par l’appel à panic!.
L’encart 12-9 montre les changements que nous devons apporter à la valeur de retour de la fonction que nous appelons maintenant Config::build, ainsi qu’au le corps de la fonction pour pouvoir retourner un Result. Notez que cela ne va pas se compiler tant que nous ne corrigeons pas aussi main, ce que nous allons faire dans le prochain encart.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
let contenu = fs::read_to_string(config.chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
println!("Dans le texte :\n{contenu}");
}
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}Result from Config::buildNotre fonction build retourne un Result contenant une instance de Config dans le cas d’un succès et un littéral de chaîne de caractères dans le cas d’une erreur. Nos valeurs d’erreur seront toujours des littéraux de chaîne de caractères qui ont la durée de vie 'static.
Nous avons fait deux changements dans le corps de notre fonction : plutôt que d’avoir à appeler panic! lorsque l’utilisateur n’envoie pas assez d’arguments, nous retournons maintenant une valeur Err, et nous avons intégré la valeur de retour Config dans un Ok. Ces modifications rendent la fonction conforme à son nouveau type de signature.
Retourner une valeur Err à partir de Config::build permet à la fonction main de gérer la valeur Result retournée par la fonction build et de terminer plus proprement le processus dans le cas d’une erreur.
Appeler Config::build et gérer les erreurs
Pour gérer les cas d’erreurs et afficher un message correct pour l’utilisateur, nous devons mettre à jour main pour gérer le Result retourné par Config::build, comme dans l’encart 12-10. Nous allons aussi prendre la décision de quitter l’outil en ligne de commande avec un code d’erreur différent de zéro avec panic! et nous allons, à la place, l’implémenter manuellement. Un statut de sortie différent de zéro est une convention pour signaler au processus qui a appelé notre programme que le programme s’est terminé dans un état d’erreur.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
// -- partie masquée ici --
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
let contenu = fs::read_to_string(config.chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
println!("Dans le texte :\n{contenu}");
}
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}Config failsDans cet encart, nous avons utilisé une méthode que nous n’avons pas encore détaillée pour l’instant : unwrap_or_else, qui est définie sur Result<T, E> par la bibliothèque standard. L’utilisation de unwrap_or_else nous permet de définir une gestion des erreurs personnalisée, exempte de panic!. Si le Result est une valeur Ok, le comportement de cette méthode est similaire à unwrap : elle retourne la valeur à l’intérieur du Ok. Cependant, si la valeur est une valeur Err, cette méthode appelle le code dans la fermeture, qui est une fonction anonyme que nous définissons et passons en argument de unwrap_or_else. Nous verrons les fermetures plus en détail dans le chapitre 13. Pour l’instant, vous avez juste à savoir que le unwrap_or_else va passer la valeur interne du Err (qui dans ce cas est la chaîne de caractères statique "pas assez d'arguments" que nous avons ajoutée dans l’encart 12-9) à notre fermeture dans l’argument err qui est présent entre deux barres verticales. Le code dans la fermeture peut ensuite utiliser la valeur err lorsqu’il est exécuté.
Nous avons ajouté une nouvelle ligne use pour importer process dans la portée à partir de la bibliothèque standard. Le code dans la fermeture qui sera exécuté dans le cas d’une erreur fait uniquement deux lignes : nous affichons la valeur de err et nous appelons ensuite process::exit. La fonction process::exit va stopper le programme immédiatement et retourner le nombre qui lui a été donné en paramètre comme code de statut de sortie. C’est semblable à la gestion basée sur panic! que nous avons utilisée à l’encart 12-8, mais nous n’avons plus tout le texte en plus. Essayons cela :
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problème rencontré lors de l'interprétation des arguments : il n'y a pas assez d'arguments
Très bien ! Cette sortie est bien plus compréhensible pour nos utilisateurs.
Extraction de la logique du main
Maintenant que nous avons fini le remaniement de l’interprétation de la configuration, occupons-nous de la logique du programme. Comme nous l’avons dit dans “Séparation des tâches des projets de binaires”, nous allons extraire une fonction run qui va contenir toute la logique qui est actuellement dans la fonction main qui n’est pas liée au réglage de la configuration ou la gestion des erreurs. Lorsque nous aurons terminé, la fonction main sera plus concise et facile à vérifier en l’inspectant, et nous pourrons écrire des tests pour toutes les autres logiques.
L’encart 12-11 montre les petites améliorations progressives pour extraire une fonction run.
use std::env;
use std::fs;
use std::process;
fn main() {
// -- partie masquée ici --
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
run(config);
}
fn run(config: Config) {
let contenu = fs::read_to_string(config.chemin_fichier)
.expect("Aurait dû pouvoir lire le fichier");
println!("Dans le texte :\n{contenu}");
}
// -- partie masquée ici --
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}run function containing the rest of the program logicLa fonction run contient maintenant toute la logique qui restait dans le main, en commençant par la lecture du fichier. La fonction run prend l’instance de Config en argument.
Retourner des erreurs depuis run
Avec le restant de la logique du programme maintenant séparée dans la fonction run, nous pouvons améliorer la gestion des erreurs, comme nous l’avons fait avec Config::build dans l’encart 12-9. Plutôt que de permettre au programme de paniquer en appelant expect, la fonction run va retourner un Result<T, E> lorsque quelque chose se passe mal. Cela va nous permettre de consolider davantage la logique de gestion des erreurs dans main pour qu’elle soit plus conviviale pour l’utilisateur. L’encart 12-12 montre les changements que nous devons appliquer à la signature et au corps du run.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// -- partie masquée ici --
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
println!("Dans le texte :\n{contenu}");
Ok(())
}
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}run function to return ResultNous avons fait trois changements significatifs ici. Premièrement, nous avons changé le type de retour de la fonction run en Result<(), Box<dyn Error>>. Cette fonction renvoyait précédemment le type unité, (), que nous gardons comme valeur de retour dans le cas de Ok.
En ce qui concerne le type d’erreur, nous avons utilisé l’objet trait Box<dyn Error> (et nous avons importé std::error::Error dans la portée avec une instruction use en haut). Nous allons voir les objets trait dans le chapitre 18. Pour l’instant, retenez juste que Box<dyn Error> signifie que la fonction va retourner un type qui implémente le trait Error, mais que nous n’avons pas à spécifier quel sera précisément le type de la valeur de retour. Cela nous donne la flexibilité de retourner des valeurs d’erreurs qui peuvent être de différents types dans différents cas d’erreurs. Le mot-clé dyn est un raccourci pour “dynamique”.
Deuxièmement, nous avons enlevé l’appel à expect pour privilégier l’opérateur ?, que nous avons vu dans le chapitre 9. Au lieu de faire un panic! sur une erreur, ? va retourner la valeur d’erreur de la fonction courante vers le code qui l’a appelé pour qu’il la gère.
Troisièmement, la fonction run retourne maintenant une valeur Ok dans les cas de succès. Nous avons déclaré dans la signature que le type de succès de la fonction run était (), ce qui signifie que nous avons enveloppé la valeur de type unité dans la valeur Ok. Cette syntaxe Ok(()) peut sembler un peu étrange au départ. Mais utiliser () de cette manière est la façon idéale d’indiquer que nous appelons run uniquement pour ses effets de bord ; elle ne retourne pas de valeur dont nous pourrions avoir besoin.
Lorsque vous exécutez ce code, il va se compiler mais il va afficher unavertissement :
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
On recherche : the
Dans le fichier : poem.txt
Dans le texte :
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust nous informe que notre code ignore la valeur Result et que cette valeur Result pourrait indiquer qu’une erreur s’est passée. Mais nous ne vérifions pas pour savoir si oui ou non il y a eu une erreur, et le compilateur nous rappelle que nous devrions avoir du code de gestion des erreurs ici ! Corrigeons dès à présent ce problème.
Gérer les erreurs retournées par run dans main
Nous allons vérifier les erreurs et les gérer en utilisant une technique similaire à celle que nous avons utilisée avec Config::build dans l’encart 12-10, mais avec une légère différence :
Fichier : src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// -- partie masquée ici --
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
println!("On recherche : {}", config.recherche);
println!("Dans le fichier : {}", config.chemin_fichier);
if let Err(e) = run(config) {
println!("Erreur applicative : {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
println!("Dans le texte :\n{contenu}");
Ok(())
}
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}Nous utilisons if let plutôt que unwrap_or_else pour vérifier si run retourne un valeur Err et appeler process::exit(1) le cas échéant. La fonction run ne retourne pas de valeur sur laquelle nous aurions besoin d’utiliser unwrap comme avec le Config::build qui retournait une instance de Config. Comme run retourne () dans le cas d’un succès, nous nous préoccupons uniquement de détecter les erreurs, donc nous n’avons pas besoin de unwrap_or_else pour retourner la valeur extraite, qui sera toujours ().
Les corps du if let et de la fonction unwrap_or_else sont identiques dans les deux cas : nous affichons l’erreur et nous quittons.
Déplacer le code dans une crate de bibliothèque
Notre projet minigrep se présente plutôt bien pour le moment ! Maintenant, nous allons diviser notre fichier src/main.rs et déplacer du code dans le fichier src/lib.rs. Ainsi, nous pourrons le tester et avoir un fichier src/main.rs qui héberge moins de fonctionnalités.
Définissons le code chargé de la recherche de texte dans src/lib.rs plutôt que dans src/main.rs, ce qui nous permettra (ainsi qu’à toute autre personne utilisant notre bibliothèque minigrep) d’appeler la fonction de recherche depuis davantage de contextes que notre binaire minigrep.
Commençons par définir la signature de la fonction rechercher dans src/lib.rs, comme indiqué dans l’encart 12-13, avec un corps qui appelle la macro unimplemented!. Nous expliquerons cette signature plus en détail lorsque nous rédigerons l’implémentation.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
unimplemented!();
}search function in src/lib.rsNous avons utilisé le mot-clé pub dans la définition de fonction pour indiquer que rechercher fait partie de l’API publique de notre crate de bibliothèque. Nous avons maintenant une crate de bibliothèque que nous pouvons utiliser et que nous pouvons tester !
Maintenant, nous devons importer le code défini dans src/lib.rs dans la portée de la crate binaire dans src/main.rs et l’appeller, comme montré dans l’encart 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// -- partie masquée ici --
use minigrep::rechercher;
fn main() {
// -- partie masquée ici --
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Erreur applicative : {e}");
process::exit(1);
}
}
// -- partie masquée ici --
struct Config {
recherche: String,
chemin_fichier: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
for ligne in rechercher(&config.recherche, &contenu) {
println!("{ligne}");
}
Ok(())
}minigrep library crate’s search function in src/main.rsNous avons ajouté une ligne use minigrep::Config pour apporter la fonction rechercher de la crate de bibliothèque dans la portée de la crate binaire. Ensuite, dans la fonction run, au lieu d’afficher le contenu du fichier, nous appelons la fonction rechercher en lui passant la valeur config.recherche et contenu comme arguments. Puis, run utilise une boucle for pour afficher chaque ligne retournée depuis rechercher qui correspond à la recherche. C’est aussi l’occasion d’enlever les appels à println! de la fonction main qui affichaient la recherche et le chemin du fichier, de sorte que notre programme n’affiche que les résultats de la recherche (si aucune erreur n’est survenue).
Notez que la fonction de recherche va collecter tous les résultats dans un vecteur qu’elle renvoie avant qu’aucun affichage n’arrive. Cette implémentation pourrait s’avérer lente à afficher les résultats quand elle traite de gros fichiers, parce que les résultats ne sont pas affichés au fur et à mesure qu’ils sont trouvés ; nous discuterons d’un moyen envisageable pour remédier à ceci en utilisant les itérateurs dans le chapitre 13.
Ouah ! C’était pas mal de travail, mais nous nous sommes organisés pour nous assurer le succès à venir. Maintenant il est bien plus facile de gérer les erreurs, et nous avons rendu le code plus modulaire. À partir de maintenant, l’essentiel de notre travail sera effectué dans src/lib.rs.
Profitons de cette nouvelle modularité en accomplissant quelque chose qui aurait été difficile à faire avec l’ancien code, mais qui est facile avec ce nouveau code : nous allons écrire des tests !
Développer les fonctionnalités de la bibliothèque avec le TDD
Ajouter des fonctionnalités à l’aide du développement piloté par les tests
Maintenant que la logique de recherche est dans src/lib.rs, à part de la fonction main, il est bien plus facile d’écrire les tests pour les fonctionnalités de base de notre code. Nous pouvons appeler les fonctions directement avec différents arguments et vérifier les valeurs de retour sans avoir à appeler notre binaire dans la ligne de commande.
Dans cette section, nous allons ajouter la logique de recherche au programme minigrep en utilisant le processus de développement piloté par les tests (c’est le TDD : Test-Driven Development) avec les étapes suivantes :
- Écrivez un test qui échoue et lancez-le pour vous assurer qu’il va échouer pour la raison que vous attendiez.
- Écrivez ou modifiez juste assez de code pour faire réussir ce nouveau test.
- Remaniez le code que vous venez d’ajouter ou de changer pour vous assurer que les tests continuent à réussir.
- Recommencez à l’étape 1 !
Bien que ce processus n’est qu’une des différentes manières d’écrire des programmes, le TDD peut aussi aider à piloter sa conception. Écrire les tests avant d’écrire le code qui fait réussir les tests aide à maintenir une haute couverture de tests tout le long du processus.
Nous allons expérimenter cela avec l’implémentation de la fonctionnalité qui va rechercher la chaîne de caractères demandée dans le contenu du fichier et générer une liste de lignes qui correspond à cette recherche. Nous ajouterons cette fonctionnalité dans une fonction rechercher.
Écrire un test qui échoue
Comme nous n’en avons plus besoin, enlevons les instructions println! de src/lib.rs et src/main.rs que nous avions utilisé pour vérifier le bon comportement du programme. Ensuite, Dans src/lib.rs, nous allons ajouter un module tests avec une fonction de test, comme nous l’avions fait dans le chapitre 11. La fonction de test définit le comportement que nous voulons qu’ait la fonction rechercher : elle va prendre en arguments une recherche et le texte dans lequel rechercher, et elle va retourner seulement les lignes du texte qui correspondent à la recherche. L’encart 12-15 montre ce test.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// -- partie masquée ici --
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_resultat() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
}search function for the functionality we wish we hadCe test recherche la chaîne de caractères "duct". Le texte dans lequel nous recherchons fait trois lignes, et seulement une d’entre elles contient "duct" (remarquez que la barre oblique inverse après le double guillemet ouvrant indique à Rust de ne pas insérer un caractère de nouvelle ligne au début du contenu de ce littéral de chaîne de caractère). Nous vérifions que la valeur retournée par la fonction rechercher contient seulement la ligne que nous avions prévue.
Si nous exécutons ce test, il va échouer pour le moment car la macro unimplemented! panique avec le message “not implemented”. En suivant les principes TDD, nous allons ajouter juste assez de code pour que le test puisse ne pas paniquer lors de l’appel de la fonction, en définissant la fonction rechercher de manière à ce qu’elle renvoie toujours un vecteur vide, comme dans l’encart 12-16. Ensuite, le test devrait compiler et échouer car un vecteur vide ne correspond pas au vecteur qui contient la ligne "sécurité, rapidité, productivité."
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_resultat() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
}search function so that calling it won’t panicVoyons maintenant pourquoi nous avons besoin de définir explicitement une durée de vie 'a dans la signature de rechercher et de l’utiliser sur l’argument contenu ainsi que la valeur de retour. Rappelez-vous que dans le chapitre 10 nous avions vu que le paramètre de durée de vie indique quelle durée de vie d’argument est connectée à la durée de vie de la valeur de retour. Dans notre cas, nous indiquons que le vecteur retourné devrait contenir des slices de chaînes de caractères qui proviennent des slices de l’argument contenu (et pas de l’argument recherche).
Autrement dit, nous disons à Rust que les données retournées par la fonction rechercher vont vivre aussi longtemps que la donnée dans l’argument contenu de la fonction rechercher. C’est très important ! Les données sur lesquelles pointent les slices doivent toujours être en vigueur pour que la référence reste valide ; si le compilateur croit que nous créons des slices de recherche plutôt que de contenu, ses vérifications de sécurité seront incorrectes.
Si nous oublions les annotations de durée de vie et que nous essayons de compiler cette fonction, nous allons obtenir cette erreur :
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn rechercher(recherche: &str, contenu: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn rechercher<'a>(recherche: &'a str, contenu: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust ne peut pas deviner lequel des deux paramètres nous allons utiliser, donc nous devons lui dire explicitement. Notez que le texte d’aide suggère de préciser la durée de vie pour tous les paramètres et le type de retour, ce qui est incorrect ! Comme contenu est le paramètre qui contient tout notre texte et que nous voulons retourner des extraits de ce texte qui correspondent à la recherche, nous savons que contenu est le seul paramètre qui doit être connecté à la valeur de retour, en utilisant la syntaxe de durée de vie.
Les autres langages de programmation n’ont pas besoin que vous connectiez les arguments aux valeurs de retour dans la signature, mais cette pratique deviendra plus facile au fil du temps. Vous pouvez comparer cet exemple aux exemples de la section “La conformité des références avec les durées de vies” du chapitre 10.
Écrire du code pour réussir au test
Pour le moment, notre test échoue car nous retournons toujours un vecteur vide. Pour corriger cela et implémenter rechercher, notre programme doit suivre les étapes suivantes :
- Itérer sur chacune des lignes de
contenu. - Vérifier si la ligne contient la chaîne de caractères recherchée.
- Si c’est le cas, l’ajouter à la liste des valeurs que nous retournerons.
- Si ce n’est pas le cas, ne rien faire.
- Retourner la liste des résultats qui ont été trouvés.
Travaillons sur chacune de ces étapes, en commençant par l’itération sur les lignes.
Itérer sur chacune des lignes avec la méthode lines
Rust a une méthode très pratique pour gérer l’itération ligne-par-ligne des chaînes de caractères, judicieusement appelée lines, qui fonctionne comme dans l’encart 12-17. Notez que cela ne se compile pas encore.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
for ligne in contenu.lines() {
// faire quelquechose avec ligne ici
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_resultat() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
}contentsLa méthode lines retourne un itérateur. Nous verrons plus tard les itérateurs dans le chapitre 13, mais souvenez-vous que vous avez vu cette façon d’utiliser un itérateur dans l’encart 3-5, dans lequel nous avions utilisé une boucle for sur un itérateur pour exécuter du code sur chaque élément d’une collection.
Trouver chaque ligne correspondant à la recherche
Ensuite, nous allons vérifier que la ligne courante contient la chaîne de caractères que nous recherchons. Heureusement, les chaînes de caractères ont une méthode contains assez pratique qui fait cela pour nous ! Ajoutez l’appel à la méthode contains dans la fonction rechercher, comme dans l’encart 12-18. Notez qu’ici non plus nous ne pouvons pas encore compiler.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
for ligne in contenu.lines() {
if ligne.contains(recherche) {
// faire quelquechose avec la ligne ici
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_resultat() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
}queryPour le moment, nous construisions des fonctionnalités. Pour que le code puisse se compiler, nous devons retourner une valeur depuis le corps de la fonction, comme nous l’avons indiqué dans la signature de la fonction.
Stocker les lignes trouvées
Pour terminer cette fonction, nous avons aussi besoin d’un moyen de stocker les lignes qui contiennent la chaîne de caractères que nous recherchons. Pour cela, nous pouvons créer un vecteur mutable avant la boucle for et appeler la méthode push pour enregistrer la ligne dans le vecteur. Après la boucle for, nous retournons le vecteur, comme dans l’encart 12-19 :
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
let mut resultats = Vec::new();
for ligne in contenu.lines() {
if ligne.contains(recherche) {
resultats.push(ligne);
}
}
resultats
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_resultat() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
}Maintenant, notre fonction rechercher retourne uniquement les lignes qui contiennent recherche, et notre test devrait réussir. Exécutons le test :
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Notre test a réussi, donc nous savons que cela fonctionne !
Arrivés à ce stade, nous pourrions envisager des pistes de remaniement pour l’implémentation de la fonction de recherche tout en faisant en sorte que les tests réussissent toujours afin de conserver les mêmes fonctionnalités. Le code de la fonction de recherche n’est pas mauvais, mais il ne profite pas de quelques fonctionnalités utiles des itérateurs. Nous retrouverons cet exemple dans le chapitre 13, dans lequel nous explorerons les itérateurs en détail, et ainsi découvrir comment nous pourrions l’améliorer.
Maintenant, l’intégralité du programme devrait fonctionner ! Essayons-le, pour commencer avec un mot qui devrait retourner exactement une seule ligne du poème d’Emily Dickinson, “frog” :
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Super ! Maintenant, essayons un mot qui devrait retourner plusieurs lignes, comme “body” :
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
Et enfin, assurons-nous que nous n’obtenons aucune ligne lorsque nous cherchons un mot qui n’est nulle part dans le poème, comme “monomorphization” :
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Très bien ! Nous avons construit notre propre mini-version d’un outil classique et nous avons beaucoup appris sur la façon de structurer nos applications. Nous en avons aussi appris un peu sur les entrées et sorties des fichiers, les durées de vie, les tests et l’interprétation de la ligne de commande.
Pour clôturer ce projet, nous allons brièvement voir comment travailler avec les variables d’environnement et comment écrire sur la sortie standard des erreurs, ce qui peut s’avérer utile lorsque vous écrivez des programmes en ligne de commande.
Travailler avec des variables d'environnement
Travailler avec des variables d’environnement
Nous allons améliorer le binaire minigrep en lui ajoutant une fonctionnalité supplémentaire : une option pour rechercher sans être sensible à la casse que l’utilisateur pourra activer via une variable d’environnement. Nous pourrions appliquer cette fonctionnalité avec une option en ligne de commande et demander à l’utilisateur de la renseigner à chaque fois qu’il veut l’activer, mais à la place, en utilisant une variable d’environnement, nous permettons à nos utilisateurs de régler la variable d’environnement une seule fois et d’avoir leurs recherches insensibles à la casse dans cette session du terminal.
Écrire un test qui échoue pour la recherche insensible à la casse
Nous ajoutons d’abord une nouvelle fonction rechercher_insensible_casse à la bibliothèque minigrep qui sera appelée lorsque la variable d’environnement aura une valeur. Nous allons continuer à suivre le processus de TDD, donc la première étape est d’écrire à nouveau un test qui échoue. Nous allons ajouter un nouveau test pour la nouvelle fonction rechercher_insensible_casse et renommer notre ancien test un_resultat en sensible_casse pour clarifier les différences entre les deux tests, comme dans l’encart 12-20.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
let mut resultats = Vec::new();
for ligne in contenu.lines() {
if ligne.contains(recherche) {
resultats.push(ligne);
}
}
resultats
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn sensible_casse() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.
Duct tape.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
#[test]
fn insensible_casse() {
let recherche = "rUsT";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.
C'est pas rustique.";
assert_eq!(
vec!["Rust:", "C'est pas rustique."],
rechercher_insensible_casse(recherche, contenu)
);
}
}Remarquez que nous avons aussi modifié le contenu de l’ancien test. Nous avons ajouté une nouvelle ligne avec le texte "Duct tape." en utilisant un D majuscule qui ne devrait pas correspondre à la recherche "duct" lorsque nous recherchons de manière à être sensible à la casse. Ce changement de l’ancien test permet de nous assurer que nous ne casserons pas accidentellement la fonction de recherche sensible à la casse que nous avons déjà implémentée. Ce test devrait toujours continuer à réussir au fur et à mesure que nous progressons sur la recherche insensible à la casse.
Le nouveau test pour la recherche insensible à la casse utilise "rUsT" comme recherche. Dans la fonction rechercher_insensible_casse que nous sommes en train d’ajouter, la recherche "rUsT" devrait correspondre à la ligne qui contient "Rust:" avec un R majuscule ainsi que la ligne C'est pas rustique. même si ces deux cas ont des casses différentes de la recherche. C’est notre test qui doit échouer, et il ne devrait pas se compiler car nous n’avons pas encore défini la fonction rechercher_insensible_casse. Ajoutez son implémentation qui retourne toujours un vecteur vide, de la même manière que nous l’avions fait pour la fonction rechercher dans l’encart 12-16 pour voir si les tests se compilent et échouent.
Implémenter la fonction rechercher_insensible_casse
La fonction rechercher_insensible_casse, présente dans l’encart 12-21, sera presque la même que la fonction rechercher. La seule différence est que nous allons transformer en minuscule le contenu de recherche et de chaque ligne pour que quelle que soit la casse des arguments d’entrée, nous aurons toujours la même casse lorsque nous vérifierons si la ligne contient la recherche.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
let mut resultats = Vec::new();
for ligne in contenu.lines() {
if ligne.contains(recherche) {
resultats.push(ligne);
}
}
resultats
}
pub fn rechercher_insensible_casse<'a>(
recherche: &str,
contenu: &'a str,
) -> Vec<&'a str> {
let recherche = recherche.to_lowercase();
let mut resultats = Vec::new();
for ligne in contenu.lines() {
if ligne.to_lowercase().contains(&recherche) {
resultats.push(ligne);
}
}
resultats
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn sensible_casse() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.
Duct tape.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
#[test]
fn insensible_casse() {
let recherche = "rUsT";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.
C'est pas rustique.";
assert_eq!(
vec!["Rust:", "C'est pas rustique."],
rechercher_insensible_casse(recherche, contenu)
);
}
}search_case_insensitive function to lowercase the query and the line before comparing themD’abord, nous convertissons la chaîne de caractères recherche en minuscules et nous l’enregistrons dans une nouvelle variable avec le même nom. L’appel à to_lowercase sur la recherche est nécessaire afin que quelle que soit la recherche de l’utilisateur, comme "rust", "RUST", "Rust", ou "rUsT", nous traitons la recherche comme si elle était "rust" et par conséquent elle est insensible à la casse. La méthode to_lowercase devrait gérer de l’Unicode de base, mais ne sera pas fiable à 100%. Si nous avions écrit une application sérieuse, nous aurions dû faire plus de choses à ce sujet, toutefois vu que la section actuelle traite des variables d’environnement et pas de la gestion de l’Unicode, nous allons conserver ce code simplifié.
Notez que recherche est désormais une String et non plus une slice de chaîne de caractères, car l’appel à to_lowercase crée des nouvelles données au lieu de modifier les données déjà existantes. Par exemple, disons que la recherche est "rUsT" : cette slice de chaîne de caractères ne contient pas de u ou de t minuscule que nous pourrions utiliser, donc nous devons allouer une nouvelle String qui contient "rust". Maintenant, lorsque nous passons recherche en argument de la méthode contains, nous devons rajouter une esperluette car la signature de contains est définie pour prendre une slice de chaîne de caractères.
Ensuite, nous ajoutons un appel à to_lowercase sur chaque ligne afin de convertir tous ses caractères en minuscules. Maintenant que nous avons ligne et recherche en minuscules, nous allons rechercher les correspondances, peu importe la casse de la recherche.
Voyons si cette implémentation passe les tests :
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::insensible_casse ... ok
test tests::sensible_casse ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Très bien ! Elles ont réussi. Maintenant, utilisons la nouvelle fonction rechercher_insensible_casse dans la fonction run. Pour commencer, nous allons ajouter une option de configuration à la structure Config pour changer entre la recherche sensible et non sensible à la casse. L’ajout de ce champ va causer des erreurs de compilation car nous n’avons jamais initialisé ce champ pour le moment :
Fichier : src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
// -- partie masquée ici --
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}Nous avons ajouté le champ ignore_casse qui contient un Booléen. Ensuite, nous devons faire en sorte que la fonction run vérifie la valeur du champ ignore_casse et l’utilise pour décider si elle doit appeler la fonction rechercher ou la fonction rechercher_insensible_casse, comme dans l’encart 12-22. Notez que cela ne se compile toujours pas.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
// -- partie masquée ici --
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
Ok(Config { recherche, chemin_fichier })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}search or search_case_insensitive based on the value in config.ignore_caseEnfin, nous devons vérifier la variable d’environnement. Les fonctions pour travailler avec les variables d’environnement sont dans le module env de la bibliothèque standard, donc nous allons importer ce module dans la portée avec une ligne use std::env; en haut de src/lib.rs. Ensuite, nous allons utiliser la fonction var du module env pour vérifier la présence d’une variable d’environnement IGNORE_CASSE, comme dans l’encart 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
let ignore_casse = env::var("IGNORE_CASSE").is_ok();
Ok(Config {
recherche,
chemin_fichier,
ignore_casse,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}IGNORE_CASEIci, nous créons une nouvelle variable ignore_casse. Pour lui donner une valeur, nous appelons la fonction env::var et nous lui passons le nom de la variable d’environnement IGNORE_CASSE. La fonction env::var retourne un Result qui sera en cas de succès la variante Ok qui contiendra la valeur de la variable d’environnement si cette variable d’environnement est définie avec n’importe quelle valeur. Elle retournera la variante Err si cette variable d’environnement n’est pas définie.
Nous utilisons la méthode is_ok sur le Result pour vérifier si la variable d’environnement est définie, ce qui signifie que le programme doit effectuer une recherche insensible à la casse. Si la variable d’environnement IGNORE_CASSE n’est pas définie à quoi que ce soit, is_ok va retourner false et le programme va procéder à une recherche sensible à la casse. Nous ne nous préoccupons pas de la valeur de la variable d’environnement, mais uniquement de savoir si elle est définie ou non, donc nous utilisons is_ok plutôt que unwrap, expect ou toute autre méthode que nous avons vue avec Result.
Nous passons la valeur de la variable ignore_casse à l’instance de Config afin que la fonction run puisse lire cette valeur et décider d’appeler rechercher ou rechercher_insensible_casse, ou rechercher, comme nous l’avons implémenté dans l’encart 12-22.
Faisons un essai ! D’abord, nous allons lancer notre programme avec la variable d’environnement non définie et avec la recherche to, qui devrait trouver toutes les lignes qui contiennent le mot “to” en minuscules :
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
On dirait que cela fonctionne ! Maintenant, lançons le programme avec IGNORE_CASSE définie à 1 mais avec la même recherche to.
$ IGNORE_CASE=1 cargo run -- to poem.txt
Si vous utilisez PowerShell, vous allez avoir besoin d’affecter la variable d’environnement puis exécuter le programme avec deux commandes distinctes :
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
Cela va faire persister la variable IGNORE_CASSE pour la durée de votre session de terminal. Elle peut être désaffectée avec la cmdlet Remove-Item :
PS> Remove-Item Env:IGNORE_CASE
Nous devrions trouver cette fois-ci également toutes les lignes qui contiennent “to” écrit avec certaines lettres en majuscules :
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Très bien, nous avons aussi obtenu les lignes qui contiennent “To” ! Notre programme minigrep peut maintenant faire des recherches insensibles à la casse, contrôlées par une variable d’environnement. Vous savez maintenant comment gérer des options définies soit par des arguments en ligne de commande, soit par des variables d’environnement.
Certains programmes permettent d’utiliser les arguments et les variables d’environnement pour un même réglage. Dans ce cas, le programme décide si l’un ou l’autre a la priorité. Pour vous exercer à nouveau, essayez de contrôler la sensibilité à la casse via un argument de ligne de commande ou une variable d’environnement. Vous devrez choisir qui de l’argument de la ligne de commande ou de la variable d’environnement doit être prioritaire lorsque les deux sont configurés simultanément mais de manière contradictoire quand le programme est exécuté.
Le module std::env contient plein d’autres fonctionnalités utiles pour utiliser les variables d’environnement : regardez sa documentation pour voir ce qu’il est possible de faire.
Écrire les erreurs sur la sortie d'erreur standard
Écrire les erreurs sur la sortie d’erreur standard
Pour l’instant, nous avons écrit toutes nos sorties du terminal en utilisant la macro println!. Dans la plupart des terminaux, il y a deux genres de sorties : la sortie standard (stdout) pour les informations générales et la sortie d’erreur standard (stderr) pour les messages d’erreur. Cette distinction permet à l’utilisateur de choisir de rediriger la sortie des messages sans erreurs d’un programme vers un fichier mais continuer à afficher les messages d’erreur à l’écran.
La macro println! ne peut écrire que sur la sortie standard, donc nous devons utiliser autre chose pour écrire sur la sortie d’erreur standard.
Vérifier où sont écrites les erreurs
Commençons par observer comment le contenu écrit par minigrep est actuellement écrit sur la sortie standard, y compris les messages d’erreur que nous souhaitons plutôt écrire sur la sortie d’erreur standard. Nous allons faire cela en redirigeant le flux de sortie standard vers un fichier pendant que nous déclencherons intentionnellement une erreur. Nous ne redirigerons pas le flux de sortie d’erreur standard, si bien que n’importe quel contenu envoyé à la sortie d’erreur standard va continuer à s’afficher à l’écran.
Les programmes en ligne de commande sont censés envoyer leurs messages d’erreur dans le flux d’erreurs standard afin que nous puissions continuer à voir les messages d’erreurs à l’écran même si nous redirigeons le flux de la sortie standard dans un fichier. Notre programme ne se comporte pas comme il le devrait : nous allons voir qu’à la place, il envoie les messages d’erreur dans le fichier !
Pour démontrer ce comportement, nous allons exécuter le programme avec > suivi du nom du fichier, sortie.txt, dans lequel nous souhaitons rediriger le flux de sortie standard. Nous ne fournissons aucun argument, ce qui va causer une erreur :
$ cargo run > sortie.txt
La syntaxe indique à l’invite de commande d’écrire le contenu de la sortie standard dans sortie.txt plutôt qu’à l’écran. Nous n’avons pas vu le message d’erreur que nous nous attendions de voir à l’écran, ce qui veut dire qu’il a dû finir dans le fichier. Voici ce que sortie.txt contient :
Problème rencontré lors de l'interprétation des arguments : il n'y a pas assez d'arguments
Effectivement, notre message d’erreur est écrit sur la sortie standard. Il serait bien plus utile que les messages d’erreur comme celui-ci soient écrits sur la sortie d’erreur standard afin que seules les données produites par exécution fructueuse finissent dans le fichier. Nous allons corriger cela.
Écrire les erreurs sur la sortie d’erreur standard
Nous allons utiliser le code de l’encart 12-24 pour changer la manière dont les messages d’erreur sont écrits. Grâce au remaniement que nous avons fait plus tôt dans ce chapitre, tout le code qui écrit les messages d’erreurs se trouve dans une seule fonction, main. La bibliothèque standard fournit la macro eprintln! qui écrit dans le flux d’erreur standard, donc changeons les deux endroits où nous appelons println! afin d’utiliser eprintln! à la place.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
let ignore_casse = env::var("IGNORE_CASSE").is_ok();
Ok(Config {
recherche,
chemin_fichier,
ignore_casse,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}eprintln!Exécutons maintenant à nouveau le programme de la même manière, sans aucun argument et en redirigeant la sortie standard avec > :
$ cargo run > sortie.txt
Problème rencontré lors de l'interprétation des arguments : il n'y a pas assez d'arguments
Désormais nous pouvons voir l’erreur à l’écran et sortie.txt ne contient rien, ce qui est le comportement que nous attendons d’un programme en ligne de commande.
Exécutons le programme à nouveau avec des arguments qui ne causent pas d’erreur tout en continuant à rediriger la sortie standard vers un fichier, comme ceci :
$ cargo run -- to poem.txt > sortie.txt
Nous ne voyons rien sur la sortie du terminal, et sortie.txt devrait contenir notre résultat :
Filename: output.txt
Are you nobody, too?
How dreary to be somebody!
Ceci prouve qu’en fonction des circonstances, nous utilisons maintenant la sortie standard pour la sortie sans les erreurs et l’erreur standard pour la sortie d’erreur.
Résumé
Ce chapitre a résumé certains des concepts majeurs que vous avez appris précédemment et expliqué comment procéder à des opérations courantes sur les entrées/sorties en Rust. En utilisant les arguments en ligne de commande, les fichiers, les variables d’environnement et la macro eprintln! pour écrire les erreurs, vous pouvez désormais écrire des applications en ligne de commande. En combinant cela avec les concepts vus dans les chapitres précédents, votre code restera bien organisé, stockera les données dans les bonnes structures de données, gèrera correctement les erreurs et sera correctement testé.
Maintenant, nous allons découvrir quelques fonctionnalités de Rust qui ont été influencées par les langages fonctionnels : les fermetures et les itérateurs.
Les fonctionnalités des langages fonctionnels : les itérateurs et les fermetures
La conception de Rust s’est inspirée de nombreux langages et technologies existantes, et une de ses influences les plus marquantes est la programmation fonctionnelle. La programmation dans un style fonctionnel consiste souvent à utiliser une fonction comme une valeur en la passant en argument d’une autre fonction, la retourner en résultat d’une autre fonction ou l’assigner à une variable pour l’exécuter plus tard, par exemple.
Dans ce chapitre, nous n’allons pas débattre sur ce qu’est ou n’est pas la programmation fonctionnelle, mais nous allons plutôt voir quelques fonctionnalités de Rust qui sont similaires à celles des autres langages souvent considérés comme fonctionnels.
Plus précisément, nous allons voir :
- les fermetures, une construction qui ressemble à une fonction que vous pouvez stocker dans une variable ;
- les itérateurs, une façon de travailler sur une série d’éléments ;
- comment utiliser les fermetures et les itérateurs pour améliorer le projet d’entrée/sortie du chapitre 12 ;
- les performances des fermetures et itérateurs (spoiler alert : elles sont probablement plus rapides que ce que vous pensez !).
Nous avons déjà traité d’autres fonctionnalités de Rust, comme le filtrage par motif et les énumérations, qui sont aussi influencées par la programmation fonctionnelle. Dans la mesure où la maîtrise des fermetures et des itérateurs est une étape importante pour écrire du code Rust performant, nous allons leur dédier ce chapitre entier.
Fermetures
Fermetures
Les fermetures en Rust sont des fonctions anonymes qui peuvent être sauvegardées dans une variable ou qui peuvent être passées en argument à d’autres fonctions. Il est possible de créer une fermeture à un endroit du code et ensuite de l’appeler ailleurs pour l’exécuter dans un contexte différent. Contrairement aux fonctions, les fermetures ont la possibilité de capturer les valeurs présentes dans le contexte où elles sont appelées. Nous allons montrer comment les fonctionnalités des fermetures permettent de réutiliser du code et suivre des comportements personnalisés.
Capture de l’environnement
Nous allons commencer par voir comment utiliser les fermetures pour récupérer les valeurs de l’environnement dans lequel elles sont définies pour un usage ultérieur. Voici le scénario : de temps à autre, notre entreprise de t-shirts offre un t-shirt exclusif en édition limitée à une personne de notre liste de diffusion à des fins promotionnelles. Les personnes inscrites sur la liste de diffusion peuvent éventuellement ajouter leur couleur préférée à leur profil. Si la personne choisie pour recevoir un t-shirt en cadeau a indiqué sa couleur préférée, elle recevra un t-shirt de cette couleur. Si la personne n’a pas spécifié de couleur préférée, elle aura la couleur des t-shirts dont l’entreprise possède le plus grand nombre.
Il y a bien des manières d’implémenter ceci. Pour cet exemple, nous allons utiliser un enum appeler CouleurTShirt qui aura les variantes Rouge et Bleu (le nombre de couleurs est limité par souci de simplicité). Nous représentons l’inventaire de l’entreprise par une structure Inventaire qui a un champ TShirts contenant un Vec<CouleurTShirt> représentant les couleurs de t-shirts présents en stock. La méthode cadeau définie sur Inventaire prend la couleur préférée du gagnant de t-shirt, et renvoie la couleur du t-shirt que la personne recevra. L’encart 13-1 montre cette organisation.
#[derive(Debug, PartialEq, Copy, Clone)]
enum CouleurTShirt {
Rouge,
Bleu,
}
struct Inventaire {
tshirts: Vec<CouleurTShirt>,
}
impl Inventaire {
fn cadeau(&self, preference_utilisateur: Option<CouleurTShirt>) -> CouleurTShirt {
preference_utilisateur.unwrap_or_else(|| self.le_plus_en_stock())
}
fn le_plus_en_stock(&self) -> CouleurTShirt {
let mut num_rouge = 0;
let mut num_bleu = 0;
for couleur in &self.tshirts {
match couleur {
CouleurTShirt::Rouge => num_rouge += 1,
CouleurTShirt::Bleu => num_bleu += 1,
}
}
if num_rouge > num_bleu {
CouleurTShirt::Rouge
} else {
CouleurTShirt::Bleu
}
}
}
fn main() {
let magasin = Inventaire {
tshirts: vec![CouleurTShirt::Bleu, CouleurTShirt::Rouge, CouleurTShirt::Bleu],
};
let preference_utilisateur1 = Some(CouleurTShirt::Rouge);
let cadeau1 = magasin.cadeau(preference_utilisateur1);
println!(
"L'utilisateur avec comme préférence {:?} reçoit {:?}",
preference_utilisateur1, cadeau1
);
let preference_utilisateur2 = None;
let cadeau2 = magasin.cadeau(preference_utilisateur2);
println!(
"L'utilisateur avec comme préférence {:?} reçoit {:?}",
preference_utilisateur2, cadeau2
);
}Le magasin défini dans main a encore deux t-shirts bleus et un t-shirt rouge à distribuer dans le cadre de cette promotion en édition limitée. Nous appelons la méthode cadeau pour un utilisateur qui préfère un t-shirt rouge et un utilisateur sans préférence particulière.
Une fois encore, ce code pourrait être implémenté de bien des manières ; ici pour nous focaliser sur les fermetures, nous nous sommes limités aux concepts que vous avez déjà appris, à l’exception du corps de la méthode cadeau qui utilise une fermeture. Dans la méthode cadeau nous récupérons la préférence de l’utilisateur comme un paramètre de type Option<CouleurTShirt> et nous appelons la méthode unwrap_or_else sur preference_utilisateur. La méthode unwrap_or_else sur Option<T> est définie par la bibliothèque standard library. Elle prend un argument : une fermeture sans aucun argument qui renvoie une valeur T (le même type stocké dans la variante Some de Option<T>, dans ce cas CouleurTShirt). Si Option<T> est de variante Some, unwrap_or_else renvoie la valeur contenue dans Some. Si Option<T> est de variante None, unwrap_or_else appelle la fermeture et renvoie la valeur renvoyée par celle-ci.
Nous spécifions l’expression || self.le_plus_en_stockd() en argument de unwrap_or_else. C’est une fermeture qui ne prend pas de paramètres (si la fermeture avait des paramètres, ils apparaîtraient entre les deux barres verticales). Le corps de la fermeture appelle self.le_plus_en_stockd(). Nous définissons la fermeture là, et l’implémentation de unwrap_or_else évaluera la fermeture plus tard si le résultat est requis.
L’exécution de ce code affichera ceci :
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
L'utilisateur avec comme préférence Some(Rouge) reçoit Rouge
L'utilisateur avec comme préférence None reçoit Bleu
Il est intéressant de noter ici que nous avons passé une fermeture qui appelle self.le_plus_en_stockd() sur l’instance actuelle de Inventaire. La bibliothèque standard n’a pas besoin de connaître les types Inventaire ou CouleurTShirt que nous avons définis, ni la logique que nous souhaitons utiliser dans ce scénario. La fermeture capture une référence immuable à l’instance self Inventaire et la transmet, avec le code que nous spécifions, à la méthode unwrap_or_else. Les fonctions, en revanche, ne sont pas capables de capturer leur environnement de cette manière.
Déduction et annotation des types de fermeture
Il y a d’autres différences entre les fonctions et les fermetures. Les fermetures ne nécessitent généralement pas d’annoter les types des paramètres ou de la valeur de retour comme le font les fonctions fn. Les annotations de type sont nécessaires pour les fonctions car elles font partie d’une interface explicite exposée à leurs utilisateurs. Définir cette interface de manière rigide est nécessaire pour s’assurer que tout le monde s’accorde sur les types de valeurs qu’une fonction utilise et retourne. Les fermetures, en revanche, ne sont pas utilisées dans une interface exposée de cette façon : elles sont stockées dans des variables et utilisées sans les nommer ni les exposer aux utilisateurs de notre bibliothèque.
Les fermetures sont typiquement brèves et ne sont pertinentes que dans un contexte précis plutôt que pour des cas génériques. Dans ces contextes limités, le compilateur est capable de déduire les types des paramètres et le type de retour, tout comme il est capable de déduire les types de la plupart des variables (il y a de rares cas où le compilateur a aussi besoin d’annotations de type de fermetures).
Comme pour les variables, nous pouvons ajouter des annotations de type si nous voulons rendre explicite et clarifier le code au risque d’être plus verbeux que ce qui est strictement nécessaire. Annoter les types d’une fermeture pourrait ressembler à la définition montrée par l’encart 13-2. Dans cet exemple, nous définissons une fermeture et la stockons dans une variable au lieu de définir la fermeture à l’endroit où on la passe comme argument, comme nous l’avions fait dans l’encart 13-1.
use std::thread;
use std::time::Duration;
fn generer_exercices(intensite: u32, nombre_aleatoire: u32) {
let fermeture_lente = |nombre: u32| -> u32 {
println!("calcul très lent ...");
thread::sleep(Duration::from_secs(2));
nombre
};
if intensite < 25 {
println!("Aujourd'hui, faire {} pompes !", fermeture_lente(intensite));
println!("Ensuite, faire {} abdominaux !", fermeture_lente(intensite));
} else {
if nombre_aleatoire == 3 {
println!("Faites une pause aujourd'hui ! Rappelez-vous de bien vous hydrater !");
} else {
println!(
"Aujourd'hui, courez pendant {} minutes !",
fermeture_lente(intensite)
);
}
}
}
fn main() {
let valeur_utilisateur_simule = 10;
let nombre_aleatoire_simule = 7;
generer_exercices(valeur_utilisateur_simule, nombre_aleatoire_simule);
}La syntaxe des fermetures et des fonctions semble plus similaire avec les annotations de type. Ici, nous définissons une fonction qui ajoute 1 à son paramètre, et d’une fermeture qui a le même comportement, pour comparaison. Nous avons ajouté des espaces pour aligner les parties pertinentes. Ceci met en évidence la similarité entre la syntaxe des fermetures et celle des fonctions, hormis l’utilisation des barres verticales et certaines syntaxes facultatives :
fn ajouter_un_v1 (x: u32) -> u32 { x + 1 }
let ajouter_un_v2 = |x: u32| -> u32 { x + 1 };
let ajouter_un_v3 = |x| { x + 1 };
let ajouter_un_v4 = |x| x + 1 ;La première ligne affiche la définition d’une fonction et la deuxième ligne une définition d’une fermeture entièrement annotée. Dans la troisième ligne, nous supprimons les annotations de type de la définition de la fermeture. Dans la quatrième ligne, nous supprimons les accolades qui sont facultatives, parce que le corps de la fermeture n’a qu’une seule expression. Ce sont toutes des définitions valides qui suivront le même comportement lorsqu’on les appellera. L’appel aux fermetures est nécessaire pour que ajouter_un_v3 et ajouter_un_v4 puissent être compilés car les types seront déduits en fonction de leur utilisation. Ceci est similaire à let v = Vec::new(); qui a besoin soit des annotations de type, soit de valeurs d’un certain type à insérer dans Vec pour que Rust puisse deviner le type.
Pour ce qui est des définitions des fermetures, le compilateur déduira un type concret pour chacun de leurs paramètres et pour leur valeur de retour. Par exemple, l’encart 13-8 montre la définition d’une petite fermeture qui renvoie simplement la valeur qu’elle reçoit comme paramètre. Cette fermeture n’est pas très utile sauf pour les besoins de cet exemple. Notez que nous n’avons pas ajouté d’annotation de type à la définition. Parce qu’il n’y a pas d’annotations de type, nous pouvons appeler la fermeture avec n’importe quel type, ce que nous avons fait ici en utilisant une String comme argument la première fois et un u32 la deuxième fois. Si nous tentons ensuite d’appeler fermeture_exemple, nous obtiendrons une erreur :
fn main() {
let fermeture_exemple = |x| x;
let s = fermeture_exemple(String::from("hello"));
let n = fermeture_exemple(5);
}Le compilateur nous renvoie l’erreur suivante :
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = fermeture_exemple(5);
| ----------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = fermeture_exemple(String::from("hello"));
| ----------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let fermeture_exemple = |x| x;
| ^
help: try using a conversion method
|
5 | let n = fermeture_exemple(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
La première fois que nous appelons fermeture_exemple avec une String, le compilateur déduit que le type de x et le type de retour de la fermeture sont de type String. Ces types sont ensuite verrouillés dans fermeture_exemple, et nous obtenons une erreur de type si après cela nous essayons d’utiliser un type différent avec la même fermeture.
Capture des références ou transfert de propriété
Les fermetures peuvent capturer les valeurs de leur environnement de trois façons différentes, qui correspondent directement aux trois façons dont une fonction peut prendre un paramètre : emprunter de manière immuable, emprunter de manière mutable, et prendre possession. La fermeture décidera laquelle de ces manières elle utilisera, en fonction de ce que le corps de la fonction fait avec les valeurs capturées.
Dans l’encart 13-4, nous définissons une fermeture qui capture une référence immuable vers le vecteur liste parce qu’il a seulement besoin d’une référence immuable pour afficher la valeur.
fn main() {
let liste = vec![1, 2, 3];
println!("Avant la définition de la fermeture : {liste:?}");
let emprunte_seulement = || println!("Depuis la fermeture: {liste:?}");
println!("Avant l'appel à la fermeture : {liste:?}");
emprunte_seulement();
println!("Après l'appel à la fermeture : {liste:?}");
}Cet exemple illustre également le fait qu’une variable peut être liée à une définition de fermeture, et qu’il est possible d’appeler plus tard la fermeture en utilisant le nom de variable avec des parenthèses, comme si le nom de variable était un nom de fonction.
Comme il est possible d’avoir plusieurs références immuables à liste en même temps, liste est toujours accessible depuis le code avant la définition de la fermeture, après la définition de la fermeture mais avant que l’appel à la fermeture, et après l’appel à la fermeture. Ce code se compile, s’exécute et affiche ceci :
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Avant la définition de la fermeture : [1, 2, 3]
Avant l'appel à la fermeture : [1, 2, 3]
Depuis la fermeture: [1, 2, 3]
Après l'appel à la fermeture : [1, 2, 3]
Ensuite, dans l’encart 13-5, nous changeons le corps de la fermeture de manière à ce qu’elle ajoute un élément au vecteur liste. La fermeture capture maintenant une référence mutable.
fn main() {
let mut liste = vec![1, 2, 3];
println!("Avant la définition de la fermeture : {liste:?}");
let mut emprunte_de_maniere_mutable = || liste.push(7);
emprunte_de_maniere_mutable();
println!("Après l'appel à la fermeture : {liste:?}");
}Ce code se compile, s’exécute et affiche ceci :
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Avant la définition de la fermeture : [1, 2, 3]
Après l'appel à la fermeture : [1, 2, 3, 7]
Notez qu’il n’y a plus de println! entre la définition et l’appel à la fermeture emprunte_de_maniere_mutable : quand emprunte_de_maniere_mutable est définie, il capture une référence mutable à liste. Nous n’utilisons pas une nouvelle fois la fermeture après l’appel à la fermeture, donc l’emprunt mutable se termine. Entre la définition de la fermeture et l’appel à la fermeture, un emprunt immutable pour affichage n’est pas autorisé, car aucun autre emprunt n’est autorisé quand il y a un emprunt mutable. Essayez d’ajouter un println! là pour voir quel message d’erreur vous obtenez !
Si nous voulons forcer la fermeture à prendre possession des valeurs qu’elle utilise dans l’environnement même si le corps de la fermeture n’a pas strictement besoin la possession, nous pouvons utiliser le mot-clé move la liste des paramètres.
Cette technique est très utile lorsque vous passez une fermeture à une nouvelle tâche pour déplacer les données afin qu’elles appartiennent à la nouvelle tâche. Nous traiterons en détail des tâches (threads) et de pourquoi vous voudriez les utiliser dans le chapitre 16 quand nous aborderons la concurrence ; mais pour le moment, voyons brièvement comment créer une nouvelle tâche à l’aide d’une fermeture qui nécessite le mot-clé move. L’encart 13-6 montre le contenu de l’encart 13-4 modifié pour afficher le vecteur dans une nouvelle tâche plutôt que dans la tâche principale.
use std::thread;
fn main() {
let liste = vec![1, 2, 3];
println!("Avant la définition de la fermeture : {liste:?}");
thread::spawn(move || println!("Depuis la tâche : {liste:?}"))
.join()
.unwrap();
}move to force the closure for the thread to take ownership of listNous créons une nouvelle tâche en lui passant comme argument une fermeture à exécuter. Le corps de la fermeture affiche la liste. Dans l’encart 13-4, la fermeture n’a capturé liste qu’à l’aide d’une référence immuable, car c’est le minimum d’accès à liste nécessaire pour l’afficher. Dans cet exemple, bien que le corps de la fermeture n’a besoin que d’une référence immuable, nous devons préciser que liste doit être déplacée dans la fermeture en mettant le mot-clé move au début de la définition de la fermeture. Si la tâche (thread) principale effectuait plus d’opérations avant d’appeler join sur la nouvelle tâche, cette nouvelle tâche pourrait se terminer avant le reste de la tâche principale, ou la tâche principale pourrait se terminer en premier. Si la tâche principale conservait la propriété de liste mais se terminait avant la nouvelle tâche et libérait liste, la référence immuable dans la tâche serait invalide. Par conséquent, le compilateur exige que liste soit déplacée dans la fermeture donnée à la nouvelle tâche, de manière à ce que la référence soit valide. Essayez de supprimer le mot-clé move ou d’utiliser liste dans la tâche principale après la définition de la fermeture pour voir quelles erreurs de compilation vous obtenez !
Déplacement de valeurs capturées en-dehors des fermetures
À partir du moment où une fermeture a capturé une référence ou qu’elle a pris possession d’une valeur provenant de l’environnement où la fermeture est définie (ce qui influence donc ce qui est éventuellement transféré dans la fermeture), le code du corps de la fermeture définit ce qui advient aux références ou aux valeurs quand la fermeture est ultérieurement évaluée (ce qui influence donc ce qui est éventuellement transféré hors de la fermeture).
Un corps de fermeture peut effectuer une des opérations suivantes : déplacer la valeur capturée hors de la fermeture, modifier la valeur capturée, ne déplacer ni ne modifier la valeur, ou ne rien capturer de l’environnement dès le départ.
La manière dont une fermeture capture et traite les valeurs à partir de l’environnement affecte quels traits la fermeture implémente, et ces traits permettent aux fonctions et aux structures de spécifier les sortes de fermetures qu’elles peuvent utiliser. Les fermetures peuvent automatiquement implémenter une, deux ou tous les trois traits Fn, de manière cumulative, selon la façon dont le corps de la fermeture traite les valeurs :
FnOnces’applique aux fermetures qui peuvent être appelées une fois. Toutes les fermetures implémentent au moins ce trait car toutes les fermetures peuvent être appelées. Une fermeture qui déplace les valeurs capturées hors de son corps implémentera uniquementFnOnceet aucun des autres traitsFnparce qu’elle ne peut être appelée qu’une fois.FnMuts’applique aux fermetures qui ne déplacent pas les valeurs capturées en-dehors de leur corps mais pourraient modifier les valeurs capturées. Ces fermetures peuvent être appelées plus d’une fois.Fns’applique aux fermetures qui ne déplacent pas les valeurs capturées hors de leur corps et ne modifient pas les valeurs capturées, ainsi que les fermetures qui ne capturent rien depuis leur environnement. Ces fermetures peuvent être appelées plus d’une fois sans changer leur environnement, ce qui est important dans des cas comme des appels multiples concurrents à une fermeture.
Voyons la définition de la méthode unwrap_or_else sur Option<T> que nous avons utilisée dans l’encart 13-1 :
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Souvenez-vous que T est le type générique représentant le type de la valeur dans la variante Some d’une Option. Ce type T est aussi le type de retour de la fonction unwrap_or_else : le code qui appelle unwrap_or_else sur une Option<String> par exemple, obtiendra une chaîne String.
Next, notice that the unwrap_or_else function has the additional generic type parameter F. The F type is the type of the parameter named f, which is the closure we provide when calling unwrap_or_else.
Le trait lié spécifié sur le type générique F est FnOnce() -> T, ce qui signifie que F doit pouvoir être appelé une fois, ne pas prendre d’arguments, et renvoyer un T. Utiliser FnOnce dans un trait lié exprime la contrainte que unwrap_or_else n’appellera pas f plus d’une fois. Dans le corps de unwrap_or_else, nous pouvons voir que si Option est Some, f ne sera pas appelée. Si Option est None, f sera appelée une fois. Parce que toutes les fermetures implémentent FnOnce, unwrap_or_else accepte les trois sortes de fermetures et est aussi flexible que possible.
Note : si ce que nous voulons faire ne nécessite pas de capturer une valeur depuis l’environnement, nous pouvons utiliser le nom d’une fonction plutôt que d’une fermeture là où nous avons besoin de quelque chose qui implémente un des traits Fn. Par exemple, sur une valeur Option<Vec<T>>, nous pourrions appeler unwrap_or_else(Vec::new) pour obtenir un nouveau vecteur vide si la valeur est None. Le compilateur implémente automatiquement le trait Fn applicable à une définition de fonction.
Voyons maintenant la méthode sort_by_key de la bibliothèque standard, définie sur les slices, pour voir en quoi elle diffère de unwrap_or_else et pourquoi sort_by_key utilise FnMut au lieu de FnOnce pour le trait lié. La fermeture reçoit un argument sous la forme d’une référence à l’élément courant de la slice concernée, et elle renvoie une valeur de type K qui peut être ordonnée. Cette fonction s’avère utile quand vous voulez trier une slice en fonction d’un attribut particulier de chaque élément. Dans l’encart 13-7, nous avons une liste d’instances de Rectangle, et nous utilisons sort_by_key pour les trier par leur attribut width, de la plus petite à la plus grande.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
fn main() {
let mut liste = [
Rectangle { largeur: 10, hauteur: 1 },
Rectangle { largeur: 3, hauteur: 5 },
Rectangle { largeur: 7, hauteur: 12 },
];
liste.sort_by_key(|r| r.largeur);
println!("{liste:#?}");
}sort_by_key to order rectangles by widthCe code va afficher :
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
largeur: 3,
hauteur: 5,
},
Rectangle {
largeur: 7,
hauteur: 12,
},
Rectangle {
largeur: 10,
hauteur: 1,
},
]
La raison pour laquelle sort_by_key est définie pour prendre une fermeture FnMut est qu’elle appelle la fermeture plusieurs fois : une fois pour chaque élément dans la slice. La fermeture |r| r.largeur ne capture ni ne modifie ni ne déplace quoi que ce soit depuis son environnement, elle remplit donc les exigences du trait lié.
Pour comparaison, l’encart 13-8 montre un exemple d’une fermeture qui implémente seulement le trait FnOnce, car elle déplace une valeur en-dehors de son environnement. Le compilateur ne nous permettra pas d’utiliser cette fermeture avec sort_by_key.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
fn main() {
let mut liste = [
Rectangle { largeur: 10, hauteur: 1 },
Rectangle { largeur: 3, hauteur: 5 },
Rectangle { largeur: 7, hauteur: 12 },
];
let mut operations_tri = vec![];
let valeur = String::from("fermeture appelée");
liste.sort_by_key(|r| {
operations_tri.push(valeur);
r.largeur
});
println!("{liste:#?}");
}FnOnce closure with sort_by_keyIl s’agit là d’une manière peu naturelle et alambiquée (et qui ne fonctionne pas) visant à compter le nombre de fois où sort_by_key appelle la fermeture lors du tri de liste. Ce code tente de faire cela en ajoutant valeur — une chaîne String de l’environnement de la fermeture — dans le vecteur sort_operations. La fermeture capture valeur et ensuite déplace valeur hors de la fermeture en transférant la possession de valeur au vecteur sort_operations. Cette fermeture ne peut être appelée qu’une seule fois ; une tentative de l’appeler une seconde fois ne fonctionnerait pas, car valeur ne serait plus dans l’environnement pour être à nouveau ajoutée dans sort_operations ! Par conséquent, cette fermeture n’implémente que FnOnce. Quand nous tentons de compiler ce code, nous obtenons cette erreur comme quoi valeur ne peut pas être déplacée en-dehors de la fermeture, car cette dernière doit implémenter FnMut :
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let valeur = String::from("fermeture appelée");
| ------ -------------------------------- move occurs because `valeur` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | liste.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | operations_tri.push(valeur);
| ^^^^^^ `valeur` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | operations_tri.push(valeur.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
L’erreur pointe vers la ligne du corps de la fermeture qui déplace valeur hors de l’environnement. Pour résoudre ce problème, nous devons changer le corps de la fermeture de manière à ce qu’elle ne déplace plus de valeurs hors de l’environnement. Garder un compteur dans l’environnement et incrémenter sa valeur dans le corps de la fermeture est une manière bien plus simple de compter le nombre de fois où la fermeture est appelée. La fermeture dans l’encart 13-9 fonctionne avec sort_by_key car elle ne peut capturer qu’une référence mutable au compteur nb_operations_tri et peut dès lors être appelée plus d’une fois.
#[derive(Debug)]
struct Rectangle {
largeur: u32,
hauteur: u32,
}
fn main() {
let mut liste = [
Rectangle { largeur: 10, hauteur: 1 },
Rectangle { largeur: 3, hauteur: 5 },
Rectangle { largeur: 7, hauteur: 12 },
];
let mut nb_operations_tri = 0;
liste.sort_by_key(|r| {
nb_operations_tri += 1;
r.largeur
});
println!("{liste:#?}, triée en {nb_operations_tri} opérations");
}FnMut closure with sort_by_key is allowed.Les traits Fn sont importants lors de la définition ou de l’utilisation de fonctions ou de types qui font appel à les fermetures. Dans la prochaine section, nous aborderons les itérateurs. De nombreuses méthodes d’itérateurs prennent des fermetures en arguments, donc gardez bien en tête ces détails concernant les fermetures à mesure que nous progressons !
Traiter une série d'éléments avec des itérateurs
Traiter une série d’éléments avec des itérateurs
Les itérateurs vous permettent d’effectuer une tâche sur une séquence d’éléments à tour de rôle. Un itérateur est responsable de la logique d’itération sur chaque élément et de déterminer lorsque la séquence est terminée. Lorsque nous utilisons des itérateurs, nous n’avons pas besoin de ré-implémenter cette logique nous-mêmes.
En Rust, un itérateur est une évaluation paresseuse, ce qui signifie qu’il n’a aucun effet jusqu’à ce que nous appelions des méthodes qui consomment l’itérateur pour l’utiliser. Par exemple, le code dans l’encart 13-10 crée un itérateur sur les éléments du vecteur v1 en appelant la méthode iter définie sur Vec<T>. Ce code en lui-même ne fait rien d’utile.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}L’itérateur est stocké dans la variable v1_iter. Une fois que nous avons créé un itérateur, nous pouvons l’utiliser de diverses manières. Dans l’encart 3-5 du chapitre 3, nous avions utilisé des itérateurs avec des boucles for pour exécuter du code sur chaque élément. Sous le capot, cela crée implicitement puis consomme un itérateur, mais jusqu’à présent, nous avons escamoté la manière dont cela fonctionne exactement.
Dans l’exemple de l’encart 13-11, nous séparons la création de l’itérateur de son utilisation dans la boucle for. Quand la boucle for est appelée en utilisant l’itérateur dans v1_iter, chaque élément de l’itérateur est utilisé au cours d’une itération de la boucle, ce qui permet d’afficher chaque valeur.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {
println!("On a : {val}");
}
}for loopDans les langages qui n’ont pas d’itérateurs fournis par leur bibliothèque standard, nous écririons probablement cette même fonctionnalité en démarrant une variable à l’indice 0, en utilisant cette variable comme indice sur le vecteur afin d’obtenir une valeur puis en incrémentant la valeur de cette variable dans une boucle jusqu’à ce qu’elle atteigne le nombre total d’éléments dans le vecteur.
Les itérateurs s’occupent de toute cette logique pour nous, réduisant le code redondant dans lequel nous pourrions potentiellement faire des erreurs. Les itérateurs nous donnent plus de flexibilité pour utiliser la même logique avec de nombreux types de séquences différentes, et pas seulement avec des structures de données avec lesquelles nous pouvons utiliser des indices, telles que les vecteurs. Voyons comment les itérateurs font cela.
Le trait Iterator et la méthode next
Tous les itérateurs implémentent un trait appelé Iterator qui est défini dans la bibliothèque standard. La définition du trait ressemble à ceci :
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// les méthodes avec des implémentations par défaut ont été exclues
}
}Remarquez que cette définition utilise une nouvelle syntaxe : type Item et Self::Item, qui définissent un type associé à ce trait. Nous verrons ce que sont les types associés au chapitre 20. Pour l’instant, tout ce que vous devez savoir est que ce code dit que l’implémentation du trait Iterator nécessite que vous définissiez aussi un type Item, et ce type Item est utilisé dans le type de retour de la méthode next. En d’autres termes, le type Item sera le type retourné par l’itérateur.
Le trait Iterator exige la définition d’une seule méthode par les développeurs : la méthode next, qui retourne un élément de l’itérateur à la fois intégré dans un Some, et lorsque l’itération est terminée, il retourne None.
On peut appeler la méthode next directement sur les itérateurs ; l’encart 13-12 montre quelles valeurs sont retournées par des appels répétés à next sur l’itérateur créé à partir du vecteur.
#[cfg(test)]
mod tests {
#[test]
fn demo_iterateur() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}next method on an iteratorRemarquez que nous avons eu besoin de rendre mutable v1_iter : appeler la méthode next sur un iterator change son état interne qui garde en mémoire l’endroit où il en est dans la séquence. En d’autres termes, ce code consomme, ou utilise, l’itérateur. Chaque appel à next consomme un élément de l’itérateur. Nous n’avions pas eu besoin de rendre mutable v1_iter lorsque nous avions utilisé une boucle for parce que la boucle avait pris possession de v1_iter et l’avait rendu mutable en coulisses.
Notez également que les valeurs que nous obtenons des appels à next sont des références immuables aux valeurs dans le vecteur. La méthode iter produit un itérateur pour des références immuables. Si nous voulons créer un itérateur qui prend possession de v1 et retourne les valeurs possédées, nous pouvons appeler into_iter au lieu de iter. De même, si nous voulons itérer sur des références mutables, nous pouvons appeler iter_mut au lieu de iter.
Les méthodes qui consomment un itérateur
Le trait Iterator a un certain nombre de méthodes différentes avec des implémentations par défaut que nous fournit la bibliothèque standard ; vous pouvez découvrir ces méthodes en regardant dans la documentation de l’API de la bibliothèque standard pour le trait Iterator. Certaines de ces méthodes appellent la méthode next dans leur définition, c’est pourquoi nous devons toujours implémenter la méthode next lors de l’implémentation du trait Iterator.
Les méthodes qui appellent next sont appelées des adaptateurs de consommation, parce que les appeler consomme l’itérateur. Un exemple est la méthode sum, qui prend possession de l’itérateur et itére sur ses éléments en appelant plusieurs fois next, consommant ainsi l’itérateur. A chaque étape de l’itération, il ajoute chaque élément à un total en cours et retourne le total une fois l’itération terminée. L’encart 13-13 a un test illustrant une utilisation de la méthode sum :
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}sum method to get the total of all items in the iteratorNous ne sommes pas autorisés à utiliser v1_iter après l’appel à sum car sum a pris possession de l’itérateur avec lequel nous l’appelons.
Méthodes qui produisent d’autres itérateurs
Les adaptateurs d’itération sont des méthodes définies sur le trait Iterator qui ne consomment pas l’itérateur. À la place, ils produisent différents itérateurs en changeant certains aspects de l’itérateur d’origine.
L’encart 13-14 montre un exemple d’appel à la méthode d’adaptation d’itération map, qui prend en paramètre une fermeture qui va s’exécuter sur chaque élément au fur et à mesure que les éléments sont itérés. La fermeture crée ici un nouvel itérateur dans lequel chaque élément du vecteur a été incrémenté de 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}map to create a new iteratorCependant, ce code déclenche un avertissement :
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Le code dans l’encart 13-14 ne fait rien ; la fermeture que nous avons renseignée n’est jamais exécutée. L’avertissement nous rappelle pourquoi : les adaptateurs d’itération sont des évaluations paresseuses, c’est pourquoi nous devons consommer l’itérateur ici.
Pour corriger ceci et consommer l’itérateur, nous utiliserons la méthode collect, que vous avez utilisé avec env::args dans l’encart 12-1 du chapitre 12. Cette méthode consomme l’itérateur et collecte les valeurs résultantes dans un type de collection de données.
Dans l’encart 13-15, nous recueillons les résultats de l’itération sur l’itérateur qui sont retournés par l’appel à map sur un vecteur. Ce vecteur finira par contenir chaque élément du vecteur original incrémenté de 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}map method to create a new iterator, and then calling the collect method to consume the new iterator and create a vectorComme map prend en paramètre une fermeture, nous pouvons renseigner n’importe quelle opération que nous souhaitons exécuter sur chaque élément. C’est un bon exemple de la façon dont les fermetures nous permettent de personnaliser certains comportements tout en réutilisant le comportement d’itération fourni par le trait Iterator.
Nous pouvons enchaîner plusieurs appels à des adaptateurs d’itération pour effectuer des actions complexes de manière compréhensible. Mais comme les itérateurs sont des évaluations paresseuses, nous devons faire appel à l’une des méthodes d’adaptation de consommation pour obtenir les résultats des appels aux adaptateurs d’itération.
Fermetures capturant leur environnement
De nombreux adaptateurs d’itération prenent des fermetures comme arguments, et ces fermetures que nous passons comme arguments aux adaptateurs d’itération seront des fermetures qui capturent leur environnement.
Pour cet exemple, nous utiliserons la méthode filter, qui prend une fermeture. La fermeture prend un élément de l’itérateur et renvoie un bool. Si la fermeture renvoie true, la valeur sera inclue dans l’itération produite par filter. Si la fermeture renvoie false, la valeur ne sera pas inclue.
Dans l’encart 13-16, nous utilisons filter avec une fermeture qui capture la variable pointure_chaussure de son environnement pour itérer sur une collection d’instances de la structure Chaussure. Il ne retournera que les chaussures avec la pointure demandée.
#[derive(PartialEq, Debug)]
struct Chaussure {
pointure: u32,
style: String,
}
fn chaussures_a_la_pointure(chaussures: Vec<Chaussure>, pointure_chaussure: u32) -> Vec<Chaussure> {
chaussures.into_iter().filter(|s| s.pointure == pointure_chaussure).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filtres_par_pointure() {
let chaussures = vec![
Chaussure {
pointure: 10,
style: String::from("basket"),
},
Chaussure {
pointure: 13,
style: String::from("sandale"),
},
Chaussure {
pointure: 10,
style: String::from("botte"),
},
];
let a_ma_pointure = chaussures_a_la_pointure(chaussures, 10);
assert_eq!(
a_ma_pointure,
vec![
Chaussure {
pointure: 10,
style: String::from("basket")
},
Chaussure {
pointure: 10,
style: String::from("botte")
},
]
);
}
}filter method with a closure that captures shoe_sizeLa fonction chaussures_a_la_pointure prend possession d’un vecteur de chaussures et d’une pointure comme paramètres. Il retourne un vecteur contenant uniquement des chaussures de la pointure demandée.
Dans le corps de chaussures_a_la_pointure, nous appelons into_iter pour créer un itérateur qui prend possession du vecteur. Ensuite, nous appelons filter pour adapter cet itérateur dans un nouvel itérateur qui ne contient que les éléments pour lesquels la fermeture retourne true.
La fermeture capture le paramètre pointure_chaussure de l’environnement et compare la valeur avec la pointure de chaque chaussure, en ne gardant que les chaussures de la pointure spécifiée. Enfin, l’appel à collect retourne un vecteur qui regroupe les valeurs renvoyées par l’itérateur.
Le test confirme que lorsque nous appelons chaussures_a_la_pointure, nous n’obtenons que des chaussures qui ont la même pointure que la valeur que nous avons demandée.
Amélioration de notre projet d'entrée/sortie
Amélioration de notre projet d’entrée/sortie
Grâce à ces nouvelles connaissances sur les itérateurs, nous pouvons améliorer le projet d’entrée/sortie du chapitre 12 en utilisant des itérateurs pour rendre certains endroits du code plus clairs et plus concis. Voyons comment les itérateurs peuvent améliorer notre implémentation de la fonction Config::build et de la fonction rechercher.
Supprimer l’appel à clone à l’aide d’un itérateur
Dans l’encart 12-6, nous avions ajouté du code qui prenait une slice de String et qui créait une instance de la structure Config en utilisant les indices de la slice et en clonant les valeurs, permettant ainsi à la structure Config de posséder ces valeurs. Dans l’encart 13-17, nous avons reproduit l’implémentation de la fonction Config::build telle qu’elle était dans l’encart 12-23 à la fin du chapitre 12 :
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
let ignore_casse = env::var("IGNORE_CASSE").is_ok();
Ok(Config {
recherche,
chemin_fichier,
ignore_casse,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}Config::build function from Listing 12-23À ce moment-là, nous avions dit de ne pas s’inquiéter des appels inefficaces à clone parce que nous les supprimerions à l’avenir. Et bien, ce moment est venu !
Nous avions besoin de clone ici parce que nous avons une slice d’éléments String dans le paramètre args, mais la fonction build ne possède pas args. Pour renvoyer la propriété d’une instance de Config, nous avons dû cloner les valeurs des champs recherche et chemin_fichier de Config afin que cette instance de Config puisse prendre possession de ces valeurs.
Avec nos nouvelles connaissances sur les itérateurs, nous pouvons changer la fonction new pour prendre possession d’un itérateur passé en argument au lieu d’emprunter une slice. Nous utiliserons les fonctionnalités des itérateurs à la place du code qui vérifie la taille de la slice et qui utilise les indices des éléments précis. Cela clarifiera ce que la fonction Config::new fait car c’est l’itérateur qui accédera aux valeurs.
Une fois que Config::build prend possession de l’itérateur et cesse d’utiliser les opérations avec les indices et d’emprunter les données, nous pouvons déplacer les valeurs String de l’iterator dans Config plutôt que de faire appel à clone et de créer par conséquent de nouvelles allocations.
Utiliser directement l’itérateur retourné
Ouvrez le fichier src/main.rs de votre projet d’entrée/sortie, qui devrait ressembler à ceci :
Fichier : src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
// -- partie masquée ici --
if let Err(e) = run(config) {
eprintln!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
let ignore_casse = env::var("IGNORE_CASSE").is_ok();
Ok(Config {
recherche,
chemin_fichier,
ignore_casse,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}Nous allons commencer par changer le début de la fonction main que nous avions dans l’encart 12-24 pour le code dans l’encart 13-18 qui, cette fois-ci, utilise un itérateur. Ceci ne compilera pas encore jusqu’à ce que nous mettions également à jour Config::build.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
// -- partie masquée ici --
if let Err(e) = run(config) {
eprintln!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
let ignore_casse = env::var("IGNORE_CASSE").is_ok();
Ok(Config {
recherche,
chemin_fichier,
ignore_casse,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}env::args to Config::buildLa fonction env::args retourne un itérateur ! Plutôt que de collecter les valeurs de l’itérateur dans un vecteur et de passer ensuite une slice à Config::build, nous passons maintenant la possession de l’itérateur de env::args directement à Config::build.
Ensuite, nous devons mettre à jour la définition de Config::build. Modifions la signature de Config::build pour qu’elle ressemble à l’encart 13-16. Ceci ne compilera pas encore car nous devons mettre à jour le corps de la fonction.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// -- partie masquée ici --
if args.len() < 3 {
return Err("il n'y a pas assez d'arguments");
}
let recherche = args[1].clone();
let chemin_fichier = args[2].clone();
let ignore_casse = env::var("IGNORE_CASSE").is_ok();
Ok(Config {
recherche,
chemin_fichier,
ignore_casse,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}Config::build to expect an iteratorLa documentation de la bibliothèque standard pour la fonction env::args indique que le type de l’itérateur qu’elle renvoie est std::env::Args, et que ce type implémente le trait Iterator et renvoie des valeurs de type String.“
Nous avons mis à jour la signature de la fonction Config::build de manière à ce que le paramètre args ait un type générique avec les contraintes de trait impl Iterator<Item = String> au lieu de &[String]. Cette utilisation de la syntaxe impl Trait, dont nous avons parlé dans la section “Utilisation des traits comme paramètres” du chapitre 10, signifie que args peut être de n’importe quel type qui implémente le trait Iterator et renvoie des éléments de type String.
Comme nous prenons possession de args et que nous allons le modifierargs en le parcourant, nous pouvons ajouter le mot-clé mut dans la spécification du paramètre args pour le rendre modifiable.
Utilisation des méthodes du trait Iterator
Corrigeons ensuite le corps de Config::build. Comme args implémente le trait Iterator, nous savons que nous pouvons appeler la méthode next dessus ! L’encart 13-20 met à jour le code de l’encart 12-23 afin d’utiliser la méthode next :
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{rechercher, rechercher_insensible_casse};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problème rencontré lors de l'interprétation des arguments : {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Erreur applicative : {e}");
process::exit(1);
}
}
pub struct Config {
pub recherche: String,
pub chemin_fichier: String
pub ignore_casse: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let recherche = match args.next() {
Some(arg) => arg,
None => return Err("nous n'avons pas de chaîne de caractères"),
};
let nom_fichier = match args.next() {
Some(arg) => arg,
None => return Err("nous n'avons pas de nom de fichier"),
};
let ignore_casse = env::var("IGNORE_CASSE").is_ok();
Ok(Config {
recherche,
chemin_fichier,
ignore_casse,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contenu = fs::read_to_string(config.chemin_fichier)?;
let resultats = if config.sensible_casse {
rechercher_insensible_casse(&config.recherche, &contenu)
} else {
recherche(&config.recherche, &contenu)
};
for ligne in resultats {
println!("{ligne}");
}
Ok(())
}Config::build to use iterator methodsRappelez-vous que la première valeur de ce qui est retourné par env::args est le nom du programme. Nous voulons ignorer cette valeur et passer à la suivante, donc d’abord nous appelons une fois next et nous ne faisons rien avec sa valeur de retour. Ensuite, nous appelons next pour obtenir la valeur que nous voulons mettre dans le champ recherche de Config. Si next renvoie un Some, nous utilisons un match pour extraire sa valeur. S’il retourne None, cela signifie que pas assez d’arguments ont été fournis, si bien que nous quittons aussitôt la fonction en retournant une valeur Err. Nous procédons de même pour la valeur chemin_fichier.
Clarification du code avec des adaptateurs d’itération
Nous pouvons également tirer parti des itérateurs dans la fonction rechercher de notre projet d’entrée/sortie, qui est reproduite ici dans l’encart 13-21, telle qu’elle était dans l’encart 12-19.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
let mut resultats = Vec::new();
for ligne in contenu.lines() {
if ligne.contains(recherche) {
resultats.push(ligne);
}
}
resultats
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_resultat() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
}search function from Listing 12-19Nous pouvons écrire ce code de façon plus concise en utilisant des méthodes des adaptateurs d’itération. Ce faisant, nous évitons ainsi d’avoir le vecteur mutable resultats. Le style de programmation fonctionnelle préfère minimiser la quantité d’états modifiables pour rendre le code plus clair. Supprimer l’état mutable pourrait nous aider à faire une amélioration future afin que la recherche se fasse en parallèle, car nous n’aurions pas à gérer l’accès concurrent au vecteur resultats. L’encart 13-22 montre ce changement.
pub fn rechercher<'a>(recherche: &str, contenu: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|ligne| ligne.contains(recherche))
.collect()
}
pub fn rechercher_insensible_casse<'a>(
recherche: &str,
contenu: &'a str,
) -> Vec<&'a str> {
let recherche = recherche.to_lowercase();
let mut resultats = Vec::new();
for ligne in contenu.lines() {
if ligne.to_lowercase().contains(&recherche) {
resultats.push(ligne);
}
}
resultats
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn sensible_casse() {
let recherche = "duct";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.
Duct tape.";
assert_eq!(vec!["sécurité, rapidité, productivité."], rechercher(recherche, contenu));
}
#[test]
fn insensible_casse() {
let recherche = "rUsT";
let contenu = "\
Rust:
sécurité, rapidité, productivité.
Obtenez les trois en même temps.
C'est pas rustique.";
assert_eq!(
vec!["Rust:", "C'est pas rustique."],
rechercher_insensible_casse(recherche, contenu)
);
}
}search functionSouvenez-vous que le but de la fonction rechercher est de renvoyer toutes les lignes dans contenu qui contiennent recherche. Comme dans l’exemple de filter dans l’encart 13-16, ce code utilise l’adaptateur filter pour ne garder que les lignes pour lesquelles ligne.contains(recherche) renvoie true. Nous collectons ensuite les lignes correspondantes dans un autre vecteur avec collect. C’est bien plus simple ! N’hésitez pas à faire le même changement pour utiliser les méthodes d’itération dans la fonction rechercher_insensible_casse.
Pour encore améliorer le code, renvoyez un itérateur depuis la fonction search en supprimant l’appel à collect et en changeant le type de retour à impl Iterator<Item = &'a str>, de sorte que la fonction devienne un adaptateur d’itérateur. Notez que vous devrez aussi mettre à jour les tests ! Faites une recherche dans un fichier volumineux en utilisant votre outil minigrep avant et après avoir procédé à ces changements, afin d’observer la différence de comportement. Avant cette modification, le programme n’affichait aucun résultat tant qu’il n’avait pas collecté tous les résultats, mais après la modification, les résultats vont s’afficher à mesure que chaque ligne correspondant au motif est trouvée, car la boucle for dans la fonction run est capable de tirer parti du fait que l’itérateur fait des évaluations paresseuses.
Choix entre boucles et itérateurs
Logiquement, la question suivante est de savoir quel style utiliser dans votre propre code et pourquoi : l’implémentation originale de l’encart 13-21 ou la version utilisant l’itérateur dans l’encart 13-22 (en supposition que nous collections tous les résultats avant de les retourner, au lieu de retourner l’itérateur). La plupart des développeurs Rust préfèrent utiliser le style avec l’itérateur. C’est un peu plus difficile à comprendre au début, mais une fois que vous avez compris les différents adaptateurs d’itération et ce qu’ils font, les itérateurs peuvent devenir plus faciles à comprendre. Au lieu de jongler avec différentes boucles et de construire de nouveaux vecteurs, ce code se concentre sur l’objectif de haut niveau de la boucle. Cette abstraction permet d’éliminer une partie du code trivial, de sorte qu’il soit plus facile de dégager les concepts propres à ce code, comme le filtrage de chaque élément de l’itérateur qui est appliqué.
Mais ces deux implémentations sont-elles réellement équivalentes ? L’hypothèse intuitive pourrait être que la boucle de plus bas niveau sera plus rapide. Intéressons nous donc maintenant à leurs performances.
Comparaison des performances : les boucles et les itérateurs
Comparaison des performances : les boucles et les itérateurs
Pour déterminer s’il faut utiliser des boucles ou des itérateurs, nous devons savoir quelle implémentation est la plus rapide : la version de la fonction rechercher avec une boucle for explicite, ou la version avec des itérateurs.
Nous avons lancé un benchmark en chargeant tout le contenu de The Adventures of Sherlock Holmes de Sir Arthur Conan Doyle dans une String et en cherchant le mot “the” dans le contenu. Voici les résultats du benchmark sur la version de rechercher avec une boucle for et avec un itérateur :
test bench_rechercher_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_rechercher_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Les deux implémentations ont des performances similaires ! Nous n’expliquerons pas le code du benchmark ici, car il ne s’agit pas de prouver que les deux versions sont équivalentes, mais d’avoir une idée générale de la différence de performances entre les deux.
Pour un benchmark plus complet, nous vous conseillons d’utiliser des textes de différentes tailles pour contenu, des mots différents et de différentes longueurs pour recherche, ainsi que tout autre type de variation que vous pourriez trouver. Le point important est le suivant : les itérateurs, bien qu’il s’agisse d’une abstraction de haut niveau, sont compilés à peu près comme si vous aviez écrit vous-même le code un niveau plus bas. Les itérateurs sont l’une des abstractions à coût zéro de Rust, c’est-à-dire que l’utilisation de l’abstraction n’impose aucun surcoût lors de l’exécution. C’est la même notion que celle que Bjarne Stroustrup, le concepteur et développeur original de C++, définit en tant que coût zéro dans son discours d’ouverture à l’ETAPS de 2012 intitulé “Foundations of C++” :
En général, les implémentations de C++ obéissent au principe du coût zéro : ce que vous n’utilisez pas, vous ne le payez pas. Et plus encore : ce que vous utilisez, vous ne pourrez pas le coder mieux à la main.
Dans de nombreux cas, le code Rust utilisant des itérateurs se compile en un code assembleur identiques à celui que vous écririez à la main. Des optimisations telles que le déroulement des boucles et la suppression des vérifications des bornes lors des accès aux tableaux s’appliquent, ce qui rend le code produit extrêmement efficace. Maintenant que vous savez cela, vous pouvez utiliser des itérateurs et des fermetures sans crainte ! Ils font en sorte que le code paraisse de haut niveau, mais n’entraînent pas de pénalité de performance à l’exécution.
Résumé
Les fermetures et les itérateurs sont des fonctionnalités de Rust inspirées par des idées des langages de programmation fonctionnels. Ils contribuent à la capacité de Rust d’exprimer clairement des idées de haut niveau avec des performances dignes d’un langage de bas niveau. Les implémentations des fermetures et des itérateurs sont telles que les performances à l’exécution n’en sont pas affectées. Cela fait partie de l’objectif de Rust de s’efforcer à fournir des abstractions à coût zéro.
Maintenant que nous avons amélioré l’expressivité de notre projet d’entrée/sortie, regardons d’autres fonctionnalités fournies par cargo qui nous aideront à partager notre projet avec le monde entier.
En savoir plus sur cargo et crates.io
Précédemment, nous avons utilisé les fonctionnalités les plus basiques de cargo pour compiler, exécuter et tester notre code, mais il peut faire bien plus. Dans ce chapitre, nous allons voir d’autres fonctionnalités avancées pour vous apprendre à faire ceci :
- Personnaliser votre compilation grâce aux profils de publication.
- Publier des bibliothèques sur crates.io.
- Organiser des gros projets avec les espaces de travail.
- Installer des binaires à partir de crates.io.
- Améliorer cargo en utilisant des commandes personnalisées.
Cargo peut faire encore plus de choses que les fonctionnalités que nous allons voir dans ce chapitre, donc pour une explication plus complète vous avez à votre disposition sa documentation.
Personnaliser les compilations avec les profils de publication
Personnaliser les compilations avec les profils de publication
Dans Rust, les profils de publication sont des profils prédéfinis et personnalisables avec différentes configurations qui permettent au développeur d’avoir plus de contrôle sur différentes options de compilation du code. Chaque profil est configuré indépendamment des autres.
Cargo a deux profils principaux : le profil dev que cargo utilise lorsque vous lancez cargo build et le profil release (NdT : publication) que cargo utilise lorsque vous lancez cargo build --release. Le profil dev est défini avec de bons réglages par défaut pour le développement, et le profil release a de bons réglages par défaut de compilation pour la publication.
Ces noms de profils vous rappellent peut-être quelque chose sur la sortie standard de vos compilations :
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
Les profils dev et release sont ces différents profils qu’utilise le compilateur.
Cargo a des réglages par défaut pour chacun des profils qui s’appliquent quand vous n’avez pas explicitement ajouté de sections [profile.*] dans le fichier Cargo.toml du projet. En ajoutant les sections [profile.*] pour chaque profil que vous souhaitez personnaliser, vous pouvez remplacer n’importe quel paramètre par défaut. Par exemple, voici les valeurs par défaut pour le paramètre opt-level des profils dev et release :
Fichier : Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Le paramètre opt-level contrôle le nombre d’optimisations que Rust va appliquer à votre code, sur une échelle allant de 0 à 3. L’application d’un niveau plus haut d’optimisation signifie un allongement de la durée de compilation, donc si vous êtes en train de développer et que vous compilez souvent votre code, vous préférerez avoir moins d’optimisations pour compiler plus rapidement, même si le code qui en résulte s’exécute plus lentement. La valeur par défaut de opt-level pour dev est donc à 0. Lorsque vous serez prêt à publier votre code, il sera préférable de passer un peu plus de temps à le compiler. Vous ne compilerez en mode publication (NdT : release) qu’une seule fois, mais vous exécuterez le programme compilé plusieurs fois, donc le mode publication opte pour un temps de compilation plus long afin que le code s’exécute plus rapidement. C’est pourquoi le paramètre opt-level par défaut pour le profil release est à 3.
Vous pouvez remplacer un paramètre par défaut en ajoutant une valeur différente dans Cargo.toml. Par exemple, si nous voulons utiliser le niveau 1 d’optimisation dans le profil de développement, nous pouvons ajouter ces deux lignes à notre fichier Cargo.toml :
Fichier : Cargo.toml
[profile.dev]
opt-level = 1
Ce code remplace le paramètre par défaut à 0. Maintenant, lorsque nous lançons cargo build, cargo va utiliser les réglages par défaut du profil dev ainsi que notre valeur personnalisée de opt-level. Comme nous avons réglé opt-level à 1, Cargo va appliquer plus d’optimisation que par défaut, mais pas autant que dans une compilation de publication.
Pour la liste complète des options de configuration et leurs valeurs par défaut pour chaque profil, référez-vous à la documentation de cargo.
Publier une crate sur crates.io
Publier une crate sur crates.io
Nous avons déjà utilisé des paquets provenant de crates.io comme dépendance de notre projet, mais vous pouvez aussi partager votre code avec d’autres personnes en publiant vos propres paquets. Le registre des crates disponible sur crates.io distribue le code source de vos paquets, donc il héberge principalement du code qui est open source.
Rust et cargo ont des fonctionnalités qui font en sorte que les paquets que vous publiez sont aisés à trouver et utiliser pour les autres développeurs. Nous allons voir certaines de ces fonctionnalités puis nous allons expliquer comment publier un paquet.
Créer des commentaires de documentation utiles
Documenter correctement vos paquets aidera les autres utilisateurs à savoir comment et quand les utiliser, donc ça vaut la peine de consacrer du temps à la rédaction de la documentation. Dans le chapitre 3, nous avons vu comment commenter du code Rust en utilisant deux barres obliques //. Rust a aussi un type particulier de commentaire pour la documentation, aussi connu sous le nom de commentaire de documentation, qui va générer de la documentation en HTML. Le HTML affiche le contenu des commentaires de documentation pour les éléments public de votre API à destination des développeurs qui s’intéressent à la manière d’utiliser votre crate et non pas à la manière dont elle est implémentée.
Les commentaires de documentation utilisent trois barres obliques /// au lieu de deux et prennent en charge la notation Markdown pour mettre en forme le texte. Placez les commentaires de documentation juste avant l’élément qu’ils documentent. L’encart 14-1 montre des commentaires de documentation pour une fonction ajouter_un dans une crate nommée ma_crate.
/// Ajoute 1 au nombre donné.
///
/// # Exemples
///
/// ```
/// let argument = 5;
/// let reponse = ma_crate::ajouter_un(argument);
///
/// assert_eq!(6, reponse);
/// ```
pub fn ajouter_un(x: i32) -> i32 {
x + 1
}Ici nous avons écrit une description de ce que fait la fonction ajouter_un, débuté une section avec le titre Exemples puis fourni du code qui montre comment utiliser la fonction ajouter_un. Nous pouvons générer la documentation HTML à partir de ces commentaires de documentation en lançant cargo doc. Cette commande lance l’outil rustdoc qui est distribué avec Rust et place la documentation HTML générée dans le répertoire target/doc.
Pour plus de facilité, lancer cargo doc --open va générer le HTML pour la documentation de votre crate courante (ainsi que la documentation pour toutes les dépendances de la crate) et ouvrir le résultat dans un navigateur web. Rendez-vous à la fonction ajouter_one et vous découvrirez comment le texte dans les commentaires de la documentation a été interprété, ce qui devrait ressembler à l’illustration 14-1.
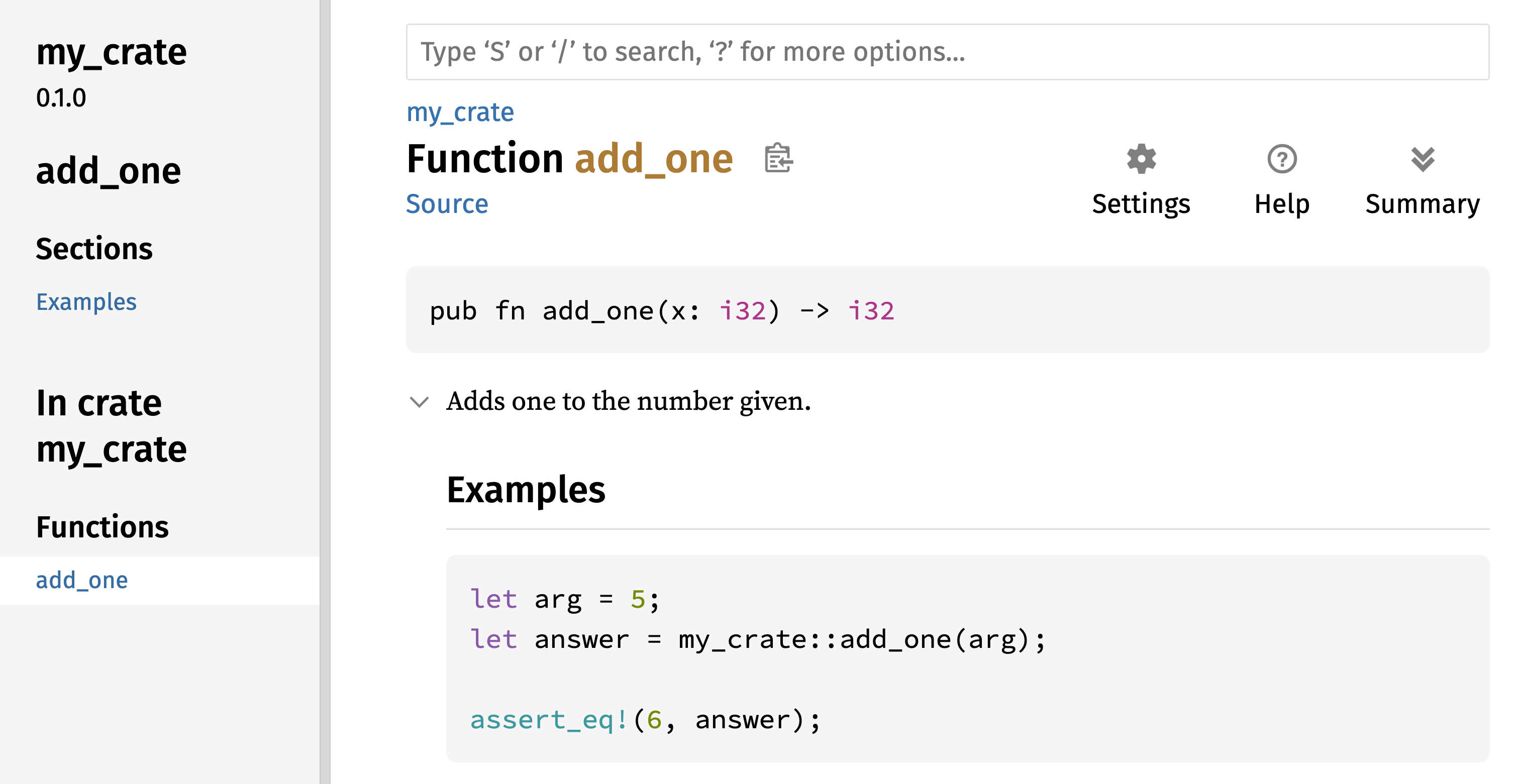
Illustration 14-1 : Documentation HTML pour la fonction ajouter_un
Les sections utilisées fréquemment
Nous avons utilisé le titre en Markdown # Exemples dans l’encart 14-1 afin de créer une section dans le HTML avec le titre “Exemples”. Voici d’autres sections que les auteurs de crate utilisent fréquemment dans leur documentation :
- Panics : il s’agit des scénarios dans lesquels la fonction qui est documentée peut paniquer. Ceux qui utilisent la fonction et qui ne veulent pas que leur programme panique doivent s’assurer qu’ils n’appellent pas la fonction dans ce genre de situation.
- Errors : si la fonction retourne un
Result, documenter les types d’erreurs qui peuvent survenir ainsi que les conditions qui mènent à ces erreurs sera très utile pour ceux qui utilisent votre API afin qu’ils puissent écrire du code pour gérer ces différents types d’erreurs de manière à ce que cela leur convienne. - Safety : si la fonction fait un appel à
unsafe(que nous verrons au chapitre 20), il devrait exister une section qui explique pourquoi la fonction fait appel à unsafe et quels sont les paramètres que la fonction s’attend à recevoir des utilisateurs de l’API.
La plupart des commentaires sur la documentation n’ont pas besoin de ces sections, mais c’est une bonne liste de vérifications à avoir pour vous rappeler les éléments importants à signaler aux utilisateurs de votre code.
Les commentaires de documentation pour faire des tests
L’ajout des blocs de code d’exemple dans vos commentaires de documentation peut vous aider à montrer comment utiliser votre bibliothèque, et ceci apporte un bonus supplémentaire : l’exécution de cargo test va lancer les codes d’exemples présents dans votre documentation comme étant des tests ! Il n’y a rien de mieux que de la documentation avec des exemples. Mais il n’y a rien de pire que des exemples qui ne fonctionnent plus car le code a changé depuis que la documentation a été écrite. Si nous lançons cargo test avec la documentation de la fonction ajouter_un de l’encart 14-1, nous verrons une section dans les résultats de tests comme celle-ci :
Doc-tests ma_crate
running 1 test
test src/lib.rs - ajouter_un (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Maintenant, si nous changeons la fonction ou l’exemple de telle sorte que le assert_eq! de l’exemple panique et que nous lançons cargo test à nouveau, nous verrons que les tests de documentation vont découvrir que l’exemple et le code sont désynchronisés l’un de l’autre !
Commentaires de l’élément contenant l’élément courant
Le style de commentaire de documentation //! ajoute de la documentation à l’élément qui contient ce commentaire plutôt qu’aux éléments qui suivent ce commentaire. Nous utilisons habituellement ces commentaires de documentation dans le fichier de la crate racine (qui est src/lib.rs par convention) ou à l’intérieur d’un module afin de documenter la crate ou le module dans son ensemble.
Par exemple, pour ajouter de la documentation qui décrit le rôle de la crate ma_crate qui contient la fonction ajouter_un, nous ajoutons des commentaires de documentation qui commencent par //! au début du fichier src/lib.rs, comme dans l’encart 14-2.
//! # Ma crate
//!
//! `ma_crate` est un regroupement d'utilitaires pour rendre plus pratique
//! certains calculs.
/// Ajoute 1 au nombre donné.
// -- partie masquée ici --
///
/// # Exemples
///
/// ```
/// let argument = 5;
/// let reponse = ma_crate::ajouter_un(argument);
///
/// assert_eq!(6, reponse);
/// ```
pub fn ajouter_un(x: i32) -> i32 {
x + 1
}my_crate crate as a wholeRemarquez qu’il n’y a pas de code après la dernière ligne qui commence par //!. Comme nous commençons les commentaires par //! au lieu de ///, nous documentons l’élément qui contient ce commentaire plutôt que l’élément qui suit ce commentaire. Dans notre cas, cet élément est le fichier src/lib.rs, qui est la racine de la crate. Ces commentaires vont décrire l’intégralité de la crate.
Lorsque nous lançons cargo doc --open, ces commentaires vont s’afficher sur la page d’accueil de la documentation de ma_crate, au-dessus de la liste des éléments publics de la crate, comme montré dans l’illustration 14-2.
Les commentaires de la documentation placés à l’intérieur des éléments sont particulièrement utiles pour décrire les crates et les modules. Utilisez-les pour expliquer globalement le rôle du conteneur pour aider vos utilisateurs à comprendre l’organisation de votre crate.
Illustration 14-2 : Documentation générée pour ma_crate, qui contient le commentaire qui décrit l’intégralité de la crate
Exporter une API publique conviviale
La structure de votre API publique est une question importante lorsque vous publiez une crate. Les personnes qui utilisent votre crate sont moins familiers avec la structure que vous l’êtes et pourraient avoir des difficultés à trouver les éléments qu’ils souhaitent utiliser si votre crate a une hiérarchie de module imposante.
Dans le chapitre 7, nous avons vu comment rendre publics des éléments en utilisant le mot-clé pub, et comment importer des éléments dans la portée en utilisant le mot-clé use. Cependant, la structure qui a un sens pour vous pendant que vous développez une crate peut ne pas être pratique pour vos utilisateurs. Vous pourriez vouloir organiser vos structures dans une hiérarchie qui a plusieurs niveaux, mais les personnes qui veulent utiliser un type que vous avez défini dans un niveau profond de la hiérarchie pourraient rencontrer des difficultés pour savoir que ce type existe. Ils peuvent aussi être agacés d’avoir à écrire use ma_crate::un_module::un_autre_module::TypeUtile; plutôt que use ma_crate::TypeUtile;.
La bonne nouvelle est que si la structure n’est pas pratique pour ceux qui l’utilisent dans une autre bibliothèque, vous n’avez pas à réorganiser votre organisation interne : à la place, vous pouvez ré-exporter les éléments pour créer une structure publique qui est différente de votre structure privée en utilisant pub use. Ré-exporter prend un élément public d’un endroit et le rend public dans un autre endroit, comme s’il était défini dans l’autre endroit.
Par exemple, disons que nous avons créé une bibliothèque art pour modéliser des concepts artistiques. À l’intérieur de cette bibliothèque nous avons deux modules : un module types qui contient deux énumérations CouleurPrimaire et CouleurSecondaire, et un module utilitaires qui contient une fonction mixer, comme dans l’encart 14-3.
//! # Art
//!
//! Une bibliothèque pour modéliser des concepts artistiques.
pub mod types {
/// Les couleurs primaires du modèle RJB.
pub enum CouleurPrimaire {
Rouge,
Jaune,
Bleu,
}
/// Les couleurs secondaires du modèle RJB.
pub enum CouleurSecondaire {
Orange,
Vert,
Violet,
}
}
pub mod utilitaires {
use crate::types::*;
/// Combine deux couleurs primaires dans les mêmes quantités pour
/// créer une couleur secondaire.
pub fn mixer(c1: CouleurPrimaire, c2: CouleurPrimaire) -> CouleurSecondaire {
// -- partie masquée ici --
unimplemented!();
}
}art library with items organized into kinds and utils modulesL’illustration 14-3 montre ce à quoi devrait ressembler la page d’accueil de la documentation de cette crate générée par cargo doc.
Illustration 14-3 : La page d’accueil de la documentation de art qui liste les modules types et utilitaires
Notez que les types CouleurPrimaire et CouleurSecondaire ne sont pas listés sur la page d’accueil, pas plus que la fonction mixer. Nous devons cliquer sur types et utilitaires pour les voir.
Une autre crate qui dépend de cette bibliothèque va avoir besoin d’utiliser l’instruction use pour importer les éléments de art dans sa portée, en suivant la structure du module qui est actuellement définie. L’encart 14-4 montre un exemple d’une crate qui utilise les éléments CouleurPrimaire et mixer de la crate art.
use art::types::CouleurPrimaire;
use art::utilitaires::mixer;
fn main() {
let rouge = CouleurPrimaire::Rouge;
let jaune = CouleurPrimaire::Jaune;
mixer(rouge, jaune);
}art crate’s items with its internal structure exportedL’auteur du code de l’encart 14-4, qui utilise la crate art, doit comprendre que CouleurPrimaire est dans le module types et que mixer est dans le module utilitaires. La structure du module de la crate art est bien plus pratique pour les développeurs qui travaillent sur la crate art que pour ceux qui l’utilisent. La structure interne ne contient aucune information utile à quelqu’un qui essaye de comprendre comment utiliser la crate art, mais elle est plutôt source de confusion car les développeurs qui l’utilisent doivent découvrir où trouver les éléments et doivent renseigner les noms des modules dans les instructions use.
Pour masquer l’organisation interne de l’API publique, nous pouvons modifier le code de la crate art de l’encart 14-3 pour ajouter l’instruction pub use pour ré-exporter les éléments au niveau supérieur, comme montré dans l’encart 14-5.
//! # Art
//!
//! Une bibliothèque pour modéliser des concepts artistiques.
pub use self::types::CouleurPrimaire;
pub use self::types::CouleurSecondaire;
pub use self::utilitaires::mixer;
pub mod types {
// -- partie masquée ici --
/// Les couleurs primaires du modèle RJB.
pub enum CouleurPrimaire {
Rouge,
Jaune,
Bleu,
}
/// Les couleurs secondaires du modèle RJB.
pub enum CouleurSecondaire {
Orange,
Vert,
Violet,
}
}
pub mod utilitaires {
// -- partie masquée ici --
use crate::types::*;
/// Combine deux couleurs primaires dans les mêmes quantités pour
/// créer une couleur secondaire.
pub fn mixer(c1: CouleurPrimaire, c2: CouleurPrimaire) -> CouleurSecondaire {
CouleurSecondaire::Orange
}
}pub use statements to re-export itemsLa documentation de l’API que cargo doc a générée pour cette crate va maintenant lister et lier les ré-exportations sur la page d’accueil, comme dans l’illustration 14-4, ce qui rend les types CouleurPrimaire et CouleurSecondaire plus faciles à trouver.
Illustration 14-4 : La page d’accueil de la documentation pour art qui liste les ré-exports
Les utilisateurs de la crate art peuvent toujours voir et utiliser la structure interne de l’encart 14-3 comme ils l’utilisaient dans l’encart 14-4, mais ils peuvent maintenant utiliser la structure plus pratique de l’encart 14-5, comme montré dans l’encart 14-6.
use art::CouleurPrimaire;
use art::mixer;
fn main() {
// -- partie masquée ici --
let rouge = CouleurPrimaire::Rouge;
let jaune = CouleurPrimaire::Jaune;
mixer(rouge, jaune);
}art crateDans les cas où il y a de nombreux modules imbriqués, ré-exporter les types au niveau le plus haut avec pub use peut faire une différence significative dans l’expérience utilisateur de ceux qui utilisent cette crate. Une autre utilisation courante de pub use est de réexporter les définitions d’une dépendance dans la crate courante afin d’intégrer les définitions de cette crate à l’API publique de votre crate.
Créer une structure d’API publique utile est plus un art qu’une science, et vous pouvez itérer plusieurs fois pour trouver une API qui fonctionne mieux pour vos utilisateurs. Choisir pub use vous donne de la flexibilité pour l’organisation interne de votre crate et découple la structure interne de ce que vous présentez aux utilisateurs. N’hésitez pas à regarder le code source des crates que vous avez installées pour voir si leur structure interne est différente de leur API publique.
Mise en place d’un compte crates.io
Avant de pouvoir publier une crate, vous devez créer un compte sur crates.io et obtenir un jeton d’API. Pour pouvoir faire cela, visitez la page d’accueil de crates.io et connectez-vous avec votre compte GitHub (le compte GitHub est actuellement une obligation, mais crates.io pourra permettre de créer un compte d’une autre manière un jour). Une fois identifié, consultez les réglages de votre compte à l’adresse https://crates.io/me/ et récupérez votre jeton d’API (NdT : API key). Ensuite, lancez la commande cargo login et collez votre clé d’API quand on vous le demande, comme ceci :
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Cette commande informera cargo de votre jeton d’API et l’enregistrera localement dans ~/.cargo/credentials. Notez que ce jeton est un secret : ne le partagez avec personne d’autre. Si vous le donnez à quelqu’un pour une quelconque raison, vous devriez le révoquer et générer un nouveau jeton sur crates.io.
Ajouter des métadonnées à une nouvelle crate
Imaginons que vous avez une crate que vous souhaitez publier. Avant de la publier, vous aurez besoin d’ajouter quelques métadonnées dans la section [package] du fichier Cargo.toml de votre crate.
Votre crate va avoir besoin d’un nom unique. Tant que vous travaillez en local, vous pouvez nommer un crate comme vous le souhaitez. Cependant, les noms des crates sur crates.io sont accordés selon le principe du premier arrivé, premier servi. Une fois qu’un nom de crate est accordé, personne d’autre ne peut publier une crate avec ce nom. Avant d’essayer de publier une crate, recherchez le nom que vous souhaitez utiliser. Si le nom a déjà été utilisé, vous allez devoir trouver un autre nom et modifier le champ name dans le fichier Cargo.toml sous la section [package] pour utiliser le nouveau nom pour la publication, comme ceci :
Fichier : Cargo.toml
[package]
name = "jeu_du_plus_ou_du_moins"
Même si vous avez choisi un nom unique, lorsque vous lancez cargo publish pour publier la crate à ce stade, vous allez avoir un avertissement suivi par une erreur :
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Cela entraîne une erreur, car il vous manque quelques informations essentielles : une description et une licence sont nécessaires pour que les gens puissent savoir ce que fait votre crate et sous quelles conditions ils peuvent l’utiliser. Dans Cargo.toml, ajoutez une description qui ne fait qu’une phrase ou deux, car elle va s’afficher à proximité de votre crate dans les résultats de recherche. Pour le champ license, vous devez donner une valeur d’identification de la licence (NdT : license identifier value). La Linux Foundation’s Software Package Data Exchange (SPDX) liste les identifiants que vous pouvez utiliser pour cette valeur. Par exemple, pour stipuler que votre crate est sous la licence MIT, ajoutez l’identifiant MIT :
Fichier : Cargo.toml
[package]
name = "jeu_du_plus_ou_du_moins"
license = "MIT"
Si vous voulez utiliser une licence qui n’apparaît pas dans le SPDX, vous devez placer le texte de cette licence dans un fichier, inclure ce fichier dans votre projet puis utiliser licence-file pour renseigner le nom de ce fichier plutôt que d’utiliser la clé licence.
Les conseils sur le choix de la licence appropriée pour votre projet sortent du cadre de ce livre. De nombreuses personnes dans la communauté Rust appliquent à leurs projets la même licence que Rust qui utilise la licence double MIT OR Apache-2.0. Cette pratique montre que vous pouvez également indiquer plusieurs identificateurs de licence séparés par OR pour avoir plusieurs licences pour votre projet.
Une fois le nom unique, la version, la description et la licence ajoutés, le fichier Cargo.toml de ce projet qui est prêt à être publié devrait ressembler à ceci :
Fichier : Cargo.toml
[package]
name = "jeu_du_plus_ou_du_moins"
version = "0.1.0"
edition = "2024"
description = "Un jeu où vous devez deviner quel nombre l'ordinateur a choisi."
license = "MIT OR Apache-2.0"
[dependencies]
La documentation de cargo décrit d’autres métadonnées que vous pouvez renseigner pour vous assurer que les autres développeurs puissent découvrir et utiliser votre crate plus facilement.
Publier sur crates.io
Maintenant que vous avez créé un compte, sauvegardé votre jeton de clé, choisi un nom pour votre crate, et précisé les métadonnées requises, vous êtes prêt à publier ! Publier une crate téléverse une version précise sur crates.io pour que les autres puissent l’utiliser.
Faites attention, car une publication est permanente. La version ne pourra jamais être remplacée, et le code ne pourra jamais être effacé, sauf dans des cas particuliers. Le but majeur de crates.io est de fournir une archive durable de code afin que les compilations de tous les projets qui dépendent des crates de crates.io puissent toujours continuer à fonctionner. Si la suppression de version était autorisée, cela rendrait ce but impossible. Cependant, il n’y a pas de limites au nombre de versions de votre crate que vous pouvez publier.
Lancez la commande cargo publish à nouveau. Elle devrait fonctionner à présent :
$ cargo publish
Updating crates.io index
Packaging jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Compiling jeu_du_plus_ou_du_moins v0.1.0
(file:///projects/jeu_du_plus_ou_du_moins/target/package/jeu_du_plus_ou_du_moins-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading jeu_du_plus_ou_du_moins v0.1.0 (file:///projects/jeu_du_plus_ou_du_moins)
Uploaded jeu_du_plus_ou_du_moins v0.1.0 to registry `crates-io`
note: waiting for `jeu_du_plus_ou_du_moins v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published jeu_du_plus_ou_du_moins v0.1.0 at registry `crates-io`
Félicitations ! Vous venez de partager votre code avec la communauté Rust, et désormais tout le monde peut facilement ajouter votre crate comme une dépendance de son projet.
Publier une nouvelle version d’une crate existante
Lorsque vous avez fait des changements sur votre crate et que vous êtes prêt à publier une nouvelle version, vous devez changer la valeur de version renseignée dans votre fichier Cargo.toml et la publier à nouveau. Utilisez les règles de versionnage sémantique pour choisir quelle sera la prochaine version la plus appropriée en fonction des changements que vous avez faits. Lancez ensuite cargo publish pour téléverser la nouvelle version.
Retirer des versions de crates.io avec cargo yank
Bien que vous ne puissiez pas enlever des versions précédentes d’une crate, vous pouvez prévenir les futurs projets de ne pas l’ajouter comme une nouvelle dépendance. Cela s’avère pratique lorsqu’une version de crate est défectueuse pour une raison ou une autre. Dans de telles circonstances, cargo permet de déprécier une version de crate.
Déprécier (NdT : yanking) une version évite que les nouveaux projets ajoutent une dépendance à cette version tout en permettant à tous les projets existants qui en dépendent de continuer à fonctionner. En gros, une version dépréciée permet à tous les projets avec un Cargo.lock de ne pas échouer, mais tous les futurs fichiers Cargo.lock générés n’utiliseront pas la version dépréciée.
Pour déprécier une version d’une crate, dans le répertoire de la crate que vous avez préalablement publiée, lancez cargo yank et renseignez quelle version vous voulez déprécier. Par exemple, si nous avons publié une crate nommée jeu_du_plus_ou_du_moins version 1.0.1 et nous voulons la déprécier, alors il nous faut entrer la commande suivante dans le répertoire de projet du jeu_du_plus_ou_du_moins :
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank jeu_du_plus_ou_du_moins@1.0.1
Si vous ajoutez --undo à la commande, vous pouvez aussi annuler une dépréciation et permettre à nouveaux aux projets de dépendre de cette version :
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank jeu_du_plus_ou_du_moins@1.0.1
Une dépréciation ne supprime pas du code. Elle ne peut pas, par exemple, supprimer des secrets téléversés par mégarde. Si cela arrive, vous devez régénérer immédiatement ces secrets.
Les espaces de travail de cargo
Les espaces de travail de cargo
Dans le chapitre 12, nous avons construit un paquet qui comprenait une crate binaire et une crate de bibliothèque. Au fur et à mesure que votre projet se développe, vous pourrez constater que la crate de bibliothèque continue de s’agrandir et vous voudriez alors peut-être diviser votre paquet en plusieurs crates de bibliothèque. Cargo a une fonctionnalité qui s’appelle les espaces de travail qui peuvent aider à gérer plusieurs paquets liés qui sont développés en tandem.
Créer un espace de travail
Un espace de travail est un jeu de paquets qui partagent tous le même Cargo.lock et le même répertoire de sortie. Créons donc un projet en utilisant un espace de travail — nous allons utiliser du code trivial afin de nous concentrer sur la structure de l’espace de travail. Il existe plusieurs façons de structurer un espace de travail, nous allons simplement vous montrer une manière commune d’organisation. Nous allons avoir un espace de travail contenant un binaire et deux bibliothèques. Le binaire, qui devrait fournir les fonctionnalités principales, va dépendre des deux bibliothèques. Une bibliothèque va fournir une fonction ajouter_un, et l’autre bibliothèque, une fonction ajouter_deux. Ces trois crates feront partie du même espace de travail. Nous allons commencer par créer un nouveau répertoire pour cet espace de travail :
$ mkdir ajout
$ cd ajout
Ensuite, dans le répertoire ajout, nous créons le fichier Cargo.toml qui va configurer l’intégralité de l’espace de travail. Ce fichier n’aura pas de section [package]. À la place, il commencera par une section [workspace] qui va nous permettre d’ajouter des membres à l’espace de travail. Nous veillons également à utiliser la version qui soit la dernière et la plus élevée de l’algorithme de résolution de Cargo dans notre espace de travail en définissant la valeur resolver à "3" :
Fichier : Cargo.toml
[workspace]
resolver = "3"
Ensuite, nous allons créer la crate binaire additionneur en lançant cargo new dans le répertoire ajout :
$ cargo new additionneur
Created binary (application) `additionneur` package
Adding `additionneur` as member of workspace at `file:///projects/ajout`
L’exécution de cargo new dans un espace de travail ajoute aussi automatiquement le paquet récemment créé à la clé members de la définition [workspace] dans le fichier Cargo.toml, comme suit :
[workspace]
resolver = "3"
members = ["additionneur"]
À partir de ce moment, nous pouvons compiler l’espace de travail en lançant cargo build. Les fichiers dans votre répertoire ajout devraient se présenter ainsi :
├── Cargo.lock
├── Cargo.toml
├── additionneur
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
L’espace de travail a un répertoire target au niveau le plus haut pour y placer les artéfacts compilés ; le paquet additionneur n’a pas son propre répertoire target. Même si nous lancions cargo build à l’intérieur du répertoire additionneur, les artéfacts compilés finirons toujours dans ajout/target plutôt que dans ajout/additionneur/target. Cargo organise ainsi le répertoire target car les crates d’un espace de travail sont censés dépendre l’une de l’autre. Si chaque crate avait son propre répertoire target, chaque crate devrait recompiler chacune des autres crates présentes dans l’espace de travail pour avoir les artéfacts dans son propre répertoire target. En partageant un seul répertoire target, les crates peuvent éviter des recompilations inutiles.
Créer le second paquet dans l’espace de travail
Ensuite, créons un autre paquet, membre de l’espace de travail et appelons-le ajouter_un. Puis générons une nouvelle crate de bibliothèque ajouter_un :
$ cargo new ajouter_un --lib
Created library `ajouter_un` package
Adding `add_one` as member of workspace at `file:///projects/add`
Le Cargo.toml du niveau le plus haut va maintenant inclure le chemin vers ajouter_un dans la liste members :
Fichier : Cargo.toml
[workspace]
resolver = "3"
members = ["additionneur", "ajouter_un"]
Votre répertoire ajout devrait maintenant avoir ces répertoires et fichiers :
├── Cargo.lock
├── Cargo.toml
├── ajouter_un
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── additionneur
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Dans le fichier ajouter_un/src/lib.rs, ajoutons une fonction ajouter_un :
Fichier : ajouter_un/src/lib.rs
pub fn ajouter_un(x: i32) -> i32 {
x + 1
}Nous pouvons maintenant faire en sorte que le paquet additionneur qui contient notre binaire dépende du paquet ajouter_un, qui contient notre bibliothèque. D’abord, nous devons ajouter un chemin de dépendance à ajouter_un dans additionneur/Cargo.toml.
Fichier : ajouter_un/Cargo.toml
[dependencies]
ajouter_un = { path = "../ajouter_un" }
Cargo ne fait pas la supposition que les crates d’un espace de travail dépendent l’une de l’autre, donc vous devez être explicites sur les relations de dépendance.
Ensuite, utilisons la fonction ajouter_un (de la crate ajouter_un) dans la crate additionneur. Ouvrez le fichier additionneur/src/main.rs et changez la fonction main pour appeler la fonction ajouter_un, comme dans l’encart 14-7.
fn main() {
let nombre = 10;
println!("Hello, world! {nombre} plus un vaut {} !", ajouter_un::ajouter_un(nombre));
}add_one library crate from the adder crateCompilons l’espace de travail en lançant cargo build dans le niveau le plus haut du répertoire ajout !
$ cargo build
Compiling ajouter_un v0.1.0 (file:///projects/ajout/ajouter_un)
Compiling additionneur v0.1.0 (file:///projects/ajout/additionneur)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Pour lancer la crate binaire à partir du répertoire ajout, nous pouvons préciser quel paquet nous souhaitons exécuter dans l’espace de travail en utilisant l’argument -p suivi du nom du paquet avec cargo run :
$ cargo run -p additionneur
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/additionneur`
Hello, world ! 10 plus un vaut 11 !
Cela exécute le code de additionneur/src/main.rs, qui dépend de la crate ajouter_un.
Dépendre d’un paquet externe dans un espace de travail
Notez que l’espace de travail a un seul fichier Cargo.lock dans le niveau le plus haut plutôt que d’avoir un Cargo.lock dans chaque répertoire de chaque crate. Cela garantit que toutes les crates utilisent la même version de toutes les dépendances. Si nous ajoutons le paquet rand aux fichiers additionneur/Cargo.toml et ajouter_un/Cargo.toml, cargo va réunir les deux en une seule version de rand et enregistrer cela dans un seul Cargo.lock. Faire en sorte que toutes les crates de l’espace de travail utilisent la même dépendance signifie que les crates seront toujours compatibles l’une avec l’autre. Ajoutons la crate rand à la section [dependencies] du fichier ajouter_un/Cargo.toml pour utiliser la crate rand dans la crate ajouter_un :
Fichier : hello.html
[dependencies]
rand = "0.8.5"
Nous pouvons maintenant ajouter use rand; au fichier ajouter_un/src/lib.rs et compiler l’ensemble de l’espace de travail en lançant cargo build dans le répertoire ajout, ce qui va importer et compiler la crate rand. Nous devrions avoir un avertissement car nous n’avons pas utilisé le rand que nous avons introduit dans la portée :
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling ajouter_un v0.1.0 (file:///projects/ajout/ajouter_un)
warning: unused import: `rand`
--> ajouter_un/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `ajouter_un` (lib) generated 1 warning (run `cargo fix --lib -p ajouter_un` to apply 1 suggestion)
Compiling additionneur v0.1.0 (file:///projects/ajout/additionneur)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Le Cargo.lock du niveau le plus haut contient maintenant les informations de dépendance à rand pour ajouter_un. Cependant, même si rand est utilisé quelque part dans l’espace de travail, nous ne pouvons pas l’utiliser dans d’autres crates de l’espace de travail tant que nous n’ajoutons pas rand dans leurs fichiers Cargo.toml. Par exemple, si nous ajoutons use rand; dans le fichier additionneur/src/main.rs pour le paquet additionneur, nous allons avoir une erreur :
$ cargo build
-- partie masquée ici --
Compiling additionneur v0.1.0 (file:///projects/ajout/additionneur)
error[E0432]: unresolved import `rand`
--> additionneur/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Pour corriger cela, modifiez le fichier Cargo.toml pour le paquet additionneur et indiquez que rand est une dépendance de cette crate aussi. La compilation du paquet additionneur va rajouter rand à la liste des dépendances pour additionneur dans Cargo.lock, mais aucune copie supplémentaire de rand ne sera téléchargée. Cargo va s’assurer que toutes chaque crate de chaque paquet de l’espace de travail qui utilise le paquet rand utilisera la même version, tant qu’elles spécifieront des versions compatibles de rand, ce qui économise de l’espace et nous assurer que les crates dans l’espace de travail seront compatibles les unes avec les autres.
Si les crates présentes dans l’espace de travail spécifient des versions incompatibles d’une même dépendance, Cargo résoudra chacune d’entre elles, tout en s’efforçant de n’en résoudre que le moins possible.
Ajouter un test à l’espace de travail
Afin de procéder à une autre amélioration, ajoutons un test de la fonction ajouter_un::ajouter_un dans la crate ajouter_un :
Fichier : ajouter_un/src/lib.rs
pub fn ajouter_un(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn cela_fonctionne() {
assert_eq!(3, ajouter_un(2));
}
}Lancez maintenant cargo test dans le niveau le plus haut du répertoire ajout. En exécutant cargo test dans un espace de travail structuré comme celui-ci, les tests de toutes les crates présentes dans l’espace de travail seront lancés :
$ cargo test
Compiling ajouter_un v0.1.0 (file:///projects/ajout/ajouter_un)
Compiling additionneur v0.1.0 (file:///projects/ajout/additionneur)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/ajouter_un-93c49ee75dc46543)
running 1 test
test tests::cela_fonctionne ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/ajouter_un-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests ajouter_un
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
La première section de la sortie indique que le test cela_fonctionne de la crate ajouter_un a réussi. La section suivante indique qu’aucun test n’a été trouvé dans la crate additionneur, puis la dernière section indique elle aussi qu’aucun test de documentation n’a été trouvé dans la crate ajouter_un. Lancer cargo test dans un espace de travail structuré comme celui-ci va exécuter les tests pour toutes les crates de cet espace de travail.
Nous pouvons aussi lancer des tests pour une crate en particulier dans un espace de travail à partir du répertoire du plus haut niveau en utilisant le drapeau -p et en renseignant le nom de la crate que nous voulons tester :
$ cargo test -p ajouter_un
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/ajouter_un-93c49ee75dc46543)
running 1 test
test tests::cela_fonctionne ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests ajouter_un
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cette sortie montre que cargo test a lancé les tests uniquement pour la crate ajouter_un et n’a pas lancé les tests de la crate additionneur.
Si vous publiez les crates présentes dans l’espace de travail sur crates.io, chaque crate de l’espace de travail va avoir besoin d’être publiée de manière séparée. Comme pour cargo test, nous pouvons publier une crate donnée de notre espace de travail en utilisant le drapeau -p et en précisant le nom de la crate que nous voulons publier.
En guise d’entrainement supplémentaire, ajoutez une crate ajouter_deux dans cet espace de travail de la même manière que nous l’avons fait pour la crate ajouter_un !
Au fur et à mesure que votre projet se développe, pensez à utiliser un espace de travail : cela vous permettre de travailler avec des composants plus petits et plus aisés à comprendre qu’un gros tas de code. De plus, garder les crates dans un espace de travail peut améliorer la coordination entre elles si elles sont souvent modifiées ensemble.
Installer des binaires avec cargo install
Installer des binaires avec cargo install
La commande cargo install vous permet d’installer et utiliser des crates de binaires localement. Cela n’est pas conçu pour remplacer les paquets systèmes ; c’est plutôt un moyen pratique pour les développeurs Rust d’installer des outils que les autres ont partagé sur crates.io. Notez que vous ne pouvez installer que des paquets qui ont des destinations binaires. Une destination binaire est le programme exécutable qui est créé si la crate a un fichier src/main.rs ou un autre fichier désigné comme binaire, par opposition à une destination de bibliothèque qui n’est pas exécutable en tant que telle mais qu’il est possible d’intégrer à d’autres programmes. Habituellement, l’information permettant de savoir si une crate est une bibliothèque, possède plutôt une destination binaire ou les deux à la fois figure dans le fichier README.
Tous les binaires installés avec cargo install sont stockés dans le répertoire bin de la racine. Si vous installez Rust avec rustup.rs et que vous n’avez pas personnalisé la configuration, ce répertoire sera $HOME/.cargo/bin. Assurez-vous que ce répertoire est dans votre $PATH pour pouvoir exécuter des programmes que vous avez installés avec cargo install.
Par exemple, dans le chapitre 12, nous avions mentionné le fait qu’il existait une implémentation de l’outil grep en Rust qui s’appelait ripgrep et qui permettait de rechercher dans des fichiers. Pour installer ripgrep, nous pouvons faire comme ceci :
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
L’avant-dernière ligne de la sortie nous montre l’emplacement et le nom du binaire installé, qui est rg dans le cas de ripgrep. Tel que mentionné précédemment, du moment que le répertoire d’installation est dans votre $PATH, vous pouvez ensuite lancer rg --help et commencer à utiliser un outil en Rust plus rapide pour rechercher dans des fichiers !
Étendre les fonctionnalités de cargo avec des commandes personnalisées
Étendre les fonctionnalités de cargo avec des commandes personnalisées
Cargo est conçu pour que vous puissiez étendre ses fonctionnalités avec des nouvelles sous-commandes sans avoir à modifier cargo. Si un binaire dans votre $PATH est nommé selon cargo-quelquechose, vous pouvez le lancer comme s’il était une sous-commande de cargo en lançant cargo quelquechose. Les commandes personnalisées comme celle-ci sont aussi listées lorsque vous lancez cargo --list. Pouvoir utiliser cargo install pour installer des extensions et ensuite les lancer comme étant un outil intégré à cargo est un avantage super pratique de la conception de cargo !
Résumé
Le partage de code avec cargo et crates.io fait partie de ce qui rend l’écosystème de Rust très utile pour de nombreuses tâches. La bibliothèque standard de Rust est compacte et stable, et les crates sont faciles à partager, à utiliser et à améliorer à un rythme différent de celui du langage. N’hésitez pas à partager du code qui vous est utile sur crates.io ; il est fort probable qu’il sera aussi utile à quelqu’un d’autre !
Les pointeurs intelligents
Un pointeur est un concept général pour une variable qui contient une adresse vers la mémoire. Cette adresse pointe vers d’autres données. Le type de pointeur le plus courant en Rust est la référence, que vous avez apprise au chapitre 4. Les références sont marquées par le symbole & et empruntent la valeur sur laquelle elles pointent. Elles n’ont pas d’autres fonctionnalités que celle de pointer sur une donnée, et elles n’ont aucun surcoût sur les performances.
Les pointeurs intelligents, d’un autre côté, sont des structures de données qui se comportent comme un pointeur mais ont aussi des fonctionnalités et métadonnées supplémentaires. Le concept de pointeur intelligent n’est pas propre à Rust : les pointeurs intelligents sont originaires du C++ et existent aussi dans d’autres langages. Rust dispose de toute une gamme de pointeurs intelligents définis dans la bibliothèque standard, qui fournissent des fonctionnalités allant au-delà de celles qui sont fournies par les références. Pour approfondir ce concept général, nous allons examiner quelques exemples de pointeurs intelligents, notamment un type de pointeur intelligent avec un compteur de références. Ce pointeur vous permet d’autoriser une donnée à avoir plusieurs propriétaires tout en gardant une trace de leur nombre et, lorsqu’il n’y a plus de propriétaire, de nettoyer cette donnée et libérer la mémoire.
En Rust, avec son concept de propriété et d’emprunt, il y a une différence supplémentaire entre les références et les pointeurs intelligents : alors que les références ne font qu’emprunter la donnée, les pointeurs intelligents sont, dans de nombreux cas, propriétaires des données sur lesquelles ils pointent.
Les pointeurs intelligents sont souvent implémentés en utilisant des structures. Au contraire d’une structure classique, les pointeurs intelligents implémentent les traits Deref et Drop. Le trait Deref permet à une instance d’un pointeur intelligent de se comporter comme une référence afin que vous puissiez écrire du code qui fonctionne aussi bien avec des références qu’avec des pointeurs intelligents. Le trait Drop vous permet de personnaliser le code qui est exécuté lorsqu’une instance d’un pointeur intelligent sort de la portée. Dans ce chapitre, nous verrons ces deux traits et expliquerons pourquoi ils sont importants pour les pointeurs intelligents.
Vu que le motif des pointeurs intelligents est un motif de conception général fréquemment utilisé en Rust, ce chapitre ne couvrira pas tous les pointeurs intelligents existants. De nombreuses bibliothèques ont leurs propres pointeurs intelligents, et vous pouvez même écrire le vôtre. Nous allons voir les pointeurs intelligents les plus courants de la bibliothèque standard :
Box<T>, pour l’allocation de valeurs sur le tas ;Rc<T>, un type comptant les références, qui permet d’avoir plusieurs propriétaires ;Ref<T>etRefMut<T>, auxquels on accède viaRefCell<T>, un type qui permet d’appliquer les règles d’emprunt au moment de l’exécution plutôt qu’au moment de la compilation.
En outre, nous allons voir le motif de mutabilité interne dans lequel un type immuable propose une API pour modifier une valeur interne. Nous allons aussi parler des boucles de références : comment elles peuvent provoquer des fuites de mémoire et comment les éviter.
Allons-y !
Utiliser Box<T> pour pointer sur des données présentes sur le tas
Utiliser Box<T> pour pointer sur des données présentes sur le tas
Le pointeur intelligent le plus simple est la boîte, dont le type s’écrit Box<T>. Les boîtes vous permettent de stocker des données sur le tas plutôt que sur la pile. La seule chose qui reste sur la pile est le pointeur vers les données sur le tas. Revenez au chapitre 4 pour vous rappeler la différence entre la pile et le tas.
Les boîtes ne provoquent pas de surcharge au niveau des performances, si ce n’est le stockage de leurs données sur le tas plutôt que sur la pile. Mais elles n’ont pas non plus beaucoup plus de fonctionnalités. Vous allez les utiliser principalement dans les situations suivantes :
- lorsque vous avez un type dont la taille ne peut pas être connue au moment de la compilation et que vous souhaitez une valeur d’un certain type dans un contexte qui nécessite de savoir exactement sa taille ;
- lorsque vous avez une grosse quantité de données et que vous souhaitez transférer la possession tout en assurant que les données ne seront pas copiées lorsque vous le ferez ;
- lorsque vous voulez prendre possession d’une valeur et que vous souhaitez seulement qu’elle soit d’un type qui implémente un trait particulier plutôt que d’être d’un type spécique.
Nous allons expérimenter la première situation dans la section “Pouvoir utiliser des types récursifs grâce aux boîtes”. Pour la seconde situation, le transfert de possession d’une grosse quantité de données peut prendre beaucoup de temps car les données sont recopiées sur la pile. Pour améliorer les performances dans cette situation, nous pouvons stocker ces données sur le tas grâce à une boîte. Ainsi, seul le petit pointeur vers les données est copié sur la pile, alors que les données qu’il pointe restent à leur place sur le tas. La troisième situation décrit ce qu’on appelle un objet de trait et “Using Trait Objects to Abstract over Shared Behavior” dans le chapitre 18 est dédiée à ce sujet. Donc ce que vous apprenez ici, vous le retrouverez à nouveau dans cette section !
Stockage des données sur le tas
Avant de parler du cas d’usage de stockage sur le tas pour Box<T>, nous devons voir sa syntaxe et comment interagir avec les valeurs stockées dans un Box<T>.
L’encart 15-1 nous montre comment utiliser une boîte pour stocker une valeur i32 sur le tas :
fn main() {
let b = Box::new(5);
println!("b = {b}");
}i32 value on the heap using a boxNous avons défini la variable b pour avoir la valeur d’une Box qui pointe sur la valeur 5, qui est donc allouée sur le tas. Ce programme va afficher b = 5 ; dans ce cas, nous pouvons accéder à la donnée présente dans la boîte de la même manière que nous le ferions si elle était sur la pile. Comme toute valeur possédée, lorsqu’une boîte sort de la portée, comme lorsque b le fait à la fin du main, elle sera désallouée. La désallocation aura lieu pour la boîte (qui est stockée sur la pile) ainsi que les données sur lesquelles elle pointait (qui sont stockées sur le tas).
Déposer une seule valeur sur le tas n’est pas très utile, donc vous n’utiliserez que très rarement les boîtes de cette manière. Laisser les valeurs comme des i32 indépendantes sur la pile, où elles sont stockées par défaut, reste plus approprié dans la majeure partie des situations. Regardons un cas où les boîtes nous permettent de définir des types que nous ne pourrions pas définir si nous n’avions pas les boîtes.
Pouvoir utiliser des types récursifs grâce aux boîtes
Une valeur d’un type récursif peut avoir une autre valeur du même type qu’elle-même. Les types récursifs posent un problème car Rust a besoin de savoir, au moment de la compilation, combien d’espace prend un type. Cependant, cet emboîtement de valeurs pourrait théoriquement se poursuivre à l’infini, donc Rust ne peut pas savoir de combien d’espace une valeur d’un type récursif peut avoir besoin. Comme les boîtes ont une taille connue, nous pouvons créer des types récursifs en insérant une boîte dans la définition d’un type récursif.
En guise d’exemple de type récursif, découvrons maintenant la liste de construction (NdT : cons list). Il s’agit d’un type de donnée courant dans les langages de programmation fonctionnels. Le type liste de construction que nous allons définir est plutôt simple, sauf pour les cas de récursivité ; par conséquent, les concepts dans l’exemple avec lequel nous allons travailler vous seront utiles à chaque fois que vous vous retrouverez dans des situations plus complexes qui impliquent des types récursifs.
Comprendre les listes de construction
Une liste de construction est une structure de donnée qui provient du langage de programmation Lisp et de ses dérivés, est constituée de paires imbriquées, et constituent la version en Lisp d’une liste chaînée. Son nom vient de la fonction cons (qui est une forme contractée de “fonction de construction”) en Lisp qui construit une nouvelle paire à partir de ses deux arguments. En appellant cons sur une paire faite d’une valeur et d’une autre paire, nous pouvons construire des listes de construction faites de paires récursives.
Par exemple, voici une représentation en pseudocode d’une liste de construction contenant la liste 1, 2, 3 avec chaque paire entre parenthèses :
(1, (2, (3, Nil)))
Chaque élément dans une liste de construction contient deux éléments : la valeur de l’élément courant et celle de l’élément suivant. Le dernier élément dans la liste contient seulement une valeur Nil sans aucun élément suivant. Une liste de construction est produite de manière récursive en appelant la fonction cons. Le nom canonique pour indiquer le cas de base de la récursion est Nil. Notez que ce n’est pas la même chose que les concepts “null” ou “nil” dont il est question dans le chapitre 6, qui signale une valeur invalide ou absente.
La liste de construction n’est pas une structure de donnée utilisée couramment en Rust. La plupart du temps, lorsque vous avez une liste d’éléments en Rust, Vec<T> s’avère être un meilleur choix à faire. Autrement, il existe des types de données récursifs plus complexes qui sont utiles dans d’autres situations, mais en commençant avec les listes de construction dans ce chapitre, nous pouvons découvrir comment les boîtes nous permettent de définir un type de données récursif sans être trop perturbé par la complexité.
L’encart 15-2 propose une définition d’une énumération pour une liste de construction. Notez que ce code ne se compile pas encore, car le type List n’a pas encore de taille connue, ce que nous allons voir ensuite.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}i32 valuesRemarque : nous implémentons une liste de construction qui stocke uniquement des valeurs i32 pour les besoins de cet exemple. Nous aurions pu l’implémenter en utilisant des génériques, que nous avons vu chapitre 10, afin de définir une liste de construction qui pourrait stocker n’importe quel type.
L’utilisation du type List pour stocker la liste 1, 2, 3 ressemblerait au code dans l’encart 15-3 :
enum List {
Cons(i32, List),
Nil,
}
// -- partie masquée ici --
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}List enum to store the list 1, 2, 3La première valeur Cons stocke 1 et une autre valeur de List. Cette valeur List est une autre valeur Cons qui stocke 2 et une autre valeur de List. Cette valeur List n’est rien d’autre qu’une valeur Cons qui stocke 3 et une valeur List, qui finalement est Nil, la variante non récursive qui signale la fin de la liste.
Si nous essayons de compiler le code de l’encart 15-3, nous avons l’erreur de l’encart 15-4 :
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
L’erreur explique que ce type “a une taille infinie”. La raison est que nous avons défini List avec une variante qui est récursive : elle stocke directement une autre valeur d’elle-même. Au final, Rust ne peut pas savoir de combien de place il a besoin pour stocker une valeur List. Analysons pourquoi nous obtenons cette erreur. D’abord, regardons comment Rust décide de l’espace dont il a besoin pour stocker une valeur d’un type non récursif.
Calculer la taille d’un type non récursif
Rappelez-vous de l’énumération Message que nous avons défini dans l’encart 6-2 lorsque nous avons abordé les définitions des énumérations au chapitre 6 :
enum Message {
Quitter,
Deplacer { x: i32, y: i32 },
Ecrire(String),
ChangerCouleur(i32, i32, i32),
}
fn main() {}Pour déterminer combien d’espace allouer pour une valeur Message, Rust parcourt chaque variante pour voir quelle variante a besoin du plus d’espace. Rust voit que Message::Quitter n’a pas besoin d’espace, Message::Deplacer a besoin de suffisamment d’espace pour stocker deux valeurs i32, et ainsi de suite. Comme une seule variante sera utilisée, le plus grand espace dont une valeur de Message aura besoin sera l’espace nécessaire pour stocker la plus grosse de ses variantes.
Comparez cela avec ce qui se passe lorsque Rust essaye de déterminer combien d’espace un type récursif comme l’énumération List de l’encart 15-2 aurait besoin. Le compilateur commence par regarder la variante Cons, qui stocke une valeur de type i32 et une valeur de type List. Ainsi, Cons a besoin d’une quantité d’espace égale à la taille d’un i32 plus la taille d’une valeur List. Pour savoir combien de mémoire le type List a besoin, le compilateur va regarder ses variantes, en commençant avec la variante Cons. La variante Cons stocke une valeur de type i32 et une valeur de type List, et ce processus continue à l’infini, comme l’illustration 15-1.

Illustration 15-1 : Une List infinie qui contient des variantes Cons infinies
Récupération d’un type récursif avec une taille finie
Comme Rust ne peut pas calculer la quantité d’espace à allouer pour les types définis récursivement, le compilateur déclenche une erreur avec cette suggestion très utile :
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
Dans cette suggestion, “indirection” (NdT : redirection) signifie qu’au lieu de stocker une valeur directement, nous allons changer la structure des données pour stocker à la place un pointeur vers la valeur.
Comme Box<T> est un pointeur, Rust connaît toujours de combien d’espace un Box<T> a besoin : la taille d’un pointeur ne change pas, peu importe la quantité de données sur lesquelles il pointe. Cela signifie que nous pouvons insérer un Box<T> à l’intérieur d’une variante Cons au lieu d’y mettre directement une autre valeur List. Le Box<T> va pointer sur la prochaine valeur List qui sera sur le tas plutôt que d’être dans la variante Cons. Théoriquement, nous avons toujours une liste, créée avec des listes qui “contiennent” d’autres listes, mais cette implémentation ressemble plus à présent à des éléments placés les uns à côté des autres plutôt que les uns dans les autres.
Nous pouvons changer la définition de l’énumération List de l’encart 15-2 et l’utilisation de List dans l’encart 15-3 pour le code de l’encart 15-5, qui va se compiler.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}List that uses Box<T> in order to have a known sizeLa variante Cons a besoin de l’espace d’un i32 plus l’espace pour stocker le pointeur vers la donnée de la boîte. La variante Nil ne stocke pas de valeurs, donc elle a besoin de moins d’espace sur la pile que la variante Cons. Nous savons maintenant que chaque valeur List va prendre la taille d’un i32 plus la taille d’un pointeur vers la donnée de la boîte. En utilisant une boîte, vous avez arrêté la chaîne infinie et récursive, donc le compilateur peut savoir l’espace dont il a besoin pour stocker une valeur List. L’illustration 15-2 montre à quoi ressemble maintenant la variante Cons.

Illustration 15-2 : Une List qui n’a pas de taille infinie car Cons est une Box
Les boîtes fournissent uniquement la redirection et l’allocation sur le tas ; elles n’ont pas d’autres fonctionnalités, comme celles que nous verrons sur d’autres types de pointeurs intelligents. Elles n’ont pas non plus les surcoût de performances autres qu’entraînent ces capacités spéciales, elles sont donc utiles dans des cas comme les listes de construction où la redirection est la seule fonctionnalité dont nous avons besoin. Nous verrons aussi plus de cas d’usages pour les boîtes dans le chapitre 18.
Le type Box<T> est un pointeur intelligent car il implémente le trait Deref, qui permet aux valeurs Box<T> d’être traitées comme des références. Lorsqu’une valeur Box<T> sort de la portée, les données sur le tas pointées par la boîte seront également nettoyées grâce à l’implémentation du trait Drop. Ces deux traits deviendront encore plus importants pour les fonctionnalités offertes par les autres pointeurs intelligents que nous verrons dans le reste de ce chapitre. Explorons plus en détail ces deux traits.
Considérer les pointeurs intelligents comme des références grâce au trait Deref
Considérer les pointeurs intelligents comme des références grâce au trait Deref
L’implémentation du trait Deref vous permet de personnaliser le comportement de l’opérateur de déréférencement * (à ne pas confondre avec l’opérateur de multiplication ou le joker global). En implémentant Deref de manière à ce qu’un pointeur intelligent puisse être considéré comme une référence classique, vous pouvez écrire du code qui fonctionne avec des références mais aussi avec des pointeurs intelligents.
Regardons d’abord comment l’opérateur de déréférencement fonctionne avec des références classiques. Ensuite nous essaierons de définir un type personnalisé qui se comporte comme Box<T> et voir pourquoi l’opérateur de déréférencement ne fonctionne pas comme une référence sur notre type fraîchement défini. Nous allons découvrir comment implémenter le trait Deref de manière à ce qu’il soit possible que les pointeurs intelligents fonctionnent comme les références. Ensuite nous verrons la fonctionnalité d’extrapolation de déréférencement de Rust et comment elle nous permet de travailler à la fois avec des références et des pointeurs intelligents.
Suivre la référence à une valeur
Une référence classique est un type de pointeur, et une manière de modéliser un pointeur est d’imaginer une flèche pointant vers une valeur stockée autre part. Dans l’encart 15-6, nous créons une référence vers une valeur i32 et utilisons ensuite l’opérateur de déréférencement pour suivre la référence vers la valeur.
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}i32 valueLa variable x stocke une valeur i32 : 5. Nous avons assigné à y une référence vers x. Nous pouvons faire une assert pour vérifier que x est égal à 5. Cependant, si nous souhaitons faire une assert sur la valeur dans y, nous devons utiliser *y pour suivre la référence vers la valeur sur laquelle elle pointe (d’où le déréférencement), de manière à ce que le compilateur puisse comparer la valeur réelle. Une fois que nous avons déréférencé y, nous avons accès à la valeur de l’entier sur laquelle y pointe afin que nous puissions la comparer avec 5.
Si nous avions essayé d’écrire assert_eq!(5, y); à la place, nous aurions obtenu cette erreur de compilation :
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Comparer un nombre et une référence vers un nombre n’est pas autorisé car ils sont de types différents. Nous devons utiliser l’opérateur de déréférencement pour suivre la référence vers la valeur sur laquelle elle pointe.
Utiliser Box<T> comme une référence
Nous pouvons réécrire le code l’encart 15-6 pour utiliser une Box<T> au lieu d’une référence ; l’opérateur de déréférencement utilisé sur le Box<T> dans l’encart 15-7 fonctionne de la même manière que l’opérateur de déréférencement utilisé sur la référence dans l’encart 15-6.
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Box<i32>La principale différence entre l’encart 15-7 et l’encart 15-6 est qu’ici nous avons fait en sorte que y soit une instance de boîte qui pointe sur une copie de la valeur de x plutôt que d’avoir une référence vers la valeur de x. Dans la dernière assertion, nous pouvons utiliser l’opérateur de déréférencement pour suivre le pointeur de la boîte de la même manière que nous l’avons fait lorsque y était une référence. Maintenant, nous allons regarder ce qu’il y a de si spécial dans Box<T> qui nous permet d’utiliser l’opérateur de déréférencement en définissant notre propre type de boîte.
Définir notre propre pointeur intelligent
Construisons un type conteneur (NdT : wrapper type) similaire au type Box<T> fourni par la bibliothèque standard pour apprendre comment les types de pointeurs intelligents se comportent différemment des références classiques. Nous regarderons ensuite comment lui ajouter la possibilité d’utiliser l’opérateur de déréférencement.
Remarque : il y a une grosse différence entre le type MaBoite<T> que nous allons construire et la vraie Box<T> : notre version ne va pas stocker ses données sur le tas. Nous allons concentrer cet exemple sur Deref, donc l’endroit où est concrètement stocké la donnée est moins important que le comportement similaire aux pointeurs.
Le type Box<T> est essentiellement défini comme étant une structure de tuple d’un seul élément, donc l’encart 15-8 définit un type MaBoite<T> de la même manière. Nous allons aussi définir une fonction new pour correspondre à la fonction new définie sur Box<T>.
struct MaBoite<T>(T);
impl<T> MaBoite<T> {
fn new(x: T) -> MaBoite<T> {
MaBoite(x)
}
}
fn main() {}MyBox<T> typeNous définissons une structure MaBoite et nous déclarons un paramètre générique T, car nous souhaitons que notre type stocke des valeurs de n’importe quel type. Le type MaBoite est une structure de tuple avec un seul élément de type T. La fonction MaBoite::new prend un paramètre de type T et retourne une instance MaBoite qui stocke la valeur qui lui est passée.
Essayons d’ajouter la fonction main de l’encart 15-7 dans l’encart 15-8 et de la modifier pour utiliser le type MaBoite<T> que nous avons défini à la place de Box<T>. Le code de l’encart 15-9 ne se compile pas car Rust ne sait pas comment déréférencer MaBoite.
struct MaBoite<T>(T);
impl<T> MaBoite<T> {
fn new(x: T) -> MaBoite<T> {
MaBoite(x)
}
}
fn main() {
let x = 5;
let y = MaBoite::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}MyBox<T> in the same way we used references and Box<T>Voici l’erreur de compilation qui en résulte :
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MaBoite<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Notre type MaBoite<T> ne peut pas être déréférencée car nous n’avons pas implémenté cette fonctionnalité sur notre type. Pour permettre le déréférencement avec l’opérateur *, nous devons implémenter le trait Deref.
Implémentation du trait Deref
Comme nous l’avons vu dans “Implémenter un trait sur un type” au chapitre 10, pour implémenter un trait, nous devons fournir les implémentations des méthodes nécessaires pour ce trait. Le trait Deref, fourni par la bibliothèque standard, nécessite que nous implémentions une méthode deref qui emprunte self et retourne une référence vers la donnée interne. L’encart 15-10 contient une implémentation de Deref à ajouter à la définition de MaBoite<T> :
use std::ops::Deref;
impl<T> Deref for MaBoite<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
struct MaBoite<T>(T);
impl<T> MaBoite<T> {
fn new(x: T) -> MaBoite<T> {
MaBoite(x)
}
}
fn main() {
let x = 5;
let y = MaBoite::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Deref on MyBox<T>La syntaxe type Target = T; définit un type associé pour le trait Deref à utiliser. Les types associés sont une manière légèrement différente de déclarer un paramètre générique, mais vous n’avez pas à vous préoccuper d’eux pour le moment ; nous les verrons plus en détail au chapitre 20.
Nous renseignons le corps de la méthode deref avec &self.0 afin que deref retourne une référence vers la valeur que nous souhaitons accéder avec l’opérateur * ; rappellez-vous de la section “Création de différents types avec les structures tuples” du chapitre 5 où nous avons appris que le .0 accède à la première valeur d’une structure tuple. La fonction main de l’encart 15-9 qui appelle * sur la valeur MaBoite<T> se compile désormais, et le assert réussit aussi !
Sans le trait Deref, le compilateur peut seulement déréférencer des références &. La méthode deref donne la possibilité au compilateur d’obtenir la valeur de n’importe quel type qui implémente Deref en appelant la méthode deref pour obtenir une référence qu’il sait comment déréférencer.
Lorsque nous avons précisé *y dans l’encart 15-9, Rust fait tourner ce code en coulisses :
*(y.deref())Rust remplace l’opérateur * par un appel à la méthode deref suivi par un simple déréférencement afin que nous n’ayons pas à nous demander si nous devons ou non appeler la méthode deref. Cette fonctionnalité de Rust nous permet d’écrire du code qui fonctionne de manière identique, que nous ayons une référence classique ou bien un type qui implémente Deref.
La raison pour laquelle la méthode deref retourne une référence à une valeur, et que le déréférencement du tout dans les parenthèses externes de *(y.deref()) reste nécessaire, a à voir avec le système de possession. Si la méthode deref retournait la valeur directement au lieu d’une référence à cette valeur, la valeur serait déplacée à l’extérieur de self. Nous ne souhaitons pas prendre possession de la valeur à l’intérieur de MaBoite<T> dans ce cas ainsi que dans la plupart des cas où nous utilisons l’opérateur de déréférencement.
Notez que l’opérateur * est remplacé par un appel à la méthode deref suivi par un appel à l’opérateur * une seule fois, à chaque fois que nous utilisons un * dans notre code. Comme la substitution de l’opérateur * ne s’effectue pas de manière récursive et infinie, nous récupèrerons une donnée de type i32, qui correspond au 5 du assert_eq! de l’encart 15-9.
Utilisation de l’extrapolation de déréférencement dans les fonctions et les méthodes
L’extrapolation de déréférencement convertit une référence vers un type qui implémente le trait Deref en une référence vers un autre type. Par exemple, l’extrapolation de déréférencement peut convertir &String en &str car String implémente le trait Deref de sorte qu’il puisse retourner &str. L’extrapolation de déréférencement est une commodité que Rust applique sur les arguments des fonctions et des méthodes, et elle fonctionne uniquement avec des types qui implémentent le trait Deref. Elle s’applique automatiquement lorsque nous passons une référence vers une valeur d’un type particulier en argument d’une fonction ou d’une méthode qui ne correspond pas à ce type de paramètre dans la définition de la fonction ou de la méthode. Une série d’appels à la méthode deref convertit le type que nous donnons dans le type que le paramètre nécessite.
L’extrapolation de déréférencement a été ajoutée à Rust afin de permettre aux développeurs d’écrire des appels de fonctions et de méthodes qui n’ont pas besoin d’indiquer explicitement les références et les déréférencements avec & et *. La fonctionnalité d’extrapolation de déréférencement nous permet aussi d’écrire plus de code qui peut fonctionner à la fois pour les références et pour les pointeurs intelligents.
Pour voir l’extrapolation de déréférencement en action, utilisons le type MaBoite<T> que nous avons défini dans l’encart 15-8 ainsi que l’implémentation de Deref que nous avons ajoutée dans l’encart 15-10. L’encart 15-11 montre la définition d’une fonction qui a un paramètre qui est une slice de chaîne de caractères.
fn saluer(nom: &str) {
println!("Salutations, {nom} !");
}
fn main() {}hello function that has the parameter name of type &strNous pouvons appeler la fonction saluer avec une slice de chaîne de caractères en argument, comme par exemple saluer("Rust");. L’extrapolation de déréférencement rend possible l’appel de saluer avec une référence à une valeur du type MaBoite<String>, comme dans l’encart 15-12.
use std::ops::Deref;
impl<T> Deref for MaBoite<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MaBoite<T>(T);
impl<T> MaBoite<T> {
fn new(x: T) -> MaBoite<T> {
MaBoite(x)
}
}
fn saluer(nom: &str) {
println!("Salutations, {nom} !");
}
fn main() {
let m = MaBoite::new(String::from("Rust"));
saluer(&m);
}hello with a reference to a MyBox<String> value, which works because of deref coercionIci nous appelons la fonction saluer avec l’argument &m, qui est une référence vers une valeur de type MaBoite<String>. Comme nous avons implémenté le trait Deref sur MaBoite<T> dans l’encart 15-10, Rust peut transformer le &MaBoite<String> en &String en appelant deref. La bibliothèque standard fournit une implémentation de Deref sur String qui retourne une slice de chaîne de caractères, comme expliqué dans la documentation de l’API de Deref. Rust appelle à nouveau deref pour transformer le &String en &str, qui correspond à la définition de la fonction saluer.
Si Rust n’avait pas implémenté l’extrapolation de déréférencement, nous aurions dû écrire le code de l’encart 15-13 au lieu du code de l’encart 15-12 pour appeler saluer avec une valeur du type &MaBoite<String>.
use std::ops::Deref;
impl<T> Deref for MaBoite<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MaBoite<T>(T);
impl<T> MaBoite<T> {
fn new(x: T) -> MaBoite<T> {
MaBoite(x)
}
}
fn saluer(nom: &str) {
println!("Salutations, {nom} !");
}
fn main() {
let m = MaBoite::new(String::from("Rust"));
saluer(&(*m)[..]);
}Le (*m) déréférence la MaBoite<String> en une String. Ensuite le & et le [..] créent une slice de chaîne de caractères à partir de la String qui est égale à l’intégralité du contenu de la String, ceci afin de correspondre à la signature de saluer. Ce code sans l’extrapolation de déréférencement est bien plus difficile à lire, écrire et comprendre avec la présence de tous ces symboles. L’extrapolation de déréférencement permet à Rust d’automatiser ces convertions pour nous.
Lorsque le trait Deref est défini pour les types concernés, Rust va analyser les types et utiliser Deref::deref autant de fois que nécessaire pour obtenir une référence qui correspond au type du paramètre. Le nombre de fois qu’il est nécessaire d’insérer Deref::deref est résolu au moment de la compilation, ainsi il n’y a pas de surcoût au moment de l’exécution pour bénéficier de l’extrapolation de déréférencement !
Gestion de l’extrapolation de déréférencement avec des références mutables
De la même manière que vous pouvez utiliser le trait Deref pour remplacer le comportement de l’opérateur * sur les références immuables, vous pouvez utiliser le trait DerefMut pour remplacer le comportement de l’opérateur * sur les références mutables.
Rust procède à l’extrapolation de déréférencement lorsqu’il trouve des types et des implémentations de traits dans trois cas :
- Passer de
&Tà&UlorsqueT: Deref<Target=U> - Passer de
&mut Tà&mut UlorsqueT: DerefMut<Target=U> - Passer de
&mut Tà&UlorsqueT: Deref<Target=U>
Les deux premiers cas sont exactement les mêmes, sauf que le second implémente la mutabilité. Le premier cas signifie que si vous avez un &T et que T implémente Deref pour le type U, vous pouvez obtenir un &U de manière transparente. Le deuxième cas signifie que la même extrapolation de déréférencement se déroule pour les références mutables.
Le troisième cas est plus ardu : Rust va aussi procéder à une extrapolation de déréférencement d’une référence mutable vers une référence immuable. Mais l’inverse n’est pas possible: une extrapolation de déréférencement d’une valeur immuable ne donnera jamais une référence mutable. À cause des règles d’emprunt, si vous avez une référence mutable, cette référence mutable doit être la seule référence vers cette donnée (autrement, le programme ne peut pas être compilé). Convertir une référence mutable vers une référence immuable ne va jamais casser les règles d’emprunt. Convertir une référence immuable vers une référence mutable nécessite que la référence immuable initiale soit la seule référence immuable vers cette donnée, mais les règles d’emprunt ne garantissent pas cela. Rust ne peut donc pas déduire que la conversion d’une référence immuable vers une référence mutable est possible.
Exécuter du code lors du nettoyage avec le trait Drop
Exécuter du code lors du nettoyage avec le trait Drop
Le second trait important pour les pointeurs intelligents est Drop, qui vous permet de personnaliser ce qui se passe lorsqu’une valeur est en train de sortir d’une portée. Vous pouvez fournir une implémentation du trait Drop sur n’importe quel type, et ce code que vous renseignez peut être utilisé pour libérer des ressources comme des fichiers ou des connections réseau.
Nous présentons Drop dans le contexte des pointeurs intelligents car la fonctionnalité du trait Drop est quasiment systématiquement utilisée lorsque nous implémentons un pointeur intelligent. Par exemple, lorsqu’une Box<T> est libérée, elle va désallouer l’espace occupé sur le tas sur lequel la boîte pointe.
Dans certains langages, pour certains types, le développeur doit appeler du code pour libérer la mémoire ou des ressources à chaque fois qu’il finit d’utiliser une instance de ces types. On peut citer, par exemple, les descripteurs de fichiers, les sockets et les verrous. Si le programmeur oublie de le faire, le système peut devenir surchargé et planter. Avec Rust, vous pouvez renseigner du code qui sera exécuté à chaque fois qu’une valeur sort de la portée, et le compilateur va insérer automatiquement ce code. Au final, vous n’avez pas besoin de concentrer votre attention à placer du code de nettoyage à chaque fois qu’une instance d’un type particulier n’est plus utilisée — vous ne risquez pas d’avoir des fuites de ressources !
Vous renseignez le code à exécuter lorsqu’une valeur sort de la portée en implémentant le trait Drop. Le trait Drop nécessite que vous implémentiez une méthode drop qui prend en paramètre une référence mutable à self. Pour voir quand Rust appelle drop, implémentons drop avec une instruction println! à l’intérieur, pour le moment.
L’encart 15-14 montre une structure PointeurPerso dont la seule fonctionnalité personnalisée est qu’elle va écrire Nettoyage d'un PointeurPerso ! lorsque l’instance sort de la portée, pour montrer quand Rust exécute la méthode drop.
struct PointeurPerso {
donnee: String,
}
impl Drop for PointeurPerso {
fn drop(&mut self) {
println!("Nettoyage d'un PointeurPerso avec la donnée `{}` !", self.donnee);
}
}
fn main() {
let c = PointeurPerso {
donnee: String::from("des trucs"),
};
let d = PointeurPerso {
donnee: String::from("d'autres trucs"),
};
println!("PointeurPersos créés.");
}CustomSmartPointer struct that implements the Drop trait where we would put our cleanup codeLe trait Drop est importé dans l’étape préliminaire, donc nous n’avons pas besoin de l’importer dans la portée. Nous implémentons le trait Drop sur PointeurPerso et nous fournissons une implémentation de la méthode drop qui appelle println!. Le corps de la méthode drop est l’endroit où vous placez la logique que vous souhaitez exécuter lorsqu’une instance du type concerné sort de la portée. Ici nous affichons un petit texte pour démontrer visuellement quand Rust appelle drop.
Dans le main, nous créons deux instances de PointeurPerso et ensuite nous affichons PointeurPersos créés. À la fin du main, nos instances de PointeurPerso vont sortir de la portée, et Rust va appeler le code que nous avons placé dans la méthode drop et qui va afficher notre message final. Notez que nous n’avons pas besoin d’appeler explicitement la méthode drop.
Lorsque nous exécutons ce programme, nous devrions voir la sortie suivante :
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
PointeurPersos créés.
Nettoyage d'un PointeurPerso avec la donnée `d'autres trucs`!
Nettoyage d'un PointeurPerso avec la donnée `des trucs`!
Rust a appelé automatiquement drop pour nous lorsque nos instances sont sorties de la portée, appelant ainsi le code que nous y avions mis. Les variables sont libérées dans l’ordre inverse de leur création, donc d a été libéré avant c. Le but de cet exemple est de vous fournir une illustration de la façon dont la méthode drop fonctionne ; normalement vous devriez y mettre le code de nettoyage dont votre type a besoin d’exécuter plutôt que d’afficher simplement un message.
Malheureusement, il n’est pas simple de désactiver la fonctionnalité automatique drop. La désactivation de drop n’est généralement pas nécessaire ; tout l’intérêt du trait Drop est qu’il est pris en charge automatiquement. Occasionnellement, cependant, vous pourriez avoir besoin de nettoyer prématurément une valeur. Un exemple est lorsque vous utilisez des pointeurs intelligents qui gèrent un système de verrouillage : vous pourriez vouloir forcer la méthode drop qui libère le verrou afin qu’un autre code dans la même portée puisse prendre ce verrou. Rust ne vous autorise pas à appeler manuellement la méthode drop du trait Drop ; à la place vous devez appeler la fonction std::mem::drop, fournie par la bibliothèque standard, si vous souhaitez forcer une valeur à être libérée avant la fin de sa portée.
Tenter d’appeler manuellement la méthode drop du trait Drop en modifiant la fonction main de l’encart 15-14 ne fonctionnera pas, comme montré dans l’encart 15-15.
struct PointeurPerso {
donnee: String,
}
impl Drop for PointeurPerso {
fn drop(&mut self) {
println!("Nettoyage d'un PointeurPerso avec la donnée `{}` !", self.donnee);
}
}
fn main() {
let c = PointeurPerso {
donnee: String::from("des trucs"),
};
println!("PointeurPerso créé.");
c.drop();
println!("PointeurPerso libéré avant la fin du main.");
}drop method from the Drop trait manually to clean up earlyLorsque nous essayons de compiler ce code, nous obtenons l’erreur suivante :
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
Ce message d’erreur signifie que nous ne sommes pas autorisés à appeler explicitement drop. Le message d’erreur utilise le terme de destructeur (destructor) qui est un terme général de programmation qui désigne une fonction qui nettoie une instance. Un destructeur est analogue à un constructeur, qui construit une instance. La fonction drop en Rust est un destructeur particulier.
Rust ne nous laisse pas appeler explicitement drop car Rust appellera toujours automatiquement drop sur la valeur à la fin du main. Cela causerait une erreur de double libération car Rust essayerait de nettoyer la même valeur deux fois.
Nous ne pouvons pas désactiver l’ajout automatique de drop lorsqu’une valeur sort de la portée, et nous ne pouvons pas désactiver explicitement la méthode drop. Donc, si nous avons besoin de forcer une valeur à être nettoyée prématurément, nous utilisons la fonction std::mem::drop.
La fonction std::mem::drop est différente de la méthode drop du trait Drop. Nous l’appelons en lui passant en argument la valeur dont nous souhaitons forcer la libération. La fonction est présente dans l’étape préliminaire, donc nous pouvons modifier main de l’encart 15-15 pour appeler la fonction drop, comme dans l’encart 15-16.
struct PointeurPerso {
donnee: String,
}
impl Drop for PointeurPerso {
fn drop(&mut self) {
println!("Nettoyage d'un PointeurPerso avec la donnée `{}` !", self.donnee);
}
}
fn main() {
let c = PointeurPerso {
donnee: String::from("des trucs"),
};
println!("PointeurPerso créé.");
drop(c);
println!("PointeurPerso libéré avant la fin du main.");
}std::mem::drop to explicitly drop a value before it goes out of scopeL’exécution de code va afficher ceci :
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
PointeurPerso créé.
Nettoyage d'un PointeurPerso avec la donnée `des trucs` !
PointeurPerso libéré avant la fin du main.
Le texte Nettoyage d'un PointeurPerso avec la donnée `des trucs` ! est affiché entre PointeurPerso créé et PointeurPerso libéré avant la fin du main, ce qui démontre que la méthode drop a été appelée pour libérer c à cet endroit.
Vous pouvez utiliser le code renseigné dans une implémentation du trait Drop de plusieurs manières afin de rendre le nettoyage pratique et sûr : par exemple, vous pouvez l’utiliser pour créer votre propre alloueur de mémoire ! Grâce au trait Drop et le système de possession de Rust, vous n’avez pas à vous souvenir de nettoyer car Rust le fait automatiquement.
Vous n’avez pas non plus à vous soucier des problèmes résultant du nettoyage accidentel de valeurs toujours utilisées : le système de possession garantit que les références restent toujours en vigueur, et garantit également que drop n’est appelée qu’une seule fois lorsque la valeur n’est plus utilisée.
Maintenant que nous avons examiné Box<T> et certaines des caractéristiques des pointeurs intelligents, découvrons d’autres pointeurs intelligents définis dans la bibliothèque standard.
Rc<T>, le pointeur intelligent qui compte les références
Rc<T>, le pointeur intelligent qui compte les références
Dans la majorité des cas, la possession est claire : vous savez exactement quelle variable possède une valeur donnée. Cependant, il existe des cas où une valeur peut être possédée par plusieurs propriétaires. Par exemple, dans des structures de données de graphes, plusieurs extrémités peuvent pointer vers le même noeud, et ce noeud est par conception possédé par toutes les extrémités qui pointent vers lui. Un noeud ne devrait pas être nettoyé, à moins qu’il n’ait plus d’extrémités qui pointent vers lui et n’a donc plus de propriétaires.
Vous devez permettre la possession multiple en utilisant le type Rust Rc<T>, qui est une abréviation pour Reference Counting (compteur de références). Le type Rc<T> assure le suivi du nombre de références vers une valeur, afin de déterminer si la valeur est toujours utilisée ou non. S’il y a zéro référence vers une valeur, la valeur peut être nettoyée sans qu’aucune référence ne devienne invalide.
Imaginez que Rc<T> est comme une télévision dans une salle commune. Lorsqu’une personne entre pour regarder la télévision, elle l’allume. Une autre entre dans la salle et regarde la télévision. Lorsque la dernière personne quitte la salle, elle éteint la télévision car elle n’est plus utilisée. Si quelqu’un éteint la télévision alors que d’autres continuent à la regarder, cela va provoquer du chahut !
Nous utilisons le type Rc<T> lorsque nous souhaitons allouer une donnée sur le tas pour que plusieurs éléments de notre programme puissent la lire et que nous ne pouvons pas déterminer au moment de la compilation quel élément cessera de l’utiliser en dernier. Si nous savions quel élément finirait en dernier, nous pourrions simplement faire en sorte que cet élément prenne possession de la donnée, et les règles de possession classiques qui s’appliquent au moment de la compilation prendraient effet.
Notez que Rc<T> fonctionne uniquement dans des scénarios à un seul processus. Lorsque nous verrons la concurrence au chapitre 16, nous verrons comment procéder au comptage de références dans des programmes multi-processus.
Partage de données
Retournons à notre exemple de liste de construction de l’encart 15-5. Souvenez-vous que nous l’avons défini en utilisant Box<T>. Cette fois-ci, nous allons créer deux listes qui partagent toutes les deux la propriété d’une troisième liste. Théoriquement, cela ressemblera à l’illustration 15-3.
 Illustration 15-3 : Deux listes, `b` et `c`, qui se partagent la possession d'une troisième liste, `a`
Illustration 15-3 : Deux listes, `b` et `c`, qui se partagent la possession d'une troisième liste, `a`
Nous allons créer une liste a qui contient 5 et ensuite 10. Ensuite, nous allons créer deux autres listes : b qui démarre avec 3 et c qui démarre avec 4. Les deux listes b et c vont ensuite continuer sur la première liste a qui contient déjà 5 et 10. Autrement dit, les deux listes vont se partager la première liste contenant 5 et 10.
Si nous essayons d’implémenter ce scénario en utilisant les définitions de List avec Box<T>, comme dans l’encart 15-17, cela ne va pas fonctionner.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Box<T> that try to share ownership of a third listLorsque nous compilons ce code, nous obtenons cette erreur :
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Les variantes Cons prennent possession des données qu’elles obtiennent, donc lorsque nous avons créé la liste b, a a été déplacée dans b et b possède désormais a. Ensuite, lorsque nous essayons d’utiliser a à nouveau lorsque nous créons c, nous ne sommes pas autorisés à le faire car a a été déplacé.
Nous pourrions changer la définition de Cons pour stocker des références à la place, mais ensuite nous aurions besoin de renseigner des paramètres de durée de vie. En renseignant les paramètres de durée de vie, nous devrions préciser que chaque élément dans la liste vivra au moins aussi longtemps que la liste entière. C’est le cas pour les éléments et les listes dans l’encart 15-17, mais pas dans tous les cas.
À la place, nous allons changer la définition de List pour utiliser Rc<T> à la place de Box<T>, comme dans l’encart 15-18. Chaque variante Cons va maintenant posséder une valeur et un Rc<T> pointant sur une List. Lorsque nous créons b, au lieu de prendre possession de a, nous allons cloner le Rc<List> que a possède, augmentant ainsi le nombre de références de un à deux et permettant à a et b de partager la propriété des données dans Rc<List>. Nous allons aussi cloner a lorsque nous créons c, augmentant le nombre de références de deux à trois. Chaque fois que nous appelons Rc::clone, le compteur de références des données présentes dans le Rc<List> va augmenter, et les données ne seront pas nettoyées tant qu’il n’y aura pas zéro référence vers elles.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}List that uses Rc<T>Nous devons ajouter une instruction use pour importer Rc<T> dans la portée car il n’est pas présent dans l’étape préliminaire. Dans le main, nous créons la liste qui stocke 5 et 10 et la stockons dans une nouvelle Rc<List> dans a. Ensuite, lorsque nous créons b et c, nous appelons la fonction Rc::clone et nous passons une référence vers le Rc<List> de a en argument.
Nous aurions pu appeler a.clone() plutôt que Rc::clone(&a), mais la convention en Rust est d’utiliser Rc::clone dans cette situation. L’implémentation de Rc::clone ne fait pas une copie profonde de toutes les données comme le fait la plupart des implémentations de clone. L’appel à Rc:clone augmente uniquement le compteur de références, ce qui ne prend pas beaucoup de temps. Les copies profondes des données peuvent prendre beaucoup de temps. En utilisant Rc::clone pour les compteurs de références, nous pouvons distinguer visuellement un clonage qui fait une copie profonde d’un clonage qui augmente uniquement le compteur de références. Lorsque vous enquêtez sur des problèmes de performances dans le code, vous pouvez ainsi écarter les appels à Rc::clone pour ne vous intéresser qu’aux clonages à copie profonde que vous recherchez probablement.
Cloner pour augmenter le compteur de références
Changeons notre exemple de l’encart 15-18 pour que nous puissions voir le compteur de références changer au fur et à mesure que nous créons et libérons des références dans le Rc<List> présent dans a.
Dans l’encart 15-19, nous allons changer le main afin qu’il ait une portée en son sein autour de c ; ainsi nous pourrons voir comment le compteur de références change lorsque c sort de la portée.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
// -- partie masquée ici --
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("compteur après la création de a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("compteur après la création de b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("compteur après la création de c = {}", Rc::strong_count(&a));
}
println!("compteur après que c est sorti de la portée = {}", Rc::strong_count(&a));
}À chaque étape du programme où le compteur de références change, nous affichons le compteur de références, que nous obtenons en faisant appel à la fonction Rc::strong_count. Cette fonction s’appelle strong_count plutôt que count car le type Rc<T> a aussi un weak_count ; nous verrons à quoi sert ce weak_count dans “Preventing Reference Cycles Using Weak<T>”.
Ce code affiche ceci :
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
compteur après la création de a = 1
compteur après la création de b = 2
compteur après la création de c = 3
compteur après que c est sorti de la portée = 2
Nous pouvons voir clairement que le Rc<List> dans a a un compteur de références initial à 1 ; puis à chaque fois que nous appelons clone, le compteur augmente de 1. Nous n’avons pas à appeler une fonction pour réduire le compteur de références, comme nous avons dû le faire avec Rc::clone pour augmenter compteur : l’implémentation du trait Drop réduit le compteur de références automatiquement lorsqu’une valeur de Rc<T> sort de la portée.
Ce que nous ne voyons pas dans cet exemple, c’est que lorsque b et a sortent de la portée à la fin du main, le compteur vaut 0 et que le Rc<List> est nettoyé complètement. L’utilisation de Rc<T> permet à une valeur d’avoir plusieurs propriétaires, et le compteur garantit que la valeur reste en vigueur tant qu’au moins un propriétaire existe encore.
Grâce aux références immuables, Rc<T> vous permet de partager des données entre plusieurs éléments de votre programme pour uniquement les lire. Si Rc<T> vous avait aussi permis d’avoir des références mutables, vous auriez alors violé une des règles d’emprunt vues au chapitre 4 : les emprunts mutables multiples à une même donnée peuvent causer des accès concurrents et des incohérences. Cependant, pouvoir modifier des données reste très utile ! Dans la section suivante, nous allons voir le motif de mutabilité interne et le type RefCell<T> que vous pouvez utiliser conjointement avec un Rc<T> pour pouvoir travailler avec cette contrainte d’immuabilité.
RefCell<T> et le motif de mutabilité interne
RefCell<T> et le motif de mutabilité interne
La mutabilité interne est un motif de conception en Rust qui vous permet de muter une donnée même s’il existe des références immuables ; normalement, cette action n’est pas autorisée par les règles d’emprunt. Pour muter des données, le motif utilise du code unsafe dans une structure de données pour contourner les règles courantes de Rust qui gouvernent la mutation et l’emprunt. Du code unsafe indique au compilateur que nous vérifions les règles manuellement au lieu de nous reposer sur le compilateur pour les vérifier ; nous verrons plus en détail le code unsafe au chapitre 20.
Nous pouvons utiliser des types qui utilisent le motif de mutabilité interne seulement lorsque nous pouvons être sûrs que les règles d’emprunt seront suivies au moment de l’exécution, même si le compilateur ne peut pas en être sûr. Le code unsafe concerné est ensuite incorporé dans une API sûre, et le type externe reste immuable.
Découvrons ce concept en examinant le type RefCell<T> qui applique le motif de mutabilité interne.
Appliquer les règles d’emprunt au moment de l’exécution
Contrairement à Rc<T>, le type RefCell<T> représente une propriété unique de la donnée qu’il contient. Qu’est-ce qui rend donc RefCell<T> différent d’un type comme Box<T> ? Souvenez-vous des règles d’emprunt que vous avez apprises au chapitre 4 :
- À un instant donné, vous pouvez avoir soit une référence mutable, soit un nombre quelconque de références immuables (mais pas les deux).
- Les références doivent toujours être en vigueur.
Avec les références et Box<T>, les règles d’emprunt obligatoires sont appliquées au moment de la compilation. Avec RefCell<T>, ces obligations sont appliquées au moment de l’exécution. Avec les références, si vous ne respectez pas ces règles, vous allez obtenir une erreur de compilation. Avec RefCell<T>, si vous ne les respectez pas, votre programme va paniquer et se fermer.
Les avantages de vérifier les règles d’emprunt au moment de la compilation est que les erreurs vont se produire plus tôt dans le processus de développement et qu’il n’y a pas d’impact sur les performances à l’exécution car toute l’analyse a déjà été faite au préalable. Pour ces raisons, la vérification des règles d’emprunt au moment de compilation est le meilleur choix à faire dans la majorité des cas, ce qui explique pourquoi c’est le choix par défaut de Rust.
L’avantage de vérifier les règles d’emprunt plutôt à l’exécution est que cela permet certains scénarios qui restent sûrs pour la mémoire, qui auraient été interdits par les vérifications effectuées à la compilation. L’analyse statique, comme le compilateur Rust, est de nature prudente. Certaines propriétés du code sont impossibles à détecter en analysant le code : l’exemple le plus connu est le problème de l’arrêt, qui dépasse le cadre de ce livre mais qui reste un sujet intéressant à étudier.
Comme certaines analyses sont impossibles, si le compilateur Rust ne peut pas s’assurer que le code respecte les règles d’emprunt, il risque de rejeter un programme valide ; dans ce sens, il est prudent. Si Rust accepte un programme incorrect, les utilisateurs ne pourront pas avoir confiance dans les garanties qu’apporte Rust. Cependant, si Rust rejette un programme valide, le développeur sera importuné, mais rien de catastrophique ne va se passer. Le type RefCell<T> est utile lorsque vous êtes sûr que votre code suit bien les règles d’emprunt mais que le compilateur est incapable de comprendre et de garantir cela.
De la même manière que Rc<T>, RefCell<T> sert uniquement pour des scénarios à une seule tâche et va vous donner une erreur à la compilation si vous essayez de l’utiliser dans un contexte multitâches. Nous verrons comment bénéficier des fonctionnalités de RefCell<T> dans un programme multi-processus au chapitre 16.
Voici un résumé des raisons de choisir Box<T>, Rc<T> ou RefCell<T> :
Rc<T>permet d’avoir plusieurs propriétaires pour une même donnée ;Box<T>etRefCell<T>n’ont qu’un seul propriétaire.Box<T>permet des emprunts immuables ou mutables à la compilation ;Rc<T>permet uniquement des emprunts immuables, vérifiés à la compilation ;RefCell<T>permet des emprunts immuables ou mutables, vérifiés à l’exécution.- Comme
RefCell<T>permet des emprunts mutables, vérifiés à l’exécution, vous pouvez muter la valeur à l’intérieur duRefCell<T>même si leRefCell<T>est immuable.
Modifer une valeur à l’intérieur d’une valeur immuable est ce qu’on appelle le motif de mutabilité interne. Découvrons une situation pour laquelle la mutabilité interne s’avère utile, puis examinons comment cela est rendu possible.
Utilisation de la mutabilité interne
Une des conséquences des règles d’emprunt est que lorsque vous avez une valeur immuable, vous ne pouvez pas emprunter sa mutabilité. Par exemple, ce code ne va pas se compiler :
fn main() {
let x = 5;
let y = &mut x;
}Si vous essayez de compiler ce code, vous allez obtenir l’erreur suivante :
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Cependant, il existe des situations pour lesquelles il serait utile qu’une valeur puisse se modifier elle-même dans ses propres méthodes mais qui semble être immuable pour le reste du code. Le code à l’extérieur des méthodes de la valeur n’est pas capable de modifier la valeur. L’utilisation de RefCell<T> est une manière de pouvoir procéder à des mutations internes. Mais RefCell<T> ne contourne pas complètement les règles d’emprunt : le vérificateur d’emprunt du compilateur permet cette mutabilité interne, et les règles d’emprunt sont plutôt vérifiées à l’exécution. Si vous violez les règles, vous allez provoquer un panic! plutôt que d’avoir une erreur de compilation.
Voyons un exemple pratique dans lequel nous pouvons utiliser RefCell<T> pour modifier une valeur immuable et voir en quoi cela est utile.
Tests à l’aide d’objets fictifs
Parfois, durant les phases de tests, un programmeur va utiliser un type à la place d’un autre, de manière à observer un comportement particulier et s’assurer qu’il l’implémente correctement. Ce type de remplacement est appelé un double de test. On peut voir cela comme un cascadeur doublant un acteur lors du tournage d’un film, où une personne remplace un acteur pour tourner une scène particulièrement dangereuse. Les doublures de test remplacent d’autres types durant l’exécution des tests. Les objets simulés (NdT : mock objects) sont des types particuliers de doubles de test qui enregistrent ce qui se passe lors d’un test, afin que vous puissiez vérifier que les actions se sont passées correctement.
Rust n’a pas d’objets au sens où l’entendent les autres langages qui en ont, et Rust n’offre pas non plus de fonctionnalité de mock object dans la bibliothèque standard comme le font d’autres langages. Cependant, vous pouvez très bien créer une structure qui va répondre aux mêmes besoins qu’un mock object.
Voici le scénario que nous allons tester : nous allons créer une bibliothèque qui surveillera la proximité d’une valeur par rapport à une valeur maximale et enverra des messages en fonction de cette limite. Par exemple, cette bibliothèque peut être utilisée pour suivre le quota d’un utilisateur afin de suivre le nombre d’appels aux API qu’il est autorisé à faire.
Notre bibliothèque fournira uniquement la fonctionnalité de suivi en fonction de la proximité d’une valeur avec la maximale et définira quels seront les messages associés. Les applications qui utiliseront notre bibliothèque devront fournir un mécanisme pour envoyer les messages : l’application peut afficher le message directement à l’utilisateur, l’envoyer par courriel, l’envoyer par SMS ou bien faire autre chose. La bibliothèque n’a pas à se charger de ce détail. Tout ce que ce mécanisme doit faire est d’implémenter un trait Messager que nous allons fournir. L’encart 15-20 propose le code pour cette bibliothèque.
pub trait Messager {
fn envoyer(&self, msg: &str);
}
pub struct TraqueurDeLimite<'a, T: Messager> {
messager: &'a T,
valeur: usize,
max: usize,
}
impl<'a, T> TraqueurDeLimite<'a, T>
where
T: Messager,
{
pub fn new(messager: &T, max: usize) -> TraqueurDeLimite<T> {
TraqueurDeLimite {
messager,
valeur: 0,
max,
}
}
pub fn set_valeur(&mut self, valeur: usize) {
self.valeur = valeur;
let pourcentage_du_maximum = self.valeur as f64 / self.max as f64;
if pourcentage_du_maximum >= 1.0 {
self.messager.envoyer("Erreur : vous avez dépassé votre quota !");
} else if pourcentage_du_maximum >= 0.9 {
self.messager
.envoyer("Avertissement urgent : vous avez utilisé 90% de votre quota !");
} else if pourcentage_du_maximum >= 0.75 {
self.messager
.envoyer("Avertissement : vous avez utilisé 75% de votre quota !");
}
}
}La partie la plus importante de ce code est celle où le trait Messager a une méthode qui fait appel à envoyer en prenant une référence immuable à self ainsi que le texte du message. Ce trait est l’interface que notre mock object doit implémenter afin que le mock puisse être utilisé de la même manière que l’objet réel. L’autre partie importante est lorsque nous souhaitons tester le comportement de la méthode set_valeur sur le TraqueurDeLimite. Nous pouvons changer ce que nous envoyons dans le paramètre valeur, mais set_valeur ne nous retourne rien qui nous permettrait de le vérifier. Nous voulons pouvoir dire que si nous créons un TraqueurDeLimite avec quelque chose qui implémente le trait Messager et une valeur précise pour max, le messager reçoit bien l’instruction d’envoyer les messages correspondants lorsque nous passons différents nombres pour valeur.
Nous avons besoin d’un mock object qui, au lieu d’envoyer un email ou un SMS lorsque nous faisons appel à envoyer, va seulement enregistrer les messages qu’on lui demande d’envoyer. Nous pouvons créer une nouvelle instance du mock object, créer un TraqueurDeLimite qui utilise le mock object, faire appel à la méthode set_value sur le TraqueurDeLimite et ensuite vérifier que le mock object a bien les messages que nous attendions. L’encart 15-21 montre une tentative d’implémentation d’un mock object qui fait ceci, mais le vérificateur d’emprunt ne nous autorise pas à le faire.
pub trait Messager {
fn envoyer(&self, msg: &str);
}
pub struct TraqueurDeLimite<'a, T: Messager> {
messager: &'a T,
valeur: usize,
max: usize,
}
impl<'a, T> TraqueurDeLimite<'a, T>
where
T: Messager,
{
pub fn new(messager: &T, max: usize) -> TraqueurDeLimite<T> {
TraqueurDeLimite {
messager,
valeur: 0,
max,
}
}
pub fn set_valeur(&mut self, valeur: usize) {
self.valeur = valeur;
let pourcentage_du_maximum = self.valeur as f64 / self.max as f64;
if pourcentage_du_maximum >= 1.0 {
self.messager.envoyer("Erreur : vous avez dépassé votre quota !");
} else if pourcentage_du_maximum >= 0.9 {
self.messager
.envoyer("Avertissement urgent : vous avez utilisé 90% de votre quota !");
} else if pourcentage_du_maximum >= 0.75 {
self.messager
.envoyer("Avertissement : vous avez utilisé 75% de votre quota !");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MessagerMock {
messages_envoyes: Vec<String>,
}
impl MessagerMock {
fn new() -> MessagerMock {
MessagerMock {
messages_envoyes: vec![],
}
}
}
impl Messager for MessagerMock {
fn envoyer(&self, message: &str) {
self.messages_envoyes.push(String::from(message));
}
}
#[test]
fn envoi_d_un_message_d_avertissement_superieur_a_75_pourcent() {
let messager_mock = MessagerMock::new();
let mut traqueur = TraqueurDeLimite::new(&messager_mock, 100);
traqueur.set_valeur(80);
assert_eq!(messager_mock.messages_envoyes.len(), 1);
}
}MockMessenger that isn’t allowed by the borrow checkerCe code de test définit une structure MessagerMock qui a un champ messages_envoyes qui est un Vec de valeurs String, afin d’y enregistrer les messages qui lui sont envoyés. Nous définissons également une fonction associée new pour faciliter la création de valeurs MessagerMock qui commencent avec une liste vide de messages. Nous implémentons ensuite le trait Messager sur MessagerMock afin de donner un MessagerMock à un TraqueurDeLimite. Dans la définition de la méthode envoyer, nous prenons le message envoyé en paramètre et nous le stockons dans la liste messages_envoyes du MessagerMock.
Dans le test, nous vérifions ce qui se passe lorsque le TraqueurDeLimite doit atteindre une valeur qui est supérieure à 75 pourcent de la valeur max. D’abord, nous créons un nouveau MessagerMock, qui va démarrer avec une liste vide de messages. Ensuite, nous créons un nouveau TraqueurDeLimite et nous lui donnons une référence vers ce MessagerMock et une valeur max de 100. Nous appelons la méthode set_valeur sur le TraqueurDeLimite avec une valeur de 80, qui est plus grande que 75 pourcents de 100. Enfin, nous vérifions que la liste de messages qu’a enregistrée le MessagerMock contient bien désormais un message.
Cependant, il reste un problème avec ce test, problème qui est montréci-dessous :
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.messages_envoyes` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.messages_envoyes.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn envoyer(&self, msg: &str);
3 | }
...
56 | impl Messager for MessagerMock {
57 ~ fn envoyer(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
Nous ne pouvons pas modifier le MessagerMock pour enregistrer les messages, car la méthode envoyer utilise une référence immuable à self. Nous ne pouvons pas non plus suivre la suggestion du texte d’erreur pour utiliser &mut self dans la méthode impl ainsi que dans la définition du trait. Nous ne voulons pas changer le trait Messenger uniquement dans le but de tester. À la place, nous devons trouver un moyen de faire en sorte que notre code de test fonctionne correctement avec la configuration existante.
C’est une situation dans laquelle la mutabilité interne peut nous aider ! Nous allons stocker messages_envoyes dans une RefCell<T>, et ensuite la méthode envoyer pourra modifier messages_envoyes pour stocker les messages que nous avons avons vus. L’encart 15-22 montre à quoi cela peut ressembler.
pub trait Messager {
fn envoyer(&self, msg: &str);
}
pub struct TraqueurDeLimite<'a, T: Messager> {
messager: &'a T,
valeur: usize,
max: usize,
}
impl<'a, T> TraqueurDeLimite<'a, T>
where
T: Messager,
{
pub fn new(messager: &T, max: usize) -> TraqueurDeLimite<T> {
TraqueurDeLimite {
messager,
valeur: 0,
max,
}
}
pub fn set_valeur(&mut self, valeur: usize) {
self.valeur = valeur;
let pourcentage_du_maximum = self.valeur as f64 / self.max as f64;
if pourcentage_du_maximum >= 1.0 {
self.messager.envoyer("Erreur : vous avez dépassé votre quota !");
} else if pourcentage_du_maximum >= 0.9 {
self.messager
.envoyer("Avertissement urgent : vous avez utilisé 90% de votre quota !");
} else if pourcentage_du_maximum >= 0.75 {
self.messager
.envoyer("Avertissement : vous avez utilisé 75% de votre quota !");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MessagerMock {
messages_envoyes: RefCell<Vec<String>>,
}
impl MessagerMock {
fn new() -> MessagerMock {
MessagerMock {
messages_envoyes: RefCell::new(vec![]),
}
}
}
impl Messager for MessagerMock {
fn envoyer(&self, message: &str) {
self.messages_envoyes.borrow_mut().push(String::from(message));
}
}
#[test]
fn envoi_d_un_message_d_avertissement_superieur_a_75_pourcent() {
// -- partie masquée ici --
let messager_mock = MessagerMock::new();
let mut traqueur = TraqueurDeLimite::new(&messager_mock, 100);
traqueur.set_valeur(80);
assert_eq!(messager_mock.messages_envoyes.borrow().len(), 1);
}
}RefCell<T> to mutate an inner value while the outer value is considered immutableLe champ messages_envoyes est maintenant du type RefCell<Vec<String>> au lieu de Vec<String>. Dans la fonction new, nous créons une nouvelle instance de RefCell<Vec<String>> autour du vecteur vide.
En ce qui concerne l’implémentation de la méthode envoyer, le premier paramètre est toujours un emprunt immuable de self, ce qui correspond à la définition du trait. Nous appelons la méthode borrow_mut sur le RefCell<Vec<String>> présent dans self.messages_envoyes pour obtenir une référence mutable vers la valeur présente dans le RefCell<Vec<String>>, qui correspond au vecteur. Ensuite, nous appelons push sur la référence mutable vers le vecteur pour enregistrer le message envoyé pendant le test.
Le dernier changement que nous devons appliquer se trouve dans la vérification : pour savoir combien d’éléments sont présents dans le vecteur, nous faisons appel à borrow de RefCell<Vec<String>> pour obtenir une référence immuable vers le vecteur.
Maintenant que vous avez appris à utiliser RefCell<T>, regardons comment il fonctionne !
Suivi des emprunts à l’exécution
Lorsque nous créons des références immuables et mutables, nous utilisons respectivement les syntaxes & et &mut. Avec RefCell<T>, nous utilisons les méthodes borrow et borrow_mut, qui font partie de l’API stable de RefCell<T>. La méthode borrow retourne un pointeur intelligent du type Ref<T> et borrow_mut retourne un pointeur intelligent du type RefMut<T>. Les deux implémentent Deref, donc nous pouvons les considérer comme des références classiques.
Le RefCell<T> suit combien de pointeurs intelligents Ref<T> et RefMut<T> sont actuellement actifs. À chaque fois que nous faisons appel à borrow, le RefCell<T> augmente son compteur du nombre d’emprunts immuables qui existent. Lorsqu’une valeur Ref<T> sort de la portée, le compteur d’emprunts immuables est décrémenté de 1. À tout moment RefCell<T> nous permet d’avoir plusieurs emprunts immuables ou bien un seul emprunt mutable, tout comme le font les règles d’emprunt au moment de la compilation.
Si nous ne respectons pas ces règles, l’implémentation de RefCell<T> va paniquer à l’exécution plutôt que de provoquer une erreur de compilation comme nous l’aurions eu en utilisant des références classiques. L’encart 15-23 nous montre une modification apportée à l’implémentation de envoyer de l’encart 15-22. Nous essayons délibérément de créer deux emprunts mutables actifs dans la même portée pour montrer que RefCell<T> nous empêche de faire ceci à l’exécution.
pub trait Messager {
fn envoyer(&self, msg: &str);
}
pub struct TraqueurDeLimite<'a, T: Messager> {
messager: &'a T,
valeur: usize,
max: usize,
}
impl<'a, T> TraqueurDeLimite<'a, T>
where
T: Messager,
{
pub fn new(messager: &T, max: usize) -> TraqueurDeLimite<T> {
TraqueurDeLimite {
messager,
valeur: 0,
max,
}
}
pub fn set_valeur(&mut self, valeur: usize) {
self.valeur = valeur;
let pourcentage_du_maximum = self.valeur as f64 / self.max as f64;
if pourcentage_du_maximum >= 1.0 {
self.messager.envoyer("Erreur : vous avez dépassé votre quota !");
} else if pourcentage_du_maximum >= 0.9 {
self.messager
.envoyer("Avertissement urgent : vous avez utilisé 90% de votre quota !");
} else if pourcentage_du_maximum >= 0.75 {
self.messager
.envoyer("Avertissement : vous avez utilisé 75% de votre quota !");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MessagerMock {
messages_envoyes: RefCell<Vec<String>>,
}
impl MessagerMock {
fn new() -> MessagerMock {
MessagerMock {
messages_envoyes: RefCell::new(vec![]),
}
}
}
impl Messager for MessagerMock {
fn envoyer(&self, message: &str) {
let mut premier_emprunt = self.messages_envoyes.borrow_mut();
let mut second_emprunt = self.messages_envoyes.borrow_mut();
premier_emprunt.push(String::from(message));
second_emprunt.push(String::from(message));
}
}
#[test]
fn envoi_d_un_message_d_avertissement_superieur_a_75_pourcent() {
let messager_mock = MessagerMock::new();
let mut traqueur = TraqueurDeLimite::new(&messager_mock, 100);
traqueur.set_valeur(80);
assert_eq!(messager_mock.messages_envoyes.borrow().len(), 1);
}
}RefCell<T> will panicNous créons une variable premier_emprunt pour le pointeur intelligent RefMut<T> retourné par borrow_mut. Ensuite nous créons un autre emprunt de la même manière, qui s’appelle second_emprunt. Cela fait deux références mutables dans la même portée, ce qui n’est pas autorisé. Lorsque nous lançons les tests sur notre bibliothèque, le code de l’encart 15-23 va se compiler sans erreur, mais les tests vont échouer :
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::envoi_d_un_message_d_avertissement_superieur_a_75_pourcent ... FAILED
failures:
---- tests::envoi_d_un_message_d_avertissement_superieur_a_75_pourcent stdout ----
thread 'tests::envoi_d_un_message_d_avertissement_superieur_a_75_pourcent' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::envoi_d_un_message_d_avertissement_superieur_a_75_pourcent
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Remarquez que le code a paniqué avec le message already borrowed: BorrowMutError (NdT : déjà emprunté). C’est ainsi que RefCell<T> gère les violations des règles d’emprunt à l’exécution.
Le choix de la détection des erreurs d’emprunt à l’exécution plutôt qu’à la compilation, comme nous venons de le faire ici, signifie que vous pourriez potentiellement découvrir des erreurs dans votre code, plus tard dans le processus de développement, et peut-être même pas avant que votre code ne soit déployé en production. De plus, votre code va subir une petite perte de performances à l’exécution en raison du contrôle des emprunts à l’exécution plutôt qu’à la compilation. Cependant, l’utilisation de RefCell<T> rend possible l’écriture d’un mock object qui peut se modifier lui-même afin d’enregistrer les messages qu’il a vu passer alors que vous l’utilisez dans un contexte où seules les valeurs immuables sont permises. Vous pouvez utiliser RefCell<T> malgré ses inconvénients pour obtenir plus de fonctionnalités que celles qu’offre une référence classique.
Permettre plusieurs propriétaires de données mutables
Il est courant d’utiliser RefCell<T> en tandem avec Rc<T>. Rappelez-vous que Rc<T> vous permet d’avoir plusieurs propriétaires d’une même donnée, mais qu’il ne vous donne qu’un seul accès immuable à cette donnée. Si vous avez un Rc<T> qui contient un RefCell<T>, vous pouvez obtenir une valeur qui peut avoir plusieurs propriétaires et que vous pouvez modifier !
Souvenez-vous de l’exemple de la liste de construction de l’encart 15-18 où nous avions utilisé Rc<T> pour permettre à plusieurs listes de se partager la possession d’une autre liste. Comme Rc<T> stocke seulement des valeurs immuables, nous ne pouvons changer aucune valeur dans la liste une fois que nous l’avons créée. Ajoutons un RefCell<T> pour sa capacité changer les valeurs dans les listes. L’encart 15-24 nous montre ceci en ajoutant un RefCell<T> dans la définition de Cons, nous pouvons ainsi modifier les valeurs stockées dans n’importe quelle liste.
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let valeur = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&valeur), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*valeur.borrow_mut() += 10;
println!("a après les opérations = {a:?}");
println!("b après les opérations = {b:?}");
println!("c après les opérations = {c:?}");
}Rc<RefCell<i32>> to create a List that we can mutateNous créons une valeur qui est une instance de Rc<RefCell<i32>> et nous la stockons dans une variable valeur afin que nous puissions y avoir accès plus tard. Ensuite, nous créons une List dans a avec une variante de Cons qui utilise valeur. Nous devons utiliser clone sur valeur afin que a et valeur soient toutes les deux propriétaires de la valeur interne 5 plutôt que d’avoir à transférer la possession de valeur à a ou avoir a qui emprunte valeur.
Nous insérons la liste a dans un Rc<T> pour que, lorsque nous créons b et c, elles puissent toutes les deux utiliser a, ce que nous avions déjà fait dans l’encart 15-18.
Après avoir créé les listes dans a, b, et c, nous ajoutons 10 à la valeur dans valeur. Nous faisons cela en appelant borrow_mut sur valeur, ce qui utilise la fonctionnalité de déréférencement automatique que nous avons vue dans la section “Où est l’opérateur -> ?” du chapitre 5 pour déréférencer le Rc<T> dans la valeur interne RefCell<T>. La méthode borrow_mut retourne un pointeur intelligent RefMut<T>, et nous utilisons l’opérateur de déréférencement sur lui pour changer sa valeur interne.
Lorsque nous affichons a, b et c, nous pouvons constater qu’elles ont toutes la valeur modifiée de 15 au lieu de 5 :
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a après les opérations = Cons(RefCell { value: 15 }, Nil)
b après les opérations = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c après les opérations = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Cette technique est plutôt ingénieuse ! En utilisant RefCell<T>, nous avons une valeur List qui est immuable de l’extérieur. Mais nous pouvons utiliser les méthodes de RefCell<T> qui nous donnent accès à sa mutabilité interne afin que nous puissions modifier notre donnée lorsque nous en avons besoin. Les vérifications des règles d’emprunt à l’exécution nous protègent des accès concurrents, et il est parfois intéressant de sacrifier un peu de vitesse pour cette flexibilité dans nos structures de données. Notez que RefCell<T> ne fonctionne pas pour du code avec plusieurs fils d’exécution concurrents ! Mutex<T> est la version compatible avec la concurrence de RefCell<T>, nous aborderons le sujet des Mutex<T> dans le chapitre 16.
Les boucles de références peuvent provoquer des fuites de mémoire
Les boucles de références peuvent provoquer des fuites de mémoire
Les garanties de sécurité de la mémoire de Rust rendent difficile, mais pas impossible, la création accidentelle de mémoire qui n’est jamais nettoyée (aussi appelée fuite de mémoire). Éviter totalement les fuites de mémoire n’est pas une des garanties de Rust, en tout cas pas comme pour l’accès concurrent au moment de la compilation, ce qui signifie que les fuites de mémoire sont sans risque pour la mémoire avec Rust. Nous pouvons constater que Rust permet les fuites de mémoire en utilisant Rc<T> et RefCell<T> : il est possible de créer des références où les éléments se réfèrent entre eux de manière cyclique. Cela crée des fuites de mémoire car le compteur de références de chaque élément dans la boucle de références ne vaudra jamais 0, et les valeurs ne seront jamais libérées.
Créer une boucle de références
Voyons comment une boucle de références peut exister et comment l’éviter, en commençant par la définition de l’énumération List et la méthode parcourir de l’encart 15-25.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn parcourir(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {}RefCell<T> so that we can modify what a Cons variant is referring toNous utilisons une autre variation de la définition de List de l’encart 15-5. Le second élément dans la variante Cons est maintenant un RefCell<Rc<List>>, ce qui signifie qu’au lieu de pouvoir modifier la valeur i32 comme nous l’avions fait dans l’encart 15-24, nous modifions la valeur List sur laquelle une variante Cons pointe. Nous ajoutons également une méthode parcourir pour nous faciliter l’accès au second élément si nous avons une variante Cons.
Dans l’encart 15-26, nous ajoutons une fonction main qui utilise les définitions de l’encart 15-25. Ce code crée une liste dans a et une liste dans b qui pointe sur la liste de a. Ensuite, on modifie la liste de a pour pointer sur b, ce qui crée une boucle de références. Il y a aussi des instructions println! tout du long pour montrer la valeur des compteurs de références à différents endroits du processus.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn parcourir(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("compteur initial de a = {}", Rc::strong_count(&a));
println!("prochain élément de a = {:?}", a.parcourir());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("compteur de a après création de b = {}", Rc::strong_count(&a));
println!("compteur initial de b = {}", Rc::strong_count(&b));
println!("prochain élément de b = {:?}", b.parcourir());
if let Some(lien) = a.parcourir() {
*lien.borrow_mut() = Rc::clone(&b);
}
println!("compteur de b après avoir changé a = {}", Rc::strong_count(&b));
println!("compteur de a après avoir changé a = {}", Rc::strong_count(&a));
// Décommentez la ligne suivante pour constater que nous sommes dans
// une boucle de références, cela fera déborder la pile
// println!("prochain élément de a = {:?}", a.parcourir());
}List values pointing to each otherNous créons une instance Rc<List> qui stocke une valeur List dans la variable a avec une valeur initiale de 5, Nil. Nous créons ensuite une instance Rc<List> qui stocke une autre valeur List dans la variable b qui contient la valeur 10 et pointe vers la liste dans a.
Nous modifions a afin qu’elle pointe sur b au lieu de Nil, ce qui crée une boucle. Nous faisons ceci en utilisant la méthode parcourir pour obtenir une référence au RefCell<Rc<List>> présent dans a, que nous plaçons dans la variable lien. Ensuite nous utilisons la méthode borrow_mut sur le RefCell<Rc<List>> pour remplacer la valeur actuellement présente en son sein, la Rc<List> contenant Nil, par la Rc<List> présente dans b.
Lorsque nous exécutons ce code, en gardant le dernier println! commenté pour le moment, nous obtenons ceci :
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
compteur initial de a = 1
prochain élément de a = Some(RefCell { value: Nil })
compteur de a après création de b = 2
compteur initial de b = 1
prochain élément de b = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
compteur de b après avoir changé a = 2
compteur de a après avoir changé a = 2
Les compteurs de références des instances de Rc<List> valent tous les deux 2 pour a et b après avoir modifié a pour qu’elle pointe sur b. À la fin du main, Rust nettoie d’abord la variable b, ce qui décrémente le compteur de références dans l’instance Rc<List> de 2 à 1. La mémoire utilisée sur le tas par Rc<List> ne sera pas libérée à ce moment, car son compteur de références est à 1, et non pas 0. Puis, Rust libère a, ce qui décrémente le compteur a de références Rc<List> de 2 à 1, également. La mémoire de cette instance ne peut pas non plus être libérée car l’autre instance Rc<List> y fait toujours référence. La mémoire alouée à la liste ne sera jamais libérée. Pour représenter cette boucle de références, nous avons créé un diagramme dans l’illustration 15-4.

Illustration 15-4 : Une boucle de références entre les listes a et b qui se pointent mutuellement dessus
Si vous décommentez le dernier println! et que vous exécutez le programme, Rust va essayer d’afficher cette boucle avec a qui pointe sur b qui pointe sur a … et ainsi de suite jusqu’à ce que cela fasse déborder la pile.
Par rapport à un programme dans le monde réel, les conséquences de la boucle dans cet exemple ne sont pas désastreuses : juste après avoir créé la boucle de références, le programme se termine. Cependant, si un programme plus complexe alloue beaucoup de mémoire dans une boucle de références et la garde pendant longtemps, le programme va utiliser bien plus de mémoire qu’il n’en a besoin et pourrait saturer le système en consommant ainsi toute la mémoire disponible.
La création de boucles de références n’est pas facile à réaliser, mais n’est pas non plus impossible. Si vous avez des valeurs RefCell<T> qui contiennent des valeurs Rc<T> ou des combinaisons similaires de types emboîtés avec de la mutabilité interne et du comptage de références, vous devez vous assurer que vous ne créez pas de boucles ; vous ne pouvez pas compter sur Rust pour les détecter. La création de boucle de références devrait être un bogue de logique de votre programme dont vous devriez réduire le risque en pratiquant des tests automatisés, des revues de code, ainsi que d’autres pratiques de développement.
Une autre solution pour éviter les boucles de références est de réorganiser vos structures de données afin que certaines références prennent possession et d’autres non. Par conséquent, vous pouvez obtenir des boucles de certaines références qui prennent possession ou d’autres références qui ne prennent pas possession, et seules celles qui prennent possession décident si oui ou non une valeur peut être libérée. Dans l’encart 15-25, nous voulons toujours que les variantes Cons possèdent leur propre liste, donc il est impossible de réorganiser la structure des données. Voyons maintenant un exemple qui utilise des graphes constitués de nœuds parents et de nœuds enfants pour voir quand des relations sans possessions constituent un moyen approprié d’éviter les boucles de références.
Éviter les boucles de références en utilisant Weak<T>
Précédemment, nous avons démontré que l’appel à Rc::clone augmente le strong_count d’une instance de Rc<T>, et une instance Rc<T> est nettoyée seulement si son strong_count est à 0. Vous pouvez aussi créer une référence faible (NdT : d’où le weak) vers la valeur présente dans une instance Rc<T> en appelant Rc::downgrade et en lui passant une référence vers le Rc<T>. Les références fortes désignent la manière de partager la propriété d’une instance Rc<T>. Les références faibles n’expriment pas de relation de possession, et leur compteur n’a aucune incidence quand une instance de Rc<T> est libérée. Ils ne provoqueront pas de boucle de références car n’importe quelle boucle impliquant des références faibles sera détruite une fois que le compteur de références fortes des valeurs impliquées vaudra 0.
Lorsque vous faites appel à Rc::downgrade, vous obtenez un pointeur intelligent du type Weak<T>. Plutôt que d’augmenter le strong_count de l’instance de 1, l’appel à Rc::downgrade augmente le weak_count de 1. Le type Rc<T> utilise le weak_count pour compter combien de références Weak<T> existent, de la même manière que strong_count. La différence réside dans le fait que weak_count n’a pas besoin d’être à 0 pour que l’instance Rc<T> soit nettoyée.
Comme la valeur contenue dans une référence Weak<T> peut être libérée, pour pouvoir faire quelque chose avec cette valeur, vous devez vous assurer qu’elle existe toujours. Vous pouvez faire ceci en appelant la méthode upgrade sur une instance Weak<T>, qui va retourner une Option<Rc<T>>. Ce résultat retournera Some si la valeur Rc<T> n’a pas encore été libérée, et un None si la valeur Rc<T> a été libérée. Comme upgrade retourne une Option<Rc<T>>, Rust va s’assurer que les cas de Some et de None sont bien gérés, et qu’il n’existe pas de pointeur invalide.
Par exemple, plutôt que d’utiliser une liste dont les éléments ne connaissent que les éléments suivants, nous allons créer un arbre dont les éléments connaissent les éléments enfants et leurs éléments parents.
Création d’une structure d’arbre de données
Pour commencer, nous allons créer un arbre avec des nœuds qui connaissent leurs nœuds enfants. Nous allons créer une structure Noeud qui contient sa propre valeur ainsi que les références vers ses Noeud enfants :
Fichier : src/main.rs
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Noeud {
valeur: i32,
enfants: RefCell<Vec<Rc<Noeud>>>,
}
fn main() {
let feuille = Rc::new(Noeud {
valeur: 3,
enfants: RefCell::new(vec![]),
});
let branche = Rc::new(Noeud {
valeur: 5,
enfants: RefCell::new(vec![Rc::clone(&feuille)]),
});
}Nous souhaitons qu’un Noeud prenne possession de ses enfants, et nous souhaitons partager la possession avec des variables afin d’accéder directement à chaque Noeud de l’arbre. Pour pouvoir faire ceci, nous définissons les éléments du Vec<T> comme étant des valeurs du type Rc<Noeud>. Nous souhaitons également pouvoir modifier le fait que tel nœud soit enfant de tel autre, donc, dans enfants, nous englobons le Vec<Rc<Noeud>> dans un RefCell<T>.
Ensuite, nous allons utiliser notre définition de structure et créer une instance de Noeud qui s’appellera feuille avec la valeur 3 et sans enfant, comme dans l’encart 15-27.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Noeud {
valeur: i32,
enfants: RefCell<Vec<Rc<Noeud>>>,
}
fn main() {
let feuille = Rc::new(Noeud {
valeur: 3,
enfants: RefCell::new(vec![]),
});
let branche = Rc::new(Noeud {
valeur: 5,
enfants: RefCell::new(vec![Rc::clone(&feuille)]),
});
}leaf node with no children and a branch node with leaf as one of its childrenNous créons un clone du Rc<Noeud> dans feuille et nous le stockons dans branche, ce qui signifie que le Noeud dans feuille a maintenant deux propriétaires : feuille et branche. Nous pouvons obtenir feuille à partir de branche en utilisant branche.feuille, mais il n’y a pas de moyen d’obtenir branche à partir de feuille. La raison est que feuille n’a pas de référence vers branche et ne sait pas s’ils sont liés. Nous voulons que feuille sache quelle branche est son parent. C’est ce que nous allons faire dès maintenant.
Ajouter une référence à un enfant vers son parent
Pour que le nœud enfant connaisse son parent, nous devons ajouter un champ parent vers notre définition de structure Noeud. La difficulté ici est de choisir quel sera le type de parent. Nous savons qu’il ne peut pas contenir de Rc<T>, car cela créera une boucle de référence avec feuille.parent qui pointe sur branche et branche.enfant qui pointe sur feuille, ce qui va faire que leurs valeurs strong_count ne seront jamais à 0.
En concevant le lien d’une autre manière, un nœud parent devrait prendre possession de ses enfants : si un nœud parent est libéré, ses nœuds enfants devraient aussi être libérés. Cependant, un enfant ne devrait pas prendre possession de son parent : si nous libérons un nœud enfant, le parent doit toujours exister. C’est donc un cas d’emploi pour les références faibles !
Donc, plutôt qu’un Rc<T>, nous allons faire en sorte que le type de parent soit un Weak<T>, plus précisément un RefCell<Weak<Noeud>>. Maintenant, la définition de notre structure Noeud devrait ressembler à ceci :
Fichier : src/main.rs
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Noeud {
valeur: i32,
parent: RefCell<Weak<Noeud>>,
enfants: RefCell<Vec<Rc<Noeud>>>,
}
fn main() {
let feuille = Rc::new(Noeud {
valeur: 3,
parent: RefCell::new(Weak::new()),
enfants: RefCell::new(vec![]),
});
println!("parent de la feuille = {:?}", feuille.parent.borrow().upgrade());
let branche = Rc::new(Noeud {
valeur: 5,
parent: RefCell::new(Weak::new()),
enfants: RefCell::new(vec![Rc::clone(&feuille)]),
});
*feuille.parent.borrow_mut() = Rc::downgrade(&branche);
println!("parent de la feuille = {:?}", feuille.parent.borrow().upgrade());
}Un nœud devrait pouvoir avoir une référence vers son nœud parent, mais il ne devrait pas prendre possession de son parent. Dans l’encart 15-28, nous mettons à jour cette nouvelle définition pour que le nœud feuille puisse avoir un moyen de pointer vers son parent, branche :
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Noeud {
valeur: i32,
parent: RefCell<Weak<Noeud>>,
enfants: RefCell<Vec<Rc<Noeud>>>,
}
fn main() {
let feuille = Rc::new(Noeud {
valeur: 3,
parent: RefCell::new(Weak::new()),
enfants: RefCell::new(vec![]),
});
println!("parent de la feuille = {:?}", feuille.parent.borrow().upgrade());
let branche = Rc::new(Noeud {
valeur: 5,
parent: RefCell::new(Weak::new()),
enfants: RefCell::new(vec![Rc::clone(&feuille)]),
});
*feuille.parent.borrow_mut() = Rc::downgrade(&branche);
println!("parent de la feuille = {:?}", feuille.parent.borrow().upgrade());
}leaf node with a weak reference to its parent node, branchLa création du nœud feuille semble être identique à l’encart 15-27, sauf pour le champ parent : feuille commence sans parent, donc nous créons une nouvelle instance de référence de type Weak<Noeud>, qui est vide.
À ce moment-là, lorsque nous essayons d’obtenir une référence vers le parent de feuille en utilisant la méthode upgrade, nous obtenons une valeur None. Nous constatons cela dans la première instruction println! sur la sortie :
parent de la feuille = None
Lorsque nous créons le nœud branche, il va aussi avoir une nouvelle référence Weak<Noeud> dans le champ parent, car branche n’a pas de nœud parent. Nous avons néanmoins feuille dans enfants de branche. Une fois que nous avons l’instance de Noeud dans branche, nous pouvons modifier feuille pour lui donner une référence Weak<Noeud> vers son parent. Nous utilisons la méthode borrow_mut sur la RefCell<Weak<Noeud>> du champ parent de feuille, et ensuite nous utilisons la fonction Rc::downgrade pour créer une référence de type Weak<Node> vers branche à partir du Rc<Noeud> présent dans branche.
Lorsque nous affichons à nouveau le parent de feuille, cette fois nous obtenons la variante Some qui contient branche : désormais, feuille peut accéder à son parent ! Lorsque nous affichons feuille, nous avons aussi évité la boucle qui aurait probablement fini en débordement de pile comme nous l’avions expérimenté dans l’encart 15-26 ; les références Weak<Noeud> s’écrivent (Weak) :
parent de la feuille = Some(Noeud { valeur: 5, parent: RefCell { value: (Weak) },
enfants: RefCell { value: [Noeud { valeur: 3, parent: RefCell { value: (Weak) },
enfants: RefCell { value: [] } }] } })
L’absence d’une sortie infinie nous confirme que ce code ne crée pas de boucle de références. Nous pouvons aussi le constater en affichant les valeurs que nous pouvons obtenir en faisant appel à Rc::strong_count et Rc::weak_count.
Visualiser les modifications de strong_count et weak_count
Regardons comment changent les valeurs strong_count et weak_count des instances de Rc<Noeud> en créant une portée interne et en déplaçant la création de branche dans cette portée. En faisant ceci, nous pourrons constater ce qui se passe lorsque branche est créée et lorsqu’elle sera libérée lorsqu’elle sortira de la portée. Ces modifications sont présentées dans l’encart 15-29.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Noeud {
valeur: i32,
parent: RefCell<Weak<Noeud>>,
enfants: RefCell<Vec<Rc<Noeud>>>,
}
fn main() {
let feuille = Rc::new(Noeud {
valeur: 3,
parent: RefCell::new(Weak::new()),
enfants: RefCell::new(vec![]),
});
println!(
"feuille strong = {}, weak = {}",
Rc::strong_count(&feuille),
Rc::weak_count(&feuille),
);
{
let branche = Rc::new(Noeud {
valeur: 5,
parent: RefCell::new(Weak::new()),
enfants: RefCell::new(vec![Rc::clone(&feuille)]),
});
*feuille.parent.borrow_mut() = Rc::downgrade(&branche);
println!(
"branche strong = {}, weak = {}",
Rc::strong_count(&branche),
Rc::weak_count(&branche),
);
println!(
"feuille strong = {}, weak = {}",
Rc::strong_count(&feuille),
Rc::weak_count(&feuille),
);
}
println!("parent de la feuille = {:?}", feuille.parent.borrow().upgrade());
println!(
"feuille strong = {}, weak = {}",
Rc::strong_count(&feuille),
Rc::weak_count(&feuille),
);
}branch in an inner scope and examining strong and weak reference countsAprès la création de feuille, son Rc<Noeud> a le compteur strong à 1 et le compteur weak à 0. Dans la portée interne, nous créons branche et l’associons à feuille, et à partir de là, lorsque nous affichons les compteurs, le Rc<Noeud> dans branche aura le compteur strong à 1 et le compteur weak à 1 (pour que feuille.parent pointe sur branche avec un Weak<Noeud>). Lorsque nous affichons les compteurs dans feuille nous constatons qu’il a le compteur strong à 2, car branche a maintenant un clone du Rc<Noeud> de feuille stocké dans branche.enfants, mais a toujours le compteur weak à 0.
Lorsque la portée interne se termine, branche sort de la portée et le compteur strong de Rc<Noeud> décroît à 0, donc son Noeud est libéré. Le compteur weak à 1 de feuille.parent n’a aucune répercussion suite à la libération ou non du Noeud, donc nous ne sommes pas dans une situation de fuite de mémoire !
Si nous essayons d’accéder au parent de feuille après la fin de la portée, nous allons à nouveau obtenir None. À la fin du programme, le Rc<Noeud> dans feuille a son compteur strong à 1 et son compteur weak à 0 car la variable feuille est à nouveau la seule référence au Rc<Noeud>.
Toute cette logique qui gère les compteurs et les libérations des valeurs est intégrée dans Rc<T> et Weak<T> et leurs implémentations du trait Drop. En précisant dans la définition de Noeud que le lien entre un enfant et son parent doit être une référence Weak<T>, vous pouvez avoir des nœuds parents qui pointent sur des nœuds enfants et vice versa sans risquer de créer des boucles de références et des fuites de mémoire.
Résumé
Ce chapitre a expliqué l’utilisation des pointeurs intelligents pour appliquer des garanties et des compromis différents de ceux qu’applique Rust par défaut avec les références classiques. Le type Box<T> a une taille connue et pointe sur une donnée allouée sur le tas. Le type Rc<T> compte le nombre de références vers une donnée présente sur le tas afin que cette donnée puisse avoir plusieurs propriétaires. Le type RefCell<T> nous permet de l’utiliser lorsque nous avons besoin d’un type immuable mais que nous avons besoin de changer une valeur interne à ce type, grâce à sa fonctionnalité de mutabilité interne ; elle nous permet aussi d’appliquer les règles d’emprunt à l’exécution plutôt qu’à la compilation.
Nous avons aussi vu les traits Deref et Drop, qui offrent des fonctionnalités très importantes aux pointeurs intelligents. Nous avons expérimenté les boucles de références qui peuvent causer des fuites de mémoire et nous avons vu comment les éviter en utilisant Weak<T>.
Si ce chapitre a éveillé votre curiosité et que vous souhaitez mettre en œuvre vos propres pointeurs intelligents, visitez “The Rustonomicon” pour en savoir plus.
Au chapitre suivant, nous allons parler de concurrence en Rust. Vous découvrirez peut-être même quelques nouveaux pointeurs intelligents …
La concurrence sans craintes
Le développement sécurisé et efficace dans des contextes de concurrence est un autre objectif majeur de Rust. La programmation concurrente, dans laquelle différentes parties d’un programme s’exécutent de manière indépendante, et le parallélisme, dans lequel différentes parties d’un programme s’exécutent en même temps, sont devenus des pratiques de plus en plus importantes au fur et à mesure que les ordinateurs tirent parti de leurs processeurs multiples. Historiquement, le développement dans ces contextes était difficile et favorisait les erreurs : Rust compte bien changer la donne.
Au début, l’équipe de Rust pensait que garantir la sécurité de la mémoire et éviter les problèmes de concurrence étaient deux challenges distincts qui devaient être résolus de manières différentes. Avec le temps, l’équipe a découvert que les systèmes de possession et de type sont des jeux d’outils puissants qui aident à sécuriser la mémoire et à régler des problèmes de concurrence ! En exploitant la possession et la vérification de type, de nombreuses erreurs de concurrence deviennent des erreurs à la compilation en Rust plutôt que des erreurs à l’exécution. Ainsi, plutôt que d’avoir à passer beaucoup de votre temps à tenter de reproduire les circonstances exactes dans lesquelles un bogue de concurrence s’est produit à l’exécution, le code incorrect va refuser de se compiler et va vous afficher une erreur expliquant le problème. Au final, vous pouvez corriger votre code pendant que vous travaillez dessus plutôt que d’avoir à le faire a posteriori après qu’il ait potentiellement été livré en production. Nous avons surnommé cet aspect de Rust la concurrence sans craintes. La concurrence sans craintes vous permet d’écrire du code dépourvu de bogues subtils et qu’il sera facile de remanier sans risquer d’introduire de nouveaux bogues.
Remarque : pour des raisons de simplicité, nous allons désigner la plupart des problèmes par des problèmes de concurrence plutôt que d’être trop précis en disant des problèmes de concurrence et/ou de parallélisme. Pour ce chapitre, veuillez garder à l’esprit que nous parlons de concurrence et/ou de parallélisme à chaque fois que nous parlerons de concurrence. Dans le prochain chapitre, où la distinction est plus importante, nous serons plus précis.
De nombreux langages sont dogmatiques sur les solutions qu’ils offrent pour gérer les problèmes de concurrence. Par exemple, Erlang a une fonctionnalité élégante de passage de messages pour la concurrence mais a une façon étrange de partager un état entre les tâches. Ne proposer qu’un sous-ensemble de solutions possibles est une stratégie acceptable pour les langages de haut niveau, car un langage de haut niveau offre des avantages en sacrifiant certains contrôles afin d’être plus accessible. Cependant, les langages de bas niveau sont censés fournir la solution la plus performante dans n’importe quelle situation donnée et proposer moins d’abstraction vis-à-vis du matériel. C’est pourquoi Rust offre toute une gamme d’outils pour répondre aux problèmes de modélisation quelle que soit la manière qui est adaptée à la situation et aux exigences.
Voici les sujets que nous allons aborder dans ce chapitre :
- comment créer des tâches pour exécuter plusieurs parties de code en même temps ;
- le passage de message en concurrence, qui permet à plusieurs tâches d’accéder à la même donnée ;
- la concurrence à état partagé, dans laquelle plusieurs tâches ont accès à une partie des données ;
- les traits
SyncetSend, qui étendent les garanties de Rust sur la concurrence tant aux types définis par les utilisateurs qu’à ceux fournis par la bibliothèque standard.
Utiliser les tâches pour exécuter simultanément du code
Utiliser les tâches pour exécuter simultanément du code
Dans la plupart des systèmes d’exploitation actuels, le code d’un programme est exécuté dans un processus, et le système d’exploitation gère plusieurs processus à la fois. Dans votre programme, vous pouvez vous aussi avoir des parties indépendantes qui s’exécutent simultanément. Les éléments qui font fonctionner ces parties indépendantes sont appelés les tâches. Par exemple, un serveur web peut disposer de plusieurs tâches afin de pouvoir répondre à plus d’une requête à la fois.
Le découpage des calculs de votre programme dans plusieurs tâches pour faire plusieurs choses à la fois peut améliorer sa performance, mais cela rajoute aussi de la complexité. Comme les tâches peuvent s’exécuter de manière simultanée, il n’y a pas de garantie absolue sur l’ordre d’exécution des différentes parties de votre code. Cela peut poser des problèmes, tels que :
- les situations de concurrence, durant lesquelles les tâches accèdent à des données ou des ressources dans un ordre incohérent ;
- des interblocages, durant lesquels deux tâches attendent mutuellement que l’autre finisse d’utiliser une ressource que l’autre tâche utilise, bloquant la progression des deux tâches ;
- des bogues qui surgissent uniquement dans certaines situations et qui sont difficiles à reproduire et corriger durablement.
Rust cherche à atténuer les effets indésirables de l’utilisation des tâches, mais le développement dans un contexte multitâches exige toujours une attention particulière et nécessite une structure de code différente de celle des programmes qui s’exécutent dans une seule tâche.
Les langages de programmation implémentent les tâches de différentes manières, et de nombreux systèmes d’exploitation offrent une API que le langage de programmation peut appeler pour créer de nouvelles tâches. La bibliothèque standard de Rust utilise un modèle d’implémentation des tâches de type 1:1, dans lequel un programme utilise une tâche du système d’exploitation par tâche dans le langage de programmation. Il existe des crates qui implémentent d’autres modèles qui font des choix différents (le système asynchrone de Rust, que nous aborderons dans le chapitre suivant, fournit une autre approche de la concurrence).
Créer une nouvelle tâche avec spawn
Pour créer une nouvelle tâche, nous appelons la fonction thread::spawn et nous lui passons une fermeture (nous avons vu les fermetures au chapitre 13) qui contient le code que nous souhaitons exécuter dans la nouvelle tâche. L’exemple dans l’encart 16-1 affiche du texte à partir de la tâche principale et un autre texte à partir d’une nouvelle tâche.
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("Bonjour n°{} à partir de la nouvelle tâche !", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("Bonjour n°{} à partir de la tâche principale !", i);
thread::sleep(Duration::from_millis(1));
}
}Remarquez que lorsque la tâche principale d’un programme Rust s’arrête, toutes les tâches créées sont arrêtées, qu’elles aient terminé leur exécution ou pas. La sortie de ce programme peut être différente à chaque fois, mais elle devrait ressembler à ceci :
Bonjour n°1 à partir de la tâche principale !
Bonjour n°1 à partir de la nouvelle tâche !
Bonjour n°2 à partir de la tâche principale !
Bonjour n°2 à partir de la nouvelle tâche !
Bonjour n°3 à partir de la tâche principale !
Bonjour n°3 à partir de la nouvelle tâche !
Bonjour n°4 à partir de la tâche principale !
Bonjour n°4 à partir de la nouvelle tâche !
Bonjour n°5 à partir de la nouvelle tâche !
Les appels à thread::sleep forcent une tâche à mettre en pause son exécution pendant une petite durée, permettant à une autre tâche de s’exécuter. Les tâches se relaieront probablement, mais ce n’est pas garanti : cela dépend de comment votre système d’exploitation agence les tâches. Lors de cette exécution, la tâche principale a écrit en premier, même si l’instruction d’écriture de la nouvelle tâche apparaissait d’abord dans le code. Et même si nous avons demandé à la nouvelle tâche d’écrire jusqu’à ce que i vaille 9, elle ne l’a fait que jusqu’à 5, moment où la tâche principale s’est arrêtée.
Si vous exécutez ce code et que vous ne voyez que du texte provenant de la tâche principale, ou que vous ne voyez aucun chevauchement, essayez d’augmenter les nombres dans les intervalles pour donner plus d’opportunités au système d’exploitation pour basculer entre les tâches.
Attendre que toutes les tâches aient fini
Le code dans l’encart 16-1 non seulement stoppe la nouvelle tâche prématurément la plupart du temps à cause de la fin de la tâche principale, mais parce qu’il n’y a pas de garantie sur l’ordre dans lequel les tâches vont s’exécuter, nous ne garantissons pas non plus que la nouvelle tâche va s’exécuter ne serait-ce qu’une seule fois !
Nous pouvons régler le problème des nouvelles tâches qui ne s’exécutent pas, ou qui se terminent prématurément, en sauvegardant la valeur de retour de thread::spawn dans une variable. Le type de retour de thread::spawn est JoinHandle<T>. Un JoinHandle<T> est une valeur possédée qui, lorsque nous appelons la méthode join sur elle, va attendre que ses tâches finissent. L’encart 16-2 montre comment utiliser le JoinHandle<T> de la tâche que nous avons créée dans l’encart 16-1 et comment appeler la méthode join pour s’assurer que la nouvelle tâche finit bien avant que main ne se termine.
use std::thread;
use std::time::Duration;
fn main() {
let manipulateur = thread::spawn(|| {
for i in 1..10 {
println!("Bonjour n°{} à partir de la nouvelle tâche !", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("Bonjour n°{} à partir de la tâche principale !", i);
thread::sleep(Duration::from_millis(1));
}
manipulateur.join().unwrap();
}JoinHandle<T> from thread::spawn to guarantee the thread is run to completionL’appel à join sur le manipulateur bloque la tâche qui s’exécute actuellement jusqu’à ce que la tâche représentée par le manipulateur se termine. Bloquer une tâche signifie que cette tâche est empêchée d’accomplir un quelconque travail ou de se terminer. Comme nous avons inséré l’appel à join après la boucle for de la tâche principale, l’exécution de l’encart 16-2 devrait produire un résultat similaire à celui-ci :
Bonjour n°1 à partir de la tâche principale !
Bonjour n°2 à partir de la tâche principale !
Bonjour n°1 à partir de la nouvelle tâche !
Bonjour n°3 à partir de la tâche principale !
Bonjour n°2 à partir de la nouvelle tâche !
Bonjour n°4 à partir de la tâche principale !
Bonjour n°3 à partir de la nouvelle tâche !
Bonjour n°4 à partir de la nouvelle tâche !
Bonjour n°5 à partir de la nouvelle tâche !
Bonjour n°6 à partir de la nouvelle tâche !
Bonjour n°7 à partir de la nouvelle tâche !
Bonjour n°8 à partir de la nouvelle tâche !
Bonjour n°9 à partir de la nouvelle tâche !
Les deux tâches continuent à alterner, mais la tâche principale attend à cause de l’appel à manipulateur.join() et ne se termine pas avant que la nouvelle tâche ne soit finie.
Mais voyons maintenant ce qui se passe lorsque nous déplaçons le manipulateur.join() avant la boucle for du main comme ceci :
use std::thread;
use std::time::Duration;
fn main() {
let manipulateur = thread::spawn(|| {
for i in 1..10 {
println!("Bonjour n°{} à partir de la nouvelle tâche !", i);
thread::sleep(Duration::from_millis(1));
}
});
manipulateur.join().unwrap();
for i in 1..5 {
println!("Bonjour n°{} à partir de la tâche principale !", i);
thread::sleep(Duration::from_millis(1));
}
}La tâche principale va attendre que la nouvelle tâche se finisse et ensuite exécuter sa boucle for, ainsi la sortie ne sera plus chevauchée, comme ci-dessous :
Bonjour n°1 à partir de la nouvelle tâche !
Bonjour n°2 à partir de la nouvelle tâche !
Bonjour n°3 à partir de la nouvelle tâche !
Bonjour n°4 à partir de la nouvelle tâche !
Bonjour n°5 à partir de la nouvelle tâche !
Bonjour n°6 à partir de la nouvelle tâche !
Bonjour n°7 à partir de la nouvelle tâche !
Bonjour n°8 à partir de la nouvelle tâche !
Bonjour n°9 à partir de la nouvelle tâche !
Bonjour n°1 à partir de la tâche principale !
Bonjour n°2 à partir de la tâche principale !
Bonjour n°3 à partir de la tâche principale !
Bonjour n°4 à partir de la tâche principale !
Des petits détails, comme l’endroit où join est appelé, peuvent déterminer si vos tâches peuvent être exécutées ou non en même temps.
Utiliser les fermetures move avec les tâches
Nous utiliserons souvent le mot-clé move avec des fermetures passées à thread::spawn car la fermeture va alors prendre possession des valeurs de son environnement qu’elle utilise, ce qui transfère la possession des valeurs d’une tâche à une autre. Dans “Capturing References or Moving Ownership” dans le chapitre 13, nous avons présenté move dans le contexte des fermetures. À présent, nous allons plus nous concentrer sur l’interaction entre move et thread::spawn.
Remarquez dans l’encart 16-1 que la fermeture que nous donnons à thread::spawn ne prend pas d’arguments : nous n’utilisons aucune donnée de la tâche principale dans le code de la nouvelle tâche. Pour utiliser des données de la tâche principale dans la nouvelle tâche, la fermeture de la nouvelle tâche doit capturer les valeurs dont elle a besoin. L’encart 16-3 montre une tentative de création d’un vecteur dans la tâche principale et son utilisation dans la nouvelle tâche. Cependant, cela ne fonctionne pas encore, comme vous allez le constater dans un moment.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let manipulateur = thread::spawn(|| {
println!("Voici un vecteur : {v:?}");
});
manipulateur.join().unwrap();
}La fermeture utilise v, donc elle va capturer v et l’intégrer dans son environnement. Comme thread::spawn exécute cette fermeture dans une nouvelle tâche, nous devrions pouvoir accéder à v dans cette nouvelle tâche. Mais lorsque nous compilons cet exemple, nous obtenons l’erreur suivante :
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let manipulateur = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {:?}", v);
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let manipulateur = thread::spawn(|| {
| ________________________^
7 | | println!("Voici un vecteur :{v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let manipulateur = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust déduit comment capturer v, et comme println! n’a besoin que d’une référence à v, la fermeture essaye d’emprunter v. Cependant, il y a un problème : Rust ne peut pas savoir combien de temps la tâche va s’exécuter, donc il ne peut pas savoir si la référence à v sera toujours valide.
L’encart 16-4 propose un scénario qui a plus de chances d’avoir une référence à v qui ne sera plus valide.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let manipulateur = thread::spawn(|| {
println!("Voici un vecteur : {v:?}");
});
drop(v); // oh, non !
manipulateur.join().unwrap();
}v from a main thread that drops vSi Rust nous autorisait à exécuter ce code, il y aurait une possibilité que la nouvelle tâche soit immédiatement placée en arrière-plan sans être exécutée du tout. La nouvelle tâche a une référence à v en son sein, mais la tâche principale libère immédiatement v, en utilisant la fonction drop que nous avons vue au chapitre 15. Ensuite, lorsque la nouvelle tâche commence à s’exécuter, v n’est plus en vigueur, donc une référence à cette dernière est elle aussi invalide !
Pour corriger l’erreur de compilation de l’encart 16-3, nous pouvons appliquer le conseil du message d’erreur :
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let manipulateur = thread::spawn(move || {
| ++++
En ajoutant le mot-clé move avant la fermeture, nous forçons la fermeture à prendre possession des valeurs qu’elle utilise au lieu de laisser Rust déduire qu’il doit emprunter les valeurs. Les modifications à l’encart 16-3 proposées dans l’encart 16-5 devraient se compiler et s’exécuter comme prévu.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let manipulateur = thread::spawn(move || {
println!("Voici un vecteur : {v:?}");
});
manipulateur.join().unwrap();
}move keyword to force a closure to take ownership of the values it usesNous pourrions être tentés de tenter la même chose pour rectifier le code de l’encart 16-4 dans lequel la tâche principale fait appel à drop en utilisant une fermeture move. Cependant, ceci ne fonctionnera pas car ce que l’encart 16-4 essaye de faire n’est pas autorisé pour une raison différente de la précédente. Si nous ajoutions move à la fermeture, nous déplacerions v dans l’environnement de la fermeture, et nous ne pourrions plus appeler drop sur v dans la tâche principale. Nous obtiendrons à la place cette erreur de compilation :
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let manipulateur = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Voici un vecteur : {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh, non !
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let manipulateur = thread::spawn(move || {
8 ~ println!("Voici un vecteur : {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Les règles de possession de Rust nous ont encore sauvé la mise ! Nous obtenions une erreur avec le code de l’encart 16-3 car Rust a été conservateur et a juste emprunté v pour la tâche, ce qui signifie que la tâche principale pouvait théoriquement neutraliser la référence de la tâche créée. En demandant à Rust de déplacer la possession de v à la nouvelle tâche, nous avons garanti à Rust que la tâche principale n’utiliserait plus v. Si nous changeons l’encart 16-4 de la même manière, nous violons les règles de possession lorsque nous essayons d’utiliser v dans la tâche principale. Le mot-clé move remplace le comportement d’emprunt conservateur par défaut de Rust; il ne nous laisse pas enfreindre les règles de possession.
Maintenant que nous avons vu ce que sont les tâches et les méthodes fournies par leur API, découvrons quelques situations dans lesquelles nous pouvons utiliser les tâches.
Utiliser l'envoi de messages pour transférer des données entre les tâches
Utiliser l’envoi de messages pour transférer des données entre les tâches
Une approche de plus en plus populaire pour garantir la sécurité de la concurrence est l’envoi de messages, avec lequel les tâches ou les acteurs communiquent en envoyant aux autres des messages contenant des données. Voici l’idée résumée, tirée d’un slogan provenant de la documentation du langage Go : “Ne communiquez pas en partageant la mémoire ; partagez plutôt la mémoire en communiquant”.
Pour accomplir l’envoi simultané de messages, la bibliothèque standard de Rust fournit une implémentation de canaux. Un canal est un concept de programmation qui permet de transmettre des données d’une tâche à une autre.
Vous pouvez imaginer un canal de programmation comme étant un canal d’eau, comme un ruisseau ou une rivière. Si vous posez quelque chose comme un canard en plastique sur une rivière, il se déplacera vers l’aval jusqu’à la fin de la voie d’eau.
Un canal est divisé en deux parties : un émetteur et un récepteur. La partie de l’émetteur est le lieu en amont où vous déposez les canards en plastique sur la rivière, et la partie du récepteur est celle où les canards en plastique finissent leur voyage. Une partie de votre code appelle des méthodes de l’émetteur en lui passant les données que vous souhaitez envoyer, tandis qu’une autre partie attend que des messages arrivent. Un canal est déclaré fermé lorsque l’une des parties, l’émetteur ou le récepteur, est libérée.
Ici, nous allons concevoir un programme qui a une tâche pour générer des valeurs et les envoyer dans un canal, et une autre tâche qui va recevoir les valeurs et les afficher. Nous allons envoyer de simples valeurs entre les tâches en utilisant un canal pour illustrer cette fonctionnalité. Une fois que vous serez familier avec cette technique, vous pourrez utiliser les canaux pour n’importe quelles tâches qui ont besoin de communiquer entre elles, comme par exemple un système de dialogue en ligne ou un système où de nombreuses tâches font chacune une partie d’un gros calcul et envoient leur résultat à une tâche chargée de les agréger.
Pour commencer, dans l’encart 16-6, nous allons créer un canal mais nous n’allons rien faire avec. Remarquez qu’il ne se compilera pas encore car Rust ne peut pas savoir le type de valeurs que nous souhaitons envoyer dans le canal.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}tx and rxNous créons un nouveau canal en utilisant la fonction mpsc::channel ; mpsc signifie multiple producer, single consumer, c’est-à-dire plusieurs producteurs, un seul consommateur. En bref, la façon dont la bibliothèque standard de Rust a implémenté ces canaux permet d’avoir plusieurs extrémités émettrices qui produisent des valeurs, mais seulement une seule extrémité réceptrice qui consomme ces valeurs. Imaginez plusieurs ruisseaux qui se rejoignent en une seule grosse rivière : tout ce qui est déposé sur les ruisseaux va finir dans une seule rivière à la fin. Nous allons commencer avec un seul producteur pour le moment, mais nous allons ajouter d’autres producteurs lorsque notre exemple fonctionnera.
La fonction mpsc::channel retourne un tuple dont le premier élément est celui qui permet d’envoyer —l’émetteur— et dont le second est celui qui reçoit —le récepteur—. Les abréviations tx et rx sont utilisés traditionnellement dans de nombreux domaines pour signifier respectivement transmetteur (émetteur) et récepteur, nous avons donc nommé nos variables ainsi pour indiquer clairement le rôle de chaque élément. Nous utilisons une instruction let avec un motif qui déstructure les tuples ; nous verrons l’utilisation des motifs dans les instructions let et la déstructuration au chapitre 19. Pour le moment, retenez que l’utilisation d’une instruction let est une façon d’extraire facilement les éléments du tuple retourné par mpsc::channel.
Déplaçons maintenant l’élément de transmission dans une nouvelle tâche et faisons-lui envoyer une chaîne de caractères afin que la nouvelle tâche communique avec la tâche principale, comme dans l’encart 16-7. C’est comme poser un canard en plastique sur l’amont de la rivière ou envoyer un message instantané d’une tâche à une autre.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let valeur = String::from("salut");
tx.send(valeur).unwrap();
});
}tx to a spawned thread and sending "hi"Nous utilisons à nouveau thread::spawn pour créer une nouvelle tâche et ensuite utiliser move pour déplacer tx dans la fermeture afin que la nouvelle tâche possède désormais tx. La nouvelle tâche a besoin de posséder l’émetteur pour être en capacité d’envoyer des messages dans ce canal.
L’émetteur a une méthode send qui prend en argument la valeur que nous souhaitons envoyer. La méthode send retourne un type Result<T, E>, donc si le récepteur a déjà été libéré et qu’il n’y a nulle part où envoyer la valeur, l’opération d’envoi va retourner une erreur. Dans cet exemple, nous faisons appel à unwrap pour paniquer en cas d’erreur. Mais dans un vrai programme, nous devrions gérer ce cas correctement : retournez au chapitre 9 pour revoir les stratégies permettant de gérer correctement les erreurs.
Dans l’encart 16-8, nous allons obtenir la valeur du récepteur dans la tâche principale. C’est comme récupérer le canard en plastique dans l’eau à la fin de la rivière, ou récupérer un message instantané.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let valeur = String::from("salut");
tx.send(valeur).unwrap();
});
let recu = rx.recv().unwrap();
println!("On a reçu : {recu}");
}"hi" in the main thread and printing itLe récepteur a deux modes intéressants : recv et try_recv. Nous avons utilisé recv, un raccourci pour recevoir, qui va bloquer l’exécution de la tâche principale et attendre jusqu’à ce qu’une valeur soit envoyée dans le canal. Une fois qu’une valeur est envoyée, recv va la retourner dans un Result<T, E>. Lorsque l’émetteur se ferme, recv va retourner une erreur pour signaler qu’il n’y aura plus de valeurs qui arriveront.
La méthode try_recv ne bloque pas, mais va plutôt retourner immédiatement un Result<T, E> : une valeur Ok qui contiendra un message s’il y en a un de disponible, et une valeur Err s’il n’y a pas de message cette fois-ci. L’utilisation de try_recv est pratique si cette tâche a d’autres choses à faire pendant qu’elle attend les messages : nous pouvons ainsi écrire une boucle qui appelle régulièrement try_recv, gère le message s’il y en a un, et sinon fait d’autres choses avant de vérifier à nouveau.
Nous avons utilisé recv dans cet exemple pour des raisons de simplicité ; nous n’avons rien d’autre à faire dans la tâche principale que d’attendre les messages, donc bloquer la tâche principale est acceptable.
Lorsque nous exécutons le code de l’encart 16-8, nous allons voir la valeur s’afficher grâce à la tâche principale :
On a reçu : salut
C’est parfait ainsi !
Transfert de possession via les canaux
Les règles de possession jouent un rôle vital dans l’envoi de messages car elles vous aident à écrire du code sûr et concurrent. Réfléchir à la possession avec vos programmes Rust vous offre l’avantage d’éviter des erreurs de développement avec la concurrence. Faisons une expérience pour montrer comment la possession et les canaux fonctionnent ensemble pour éviter les problèmes : nous allons essayer d’utiliser la valeur dans la nouvelle tâche après que nous l’avons envoyée dans le canal. Essayez de compiler le code de l’encart 16-9 pour découvrir pourquoi ce code n’est pas autorisé.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let valeur = String::from("salut");
tx.send(valeur).unwrap();
println!("valeur vaut {valeur}");
});
let recu = rx.recv().unwrap();
println!("On a reçu : {recu}");
}val after we’ve sent it down the channelIci, nous essayons d’afficher valeur après que nous l’avons envoyée dans le canal avec tx.send. Ce serait une mauvaise idée de permettre cela : une fois que la valeur a été envoyée à une autre tâche, cette tâche peut la modifier ou la libérer avant que nous essayions de l’utiliser à nouveau. Il est possible que des modifications faites par l’autre tâche puissent causer des erreurs ou des résultats inattendus à cause de données incohérentes ou manquantes. Toutefois, Rust nous affiche une erreur si nous essayons de compiler le code de l’encart 16-9 :
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `valeur`
--> src/main.rs:10:27
|
8 | let valeur = String::from("salut");
| ------ move occurs because `valeur` has type `String`, which does not implement the `Copy` trait
9 | tx.send(valeur).unwrap();
| ------ value moved here
10 | println!("valeur vaut {valeur}");
| ^^^^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
Notre erreur de concurrence a provoqué une erreur à la compilation. La fonction send prend possession de ses paramètres, et lorsque la valeur est déplacée, le récepteur en prend possession. Cela nous évite d’utiliser à nouveau accidentellement la valeur après l’avoir envoyée ; le système de possession vérifie que tout est en ordre.
Envoyer plusieurs valeurs
Le code de l’encart 16-8 s’est compilé et exécuté, mais il ne nous a pas clairement indiqué que deux tâches séparées communiquaient entre elles via le canal.
Dans l’encart 16-10, nous avons fait quelques modifications qui prouvent que le code de l’encart 16-8 est exécuté avec de la concurrence : la nouvelle tâche va maintenant envoyer plusieurs messages et faire une pause d’une seconde entre chaque message.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let valeurs = vec![
String::from("salut"),
String::from("à partir"),
String::from("de la"),
String::from("nouvelle tâche"),
];
for valeur in valeurs {
tx.send(valeur).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for recu in rx {
println!("On a reçu : {recu}");
}
}Cette fois-ci, la nouvelle tâche a un vecteur de chaînes de caractères que nous souhaitons envoyer à la tâche principale. Nous itérons sur celui-ci, nous envoyons les chaînes une par une en faisant une pause entre chaque envoi en appelant la fonction thread::sleep avec une valeur Duration d’une seconde.
Dans la tâche principale, nous n’appelons plus explicitement la fonction recv : à la place, nous utilisons rx comme un itérateur. Pour chaque valeur reçue, nous l’affichons. Lorsque le canal se fermera, l’itération se terminera.
Lorsque nous exécutons le code de l’encart 16-10, nous devrions voir la sortie suivante, avec une pause d’une seconde entre chaque ligne :
On a reçu : salut
On a reçu : à partir
On a reçu : de la
On a reçu : nouvelle tâche
Comme nous n’avons pas de code qui met en pause ou retarde la boucle for de la tâche principale, nous pouvons dire que la tâche principale est en attente de réception des valeurs de la part de la nouvelle tâche.
Création de plusieurs producteurs
Précédemment, nous avions évoqué que mpsc était un acronyme pour multiple producer, single consumer. Mettons mpsc en œuvre en élargissant le code de l’encart 16-10 pour créer plusieurs tâches qui vont toutes envoyer des valeurs au même récepteur. Nous pouvons faire ceci en clonant l’émetteur, comme dans l’encart 16-11 :
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// -- partie masquée ici --
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let valeurs = vec![
String::from("salut"),
String::from("à partir"),
String::from("de la"),
String::from("nouvelle tâche"),
];
for valeur in valeurs {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let valeurs = vec![
String::from("encore plus"),
String::from("de messages"),
String::from("pour"),
String::from("vous"),
];
for valeur in valeurs {
tx.send(valeur).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for recu in rx {
println!("On a reçu : {recu}");
}
// -- partie masquée ici --
}Cette fois-ci, avant de créer la première nouvelle tâche, nous appelons clone sur l’émetteur. Cela va nous donner un nouvel émetteur que nous pouvons passer à la première nouvelle tâche. Nous passons ensuite l’émetteur original à une seconde nouvelle tâche. Cela va nous donner deux tâches, chacune envoyant des messages différents au récepteur.
Lorsque vous exécuterez ce code, votre sortie devrait ressembler à ceci :
On a reçu : salut
On a reçu : encore plus
On a reçu : à partir
On a reçu : de messages
On a reçu : pour
On a reçu : de la
On a reçu : nouvelle tâche
On a reçu : pour vous
Vous pourrez peut-être constater que les valeurs sont dans un autre ordre chez vous, en fonction de votre système. C’est ce qui rend la concurrence aussi intéressante que difficile. Si vous jouez avec la valeur de thread::sleep en lui donnant différentes valeurs dans différentes tâches, chaque exécution sera encore moins déterministe et créera une sortie différente à chaque fois.
Maintenant que nous avons découvert le fonctionnement des canaux, examinons un autre genre de concurrence.
Le partage d'état en concurrence
Le partage d’état en concurrence
L’envoi de messages est un assez bon moyen de gestion de la concurrence, mais ce n’est pas le seul. Une autre méthode serait, pour plusieurs tâches, d’accéder aux mêmes données partagées. Repensons à cette partie du slogan de la documentation du langage Go : “ne communiquez pas en partageant la mémoire”.
À quoi ressemble la communication par partage de mémoire ? De plus, pourquoi les partisans de l’envoi de messages déconseillent-ils le partage de mémoire ?
De manière générale, les canaux dans les langages de programmation ressemblent à la possession exclusive, car une fois que vous avez transféré une valeur dans un canal, vous ne pouvez plus utiliser cette valeur. Le partage de mémoire en concurrence est comme de la possession multiple : plusieurs tâches peuvent accéder au même endroit de la mémoire en même temps. Comme vous l’avez vu au chapitre 15, dans lequel les pointeurs intelligents la rendent possible, la possession multiple peut ajouter de la complexité car ses différents propriétaires ont besoin d’être gérés. Le système de type de Rust et les règles de possession aident beaucoup à les gérer correctement. Par exemple, découvrons les mutex, une des primitives les plus courantes pour partager la mémoire.
Contrôle d’accès avec les mutex
Mutex est une abréviation pour mutual exclusion, ce qui veut dire qu’un mutex ne permet qu’à une seule tâche d’accéder à une donnée à un instant donné. Pour accéder à la donnée dans un mutex, une tâche doit d’abord signaler qu’elle souhaite y accéder en demandant l’obtention du verrou du mutex. Le verrou est une structure de donnée qui fait partie du mutex et qui assure le suivi de qui a actuellement accès à la donnée. Par conséquent, le mutex est qualifié de gardien de la donnée qu’il renferme via le système de verrou.
Les mutex ont la réputation d’être difficiles à utiliser car vous devez veiller à deux règles :
- Vous devez obtenir le verrou avant d’utiliser la donnée.
- Lorsque vous avez fini avec la donnée que le mutex garde, vous devez déverrouiller la donnée afin que d’autres tâches puissent obtenir le verrou.
Pour faire une métaphore de la vie courante d’un mutex, imaginez une table ronde lors d’une conférence avec un seul microphone. Avant qu’un participant ne puisse parler, il doit demander ou signaler qu’il veut utiliser le micro. Lorsqu’il obtient le micro, il peut parler aussi longtemps qu’il le souhaite et ensuite passer le micro au prochain participant qui a demandé à pouvoir parler. Si un participant oublie de rendre le micro après avoir fini de parler, personne d’autre ne peut parler. Si la gestion du micro partagé se passe mal, la table ronde ne fonctionnera pas comme prévu !
La gestion des mutex peut devenir incroyablement compliquée, c’est pourquoi tant de personnes sont partisanes des canaux. Cependant, grâce au système de type de Rust et aux règles de possession, vous ne pouvez pas vous tromper dans le verrouillage et déverrouillage.
L’API des Mutex<T>
Pour illustrer l’utilisation d’un mutex, commençons par utiliser un mutex dans le contexte d’une seule tâche, comme dans l’encart 16-12.
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
let mut nombre = m.lock().unwrap();
*nombre = 6;
}
println!("m = {m:?}");
}Mutex<T> in a single-threaded context for simplicityComme avec beaucoup de types, nous créons un Mutex<T> en utilisant la fonction associée new. Pour accéder à la donnée dans le mutex, nous utilisons la méthode lock pour obtenir le verrou. Cela va bloquer la tâche courante, donc elle ne s’exécutera plus tant que ce ne sera pas à notre tour d’avoir le verrou.
L’appel à lock échouera si une autre tâche qui avait le verrou a paniqué. Dans ce cas, personne ne pourra obtenir le verrou, donc nous avons choisi d’utiliser unwrap pour que notre tâche panique si nous nous retrouvons dans une telle situation.
Après avoir obtenu le verrou, nous pouvons utiliser la valeur de retour comme une référence mutable vers la donnée, qui s’appellera nombre dans ce cas. Le système de type s’assure que nous obtenons le verrou avant d’utiliser la valeur présente dans m. Le type de m est Mutex<i32>, et pas i32, donc nous devons appeler lock pour pouvoir utiliser la valeur i32. Nous ne pouvons pas l’oublier ; le système de type ne nous laissera pas accéder au i32 à l’intérieur de toute façon.
L’appel à lock retourne un type appelé MutexGuard, intégré dans un LockResult que nous avons géré en faisant appel à unwrap. Le type MutexGuard implémente Deref pour pouvoir pointer sur la donnée interne ; ce type implémente aussi Drop qui libère le verrou automatiquement lorsqu’un MutexGuard sort de la portée, ce qui arrive à la fin de la portée interne. Au final, nous ne risquons pas d’oublier de rendre le verrou et ainsi bloquer l’utilisation du mutex pour les autres tâches car la libération du verrou se produit automatiquement.
Après avoir libéré le verrou, nous pouvons afficher la valeur dans le mutex et constater que nous avons pu changer la valeur interne du i32 à 6.
Accès partagé au Mutex<T>
Essayons maintenant de partager une valeur entre plusieurs tâches en utilisant Mutex<T>. Nous allons faire fonctionner 10 tâches et faire en sorte que chacune augmente la valeur du compteur de 1, donc le compteur va passer de 0 à 10. L’exemple dans l’encart 16-13 débouchera sur une erreur de compilation, et nous allons utiliser cette erreur pour en apprendre plus sur l’utilisation de Mutex<T> et sur la façon dont Rust nous aide à l’utiliser correctement.
use std::sync::Mutex;
use std::thread;
fn main() {
let compteur = Mutex::new(0);
let mut manipulateurs = vec![];
for _ in 0..10 {
let manipulateur = thread::spawn(move || {
let mut nombre = compteur.lock().unwrap();
*nombre += 1;
});
manipulateurs.push(manipulateur);
}
for manipulateur in manipulateurs {
manipulateur.join().unwrap();
}
println!("Résultat : {}", *compteur.lock().unwrap());
}Mutex<T>Nous avons créé une variable compteur pour stocker un i32 dans un Mutex<T>, comme nous l’avons fait dans l’encart 16-12. Ensuite, nous créons 10 tâches en itérant sur un intervalle de nombres. Nous utilisons thread::spawn et nous donnons à toutes les tâches la même fermeture, qui déplace le compteur dans la tâche, obtient le verrou sur le Mutex<T> en faisant appel à la méthode lock et ajoute ensuite 1 à la valeur présente dans le mutex. Lorsqu’une tâche finit d’exécuter sa fermeture, nombre va sortir de la portée et va libérer le verrou afin qu’une autre tâche puisse l’obtenir.
Dans la tâche principale, nous collectons tous les manipulateurs. Ensuite, comme nous l’avions fait dans l’encart 16-2, nous faisons appel à join sur chaque manipulateur pour s’assurer que toutes les tâches ont fini. Une fois que c’est le cas, la tâche principale va obtenir le verrou et afficher le résultat de ce programme.
Nous avions annoncé que cet exemple ne se compilerait pas. Découvrons maintenant pourquoi !
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: use of moved value: `compteur`
--> src/main.rs:21:29
|
5 | let compteur = Mutex::new(0);
| -------- move occurs because `compteur` has type `Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let manipulateur = thread::spawn(move || {
| ^^^^^^^ value moved into closure here, in previous iteration of loop
...
21 | println!("Résultat : {}", *compteur.lock().unwrap());
| ^^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = compteur.lock();
9 ~ for _ in 0..10 {
10 | let manipulateur = thread::spawn(move || {
11 ~ let mut nombre = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Le message d’erreur signale que la valeur compteur a été déplacée dans l’itération précédente de la boucle. Rust nous explique qu’il ne peut pas déplacer la possession du verrou de compteur dans plusieurs tâches. Corrigeons cette erreur de compilation avec la méthode permettant d’avoir plusieurs propriétaires que nous avons vue au chapitre 15.
Plusieurs propriétaires avec plusieurs tâches
Dans le chapitre 15, nous avons assigné plusieurs propriétaires à une valeur en utilisant le pointeur intelligent Rc<T> pour créer un compteur de référence. Faisons la même chose ici et voyons ce qui se passe. Nous allons intégrer le Mutex<T> dans un Rc<T> dans l’encart 16-14 et cloner le Rc<T> avant de déplacer sa possession à la tâche.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let compteur = Rc::new(Mutex::new(0));
let mut manipulateurs = vec![];
for _ in 0..10 {
let compteur = Rc::clone(&compteur);
let manipulateur = thread::spawn(move || {
let mut nombre = compteur.lock().unwrap();
*nombre += 1;
});
manipulateurs.push(manipulateur);
}
for manipulateur in manipulateurs {
manipulateur.join().unwrap();
}
println!("Résultat : {}", *compteur.lock().unwrap());
}Rc<T> to allow multiple threads to own the Mutex<T>À nouveau, nous compilons et nous obtenons … une erreur différente ! Le compilateur nous en apprend beaucoup :
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let manipulateur = thread::spawn(move || {
| ------------- ^------
| | |
| ____________________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut nombre = compteur.lock().unwrap();
13 | |
14 | | *nombre += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let manipulateur = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Ouah, ce message d’erreur est très verbeux ! Voici la partie la plus importante sur laquelle se concentrer : `Rc<Mutex<i32>>` cannot be sent between threads safely. Le compilateur nous indique aussi pour quelle raison : the trait `Send` is not implemented for `Rc<Mutex<i32>>` . Nous allons voir Send dans la prochaine section : c’est l’un des traits qui garantissent que le type que nous utilisons avec les tâches est prévu pour être utilisé dans des situations de concurrence.
Malheureusement, l’utilisation de Rc<T> n’est pas sûre lorsqu’il est partagé entre plusieurs tâches. Lorsque Rc<T> gère le compteur de références, il incrémente le compteur autant de fois que nous avons fait appel à clone et décrémente le compteur à chaque fois qu’un clone est libéré. Mais il n’utilise pas de primitives de concurrence pour s’assurer que les changements faits au compteur ne peuvent pas être interrompus par une autre tâche. Cela pourrait provoquer des bogues subtils induisant une mauvaise gestion du compteur, ce qui pourrait provoquer des fuites de mémoire ou faire qu’une valeur soit libérée avant que nous ayions fini de l’utiliser. Nous avons besoin d’un type exactement comme Rc<T> mais qui procède aux changements du compteur de références de manière sûre en situation de concurrence.
Compteur de référence atomique avec Arc<T>
Heureusement, Arc<T> est un type comme Rc<T> qui est sûr en situation de concurrence. Le A signifie atomique, ce qui signifie que c’est un type compteur de références atomique. L’atome est une sorte de primitive concurrente que nous n’allons pas aborder en détail ici : rendez-vous dans la documentation de la bibliothèque standard sur std::sync::atomic pour en savoir plus. Pour le moment, vous avez juste besoin de retenir que les atomes fonctionnent comme les types primitifs mais qui sont sûrs à partager entre plusieurs tâches.
Vous vous demandez pourquoi tous les types primitifs ne sont pas atomiques et pourquoi les types de la bibliothèque standard ne sont pas implémentés en utilisant Arc<T> par défaut. La raison à cela est que la sécurité entre les tâches a un coût sur les performances que vous n’êtes prêt à payer que lorsque vous en avez besoin. Si vous procédez à des opérations sur des valeurs uniquement dans une seule tâche, votre code va s’exécuter plus vite car il n’a pas besoin d’appliquer les garanties fournies par les types atomiques.
Retournons à notre exemple : Arc<T> et Rc<T> ont la même API, donc corrigeons notre programme en changeant la ligne use, l’appel à new et l’appel à clone. Le code dans l’encart 16-15 va finalement se compiler et s’exécuter.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let compteur = Arc::new(Mutex::new(0));
let mut manipulateurs = vec![];
for _ in 0..10 {
let compteur = Arc::clone(&compteur);
let manipulateur = thread::spawn(move || {
let mut nombre = compteur.lock().unwrap();
*nombre += 1;
});
manipulateurs.push(manipulateur);
}
for manipulateur in manipulateurs {
manipulateur.join().unwrap();
}
println!("Résultat : {}", *compteur.lock().unwrap());
}Arc<T> to wrap the Mutex<T> to be able to share ownership across multiple threadsCe code va afficher ceci :
Result: 10
Nous y sommes arrivés ! Nous avons compté de 0 à 10, ce qui ne semble pas très impressionnant, mais cela nous a appris beaucoup sur Mutex<T> et la sûreté des tâches. Vous pouvez aussi utiliser cette structure de programme pour procéder à des opérations plus complexes que simplement incrémenter un compteur. En utilisant cette stratégie, vous pouvez diviser un calcul en différentes parties, répartir ces parties sur des tâches, et ensuite utiliser un Mutex<T> pour faire en sorte que chaque tâche mette à jour le résultat final avec sa propre partie.
Notez que si vous faites de simples opérations numériques, il existe des types plus simples que les types Mutex<T> fournis par le module std::sync::atomic de la bibliothèque standard. Ces types offrent un accès atomique, concurrent et sécurisé aux types primitifs. Nous avons choisi d’utiliser Mutex<T> avec un type primitif pour cet exemple afin de pouvoir nous concentrer sur le fonctionnement de Mutex<T>.
Comparaison de RefCell<T>/Rc<T> et Mutex<T>/Arc<T>
Vous avez peut-être constaté que compteur est immuable mais que nous pouvons obtenir une référence mutable vers la valeur qu’il renferme ; cela signifie que Mutex<T> a une mutabilité interne, comme le fait la famille des Cell. De la même manière que nous avons utilisé RefCell<T> au chapitre 15 pour nous permettre de changer le contenu dans un Rc<T>, nous utilisons Mutex<T> pour modifier le contenu d’un Arc<T>.
Un autre détail à souligner est que Rust ne peut pas vous protéger de tous les genres d’erreurs de logique lorsque vous utilisez Mutex<T>. Souvenez-vous que dans le chapitre 15, l’utilisation de Rc<T> comportait le risque de créer des boucles de références, dans lesquelles deux valeurs Rc<T> se référeraient l’une à l’autre, ce qui provoquait des fuites de mémoire. De la même manière, l’utilisation de Mutex<T> risque de créer des interblocages. Cela se produit lorsqu’une opération nécessite de verrouiller deux ressources et que deux tâches ont chacune un des deux verrous, ce qui fait qu’elles s’attendent mutuellement pour toujours. Si vous êtes intéressés par les interblocages, essayez de créer un programme Rust qui a un interblocage ; recherchez ensuite des stratégies pour remédier aux interblocages dans n’importe quel langage et implémentez-les en Rust. La documentation de l’API de la bibliothèque standard pour Mutex<T> et MutexGuard offre des informations précieuses à ce sujet.
Nous allons terminer ce chapitre en parlant des traits Send et Sync et voir comment nous pouvons les utiliser sur des types personnalisés.
Étendre la concurrence avec les traits Sync et Send
Étendre la concurrence avec les traits Sync et Send
Curieusement, la plupart des fonctionnalités de concurrence que nous avons vues précédemment dans ce chapitre font partie de la bibliothèque standard, pas du langage. Vos options pour gérer la concurrence ne sont pas limitées à celles du langage ou de la bibliothèque standard ; vous pouvez aussi écrire vos propres fonctionnalités de concurrence ou utiliser celles qui ont été écrites par d’autres.
Cependant, parmi les concepts clés de la concurrence qui sont intégrés dans le langage plutôt que dans la bibliothèque standard, on trouve les traits Send et Sync de std::marker.
Transfert de possession entre tâches
Le trait Send indique que la possession des valeurs du type qui implémente Send peut être transférée entre plusieurs tâches. Presque tous les types de Rust implémentent Send, mais il subsiste quelques exceptions, comme Rc<T> : il ne peut pas implémenter Send car si vous clonez une valeur Rc<T> et que vous essayez de transférer la possession de ce clone à une autre tâche, les deux tâches peuvent modifier le compteur de référence en même temps. Pour cette raison, Rc<T> n’est prévu que pour une utilisation dans des situations qui ne nécessitent qu’une seule tâche et pour lesquelles vous n’avez pas besoin de payer le surcoût sur la performance induit par la sureté de fonctionnement multitâches.
Toutefois, le système de type et de traits liés de Rust garantit que vous ne pourrez jamais envoyer accidentellement en toute insécurité une valeur Rc<T> entre des tâches. Lorsque nous avons essayé de faire cela dans l’encart 16-14, nous avons obtenu l’erreur the trait `Send` is not implemented for `Rc<Mutex<i32>>` . Lorsque nous l’avons changé pour un Arc<T>, qui implémente Send, le code s’est compilé.
Tous les types composés entièrement d’autres types qui implémentent Send sont automatiquement marqués comme Send eux aussi. Presque tous les types primitifs sont marqués comme Send, à part les pointeurs bruts, ce que nous verrons au chapitre 20.
Permettre l’accès à plusieurs tâches avec Sync
Accès depuis plusieurs tâches
Le trait Sync indique qu’il est sûr d’avoir une référence dans plusieurs tâches vers le type qui implémente Sync. Autrement dit, n’importe quel type T implémente Sync si &T (une référence immuable vers T) implémente Send, ce qui signifie que la référence peut être envoyée en toute sécurité à une autre tâche. De la même manière que Send, les types primitifs implémentent tous Sync, et les types composés entièrement d’autres types qui implémentent Sync implémentent eux-mêmes Sync.
Le pointeur intelligent Rc<T> n’implémente pas non plus Sync pour les mêmes raisons qu’il n’implémente pas Send. Le type RefCell<T> (que nous avons vu au chapitre 15) et la famille liée aux types Cell<T> n’implémentent pas Sync. L’implémentation du vérificateur d’emprunt que RefCell<T> met en oeuvre à l’exécution n’est pas sûre pour le multitâches. Le pointeur intelligent Mutex<T> implémente Sync et peut être utilisé pour partager l’accès entre plusieurs tâches, comme vous l’avez vu dans “Accès partagé au Mutex<T>”.
Implémenter manuellement Send et Sync n’est pas sûr
Comme les types qui sont entièrement constitués de types implémentant les traits Send et Sync implémentent automatiquement Send et Sync, nous n’avons pas à implémenter manuellement ces traits. Comme ce sont des traits de marquage, ils n’ont même pas de méthodes à implémenter. Ils sont uniquement utiles pour appliquer les règles de concurrence.
L’implémentation manuelle de ces traits implique de faire du code Rust non sécurisé. Nous allons voir le code Rust non sécurisé dans le chapitre 20 ; pour l’instant l’information à retenir est que construire de nouveaux types pour la concurrence constitués d’éléments qui n’implémentent pas Send et Sync nécessite une réflexion approfondie pour respecter les garanties de sécurité. “The Rustonomicon” contient plus d’informations à propos de ces garanties et de la façon de les faire appliquer.
Résumé
Ce n’est pas la dernière fois que vous allez rencontrer de la concurrence dans ce livre : le prochain chapitre est consacré à la programmation asynchrone, et le projet du chapitre 21 va utiliser ces concepts dans une situation plus réaliste que les petits exemples que nous avons utilisés ici.
Nous l’avons dit précédemment, comme les outils pour gérer la concurrence de Rust ne sont pas directement intégrés dans le langage, de nombreuses solutions pour de la concurrence sont implémentées dans des crates. Elles évoluent plus rapidement que la bibliothèque standard, donc assurez-vous de rechercher en ligne des crates modernes et à la pointe de la technologie à utiliser dans des situations multitâches.
La bibliothèque standard de Rust fournit les canaux pour l’envoi de messages et les types de pointeurs intelligents, comme Mutex<T> et Arc<T>, qui sont sûrs à utiliser en situation de concurrence. Le système de type et le vérificateur d’emprunt sont là pour s’assurer que le code utilisé dans ces solutions ne vont pas conduire à des situations de concurrence ou utiliser des références qui ne sont plus en vigueur. Une fois que votre code se compile, vous pouvez être assuré qu’il fonctionnera bien sur plusieurs tâches sans avoir les genres de bogues difficiles à traquer qui sont monnaie courante dans les autres langages. Le développement en concurrence est un domaine qui ne devrait plus faire peur : lancez-vous et utilisez la concurrence dans vos programmes sans crainte !
Notions fondamentales de programmation asynchrone: Async, Await, Futures et Streams
Many operations we ask the computer to do can take a while to finish. It would be nice if we could do something else while we’re waiting for those long-running processes to complete. Modern computers offer two techniques for working on more than one operation at a time: parallelism and concurrency. Our programs’ logic, however, is written in a mostly linear fashion. We’d like to be able to specify the operations a program should perform and points at which a function could pause and some other part of the program could run instead, without needing to specify up front exactly the order and manner in which each bit of code should run. Asynchronous programming is an abstraction that lets us express our code in terms of potential pausing points and eventual results that takes care of the details of coordination for us.
This chapter builds on Chapter 16’s use of threads for parallelism and concurrency by introducing an alternative approach to writing code: Rust’s futures, streams, and the async and await syntax that let us express how operations could be asynchronous, and the third-party crates that implement asynchronous runtimes: code that manages and coordinates the execution of asynchronous operations.
Let’s consider an example. Say you’re exporting a video you’ve created of a family celebration, an operation that could take anywhere from minutes to hours. The video export will use as much CPU and GPU power as it can. If you had only one CPU core and your operating system didn’t pause that export until it completed—that is, if it executed the export synchronously—you couldn’t do anything else on your computer while that task was running. That would be a pretty frustrating experience. Fortunately, your computer’s operating system can, and does, invisibly interrupt the export often enough to let you get other work done simultaneously.
Now say you’re downloading a video shared by someone else, which can also take a while but does not take up as much CPU time. In this case, the CPU has to wait for data to arrive from the network. While you can start reading the data once it starts to arrive, it might take some time for all of it to show up. Even once the data is all present, if the video is quite large, it could take at least a second or two to load it all. That might not sound like much, but it’s a very long time for a modern processor, which can perform billions of operations every second. Again, your operating system will invisibly interrupt your program to allow the CPU to perform other work while waiting for the network call to finish.
The video export is an example of a CPU-bound or compute-bound operation. It’s limited by the computer’s potential data processing speed within the CPU or GPU, and how much of that speed it can dedicate to the operation. The video download is an example of an I/O-bound operation, because it’s limited by the speed of the computer’s input and output; it can only go as fast as the data can be sent across the network.
In both of these examples, the operating system’s invisible interrupts provide a form of concurrency. That concurrency happens only at the level of the entire program, though: the operating system interrupts one program to let other programs get work done. In many cases, because we understand our programs at a much more granular level than the operating system does, we can spot opportunities for concurrency that the operating system can’t see.
For example, if we’re building a tool to manage file downloads, we should be able to write our program so that starting one download won’t lock up the UI, and users should be able to start multiple downloads at the same time. Many operating system APIs for interacting with the network are blocking, though; that is, they block the program’s progress until the data they’re processing is completely ready.
Note: This is how most function calls work, if you think about it. However, the term blocking is usually reserved for function calls that interact with files, the network, or other resources on the computer, because those are the cases where an individual program would benefit from the operation being non-blocking.
We could avoid blocking our main thread by spawning a dedicated thread to download each file. However, the overhead of the system resources used by those threads would eventually become a problem. It would be preferable if the call didn’t block in the first place, and instead we could define a number of tasks that we’d like our program to complete and allow the runtime to choose the best order and manner in which to run them.
That is exactly what Rust’s async (short for asynchronous) abstraction gives us. In this chapter, you’ll learn all about async as we cover the following topics:
- How to use Rust’s
asyncandawaitsyntax and execute asynchronous functions with a runtime - How to use the async model to solve some of the same challenges we looked at in Chapter 16
- How multithreading and async provide complementary solutions that you can combine in many cases
Before we see how async works in practice, though, we need to take a short detour to discuss the differences between parallelism and concurrency.
Parallelism and Concurrency
We’ve treated parallelism and concurrency as mostly interchangeable so far. Now we need to distinguish between them more precisely, because the differences will show up as we start working.
Consider the different ways a team could split up work on a software project. You could assign a single member multiple tasks, assign each member one task, or use a mix of the two approaches.
When an individual works on several different tasks before any of them is complete, this is concurrency. One way to implement concurrency is similar to having two different projects checked out on your computer, and when you get bored or stuck on one project, you switch to the other. You’re just one person, so you can’t make progress on both tasks at the exact same time, but you can multitask, making progress on one at a time by switching between them (see Figure 17-1).

When the team splits up a group of tasks by having each member take one task and work on it alone, this is parallelism. Each person on the team can make progress at the exact same time (see Figure 17-2).

In both of these workflows, you might have to coordinate between different tasks. Maybe you thought the task assigned to one person was totally independent from everyone else’s work, but it actually requires another person on the team to finish their task first. Some of the work could be done in parallel, but some of it was actually serial: it could only happen in a series, one task after the other, as in Figure 17-3.

Likewise, you might realize that one of your own tasks depends on another of your tasks. Now your concurrent work has also become serial.
Parallelism and concurrency can intersect with each other, too. If you learn that a colleague is stuck until you finish one of your tasks, you’ll probably focus all your efforts on that task to “unblock” your colleague. You and your coworker are no longer able to work in parallel, and you’re also no longer able to work concurrently on your own tasks.
The same basic dynamics come into play with software and hardware. On a machine with a single CPU core, the CPU can perform only one operation at a time, but it can still work concurrently. Using tools such as threads, processes, and async, the computer can pause one activity and switch to others before eventually cycling back to that first activity again. On a machine with multiple CPU cores, it can also do work in parallel. One core can be performing one task while another core performs a completely unrelated one, and those operations actually happen at the same time.
Running async code in Rust usually happens concurrently. Depending on the hardware, the operating system, and the async runtime we are using (more on async runtimes shortly), that concurrency may also use parallelism under the hood.
Now, let’s dive into how async programming in Rust actually works.
Futures et la syntaxe de Async
Futures et la syntaxe de Async
The key elements of asynchronous programming in Rust are futures and Rust’s async and await keywords.
A future is a value that may not be ready now but will become ready at some point in the future. (This same concept shows up in many languages, sometimes under other names such as task or promise.) Rust provides a Future trait as a building block so that different async operations can be implemented with different data structures but with a common interface. In Rust, futures are types that implement the Future trait. Each future holds its own information about the progress that has been made and what “ready” means.
You can apply the async keyword to blocks and functions to specify that they can be interrupted and resumed. Within an async block or async function, you can use the await keyword to await a future (that is, wait for it to become ready). Any point where you await a future within an async block or function is a potential spot for that block or function to pause and resume. The process of checking with a future to see if its value is available yet is called polling.
Some other languages, such as C# and JavaScript, also use async and await keywords for async programming. If you’re familiar with those languages, you may notice some significant differences in how Rust handles the syntax. That’s for good reason, as we’ll see!
When writing async Rust, we use the async and await keywords most of the time. Rust compiles them into equivalent code using the Future trait, much as it compiles for loops into equivalent code using the Iterator trait. Because Rust provides the Future trait, though, you can also implement it for your own data types when you need to. Many of the functions we’ll see throughout this chapter return types with their own implementations of Future. We’ll return to the definition of the trait at the end of the chapter and dig into more of how it works, but this is enough detail to keep us moving forward.
This may all feel a bit abstract, so let’s write our first async program: a little web scraper. We’ll pass in two URLs from the command line, fetch both of them concurrently, and return the result of whichever one finishes first. This example will have a fair bit of new syntax, but don’t worry—we’ll explain everything you need to know as we go.
Our First Async Program
To keep the focus of this chapter on learning async rather than juggling parts of the ecosystem, we’ve created the trpl crate (trpl is short for “The Rust Programming Language”). It re-exports all the types, traits, and functions you’ll need, primarily from the futures and tokio crates. The futures crate is an official home for Rust experimentation for async code, and it’s actually where the Future trait was originally designed. Tokio is the most widely used async runtime in Rust today, especially for web applications. There are other great runtimes out there, and they may be more suitable for your purposes. We use the tokio crate under the hood for trpl because it’s well tested and widely used.
In some cases, trpl also renames or wraps the original APIs to keep you focused on the details relevant to this chapter. If you want to understand what the crate does, we encourage you to check out its source code. You’ll be able to see what crate each re-export comes from, and we’ve left extensive comments explaining what the crate does.
Create a new binary project named hello-async and add the trpl crate as a dependency:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Now we can use the various pieces provided by trpl to write our first async program. We’ll build a little command line tool that fetches two web pages, pulls the <title> element from each, and prints out the title of whichever page finishes that whole process first.
Defining the page_title Function
Let’s start by writing a function that takes one page URL as a parameter, makes a request to it, and returns the text of the <title> element (see Listing 17-1).
extern crate trpl; // required for mdbook test
fn main() {
// TODO: we'll add this next!
}
use trpl::Html;
async fn page_title(url: &str) -> Option<String> {
let response = trpl::get(url).await;
let response_text = response.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}First, we define a function named page_title and mark it with the async keyword. Then we use the trpl::get function to fetch whatever URL is passed in and add the await keyword to await the response. To get the text of the response, we call its text method and once again await it with the await keyword. Both of these steps are asynchronous. For the get function, we have to wait for the server to send back the first part of its response, which will include HTTP headers, cookies, and so on and can be delivered separately from the response body. Especially if the body is very large, it can take some time for it all to arrive. Because we have to wait for the entirety of the response to arrive, the text method is also async.
We have to explicitly await both of these futures, because futures in Rust are lazy: they don’t do anything until you ask them to with the await keyword. (In fact, Rust will show a compiler warning if you don’t use a future.) This might remind you of the discussion of iterators in the “Processing a Series of Items with Iterators” section in Chapter 13. Iterators do nothing unless you call their next method—whether directly or by using for loops or methods such as map that use next under the hood. Likewise, futures do nothing unless you explicitly ask them to. This laziness allows Rust to avoid running async code until it’s actually needed.
Note: This is different from the behavior we saw when using thread::spawn in the “Creating a New Thread with spawn” section in Chapter 16, where the closure we passed to another thread started running immediately. It’s also different from how many other languages approach async. But it’s important for Rust to be able to provide its performance guarantees, just as it is with iterators.
Once we have response_text, we can parse it into an instance of the Html type using Html::parse. Instead of a raw string, we now have a data type we can use to work with the HTML as a richer data structure. In particular, we can use the select_first method to find the first instance of a given CSS selector. By passing the string "title", we’ll get the first <title> element in the document, if there is one. Because there may not be any matching element, select_first returns an Option<ElementRef>. Finally, we use the Option::map method, which lets us work with the item in the Option if it’s present, and do nothing if it isn’t. (We could also use a match expression here, but map is more idiomatic.) In the body of the function we supply to map, we call inner_html on the title to get its content, which is a String. When all is said and done, we have an Option<String>.
Notice that Rust’s await keyword goes after the expression you’re awaiting, not before it. That is, it’s a postfix keyword. This may differ from what you’re used to if you’ve used async in other languages, but in Rust it makes chains of methods much nicer to work with. As a result, we could change the body of page_title to chain the trpl::get and text function calls together with await between them, as shown in Listing 17-2.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
// TODO: we'll add this next!
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}await keywordWith that, we have successfully written our first async function! Before we add some code in main to call it, let’s talk a little more about what we’ve written and what it means.
When Rust sees a block marked with the async keyword, it compiles it into a unique, anonymous data type that implements the Future trait. When Rust sees a function marked with async, it compiles it into a non-async function whose body is an async block. An async function’s return type is the type of the anonymous data type the compiler creates for that async block.
Thus, writing async fn is equivalent to writing a function that returns a future of the return type. To the compiler, a function definition such as the async fn page_title in Listing 17-1 is roughly equivalent to a non-async function defined like this:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
use std::future::Future;
use trpl::Html;
fn page_title(url: &str) -> impl Future<Output = Option<String>> {
async move {
let text = trpl::get(url).await.text().await;
Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html())
}
}
}Let’s walk through each part of the transformed version:
- It uses the
impl Traitsyntax we discussed back in Chapter 10 in the “Traits as Parameters” section. - The returned value implements the
Futuretrait with an associated type ofOutput. Notice that theOutputtype isOption<String>, which is the same as the original return type from theasync fnversion ofpage_title. - All of the code called in the body of the original function is wrapped in an
async moveblock. Remember that blocks are expressions. This whole block is the expression returned from the function. - This async block produces a value with the type
Option<String>, as just described. That value matches theOutputtype in the return type. This is just like other blocks you have seen. - The new function body is an
async moveblock because of how it uses theurlparameter. (We’ll talk much more aboutasyncversusasync movelater in the chapter.)
Now we can call page_title in main.
Executing an Async Function with a Runtime
To start, we’ll get the title for a single page, shown in Listing 17-3. Unfortunately, this code doesn’t compile yet.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}page_title function from main with a user-supplied argumentWe follow the same pattern we used to get command line arguments in the “Accepting Command Line Arguments” section in Chapter 12. Then we pass the URL argument to page_title and await the result. Because the value produced by the future is an Option<String>, we use a match expression to print different messages to account for whether the page had a <title>.
The only place we can use the await keyword is in async functions or blocks, and Rust won’t let us mark the special main function as async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
The reason main can’t be marked async is that async code needs a runtime: a Rust crate that manages the details of executing asynchronous code. A program’s main function can initialize a runtime, but it’s not a runtime itself. (We’ll see more about why this is the case in a bit.) Every Rust program that executes async code has at least one place where it sets up a runtime that executes the futures.
Most languages that support async bundle a runtime, but Rust does not. Instead, there are many different async runtimes available, each of which makes different tradeoffs suitable to the use case it targets. For example, a high-throughput web server with many CPU cores and a large amount of RAM has very different needs than a microcontroller with a single core, a small amount of RAM, and no heap allocation ability. The crates that provide those runtimes also often supply async versions of common functionality such as file or network I/O.
Here, and throughout the rest of this chapter, we’ll use the block_on function from the trpl crate, which takes a future as an argument and blocks the current thread until this future runs to completion. Behind the scenes, calling block_on sets up a runtime using the tokio crate that’s used to run the future passed in (the trpl crate’s block_on behavior is similar to other runtime crates’ block_on functions). Once the future completes, block_on returns whatever value the future produced.
We could pass the future returned by page_title directly to block_on and, once it completed, we could match on the resulting Option<String> as we tried to do in Listing 17-3. However, for most of the examples in the chapter (and most async code in the real world), we’ll be doing more than just one async function call, so instead we’ll pass an async block and explicitly await the result of the page_title call, as in Listing 17-4.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}trpl::block_onWhen we run this code, we get the behavior we expected initially:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
Phew—we finally have some working async code! But before we add the code to race two sites against each other, let’s briefly turn our attention back to how futures work.
Each await point—that is, every place where the code uses the await keyword—represents a place where control is handed back to the runtime. To make that work, Rust needs to keep track of the state involved in the async block so that the runtime could kick off some other work and then come back when it’s ready to try advancing the first one again. This is an invisible state machine, as if you’d written an enum like this to save the current state at each await point:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
enum PageTitleFuture<'a> {
Initial { url: &'a str },
GetAwaitPoint { url: &'a str },
TextAwaitPoint { response: trpl::Response },
}
}Writing the code to transition between each state by hand would be tedious and error-prone, however, especially when you need to add more functionality and more states to the code later. Fortunately, the Rust compiler creates and manages the state machine data structures for async code automatically. The normal borrowing and ownership rules around data structures all still apply, and happily, the compiler also handles checking those for us and provides useful error messages. We’ll work through a few of those later in the chapter.
Ultimately, something has to execute this state machine, and that something is a runtime. (This is why you may come across mentions of executors when looking into runtimes: an executor is the part of a runtime responsible for executing the async code.)
Now you can see why the compiler stopped us from making main itself an async function back in Listing 17-3. If main were an async function, something else would need to manage the state machine for whatever future main returned, but main is the starting point for the program! Instead, we called the trpl::block_on function in main to set up a runtime and run the future returned by the async block until it’s done.
Note: Some runtimes provide macros so you can write an async main function. Those macros rewrite async fn main() { ... } to be a normal fn main, which does the same thing we did by hand in Listing 17-4: call a function that runs a future to completion the way trpl::block_on does.
Now let’s put these pieces together and see how we can write concurrent code.
Racing Two URLs Against Each Other Concurrently
In Listing 17-5, we call page_title with two different URLs passed in from the command line and race them by selecting whichever future finishes first.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let response_text = trpl::get(url).await.text().await;
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}page_title for two URLs to see which returns firstWe begin by calling page_title for each of the user-supplied URLs. We save the resulting futures as title_fut_1 and title_fut_2. Remember, these don’t do anything yet, because futures are lazy and we haven’t yet awaited them. Then we pass the futures to trpl::select, which returns a value to indicate which of the futures passed to it finishes first.
Note: Under the hood, trpl::select is built on a more general select function defined in the futures crate. The futures crate’s select function can do a lot of things that the trpl::select function can’t, but it also has some additional complexity that we can skip over for now.
Either future can legitimately “win,” so it doesn’t make sense to return a Result. Instead, trpl::select returns a type we haven’t seen before, trpl::Either. The Either type is somewhat similar to a Result in that it has two cases. Unlike Result, though, there is no notion of success or failure baked into Either. Instead, it uses Left and Right to indicate “one or the other”:
#![allow(unused)]
fn main() {
enum Either<A, B> {
Left(A),
Right(B),
}
}The select function returns Left with that future’s output if the first argument wins, and Right with the second future argument’s output if that one wins. This matches the order the arguments appear in when calling the function: the first argument is to the left of the second argument.
We also update page_title to return the same URL passed in. That way, if the page that returns first does not have a <title> we can resolve, we can still print a meaningful message. With that information available, we wrap up by updating our println! output to indicate both which URL finished first and what, if any, the <title> is for the web page at that URL.
You have built a small working web scraper now! Pick a couple URLs and run the command line tool. You may discover that some sites are consistently faster than others, while in other cases the faster site varies from run to run. More importantly, you’ve learned the basics of working with futures, so now we can dig deeper into what we can do with async.
Mise en œuvre de la concurrence avec Async
Mise en œuvre de la concurrence avec Async
In this section, we’ll apply async to some of the same concurrency challenges we tackled with threads in Chapter 16. Because we already talked about a lot of the key ideas there, in this section we’ll focus on what’s different between threads and futures.
In many cases, the APIs for working with concurrency using async are very similar to those for using threads. In other cases, they end up being quite different. Even when the APIs look similar between threads and async, they often have different behavior—and they nearly always have different performance characteristics.
Creating a New Task with spawn_task
The first operation we tackled in the “Creating a New Thread with spawn” section in Chapter 16 was counting up on two separate threads. Let’s do the same using async. The trpl crate supplies a spawn_task function that looks very similar to the thread::spawn API, and a sleep function that is an async version of the thread::sleep API. We can use these together to implement the counting example, as shown in Listing 17-6.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
}As our starting point, we set up our main function with trpl::block_on so that our top-level function can be async.
Note: From this point forward in the chapter, every example will include this exact same wrapping code with trpl::block_on in main, so we’ll often skip it just as we do with main. Remember to include it in your code!
Then we write two loops within that block, each containing a trpl::sleep call, which waits for half a second (500 milliseconds) before sending the next message. We put one loop in the body of a trpl::spawn_task and the other in a top-level for loop. We also add an await after the sleep calls.
This code behaves similarly to the thread-based implementation—including the fact that you may see the messages appear in a different order in your own terminal when you run it:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
This version stops as soon as the for loop in the body of the main async block finishes, because the task spawned by spawn_task is shut down when the main function ends. If you want it to run all the way to the task’s completion, you will need to use a join handle to wait for the first task to complete. With threads, we used the join method to “block” until the thread was done running. In Listing 17-7, we can use await to do the same thing, because the task handle itself is a future. Its Output type is a Result, so we also unwrap it after awaiting it.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let handle = trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
handle.await.unwrap();
});
}await with a join handle to run a task to completionThis updated version runs until both loops finish:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
So far, it looks like async and threads give us similar outcomes, just with different syntax: using await instead of calling join on the join handle, and awaiting the sleep calls.
The bigger difference is that we didn’t need to spawn another operating system thread to do this. In fact, we don’t even need to spawn a task here. Because async blocks compile to anonymous futures, we can put each loop in an async block and have the runtime run them both to completion using the trpl::join function.
In the “Waiting for All Threads to Finish” section in Chapter 16, we showed how to use the join method on the JoinHandle type returned when you call std::thread::spawn. The trpl::join function is similar, but for futures. When you give it two futures, it produces a single new future whose output is a tuple containing the output of each future you passed in once they both complete. Thus, in Listing 17-8, we use trpl::join to wait for both fut1 and fut2 to finish. We do not await fut1 and fut2 but instead the new future produced by trpl::join. We ignore the output, because it’s just a tuple containing two unit values.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let fut1 = async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
trpl::join(fut1, fut2).await;
});
}trpl::join to await two anonymous futuresWhen we run this, we see both futures run to completion:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Now, you’ll see the exact same order every time, which is very different from what we saw with threads and with trpl::spawn_task in Listing 17-7. That is because the trpl::join function is fair, meaning it checks each future equally often, alternating between them, and never lets one race ahead if the other is ready. With threads, the operating system decides which thread to check and how long to let it run. With async Rust, the runtime decides which task to check. (In practice, the details get complicated because an async runtime might use operating system threads under the hood as part of how it manages concurrency, so guaranteeing fairness can be more work for a runtime—but it’s still possible!) Runtimes don’t have to guarantee fairness for any given operation, and they often offer different APIs to let you choose whether or not you want fairness.
Try some of these variations on awaiting the futures and see what they do:
- Remove the async block from around either or both of the loops.
- Await each async block immediately after defining it.
- Wrap only the first loop in an async block, and await the resulting future after the body of second loop.
For an extra challenge, see if you can figure out what the output will be in each case before running the code!
Sending Data Between Two Tasks Using Message Passing
Sharing data between futures will also be familiar: we’ll use message passing again, but this time with async versions of the types and functions. We’ll take a slightly different path than we did in the “Transfer Data Between Threads with Message Passing” section in Chapter 16 to illustrate some of the key differences between thread-based and futures-based concurrency. In Listing 17-9, we’ll begin with just a single async block—not spawning a separate task as we spawned a separate thread.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let valeur = String::from("salut");
tx.send(valeur).unwrap();
let received = rx.recv().await.unwrap();
println!("received '{received}'");
});
}tx and rxHere, we use trpl::channel, an async version of the multiple-producer, single-consumer channel API we used with threads back in Chapter 16. The async version of the API is only a little different from the thread-based version: it uses a mutable rather than an immutable receiver rx, and its recv method produces a future we need to await rather than producing the value directly. Now we can send messages from the sender to the receiver. Notice that we don’t have to spawn a separate thread or even a task; we merely need to await the rx.recv call.
The synchronous Receiver::recv method in std::mpsc::channel blocks until it receives a message. The trpl::Receiver::recv method does not, because it is async. Instead of blocking, it hands control back to the runtime until either a message is received or the send side of the channel closes. By contrast, we don’t await the send call, because it doesn’t block. It doesn’t need to, because the channel we’re sending it into is unbounded.
Note: Because all of this async code runs in an async block in a trpl::block_on call, everything within it can avoid blocking. However, the code outside it will block on the block_on function returning. That’s the whole point of the trpl::block_on function: it lets you choose where to block on some set of async code, and thus where to transition between sync and async code.
Notice two things about this example. First, the message will arrive right away. Second, although we use a future here, there’s no concurrency yet. Everything in the listing happens in sequence, just as it would if there were no futures involved.
Let’s address the first part by sending a series of messages and sleeping in between them, as shown in Listing 17-10.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let valeurs = vec![
String::from("salut"),
String::from("à partir"),
String::from("de la"),
String::from("future"),
];
for valeur in valeurs {
tx.send(valeur).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}await between each messageIn addition to sending the messages, we need to receive them. In this case, because we know how many messages are coming in, we could do that manually by calling rx.recv().await four times. In the real world, though, we’ll generally be waiting on some unknown number of messages, so we need to keep waiting until we determine that there are no more messages.
In Listing 16-10, we used a for loop to process all the items received from a synchronous channel. Rust doesn’t yet have a way to use a for loop with an asynchronously produced series of items, however, so we need to use a loop we haven’t seen before: the while let conditional loop. This is the loop version of the if let construct we saw back in the “Concise Control Flow with if let and let...else” section in Chapter 6. The loop will continue executing as long as the pattern it specifies continues to match the value.
The rx.recv call produces a future, which we await. The runtime will pause the future until it is ready. Once a message arrives, the future will resolve to Some(message) as many times as a message arrives. When the channel closes, regardless of whether any messages have arrived, the future will instead resolve to None to indicate that there are no more values and thus we should stop polling—that is, stop awaiting.
The while let loop pulls all of this together. If the result of calling rx.recv().await is Some(message), we get access to the message and we can use it in the loop body, just as we could with if let. If the result is None, the loop ends. Every time the loop completes, it hits the await point again, so the runtime pauses it again until another message arrives.
The code now successfully sends and receives all of the messages. Unfortunately, there are still a couple of problems. For one thing, the messages do not arrive at half-second intervals. They arrive all at once, 2 seconds (2,000 milliseconds) after we start the program. For another, this program also never exits! Instead, it waits forever for new messages. You will need to shut it down using ctrl-C.
Code Within One Async Block Executes Linearly
Let’s start by examining why the messages come in all at once after the full delay, rather than coming in with delays between each one. Within a given async block, the order in which await keywords appear in the code is also the order in which they’re executed when the program runs.
There’s only one async block in Listing 17-10, so everything in it runs linearly. There’s still no concurrency. All the tx.send calls happen, interspersed with all of the trpl::sleep calls and their associated await points. Only then does the while let loop get to go through any of the await points on the recv calls.
To get the behavior we want, where the sleep delay happens between each message, we need to put the tx and rx operations in their own async blocks, as shown in Listing 17-11. Then the runtime can execute each of them separately using trpl::join, just as in Listing 17-8. Once again, we await the result of calling trpl::join, not the individual futures. If we awaited the individual futures in sequence, we would just end up back in a sequential flow—exactly what we’re trying not to do.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}send and recv into their own async blocks and awaiting the futures for those blocksWith the updated code in Listing 17-11, the messages get printed at 500-millisecond intervals, rather than all in a rush after 2 seconds.
Moving Ownership Into an Async Block
The program still never exits, though, because of the way the while let loop interacts with trpl::join:
- The future returned from
trpl::joincompletes only once both futures passed to it have completed. - The
tx_futfuture completes once it finishes sleeping after sending the last message invals. - The
rx_futfuture won’t complete until thewhile letloop ends. - The
while letloop won’t end until awaitingrx.recvproducesNone. - Awaiting
rx.recvwill returnNoneonly once the other end of the channel is closed. - The channel will close only if we call
rx.closeor when the sender side,tx, is dropped. - We don’t call
rx.closeanywhere, andtxwon’t be dropped until the outermost async block passed totrpl::block_onends. - The block can’t end because it is blocked on
trpl::joincompleting, which takes us back to the top of this list.
Right now, the async block where we send the messages only borrows tx because sending a message doesn’t require ownership, but if we could move tx into that async block, it would be dropped once that block ends. In the “Capturing References or Moving Ownership” section in Chapter 13, you learned how to use the move keyword with closures, and, as discussed in the “Using move Closures with Threads” section in Chapter 16, we often need to move data into closures when working with threads. The same basic dynamics apply to async blocks, so the move keyword works with async blocks just as it does with closures.
In Listing 17-12, we change the block used to send messages from async to async move.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async move {
// -- partie masquée ici --
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}When we run this version of the code, it shuts down gracefully after the last message is sent and received. Next, let’s see what would need to change to send data from more than one future.
Joining a Number of Futures with the join! Macro
This async channel is also a multiple-producer channel, so we can call clone on tx if we want to send messages from multiple futures, as shown in Listing 17-13.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(1500)).await;
}
};
trpl::join!(tx1_fut, tx_fut, rx_fut);
});
}First, we clone tx, creating tx1 outside the first async block. We move tx1 into that block just as we did before with tx. Then, later, we move the original tx into a new async block, where we send more messages on a slightly slower delay. We happen to put this new async block after the async block for receiving messages, but it could go before it just as well. The key is the order in which the futures are awaited, not in which they’re created.
Both of the async blocks for sending messages need to be async move blocks so that both tx and tx1 get dropped when those blocks finish. Otherwise, we’ll end up back in the same infinite loop we started out in.
Finally, we switch from trpl::join to trpl::join! to handle the additional future: the join! macro awaits an arbitrary number of futures where we know the number of futures at compile time. We’ll discuss awaiting a collection of an unknown number of futures later in this chapter.
Now we see all the messages from both sending futures, and because the sending futures use slightly different delays after sending, the messages are also received at those different intervals:
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
We’ve explored how to use message passing to send data between futures, how code within an async block runs sequentially, how to move ownership into an async block, and how to join multiple futures. Next, let’s discuss how and why to tell the runtime it can switch to another task.
Travail avec un nombre quelconque de Futures
Yielding Control to the Runtime
Recall from the “Our First Async Program” section that at each await point, Rust gives a runtime a chance to pause the task and switch to another one if the future being awaited isn’t ready. The inverse is also true: Rust only pauses async blocks and hands control back to a runtime at an await point. Everything between await points is synchronous.
That means if you do a bunch of work in an async block without an await point, that future will block any other futures from making progress. You may sometimes hear this referred to as one future starving other futures. In some cases, that may not be a big deal. However, if you are doing some kind of expensive setup or long-running work, or if you have a future that will keep doing some particular task indefinitely, you’ll need to think about when and where to hand control back to the runtime.
Let’s simulate a long-running operation to illustrate the starvation problem, then explore how to solve it. Listing 17-14 introduces a slow function.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
// We will call `slow` here later
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}thread::sleep to simulate slow operationsThis code uses std::thread::sleep instead of trpl::sleep so that calling slow will block the current thread for some number of milliseconds. We can use slow to stand in for real-world operations that are both long-running and blocking.
In Listing 17-15, we use slow to emulate doing this kind of CPU-bound work in a pair of futures.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}slow function to simulate slow operationsEach future hands control back to the runtime only after carrying out a bunch of slow operations. If you run this code, you will see this output:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
As with Listing 17-5 where we used trpl::select to race futures fetching two URLs, select still finishes as soon as a is done. There’s no interleaving between the calls to slow in the two futures, though. The a future does all of its work until the trpl::sleep call is awaited, then the b future does all of its work until its own trpl::sleep call is awaited, and finally the a future completes. To allow both futures to make progress between their slow tasks, we need await points so we can hand control back to the runtime. That means we need something we can await!
We can already see this kind of handoff happening in Listing 17-15: if we removed the trpl::sleep at the end of the a future, it would complete without the b future running at all. Let’s try using the trpl::sleep function as a starting point for letting operations switch off making progress, as shown in Listing 17-16.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await;
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}trpl::sleep to let operations switch off making progressWe’ve added trpl::sleep calls with await points between each call to slow. Now the two futures’ work is interleaved:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
The a future still runs for a bit before handing off control to b, because it calls slow before ever calling trpl::sleep, but after that the futures swap back and forth each time one of them hits an await point. In this case, we have done that after every call to slow, but we could break up the work in whatever way makes the most sense to us.
We don’t really want to sleep here, though: we want to make progress as fast as we can. We just need to hand back control to the runtime. We can do that directly, using the trpl::yield_now function. In Listing 17-17, we replace all those trpl::sleep calls with trpl::yield_now.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}yield_now to let operations switch off making progressThis code is both clearer about the actual intent and can be significantly faster than using sleep, because timers such as the one used by sleep often have limits on how granular they can be. The version of sleep we are using, for example, will always sleep for at least a millisecond, even if we pass it a Duration of one nanosecond. Again, modern computers are fast: they can do a lot in one millisecond!
This means that async can be useful even for compute-bound tasks, depending on what else your program is doing, because it provides a useful tool for structuring the relationships between different parts of the program (but at a cost of the overhead of the async state machine). This is a form of cooperative multitasking, where each future has the power to determine when it hands over control via await points. Each future therefore also has the responsibility to avoid blocking for too long. In some Rust-based embedded operating systems, this is the only kind of multitasking!
In real-world code, you won’t usually be alternating function calls with await points on every single line, of course. While yielding control in this way is relatively inexpensive, it’s not free. In many cases, trying to break up a compute-bound task might make it significantly slower, so sometimes it’s better for overall performance to let an operation block briefly. Always measure to see what your code’s actual performance bottlenecks are. The underlying dynamic is important to keep in mind, though, if you are seeing a lot of work happening in serial that you expected to happen concurrently!
Building Our Own Async Abstractions
We can also compose futures together to create new patterns. For example, we can build a timeout function with async building blocks we already have. When we’re done, the result will be another building block we could use to create still more async abstractions.
Listing 17-18 shows how we would expect this timeout to work with a slow future.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}timeout to run a slow operation with a time limitLet’s implement this! To begin, let’s think about the API for timeout:
- It needs to be an async function itself so we can await it.
- Its first parameter should be a future to run. We can make it generic to allow it to work with any future.
- Its second parameter will be the maximum time to wait. If we use a
Duration, that will make it easy to pass along totrpl::sleep. - It should return a
Result. If the future completes successfully, theResultwill beOkwith the value produced by the future. If the timeout elapses first, theResultwill beErrwith the duration that the timeout waited for.
Listing 17-19 shows this declaration.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implementation will go!
}timeoutThat satisfies our goals for the types. Now let’s think about the behavior we need: we want to race the future passed in against the duration. We can use trpl::sleep to make a timer future from the duration, and use trpl::select to run that timer with the future the caller passes in.
In Listing 17-20, we implement timeout by matching on the result of awaiting trpl::select.
extern crate trpl; // required for mdbook test
use std::time::Duration;
use trpl::Either;
// -- partie masquée ici --
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
match trpl::select(future_to_try, trpl::sleep(max_time)).await {
Either::Left(output) => Ok(output),
Either::Right(_) => Err(max_time),
}
}timeout with select and sleepThe implementation of trpl::select is not fair: it always polls arguments in the order in which they are passed (other select implementations will randomly choose which argument to poll first). Thus, we pass future_to_try to select first so it gets a chance to complete even if max_time is a very short duration. If future_to_try finishes first, select will return Left with the output from future_to_try. If timer finishes first, select will return Right with the timer’s output of ().
If the future_to_try succeeds and we get a Left(output), we return Ok(output). If the sleep timer elapses instead and we get a Right(()), we ignore the () with _ and return Err(max_time) instead.
With that, we have a working timeout built out of two other async helpers. If we run our code, it will print the failure mode after the timeout:
Failed after 2 seconds
Because futures compose with other futures, you can build really powerful tools using smaller async building blocks. For example, you can use this same approach to combine timeouts with retries, and in turn use those with operations such as network calls (such as those in Listing 17-5).
In practice, you’ll usually work directly with async and await, and secondarily with functions such as select and macros such as the join! macro to control how the outermost futures are executed.
We’ve now seen a number of ways to work with multiple futures at the same time. Up next, we’ll look at how we can work with multiple futures in a sequence over time with streams.
Futures en séquence
Futures en séquence
Recall how we used the receiver for our async channel earlier in this chapter in the “Message Passing” section. The async recv method produces a sequence of items over time. This is an instance of a much more general pattern known as a stream. Many concepts are naturally represented as streams: items becoming available in a queue, chunks of data being pulled incrementally from the filesystem when the full data set is too large for the computer’s memory, or data arriving over the network over time. Because streams are futures, we can use them with any other kind of future and combine them in interesting ways. For example, we can batch up events to avoid triggering too many network calls, set timeouts on sequences of long-running operations, or throttle user interface events to avoid doing needless work.
We saw a sequence of items back in Chapter 13, when we looked at the Iterator trait in “The Iterator Trait and the next Method” section, but there are two differences between iterators and the async channel receiver. The first difference is time: iterators are synchronous, while the channel receiver is asynchronous. The second difference is the API. When working directly with Iterator, we call its synchronous next method. With the trpl::Receiver stream in particular, we called an asynchronous recv method instead. Otherwise, these APIs feel very similar, and that similarity isn’t a coincidence. A stream is like an asynchronous form of iteration. Whereas the trpl::Receiver specifically waits to receive messages, though, the general-purpose stream API is much broader: it provides the next item the way Iterator does, but asynchronously.
The similarity between iterators and streams in Rust means we can actually create a stream from any iterator. As with an iterator, we can work with a stream by calling its next method and then awaiting the output, as in Listing 17-21, which won’t compile yet.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}We start with an array of numbers, which we convert to an iterator and then call map on to double all the values. Then we convert the iterator into a stream using the trpl::stream_from_iter function. Next, we loop over the items in the stream as they arrive with the while let loop.
Unfortunately, when we try to run the code, it doesn’t compile but instead reports that there’s no next method available:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
As this output explains, the reason for the compiler error is that we need the right trait in scope to be able to use the next method. Given our discussion so far, you might reasonably expect that trait to be Stream, but it’s actually StreamExt. Short for extension, Ext is a common pattern in the Rust community for extending one trait with another.
The Stream trait defines a low-level interface that effectively combines the Iterator and Future traits. StreamExt supplies a higher-level set of APIs on top of Stream, including the next method as well as other utility methods similar to those provided by the Iterator trait. Stream and StreamExt are not yet part of Rust’s standard library, but most ecosystem crates use similar definitions.
The fix to the compiler error is to add a use statement for trpl::StreamExt, as in Listing 17-22.
extern crate trpl; // required for mdbook test
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// -- partie masquée ici --
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}With all those pieces put together, this code works the way we want! What’s more, now that we have StreamExt in scope, we can use all of its utility methods, just as with iterators.
Examen plus approfondi des traits pour Async
Examen plus approfondi des traits pour Async
Throughout the chapter, we’ve used the Future, Stream, and StreamExt traits in various ways. So far, though, we’ve avoided getting too far into the details of how they work or how they fit together, which is fine most of the time for your day-to-day Rust work. Sometimes, though, you’ll encounter situations where you’ll need to understand a few more of these traits’ details, along with the Pin type and the Unpin trait. In this section, we’ll dig in just enough to help in those scenarios, still leaving the really deep dive for other documentation.
The Future Trait
Let’s start by taking a closer look at how the Future trait works. Here’s how Rust defines it:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}That trait definition includes a bunch of new types and also some syntax we haven’t seen before, so let’s walk through the definition piece by piece.
First, Future’s associated type Output says what the future resolves to. This is analogous to the Item associated type for the Iterator trait. Second, Future has the poll method, which takes a special Pin reference for its self parameter and a mutable reference to a Context type, and returns a Poll<Self::Output>. We’ll talk more about Pin and Context in a moment. For now, let’s focus on what the method returns, the Poll type:
#![allow(unused)]
fn main() {
pub enum Poll<T> {
Ready(T),
Pending,
}
}This Poll type is similar to an Option. It has one variant that has a value, Ready(T), and one that does not, Pending. Poll means something quite different from Option, though! The Pending variant indicates that the future still has work to do, so the caller will need to check again later. The Ready variant indicates that the Future has finished its work and the T value is available.
Note: It’s rare to need to call poll directly, but if you do need to, keep in mind that with most futures, the caller should not call poll again after the future has returned Ready. Many futures will panic if polled again after becoming ready. Futures that are safe to poll again will say so explicitly in their documentation. This is similar to how Iterator::next behaves.
When you see code that uses await, Rust compiles it under the hood to code that calls poll. If you look back at Listing 17-4, where we printed out the page title for a single URL once it resolved, Rust compiles it into something kind of (although not exactly) like this:
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// But what goes here?
}
}What should we do when the future is still Pending? We need some way to try again, and again, and again, until the future is finally ready. In other words, we need a loop:
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// continue
}
}
}If Rust compiled it to exactly that code, though, every await would be blocking—exactly the opposite of what we were going for! Instead, Rust ensures that the loop can hand off control to something that can pause work on this future to work on other futures and then check this one again later. As we’ve seen, that something is an async runtime, and this scheduling and coordination work is one of its main jobs.
In the “Sending Data Between Two Tasks Using Message Passing” section, we described waiting on rx.recv. The recv call returns a future, and awaiting the future polls it. We noted that a runtime will pause the future until it’s ready with either Some(message) or None when the channel closes. With our deeper understanding of the Future trait, and specifically Future::poll, we can see how that works. The runtime knows the future isn’t ready when it returns Poll::Pending. Conversely, the runtime knows the future is ready and advances it when poll returns Poll::Ready(Some(message)) or Poll::Ready(None).
The exact details of how a runtime does that are beyond the scope of this book, but the key is to see the basic mechanics of futures: a runtime polls each future it is responsible for, putting the future back to sleep when it is not yet ready.
The Pin Type and the Unpin Trait
Back in Listing 17-13, we used the trpl::join! macro to await three futures. However, it’s common to have a collection such as a vector containing some number futures that won’t be known until runtime. Let’s change Listing 17-13 to the code in Listing 17-23 that puts the three futures into a vector and calls the trpl::join_all function instead, which won’t compile yet.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
// -- partie masquée ici --
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}We put each future within a Box to make them into trait objects, just as we did in the “Returning Errors from run” section in Chapter 12. (We’ll cover trait objects in detail in Chapter 18.) Using trait objects lets us treat each of the anonymous futures produced by these types as the same type, because all of them implement the Future trait.
This might be surprising. After all, none of the async blocks returns anything, so each one produces a Future<Output = ()>. Remember that Future is a trait, though, and that the compiler creates a unique enum for each async block, even when they have identical output types. Just as you can’t put two different handwritten structs in a Vec, you can’t mix compiler-generated enums.
Then we pass the collection of futures to the trpl::join_all function and await the result. However, this doesn’t compile; here’s the relevant part of the error messages.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
The note in this error message tells us that we should use the pin! macro to pin the values, which means putting them inside the Pin type that guarantees the values won’t be moved in memory. The error message says pinning is required because dyn Future<Output = ()> needs to implement the Unpin trait and it currently does not.
The trpl::join_all function returns a struct called JoinAll. That struct is generic over a type F, which is constrained to implement the Future trait. Directly awaiting a future with await pins the future implicitly. That’s why we don’t need to use pin! everywhere we want to await futures.
However, we’re not directly awaiting a future here. Instead, we construct a new future, JoinAll, by passing a collection of futures to the join_all function. The signature for join_all requires that the types of the items in the collection all implement the Future trait, and Box<T> implements Future only if the T it wraps is a future that implements the Unpin trait.
That’s a lot to absorb! To really understand it, let’s dive a little further into how the Future trait actually works, in particular around pinning. Look again at the definition of the Future trait:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
// Required method
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}The cx parameter and its Context type are the key to how a runtime actually knows when to check any given future while still being lazy. Again, the details of how that works are beyond the scope of this chapter, and you generally only need to think about this when writing a custom Future implementation. We’ll focus instead on the type for self, as this is the first time we’ve seen a method where self has a type annotation. A type annotation for self works like type annotations for other function parameters but with two key differences:
- It tells Rust what type
selfmust be for the method to be called. - It can’t be just any type. It’s restricted to the type on which the method is implemented, a reference or smart pointer to that type, or a
Pinwrapping a reference to that type.
We’ll see more on this syntax in Chapter 18. For now, it’s enough to know that if we want to poll a future to check whether it is Pending or Ready(Output), we need a Pin-wrapped mutable reference to the type.
Pin is a wrapper for pointer-like types such as &, &mut, Box, and Rc. (Technically, Pin works with types that implement the Deref or DerefMut traits, but this is effectively equivalent to working only with references and smart pointers.) Pin is not a pointer itself and doesn’t have any behavior of its own like Rc and Arc do with reference counting; it’s purely a tool the compiler can use to enforce constraints on pointer usage.
Recalling that await is implemented in terms of calls to poll starts to explain the error message we saw earlier, but that was in terms of Unpin, not Pin. So how exactly does Pin relate to Unpin, and why does Future need self to be in a Pin type to call poll?
Remember from earlier in this chapter that a series of await points in a future get compiled into a state machine, and the compiler makes sure that state machine follows all of Rust’s normal rules around safety, including borrowing and ownership. To make that work, Rust looks at what data is needed between one await point and either the next await point or the end of the async block. It then creates a corresponding variant in the compiled state machine. Each variant gets the access it needs to the data that will be used in that section of the source code, whether by taking ownership of that data or by getting a mutable or immutable reference to it.
So far, so good: if we get anything wrong about the ownership or references in a given async block, the borrow checker will tell us. When we want to move around the future that corresponds to that block—like moving it into a Vec to pass to join_all—things get trickier.
When we move a future—whether by pushing it into a data structure to use as an iterator with join_all or by returning it from a function—that actually means moving the state machine Rust creates for us. And unlike most other types in Rust, the futures Rust creates for async blocks can end up with references to themselves in the fields of any given variant, as shown in the simplified illustration in Figure 17-4.

By default, though, any object that has a reference to itself is unsafe to move, because references always point to the actual memory address of whatever they refer to (see Figure 17-5). If you move the data structure itself, those internal references will be left pointing to the old location. However, that memory location is now invalid. For one thing, its value will not be updated when you make changes to the data structure. For another—more important—thing, the computer is now free to reuse that memory for other purposes! You could end up reading completely unrelated data later.

Theoretically, the Rust compiler could try to update every reference to an object whenever it gets moved, but that could add a lot of performance overhead, especially if a whole web of references needs updating. If we could instead make sure the data structure in question doesn’t move in memory, we wouldn’t have to update any references. This is exactly what Rust’s borrow checker is for: in safe code, it prevents you from moving any item with an active reference to it.
Pin builds on that to give us the exact guarantee we need. When we pin a value by wrapping a pointer to that value in Pin, it can no longer move. Thus, if you have Pin<Box<SomeType>>, you actually pin the SomeType value, not the Box pointer. Figure 17-6 illustrates this process.

In fact, the Box pointer can still move around freely. Remember: we care about making sure the data ultimately being referenced stays in place. If a pointer moves around, but the data it points to is in the same place, as in Figure 17-7, there’s no potential problem. (As an independent exercise, look at the docs for the types as well as the std::pin module and try to work out how you’d do this with a Pin wrapping a Box.) The key is that the self-referential type itself cannot move, because it is still pinned.

However, most types are perfectly safe to move around, even if they happen to be behind a Pin pointer. We only need to think about pinning when items have internal references. Primitive values such as numbers and Booleans are safe because they obviously don’t have any internal references. Neither do most types you normally work with in Rust. You can move around a Vec, for example, without worrying. Given what we have seen so far, if you have a Pin<Vec<String>>, you’d have to do everything via the safe but restrictive APIs provided by Pin, even though a Vec<String> is always safe to move if there are no other references to it. We need a way to tell the compiler that it’s fine to move items around in cases like this—and that’s where Unpin comes into play.
Unpin is a marker trait, similar to the Send and Sync traits we saw in Chapter 16, and thus has no functionality of its own. Marker traits exist only to tell the compiler it’s safe to use the type implementing a given trait in a particular context. Unpin informs the compiler that a given type does not need to uphold any guarantees about whether the value in question can be safely moved.
Just as with Send and Sync, the compiler implements Unpin automatically for all types where it can prove it is safe. A special case, again similar to Send and Sync, is where Unpin is not implemented for a type. The notation for this is impl !Unpin for SomeType, where SomeType is the name of a type that does need to uphold those guarantees to be safe whenever a pointer to that type is used in a Pin.
In other words, there are two things to keep in mind about the relationship between Pin and Unpin. First, Unpin is the “normal” case, and !Unpin is the special case. Second, whether a type implements Unpin or !Unpin only matters when you’re using a pinned pointer to that type like Pin<&mut SomeType>.
To make that concrete, think about a String: it has a length and the Unicode characters that make it up. We can wrap a String in Pin, as seen in Figure 17-8. However, String automatically implements Unpin, as do most other types in Rust.

As a result, we can do things that would be illegal if String implemented !Unpin instead, such as replacing one string with another at the exact same location in memory as in Figure 17-9. This doesn’t violate the Pin contract, because String has no internal references that make it unsafe to move around. That is precisely why it implements Unpin rather than !Unpin.

Now we know enough to understand the errors reported for that join_all call from back in Listing 17-23. We originally tried to move the futures produced by async blocks into a Vec<Box<dyn Future<Output = ()>>>, but as we’ve seen, those futures may have internal references, so they don’t automatically implement Unpin. Once we pin them, we can pass the resulting Pin type into the Vec, confident that the underlying data in the futures will not be moved. Listing 17-24 shows how to fix the code by calling the pin! macro where each of the three futures are defined and adjusting the trait object type.
extern crate trpl; // required for mdbook test
use std::pin::{Pin, pin};
// -- partie masquée ici --
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = pin!(async move {
// -- partie masquée ici --
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let rx_fut = pin!(async {
// -- partie masquée ici --
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
let tx_fut = pin!(async move {
// -- partie masquée ici --
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let futures: Vec<Pin<&mut dyn Future<Output = ()>>> =
vec![tx1_fut, rx_fut, tx_fut];
trpl::join_all(futures).await;
});
}This example now compiles and runs, and we could add or remove futures from the vector at runtime and join them all.
Pin and Unpin are mostly important for building lower-level libraries, or when you’re building a runtime itself, rather than for day-to-day Rust code. When you see these traits in error messages, though, now you’ll have a better idea of how to fix your code!
Note: This combination of Pin and Unpin makes it possible to safely implement a whole class of complex types in Rust that would otherwise prove challenging because they’re self-referential. Types that require Pin show up most commonly in async Rust today, but every once in a while, you might see them in other contexts, too.
The specifics of how Pin and Unpin work, and the rules they’re required to uphold, are covered extensively in the API documentation for std::pin, so if you’re interested in learning more, that’s a great place to start.
If you want to understand how things work under the hood in even more detail, see Chapters 2 and 4 of Asynchronous Programming in Rust.
The Stream Trait
Now that you have a deeper grasp on the Future, Pin, and Unpin traits, we can turn our attention to the Stream trait. As you learned earlier in the chapter, streams are similar to asynchronous iterators. Unlike Iterator and Future, however, Stream has no definition in the standard library as of this writing, but there is a very common definition from the futures crate used throughout the ecosystem.
Let’s review the definitions of the Iterator and Future traits before looking at how a Stream trait might merge them together. From Iterator, we have the idea of a sequence: its next method provides an Option<Self::Item>. From Future, we have the idea of readiness over time: its poll method provides a Poll<Self::Output>. To represent a sequence of items that become ready over time, we define a Stream trait that puts those features together:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
}The Stream trait defines an associated type called Item for the type of the items produced by the stream. This is similar to Iterator, where there may be zero to many items, and unlike Future, where there is always a single Output, even if it’s the unit type ().
Stream also defines a method to get those items. We call it poll_next, to make it clear that it polls in the same way Future::poll does and produces a sequence of items in the same way Iterator::next does. Its return type combines Poll with Option. The outer type is Poll, because it has to be checked for readiness, just as a future does. The inner type is Option, because it needs to signal whether there are more messages, just as an iterator does.
Something very similar to this definition will likely end up as part of Rust’s standard library. In the meantime, it’s part of the toolkit of most runtimes, so you can rely on it, and everything we cover next should generally apply!
In the examples we saw in the “Streams: Futures in Sequence” section, though, we didn’t use poll_next or Stream, but instead used next and StreamExt. We could work directly in terms of the poll_next API by hand-writing our own Stream state machines, of course, just as we could work with futures directly via their poll method. Using await is much nicer, though, and the StreamExt trait supplies the next method so we can do just that:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>,
) -> Poll<Option<Self::Item>>;
}
trait StreamExt: Stream {
async fn next(&mut self) -> Option<Self::Item>
where
Self: Unpin;
// other methods...
}
}Note: The actual definition we used earlier in the chapter looks slightly different than this, because it supports versions of Rust that did not yet support using async functions in traits. As a result, it looks like this:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;That Next type is a struct that implements Future and allows us to name the lifetime of the reference to self with Next<'_, Self>, so that await can work with this method.
The StreamExt trait is also the home of all the interesting methods available to use with streams. StreamExt is automatically implemented for every type that implements Stream, but these traits are defined separately to enable the community to iterate on convenience APIs without affecting the foundational trait.
In the version of StreamExt used in the trpl crate, the trait not only defines the next method but also supplies a default implementation of next that correctly handles the details of calling Stream::poll_next. This means that even when you need to write your own streaming data type, you only have to implement Stream, and then anyone who uses your data type can use StreamExt and its methods with it automatically.
That’s all we’re going to cover for the lower-level details on these traits. To wrap up, let’s consider how futures (including streams), tasks, and threads all fit together!
Futures, tâches et fils
Futures, Tasks et Threads
As we saw in Chapter 16, threads provide one approach to concurrency. We’ve seen another approach in this chapter: using async with futures and streams. If you’re wondering when to choose one method over the other, the answer is: it depends! And in many cases, the choice isn’t threads or async but rather threads and async.
Many operating systems have supplied threading-based concurrency models for decades now, and many programming languages support them as a result. However, these models are not without their tradeoffs. On many operating systems, they use a fair bit of memory for each thread. Threads are also only an option when your operating system and hardware support them. Unlike mainstream desktop and mobile computers, some embedded systems don’t have an OS at all, so they also don’t have threads.
The async model provides a different—and ultimately complementary—set of tradeoffs. In the async model, concurrent operations don’t require their own threads. Instead, they can run on tasks, as when we used trpl::spawn_task to kick off work from a synchronous function in the streams section. A task is similar to a thread, but instead of being managed by the operating system, it’s managed by library-level code: the runtime.
There’s a reason the APIs for spawning threads and spawning tasks are so similar. Threads act as a boundary for sets of synchronous operations; concurrency is possible between threads. Tasks act as a boundary for sets of asynchronous operations; concurrency is possible both between and within tasks, because a task can switch between futures in its body. Finally, futures are Rust’s most granular unit of concurrency, and each future may represent a tree of other futures. The runtime—specifically, its executor—manages tasks, and tasks manage futures. In that regard, tasks are similar to lightweight, runtime-managed threads with added capabilities that come from being managed by a runtime instead of by the operating system.
This doesn’t mean that async tasks are always better than threads (or vice versa). Concurrency with threads is in some ways a simpler programming model than concurrency with async. That can be a strength or a weakness. Threads are somewhat “fire and forget”; they have no native equivalent to a future, so they simply run to completion without being interrupted except by the operating system itself.
And it turns out that threads and tasks often work very well together, because tasks can (at least in some runtimes) be moved around between threads. In fact, under the hood, the runtime we’ve been using—including the spawn_blocking and spawn_task functions—is multithreaded by default! Many runtimes use an approach called work stealing to transparently move tasks around between threads, based on how the threads are currently being utilized, to improve the system’s overall performance. That approach actually requires threads and tasks, and therefore futures.
When thinking about which method to use when, consider these rules of thumb:
- If the work is very parallelizable (that is, CPU-bound), such as processing a bunch of data where each part can be processed separately, threads are a better choice.
- If the work is very concurrent (that is, I/O-bound), such as handling messages from a bunch of different sources that may come in at different intervals or different rates, async is a better choice.
And if you need both parallelism and concurrency, you don’t have to choose between threads and async. You can use them together freely, letting each play the part it’s best at. For example, Listing 17-25 shows a fairly common example of this kind of mix in real-world Rust code.
extern crate trpl; // for mdbook test
use std::{thread, time::Duration};
fn main() {
let (tx, mut rx) = trpl::channel();
thread::spawn(move || {
for i in 1..11 {
tx.send(i).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
trpl::block_on(async {
while let Some(message) = rx.recv().await {
println!("{message}");
}
});
}We begin by creating an async channel, then spawning a thread that takes ownership of the sender side of the channel using the move keyword. Within the thread, we send the numbers 1 through 10, sleeping for a second between each. Finally, we run a future created with an async block passed to trpl::block_on just as we have throughout the chapter. In that future, we await those messages, just as in the other message-passing examples we have seen.
To return to the scenario we opened the chapter with, imagine running a set of video encoding tasks using a dedicated thread (because video encoding is compute-bound) but notifying the UI that those operations are done with an async channel. There are countless examples of these kinds of combinations in real-world use cases.
Résumé
This isn’t the last you’ll see of concurrency in this book. The project in Chapter 21 will apply these concepts in a more realistic situation than the simpler examples discussed here and compare problem-solving with threading versus tasks and futures more directly.
No matter which of these approaches you choose, Rust gives you the tools you need to write safe, fast, concurrent code—whether for a high-throughput web server or an embedded operating system.
Au chapitre suivant, nous allons voir des techniques adaptées pour modéliser des problèmes et structurer votre solution au fur et à mesure que vos programmes en Rust grandissent. De plus, nous analyserons les liens qui peuvent exister entre les idées de Rust et celles avec lesquelles vous êtes peut-être familier en programmation orientée objet.
Les fonctionnalités orientées objet de Rust
Object-oriented programming (OOP) is a way of modeling programs. Objects as a programmatic concept were introduced in the programming language Simula in the 1960s. Those objects influenced Alan Kay’s programming architecture in which objects pass messages to each other. To describe this architecture, he coined the term object-oriented programming in 1967. Many competing definitions describe what OOP is, and by some of these definitions Rust is object oriented but by others it is not. In this chapter, we’ll explore certain characteristics that are commonly considered object oriented and how those characteristics translate to idiomatic Rust. We’ll then show you how to implement an object-oriented design pattern in Rust and discuss the trade-offs of doing so versus implementing a solution using some of Rust’s strengths instead.
Les caractéristiques des langages orientés objet
Les caractéristiques des langages orientés objet
There is no consensus in the programming community about what features a language must have to be considered object oriented. Rust is influenced by many programming paradigms, including OOP; for example, we explored the features that came from functional programming in Chapter 13. Arguably, OOP languages share certain common characteristics—namely, objects, encapsulation, and inheritance. Let’s look at what each of those characteristics means and whether Rust supports it.
Objects Contain Data and Behavior
The book Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (Addison-Wesley, 1994), colloquially referred to as The Gang of Four book, is a catalog of object-oriented design patterns. It defines OOP in this way:
Object-oriented programs are made up of objects. An object packages both data and the procedures that operate on that data. The procedures are typically called methods or operations.
Using this definition, Rust is object oriented: Structs and enums have data, and impl blocks provide methods on structs and enums. Even though structs and enums with methods aren’t called objects, they provide the same functionality, according to the Gang of Four’s definition of objects.
Encapsulation That Hides Implementation Details
Another aspect commonly associated with OOP is the idea of encapsulation, which means that the implementation details of an object aren’t accessible to code using that object. Therefore, the only way to interact with an object is through its public API; code using the object shouldn’t be able to reach into the object’s internals and change data or behavior directly. This enables the programmer to change and refactor an object’s internals without needing to change the code that uses the object.
We discussed how to control encapsulation in Chapter 7: We can use the pub keyword to decide which modules, types, functions, and methods in our code should be public, and by default everything else is private. For example, we can define a struct AveragedCollection that has a field containing a vector of i32 values. The struct can also have a field that contains the average of the values in the vector, meaning the average doesn’t have to be computed on demand whenever anyone needs it. In other words, AveragedCollection will cache the calculated average for us. Listing 18-1 has the definition of the AveragedCollection struct.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}AveragedCollection struct that maintains a list of integers and the average of the items in the collectionThe struct is marked pub so that other code can use it, but the fields within the struct remain private. This is important in this case because we want to ensure that whenever a value is added or removed from the list, the average is also updated. We do this by implementing add, remove, and average methods on the struct, as shown in Listing 18-2.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}add, remove, and average on AveragedCollectionLes méthodes publiques ajouter, retirer et moyenne sont les seules façons d’accéder ou de modifier les données d’une instance de CollectionMoyennee. Lorsqu’un élément est ajouté à liste en utilisant la méthode ajouter ou retiré en utilisant la méthode retirer, l’implémentation de chacune de ces méthodes appelle la méthode privée mettre_a_jour_moyenne qui met à jour le champ moyenne également.
We leave the list and average fields private so that there is no way for external code to add or remove items to or from the list field directly; otherwise, the average field might become out of sync when the list changes. The average method returns the value in the average field, allowing external code to read the average but not modify it.
Because we’ve encapsulated the implementation details of the struct AveragedCollection, we can easily change aspects, such as the data structure, in the future. For instance, we could use a HashSet<i32> instead of a Vec<i32> for the list field. As long as the signatures of the add, remove, and average public methods stayed the same, code using AveragedCollection wouldn’t need to change. If we made list public instead, this wouldn’t necessarily be the case: HashSet<i32> and Vec<i32> have different methods for adding and removing items, so the external code would likely have to change if it were modifying list directly.
Si l’encapsulation est une condition nécessaire pour qu’un langage soit considéré comme orienté objet, alors Rust satisfait cette condition. La possibilité d’utiliser pub ou non pour différentes parties de notre code permet d’encapsuler les détails d’implémentation.
Inheritance as a Type System and as Code Sharing
Inheritance is a mechanism whereby an object can inherit elements from another object’s definition, thus gaining the parent object’s data and behavior without you having to define them again.
If a language must have inheritance to be object oriented, then Rust is not such a language. There is no way to define a struct that inherits the parent struct’s fields and method implementations without using a macro.
However, if you’re used to having inheritance in your programming toolbox, you can use other solutions in Rust, depending on your reason for reaching for inheritance in the first place.
You would choose inheritance for two main reasons. One is for reuse of code: You can implement particular behavior for one type, and inheritance enables you to reuse that implementation for a different type. You can do this in a limited way in Rust code using default trait method implementations, which you saw in Listing 10-14 when we added a default implementation of the summarize method on the Summary trait. Any type implementing the Summary trait would have the summarize method available on it without any further code. This is similar to a parent class having an implementation of a method and an inheriting child class also having the implementation of the method. We can also override the default implementation of the summarize method when we implement the Summary trait, which is similar to a child class overriding the implementation of a method inherited from a parent class.
The other reason to use inheritance relates to the type system: to enable a child type to be used in the same places as the parent type. This is also called polymorphism, which means that you can substitute multiple objects for each other at runtime if they share certain characteristics.
Polymorphism
To many people, polymorphism is synonymous with inheritance. But it’s actually a more general concept that refers to code that can work with data of multiple types. For inheritance, those types are generally subclasses.
Rust instead uses generics to abstract over different possible types and trait bounds to impose constraints on what those types must provide. This is sometimes called bounded parametric polymorphism.
Rust has chosen a different set of trade-offs by not offering inheritance. Inheritance is often at risk of sharing more code than necessary. Subclasses shouldn’t always share all characteristics of their parent class but will do so with inheritance. This can make a program’s design less flexible. It also introduces the possibility of calling methods on subclasses that don’t make sense or that cause errors because the methods don’t apply to the subclass. In addition, some languages will only allow single inheritance (meaning a subclass can only inherit from one class), further restricting the flexibility of a program’s design.
For these reasons, Rust takes the different approach of using trait objects instead of inheritance to achieve polymorphism at runtime. Let’s look at how trait objects work.
Utiliser les objets traits qui permettent des valeurs de types différents
Utiliser les objets traits qui permettent des valeurs de types différents
In Chapter 8, we mentioned that one limitation of vectors is that they can store elements of only one type. We created a workaround in Listing 8-9 where we defined a SpreadsheetCell enum that had variants to hold integers, floats, and text. This meant we could store different types of data in each cell and still have a vector that represented a row of cells. This is a perfectly good solution when our interchangeable items are a fixed set of types that we know when our code is compiled.
However, sometimes we want our library user to be able to extend the set of types that are valid in a particular situation. To show how we might achieve this, we’ll create an example graphical user interface (GUI) tool that iterates through a list of items, calling a draw method on each one to draw it to the screen—a common technique for GUI tools. We’ll create a library crate called gui that contains the structure of a GUI library. This crate might include some types for people to use, such as Button or TextField. In addition, gui users will want to create their own types that can be drawn: For instance, one programmer might add an Image, and another might add a SelectBox.
At the time of writing the library, we can’t know and define all the types other programmers might want to create. But we do know that gui needs to keep track of many values of different types, and it needs to call a draw method on each of these differently typed values. It doesn’t need to know exactly what will happen when we call the draw method, just that the value will have that method available for us to call.
To do this in a language with inheritance, we might define a class named Component that has a method named draw on it. The other classes, such as Button, Image, and SelectBox, would inherit from Component and thus inherit the draw method. They could each override the draw method to define their custom behavior, but the framework could treat all of the types as if they were Component instances and call draw on them. But because Rust doesn’t have inheritance, we need another way to structure the gui library to allow users to create new types compatible with the library.
Defining a Trait for Common Behavior
To implement the behavior that we want gui to have, we’ll define a trait named Draw that will have one method named draw. Then, we can define a vector that takes a trait object. A trait object points to both an instance of a type implementing our specified trait and a table used to look up trait methods on that type at runtime. We create a trait object by specifying some sort of pointer, such as a reference or a Box<T> smart pointer, then the dyn keyword, and then specifying the relevant trait. (We’ll talk about the reason trait objects must use a pointer in “Dynamically Sized Types and the Sized Trait” in Chapter 20.) We can use trait objects in place of a generic or concrete type. Wherever we use a trait object, Rust’s type system will ensure at compile time that any value used in that context will implement the trait object’s trait. Consequently, we don’t need to know all the possible types at compile time.
We’ve mentioned that, in Rust, we refrain from calling structs and enums “objects” to distinguish them from other languages’ objects. In a struct or enum, the data in the struct fields and the behavior in impl blocks are separated, whereas in other languages, the data and behavior combined into one concept is often labeled an object. Trait objects differ from objects in other languages in that we can’t add data to a trait object. Trait objects aren’t as generally useful as objects in other languages: Their specific purpose is to allow abstraction across common behavior.
Listing 18-3 shows how to define a trait named Draw with one method named draw.
pub trait Draw {
fn draw(&self);
}Draw traitThis syntax should look familiar from our discussions on how to define traits in Chapter 10. Next comes some new syntax: Listing 18-4 defines a struct named Screen that holds a vector named components. This vector is of type Box<dyn Draw>, which is a trait object; it’s a stand-in for any type inside a Box that implements the Draw trait.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Screen struct with a components field holding a vector of trait objects that implement the Draw traitOn the Screen struct, we’ll define a method named run that will call the draw method on each of its components, as shown in Listing 18-5.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}run method on Screen that calls the draw method on each componentThis works differently from defining a struct that uses a generic type parameter with trait bounds. A generic type parameter can be substituted with only one concrete type at a time, whereas trait objects allow for multiple concrete types to fill in for the trait object at runtime. For example, we could have defined the Screen struct using a generic type and a trait bound, as in Listing 18-6.
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Screen struct and its run method using generics and trait boundsCela nous restreint à une instance de Ecran qui a une liste de composants qui sont soit tous de type Bouton, soit tous de type ChampDeTexte. Si vous ne voulez que des collections homogènes, il est préférable d’utiliser la généricité et les traits liés parce que les définitions seront monomorphisées à la compilation pour utiliser les types concrets.
D’un autre côté, en utilisant des objets traits, une instance de Ecran peut contenir un Vec<T> qui contient à la fois un Box<Bouton> et un Box<ChampDeTexte>. Regardons comment cela fonctionne, puis nous parlerons ensuite du coût en performances à l’exécution.
Implementing the Trait
Now we’ll add some types that implement the Draw trait. We’ll provide the Button type. Again, actually implementing a GUI library is beyond the scope of this book, so the draw method won’t have any useful implementation in its body. To imagine what the implementation might look like, a Button struct might have fields for width, height, and label, as shown in Listing 18-7.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Button struct that implements the Draw traitThe width, height, and label fields on Button will differ from the fields on other components; for example, a TextField type might have those same fields plus a placeholder field. Each of the types we want to draw on the screen will implement the Draw trait but will use different code in the draw method to define how to draw that particular type, as Button has here (without the actual GUI code, as mentioned). The Button type, for instance, might have an additional impl block containing methods related to what happens when a user clicks the button. These kinds of methods won’t apply to types like TextField.
If someone using our library decides to implement a SelectBox struct that has width, height, and options fields, they would implement the Draw trait on the SelectBox type as well, as shown in Listing 18-8.
use gui::Draw;
struct SelectBox {
largeur: u32,
hauteur: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}gui and implementing the Draw trait on a SelectBox structOur library’s user can now write their main function to create a Screen instance. To the Screen instance, they can add a SelectBox and a Button by putting each in a Box<T> to become a trait object. They can then call the run method on the Screen instance, which will call draw on each of the components. Listing 18-9 shows this implementation.
use gui::Draw;
struct SelectBox {
largeur: u32,
hauteur: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Quand nous avons écrit la bibliothèque, nous ne savions pas que quelqu’un pourrait y ajouter le type ListeDeroulante, mais notre implémentation de Ecran a pu opérer sur le nouveau type et l’afficher parce que ListeDeroulante implémente le trait Affichable, ce qui veut dire qu’elle implémente la méthode afficher.
This concept—of being concerned only with the messages a value responds to rather than the value’s concrete type—is similar to the concept of duck typing in dynamically typed languages: If it walks like a duck and quacks like a duck, then it must be a duck! In the implementation of run on Screen in Listing 18-5, run doesn’t need to know what the concrete type of each component is. It doesn’t check whether a component is an instance of a Button or a SelectBox, it just calls the draw method on the component. By specifying Box<dyn Draw> as the type of the values in the components vector, we’ve defined Screen to need values that we can call the draw method on.
L’avantage d’utiliser les objets traits et le système de types de Rust pour écrire du code semblable à celui utilisant le duck typing est que nous n’avons jamais besoin de vérifier si une valeur implémente une méthode en particulier à l’exécution, ni de nous inquiéter d’avoir des erreurs si une valeur n’implémente pas une méthode mais qu’on l’appelle quand même. Rust ne compilera pas notre code si les valeurs n’implémentent pas les traits requis par les objets traits.
For example, Listing 18-10 shows what happens if we try to create a Screen with a String as a component.
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}We’ll get this error because String doesn’t implement the Draw trait:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
This error lets us know that either we’re passing something to Screen that we didn’t mean to pass and so should pass a different type, or we should implement Draw on String so that Screen is able to call draw on it.
Performing Dynamic Dispatch
Recall in “Performance of Code Using Generics” in Chapter 10 our discussion on the monomorphization process performed on generics by the compiler: The compiler generates nongeneric implementations of functions and methods for each concrete type that we use in place of a generic type parameter. The code that results from monomorphization is doing static dispatch, which is when the compiler knows what method you’re calling at compile time. This is opposed to dynamic dispatch, which is when the compiler can’t tell at compile time which method you’re calling. In dynamic dispatch cases, the compiler emits code that at runtime will know which method to call.
When we use trait objects, Rust must use dynamic dispatch. The compiler doesn’t know all the types that might be used with the code that’s using trait objects, so it doesn’t know which method implemented on which type to call. Instead, at runtime, Rust uses the pointers inside the trait object to know which method to call. This lookup incurs a runtime cost that doesn’t occur with static dispatch. Dynamic dispatch also prevents the compiler from choosing to inline a method’s code, which in turn prevents some optimizations, and Rust has some rules about where you can and cannot use dynamic dispatch, called dyn compatibility. Those rules are beyond the scope of this discussion, but you can read more about them in the reference. However, we did get extra flexibility in the code that we wrote in Listing 18-5 and were able to support in Listing 18-9, so it’s a trade-off to consider.
Implémenter un patron de conception orienté-objet
Implémenter un patron de conception orienté-objet
The state pattern is an object-oriented design pattern. The crux of the pattern is that we define a set of states a value can have internally. The states are represented by a set of state objects, and the value’s behavior changes based on its state. We’re going to work through an example of a blog post struct that has a field to hold its state, which will be a state object from the set “draft,” “review,” or “published.”
The state objects share functionality: In Rust, of course, we use structs and traits rather than objects and inheritance. Each state object is responsible for its own behavior and for governing when it should change into another state. The value that holds a state object knows nothing about the different behavior of the states or when to transition between states.
The advantage of using the state pattern is that, when the business requirements of the program change, we won’t need to change the code of the value holding the state or the code that uses the value. We’ll only need to update the code inside one of the state objects to change its rules or perhaps add more state objects.
First, we’re going to implement the state pattern in a more traditional object-oriented way. Then, we’ll use an approach that’s a bit more natural in Rust. Let’s dig in to incrementally implement a blog post workflow using the state pattern.
The final functionality will look like this:
- A blog post starts as an empty draft.
- When the draft is done, a review of the post is requested.
- When the post is approved, it gets published.
- Only published blog posts return content to print so that unapproved posts can’t accidentally be published.
Tous les autres changements effectués sur un billet n’auront pas d’effet. Par exemple, si nous essayons d’approuver un brouillon de billet de blog avant d’avoir demandé une relecture, le billet devrait rester à l’état de brouillon non publié.
Attempting Traditional Object-Oriented Style
There are infinite ways to structure code to solve the same problem, each with different trade-offs. This section’s implementation is more of a traditional object-oriented style, which is possible to write in Rust, but doesn’t take advantage of some of Rust’s strengths. Later, we’ll demonstrate a different solution that still uses the object-oriented design pattern but is structured in a way that might look less familiar to programmers with object-oriented experience. We’ll compare the two solutions to experience the trade-offs of designing Rust code differently than code in other languages.
Listing 18-11 shows this workflow in code form: This is an example usage of the API we’ll implement in a library crate named blog. This won’t compile yet because we haven’t implemented the blog crate.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}blog crate to haveWe want to allow the user to create a new draft blog post with Post::new. We want to allow text to be added to the blog post. If we try to get the post’s content immediately, before approval, we shouldn’t get any text because the post is still a draft. We’ve added assert_eq! in the code for demonstration purposes. An excellent unit test for this would be to assert that a draft blog post returns an empty string from the content method, but we’re not going to write tests for this example.
Ensuite, nous voulons permettre de demander une relecture du billet, et nous souhaitons que contenu retourne toujours une chaîne de caractères vide pendant que nous attendons la relecture. Lorsque la relecture du billet est approuvée, il doit être publié, ce qui signifie que le texte du billet doit être retourné lors de l’appel à contenu.
Notice that the only type we’re interacting with from the crate is the Post type. This type will use the state pattern and will hold a value that will be one of three state objects representing the various states a post can be in—draft, review, or published. Changing from one state to another will be managed internally within the Post type. The states change in response to the methods called by our library’s users on the Post instance, but they don’t have to manage the state changes directly. Also, users can’t make a mistake with the states, such as publishing a post before it’s reviewed.
Defining Post and Creating a New Instance
Let’s get started on the implementation of the library! We know we need a public Post struct that holds some content, so we’ll start with the definition of the struct and an associated public new function to create an instance of Post, as shown in Listing 18-12. We’ll also make a private State trait that will define the behavior that all state objects for a Post must have.
Then, Post will hold a trait object of Box<dyn State> inside an Option<T> in a private field named state to hold the state object. You’ll see why the Option<T> is necessary in a bit.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}Post struct and a new function that creates a new Post instance, a State trait, and a Draft structThe State trait defines the behavior shared by different post states. The state objects are Draft, PendingReview, and Published, and they will all implement the State trait. For now, the trait doesn’t have any methods, and we’ll start by defining just the Draft state because that is the state we want a post to start in.
When we create a new Post, we set its state field to a Some value that holds a Box. This Box points to a new instance of the Draft struct. This ensures that whenever we create a new instance of Post, it will start out as a draft. Because the state field of Post is private, there is no way to create a Post in any other state! In the Post::new function, we set the content field to a new, empty String.
Storing the Text of the Post Content
We saw in Listing 18-11 that we want to be able to call a method named add_text and pass it a &str that is then added as the text content of the blog post. We implement this as a method, rather than exposing the content field as pub, so that later we can implement a method that will control how the content field’s data is read. The add_text method is pretty straightforward, so let’s add the implementation in Listing 18-13 to the impl Post block.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// -- partie masquée ici --
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}add_text method to add text to a post’s contentThe add_text method takes a mutable reference to self because we’re changing the Post instance that we’re calling add_text on. We then call push_str on the String in content and pass the text argument to add to the saved content. This behavior doesn’t depend on the state the post is in, so it’s not part of the state pattern. The add_text method doesn’t interact with the state field at all, but it is part of the behavior we want to support.
Ensuring That the Content of a Draft Post Is Empty
Even after we’ve called add_text and added some content to our post, we still want the content method to return an empty string slice because the post is still in the draft state, as shown by the first assert_eq! in Listing 18-11. For now, let’s implement the content method with the simplest thing that will fulfill this requirement: always returning an empty string slice. We’ll change this later once we implement the ability to change a post’s state so that it can be published. So far, posts can only be in the draft state, so the post content should always be empty. Listing 18-14 shows this placeholder implementation.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// -- partie masquée ici --
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}content method on Post that always returns an empty string sliceWith this added content method, everything in Listing 18-11 through the first assert_eq! works as intended.
Requesting a Review, Which Changes the Post’s State
Next, we need to add functionality to request a review of a post, which should change its state from Draft to PendingReview. Listing 18-15 shows this code.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// -- partie masquée ici --
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}request_review methods on Post and the State traitWe give Post a public method named request_review that will take a mutable reference to self. Then, we call an internal request_review method on the current state of Post, and this second request_review method consumes the current state and returns a new state.
We add the request_review method to the State trait; all types that implement the trait will now need to implement the request_review method. Note that rather than having self, &self, or &mut self as the first parameter of the method, we have self: Box<Self>. This syntax means the method is only valid when called on a Box holding the type. This syntax takes ownership of Box<Self>, invalidating the old state so that the state value of the Post can transform into a new state.
To consume the old state, the request_review method needs to take ownership of the state value. This is where the Option in the state field of Post comes in: We call the take method to take the Some value out of the state field and leave a None in its place because Rust doesn’t let us have unpopulated fields in structs. This lets us move the state value out of Post rather than borrowing it. Then, we’ll set the post’s state value to the result of this operation.
We need to set state to None temporarily rather than setting it directly with code like self.state = self.state.request_review(); to get ownership of the state value. This ensures that Post can’t use the old state value after we’ve transformed it into a new state.
The request_review method on Draft returns a new, boxed instance of a new PendingReview struct, which represents the state when a post is waiting for a review. The PendingReview struct also implements the request_review method but doesn’t do any transformations. Rather, it returns itself because when we request a review on a post already in the PendingReview state, it should stay in the PendingReview state.
Now we can start seeing the advantages of the state pattern: The request_review method on Post is the same no matter its state value. Each state is responsible for its own rules.
We’ll leave the content method on Post as is, returning an empty string slice. We can now have a Post in the PendingReview state as well as in the Draft state, but we want the same behavior in the PendingReview state. Listing 18-11 now works up to the second assert_eq! call!
Adding approve to Change content’s Behavior
The approve method will be similar to the request_review method: It will set state to the value that the current state says it should have when that state is approved, as shown in Listing 18-16.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// -- partie masquée ici --
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// -- partie masquée ici --
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// -- partie masquée ici --
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}approve method on Post and the State traitNous avons ajouté la méthode approuver au trait Etat et ajouté une nouvelle structure Publier, qui implémente Etat.
Similar to the way request_review on PendingReview works, if we call the approve method on a Draft, it will have no effect because approve will return self. When we call approve on PendingReview, it returns a new, boxed instance of the Published struct. The Published struct implements the State trait, and for both the request_review method and the approve method, it returns itself because the post should stay in the Published state in those cases.
Now we need to update the content method on Post. We want the value returned from content to depend on the current state of the Post, so we’re going to have the Post delegate to a content method defined on its state, as shown in Listing 18-17.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// -- partie masquée ici --
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// -- partie masquée ici --
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}content method on Post to delegate to a content method on StateBecause the goal is to keep all of these rules inside the structs that implement State, we call a content method on the value in state and pass the post instance (that is, self) as an argument. Then, we return the value that’s returned from using the content method on the state value.
We call the as_ref method on the Option because we want a reference to the value inside the Option rather than ownership of the value. Because state is an Option<Box<dyn State>>, when we call as_ref, an Option<&Box<dyn State>> is returned. If we didn’t call as_ref, we would get an error because we can’t move state out of the borrowed &self of the function parameter.
We then call the unwrap method, which we know will never panic because we know the methods on Post ensure that state will always contain a Some value when those methods are done. This is one of the cases we talked about in the “When You Have More Information Than the Compiler” section of Chapter 9 when we know that a None value is never possible, even though the compiler isn’t able to understand that.
At this point, when we call content on the &Box<dyn State>, deref coercion will take effect on the & and the Box so that the content method will ultimately be called on the type that implements the State trait. That means we need to add content to the State trait definition, and that is where we’ll put the logic for what content to return depending on which state we have, as shown in Listing 18-18.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// -- partie masquée ici --
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// -- partie masquée ici --
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// -- partie masquée ici --
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}content method to the State traitWe add a default implementation for the content method that returns an empty string slice. That means we don’t need to implement content on the Draft and PendingReview structs. The Published struct will override the content method and return the value in post.content. While convenient, having the content method on State determine the content of the Post is blurring the lines between the responsibility of State and the responsibility of Post.
Remarquez aussi que nous devons annoter des durées de vie sur cette méthode, comme nous l’avons vu au chapitre 10. Nous allons prendre en argument une référence au billet et retourner une référence à une partie de ce billet, donc la durée de vie retournée par la référence est liée à la durée de vie de l’argument billet.
And we’re done—all of Listing 18-11 now works! We’ve implemented the state pattern with the rules of the blog post workflow. The logic related to the rules lives in the state objects rather than being scattered throughout Post.
Why Not An Enum?
You may have been wondering why we didn’t use an enum with the different possible post states as variants. That’s certainly a possible solution; try it and compare the end results to see which you prefer! One disadvantage of using an enum is that every place that checks the value of the enum will need a match expression or similar to handle every possible variant. This could get more repetitive than this trait object solution.
Evaluating the State Pattern
We’ve shown that Rust is capable of implementing the object-oriented state pattern to encapsulate the different kinds of behavior a post should have in each state. The methods on Post know nothing about the various behaviors. Because of the way we organized the code, we have to look in only one place to know the different ways a published post can behave: the implementation of the State trait on the Published struct.
If we were to create an alternative implementation that didn’t use the state pattern, we might instead use match expressions in the methods on Post or even in the main code that checks the state of the post and changes behavior in those places. That would mean we would have to look in several places to understand all the implications of a post being in the published state.
With the state pattern, the Post methods and the places we use Post don’t need match expressions, and to add a new state, we would only need to add a new struct and implement the trait methods on that one struct in one location.
L’implémentation qui utilise le patron état est facile à améliorer pour ajouter plus de fonctionnalités. Pour découvrir la simplicité de maintenance du code qui utilise le patron état, essayez d’accomplir certaines de ces suggestions :
- Add a
rejectmethod that changes the post’s state fromPendingReviewback toDraft. - Require two calls to
approvebefore the state can be changed toPublished. - Allow users to add text content only when a post is in the
Draftstate. Hint: have the state object responsible for what might change about the content but not responsible for modifying thePost.
Un inconvénient du patron état est que comme les états implémentent les transitions entre les états, certains des états sont couplés entre eux. Si nous ajoutons un nouvel état entre EnRelecture et Publier, Planifier par exemple, nous devrons alors changer le code dans EnRelecture pour qu’il passe ensuite à l’état Planifier au lieu de Publier. Cela représenterait moins de travail si EnRelecture n’avait pas besoin de changer lorsqu’on ajoute un nouvel état, mais cela signifierait alors qu’il faudrait changer de patron.
Another downside is that we’ve duplicated some logic. To eliminate some of the duplication, we might try to make default implementations for the request_review and approve methods on the State trait that return self. However, this wouldn’t work: When using State as a trait object, the trait doesn’t know what the concrete self will be exactly, so the return type isn’t known at compile time. (This is one of the dyn compatibility rules mentioned earlier.)
Other duplication includes the similar implementations of the request_review and approve methods on Post. Both methods use Option::take with the state field of Post, and if state is Some, they delegate to the wrapped value’s implementation of the same method and set the new value of the state field to the result. If we had a lot of methods on Post that followed this pattern, we might consider defining a macro to eliminate the repetition (see the “Macros” section in Chapter 20).
By implementing the state pattern exactly as it’s defined for object-oriented languages, we’re not taking as full advantage of Rust’s strengths as we could. Let’s look at some changes we can make to the blog crate that can make invalid states and transitions into compile-time errors.
Implémenter les états et les comportements avec des types
We’ll show you how to rethink the state pattern to get a different set of trade-offs. Rather than encapsulating the states and transitions completely so that outside code has no knowledge of them, we’ll encode the states into different types. Consequently, Rust’s type-checking system will prevent attempts to use draft posts where only published posts are allowed by issuing a compiler error.
Let’s consider the first part of main in Listing 18-11:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}We still enable the creation of new posts in the draft state using Post::new and the ability to add text to the post’s content. But instead of having a content method on a draft post that returns an empty string, we’ll make it so that draft posts don’t have the content method at all. That way, if we try to get a draft post’s content, we’ll get a compiler error telling us the method doesn’t exist. As a result, it will be impossible for us to accidentally display draft post content in production because that code won’t even compile. Listing 18-19 shows the definition of a Post struct and a DraftPost struct, as well as methods on each.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Post with a content method and a DraftPost without a content methodLes deux structures Billet et BrouillonDeBillet ont un champ privé contenu qui stocke le texte du billet de blog. Les structures n’ont plus le champ etat car nous avons déplacé la signification de l’état directement dans le nom de ces types de structures. La structure Billet représente un billet publié et possède une méthode contenu qui retourne le contenu.
Nous avons toujours la fonction Billet::new, mais au lieu de retourner une instance de Billet, elle va retourner une instance de BrouillonDeBillet. Comme contenu est privé et qu’il n’y a pas de fonction qui retourne Billet, il ne sera pas possible pour le moment de créer une instance de Billet.
The DraftPost struct has an add_text method, so we can add text to content as before, but note that DraftPost does not have a content method defined! So now the program ensures that all posts start as draft posts, and draft posts don’t have their content available for display. Any attempt to get around these constraints will result in a compiler error.
So, how do we get a published post? We want to enforce the rule that a draft post has to be reviewed and approved before it can be published. A post in the pending review state should still not display any content. Let’s implement these constraints by adding another struct, PendingReviewPost, defining the request_review method on DraftPost to return a PendingReviewPost and defining an approve method on PendingReviewPost to return a Post, as shown in Listing 18-20.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// -- partie masquée ici --
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}PendingReviewPost that gets created by calling request_review on DraftPost and an approve method that turns a PendingReviewPost into a published PostLes méthodes demander_relecture et approuver prennent possession de self, ce qui consomme les instances de BrouillonDeBillet et de BilletEnRelecture pour les transformer respectivement en BilletEnRelecture et en Billet. Ainsi, il ne restera plus d’instances de BrouillonDeBillet après avoir appelé approuver sur elles, et ainsi de suite. La structure BilletEnRelecture n’a pas de méthode contenu qui lui est définie, donc si on essaye de lire son contenu, on obtient une erreur de compilation, comme avec BrouillonDeBillet. Comme la seule manière d’obtenir une instance de Billet qui a une méthode contenu de définie est d’appeler la méthodeapprouver sur un BilletEnRelecture, et que la seule manière d’obtenir un BilletEnRelecture est d’appeler la méthode demander_relecture sur un BrouillonDeBillet, nous avons désormais intégré le processus de publication des billets de blog avec le système de type.
But we also have to make some small changes to main. The request_review and approve methods return new instances rather than modifying the struct they’re called on, so we need to add more let post = shadowing assignments to save the returned instances. We also can’t have the assertions about the draft and pending review posts’ contents be empty strings, nor do we need them: We can’t compile code that tries to use the content of posts in those states any longer. The updated code in main is shown in Listing 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}main to use the new implementation of the blog post workflowThe changes we needed to make to main to reassign post mean that this implementation doesn’t quite follow the object-oriented state pattern anymore: The transformations between the states are no longer encapsulated entirely within the Post implementation. However, our gain is that invalid states are now impossible because of the type system and the type checking that happens at compile time! This ensures that certain bugs, such as display of the content of an unpublished post, will be discovered before they make it to production.
Try the tasks suggested at the start of this section on the blog crate as it is after Listing 18-21 to see what you think about the design of this version of the code. Note that some of the tasks might be completed already in this design.
Nous avons vu que même si Rust est capable d’implémenter des patrons de conception orientés-objet, d’autres patrons, tel qu’intégrer l’état dans le système de type, sont également possibles en Rust. Ces patrons présentent différents avantages et inconvénients. Bien que vous puissiez être très familier avec les patrons orientés-objet, vous gagnerez à repenser les choses pour tirer avantage des fonctionnalités de Rust, telles que la détection de certains bogues à la compilation. Les patrons orientés-objet ne sont pas toujours la meilleure solution en Rust à cause de certaines de ses fonctionnalités, comme la possession, que les langages orientés-objet n’ont pas.
Résumé
Regardless of whether you think Rust is an object-oriented language after reading this chapter, you now know that you can use trait objects to get some object-oriented features in Rust. Dynamic dispatch can give your code some flexibility in exchange for a bit of runtime performance. You can use this flexibility to implement object-oriented patterns that can help your code’s maintainability. Rust also has other features, like ownership, that object-oriented languages don’t have. An object-oriented pattern won’t always be the best way to take advantage of Rust’s strengths, but it is an available option.
Dans le chapitre suivant, nous allons étudier les motifs, qui constituent une autre des fonctionnalités de Rust et apportent beaucoup de flexibilité. Nous les avons abordés brièvement dans le livre, mais nous n’avons pas encore vu tout leur potentiel. C’est parti !
Les motifs et le filtrage par motif
Les motifs sont une syntaxe spéciale de Rust permettant de filtrer selon la structure des types, qu’elle soit simple ou complexe. L’utilisation de motifs conjointement avec des expressions match et d’autres constructions vous donne davantage de maîtrise sur le flux de contrôle de votre programme. Un motif est constitué d’une combinaison de :
- Literals
- Destructured arrays, enums, structs, or tuples
- Variables
- Wildcards
- Placeholders
Some example patterns include x, (a, 3), and Some(Color::Red). In the contexts in which patterns are valid, these components describe the shape of data. Our program then matches values against the patterns to determine whether it has the correct shape of data to continue running a particular piece of code.
Pour utiliser un motif, nous le comparons à une certaine valeur. Si le motif correspond à la valeur, nous utilisons les éléments présents dans la valeur pour notre code. Rappelez-vous que les expressions match du chapitre 6 utilisaient les motifs, comme pour la machine à trier la monnaie par exemple. Si la valeur correspondait à la forme d’un motif, nous pouvions utiliser le nom de la pièce. Sinon, le code associé au motif n’était pas exécuté.
Ce chapitre sert de référence pour tout ce qui concerne les motifs. Nous allons voir les moments appropriés pour utiliser les motifs, les différences entre les motifs réfutables et irréfutables ainsi que les différentes syntaxes de motifs que vous pouvez rencontrer. À la fin de ce chapitre, vous saurez comment utiliser les motifs pour exprimer clairement de nombreux concepts.
Tous les endroits où les motifs peuvent être utilisés
Tous les endroits où les motifs peuvent être utilisés
Les motifs apparaissent dans de nombreux endroits en Rust, et vous en avez utilisé beaucoup sans vous en rendre compte ! Cette section va présenter les différentes situations où l’utilisation des motifs est appropriée.
match Arms
Comme nous l’avons vu au chapitre 6, nous utilisons les motifs dans les branches des expressions match. Techniquement, les expressions match sont définies avec le mot-clé match, une valeur sur laquelle procéder et une ou plusieurs branches qui constituent un motif, chacune associée à une expression à exécuter si la valeur correspond au motif de la branche, comme ceci :
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}For example, here’s the match expression from Listing 6-5 that matches on an Option<i32> value in the variable x:
match x {
None => None,
Some(i) => Some(i + 1),
}The patterns in this match expression are the None and Some(i) to the left of each arrow.
One requirement for match expressions is that they need to be exhaustive in the sense that all possibilities for the value in the match expression must be accounted for. One way to ensure that you’ve covered every possibility is to have a catch-all pattern for the last arm: For example, a variable name matching any value can never fail and thus covers every remaining case.
The particular pattern _ will match anything, but it never binds to a variable, so it’s often used in the last match arm. The _ pattern can be useful when you want to ignore any value not specified, for example. We’ll cover the _ pattern in more detail in “Ignoring Values in a Pattern” later in this chapter.
let Statements
Avant d’arriver à ce chapitre, nous n’avions abordé explicitement l’utilisation des motifs qu’avec match et if let, mais en réalité, nous avions utilisé les motifs dans d’autres endroits, y compris dans les instructions let. Par exemple, considérons l’assignation de la variable suivante avec let :
#![allow(unused)]
fn main() {
let x = 5;
}Every time you’ve used a let statement like this you’ve been using patterns, although you might not have realized it! More formally, a let statement looks like this:
let PATTERN = EXPRESSION;
In statements like let x = 5; with a variable name in the PATTERN slot, the variable name is just a particularly simple form of a pattern. Rust compares the expression against the pattern and assigns any names it finds. So, in the let x = 5; example, x is a pattern that means “bind what matches here to the variable x.” Because the name x is the whole pattern, this pattern effectively means “bind everything to the variable x, whatever the value is.”
To see the pattern-matching aspect of let more clearly, consider Listing 19-1, which uses a pattern with let to destructure a tuple.
fn main() {
let (x, y, z) = (1, 2, 3);
}Here, we match a tuple against a pattern. Rust compares the value (1, 2, 3) to the pattern (x, y, z) and sees that the value matches the pattern—that is, it sees that the number of elements is the same in both—so Rust binds 1 to x, 2 to y, and 3 to z. You can think of this tuple pattern as nesting three individual variable patterns inside it.
If the number of elements in the pattern doesn’t match the number of elements in the tuple, the overall type won’t match and we’ll get a compiler error. For example, Listing 19-2 shows an attempt to destructure a tuple with three elements into two variables, which won’t work.
fn main() {
let (x, y) = (1, 2, 3);
}Attempting to compile this code results in this type error:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
To fix the error, we could ignore one or more of the values in the tuple using _ or .., as you’ll see in the “Ignoring Values in a Pattern” section. If the problem is that we have too many variables in the pattern, the solution is to make the types match by removing variables so that the number of variables equals the number of elements in the tuple.
Conditional if let Expressions
In Chapter 6, we discussed how to use if let expressions mainly as a shorter way to write the equivalent of a match that only matches one case. Optionally, if let can have a corresponding else containing code to run if the pattern in the if let doesn’t match.
Listing 19-3 shows that it’s also possible to mix and match if let, else if, and else if let expressions. Doing so gives us more flexibility than a match expression in which we can express only one value to compare with the patterns. Also, Rust doesn’t require that the conditions in a series of if let, else if, and else if let arms relate to each other.
The code in Listing 19-3 determines what color to make your background based on a series of checks for several conditions. For this example, we’ve created variables with hardcoded values that a real program might receive from user input.
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}if let, else if, else if let, and elseIf the user specifies a favorite color, that color is used as the background. If no favorite color is specified and today is Tuesday, the background color is green. Otherwise, if the user specifies their age as a string and we can parse it as a number successfully, the color is either purple or orange depending on the value of the number. If none of these conditions apply, the background color is blue.
Cette structure conditionnelle nous permet de répondre à des conditions complexes. Avec les valeurs codées en dur que nous avons ici, cet exemple devrait afficher Utilisation du violet comme couleur de fond.
You can see that if let can also introduce new variables that shadow existing variables in the same way that match arms can: The line if let Ok(age) = age introduces a new age variable that contains the value inside the Ok variant, shadowing the existing age variable. This means we need to place the if age > 30 condition within that block: We can’t combine these two conditions into if let Ok(age) = age && age > 30. The new age we want to compare to 30 isn’t valid until the new scope starts with the curly bracket.
The downside of using if let expressions is that the compiler doesn’t check for exhaustiveness, whereas with match expressions it does. If we omitted the last else block and therefore missed handling some cases, the compiler would not alert us to the possible logic bug.
while let Conditional Loops
Similar in construction to if let, the while let conditional loop allows a while loop to run for as long as a pattern continues to match. In Listing 19-4, we show a while let loop that waits on messages sent between threads, but in this case checking a Result instead of an Option.
fn main() {
let (tx, rx) = std::sync::mpsc::channel();
std::thread::spawn(move || {
for val in [1, 2, 3] {
tx.send(valeur).unwrap();
}
});
while let Ok(value) = rx.recv() {
println!("{value}");
}
}while let loop to print values for as long as rx.recv() returns OkThis example prints 1, 2, and then 3. The recv method takes the first message out of the receiver side of the channel and returns an Ok(value). When we first saw recv back in Chapter 16, we unwrapped the error directly, or we interacted with it as an iterator using a for loop. As Listing 19-4 shows, though, we can also use while let, because the recv method returns an Ok each time a message arrives, as long as the sender exists, and then produces an Err once the sender side disconnects.
for Loops
In a for loop, the value that directly follows the keyword for is a pattern. For example, in for x in y, the x is the pattern. Listing 19-5 demonstrates how to use a pattern in a for loop to destructure, or break apart, a tuple as part of the for loop.
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{value} is at index {index}");
}
}for loop to destructure a tupleThe code in Listing 19-5 will print the following:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
We adapt an iterator using the enumerate method so that it produces a value and the index for that value, placed into a tuple. The first value produced is the tuple (0, 'a'). When this value is matched to the pattern (index, value), index will be 0 and value will be 'a', printing the first line of the output.
Function Parameters
Function parameters can also be patterns. The code in Listing 19-6, which declares a function named foo that takes one parameter named x of type i32, should by now look familiar.
fn foo(x: i32) {
// code goes here
}
fn main() {}The x part is a pattern! As we did with let, we could match a tuple in a function’s arguments to the pattern. Listing 19-7 splits the values in a tuple as we pass it to a function.
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({x}, {y})");
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}Ce code affiche Coordonées actuelles : (3, 5). Les valeurs &(3, 5) correspondent au motif &(x, y), donc x a la valeur 3 et y a la valeur 5.
We can also use patterns in closure parameter lists in the same way as in function parameter lists because closures are similar to functions, as discussed in Chapter 13.
At this point, you’ve seen several ways to use patterns, but patterns don’t work the same in every place we can use them. In some places, the patterns must be irrefutable; in other circumstances, they can be refutable. We’ll discuss these two concepts next.
La réfutabilité : lorsqu'un motif peut échouer à correspondre
La réfutabilité : lorsqu’un motif peut échouer à correspondre
Patterns come in two forms: refutable and irrefutable. Patterns that will match for any possible value passed are irrefutable. An example would be x in the statement let x = 5; because x matches anything and therefore cannot fail to match. Patterns that can fail to match for some possible value are refutable. An example would be Some(x) in the expression if let Some(x) = a_value because if the value in the a_value variable is None rather than Some, the Some(x) pattern will not match.
Function parameters, let statements, and for loops can only accept irrefutable patterns because the program cannot do anything meaningful when values don’t match. The if let and while let expressions and the let...else statement accept refutable and irrefutable patterns, but the compiler warns against irrefutable patterns because, by definition, they’re intended to handle possible failure: The functionality of a conditional is in its ability to perform differently depending on success or failure.
In general, you shouldn’t have to worry about the distinction between refutable and irrefutable patterns; however, you do need to be familiar with the concept of refutability so that you can respond when you see it in an error message. In those cases, you’ll need to change either the pattern or the construct you’re using the pattern with, depending on the intended behavior of the code.
Let’s look at an example of what happens when we try to use a refutable pattern where Rust requires an irrefutable pattern and vice versa. Listing 19-8 shows a let statement, but for the pattern, we’ve specified Some(x), a refutable pattern. As you might expect, this code will not compile.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}letIf some_option_value were a None value, it would fail to match the pattern Some(x), meaning the pattern is refutable. However, the let statement can only accept an irrefutable pattern because there is nothing valid the code can do with a None value. At compile time, Rust will complain that we’ve tried to use a refutable pattern where an irrefutable pattern is required:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Comme nous n’avons pas couvert (et nous ne pouvons pas le faire !) chaque valeur possible avec le motif Some(x), Rust génère une erreur de compilation, à juste titre.
If we have a refutable pattern where an irrefutable pattern is needed, we can fix it by changing the code that uses the pattern: Instead of using let, we can use let...else. Then, if the pattern doesn’t match, the code in the curly brackets will handle the value. Listing 19-9 shows how to fix the code in Listing 19-8.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value else {
return;
};
}let...else and a block with refutable patterns instead of letWe’ve given the code an out! This code is perfectly valid, although it means we cannot use an irrefutable pattern without receiving a warning. If we give let...else a pattern that will always match, such as x, as shown in Listing 19-10, the compiler will give a warning.
fn main() {
let x = 5 else {
return;
};
}let...elseRust complains that it doesn’t make sense to use let...else with an irrefutable pattern:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
C’est pourquoi les branches de match doivent utiliser des motifs réfutables, sauf pour la dernière branche, qui devrait correspondre à n’importe quelle valeur grâce à un motif irréfutable. Rust nous permet d’utiliser un motif irréfutable dans un match ne possédant qu’une seule branche, mais cette syntaxe n’est pas particulièrement utile et devrait être remplacée par une instruction let plus simple.
Maintenant que vous savez où utiliser les motifs et que vous connaissez la différence entre les motifs réfutables et irréfutables, voyons toutes les syntaxes que nous pouvons utiliser pour créer des motifs.
La syntaxe des motifs
La syntaxe des motifs
In this section, we gather all the syntax that is valid in patterns and discuss why and when you might want to use each one.
Matching Literals
Comme vous l’avez vu chapitre 6, vous pouvez faire directement correspondre des motifs avec des littéraux. Le code suivant vous donne quelques exemples :
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
3 => println!("three"),
_ => println!("anything"),
}
}This code prints one because the value in x is 1. This syntax is useful when you want your code to take an action if it gets a particular concrete value.
Matching Named Variables
Named variables are irrefutable patterns that match any value, and we’ve used them many times in this book. However, there is a complication when you use named variables in match, if let, or while let expressions. Because each of these kinds of expressions starts a new scope, variables declared as part of a pattern inside these expressions will shadow those with the same name outside the constructs, as is the case with all variables. In Listing 19-11, we declare a variable named x with the value Some(5) and a variable y with the value 10. We then create a match expression on the value x. Look at the patterns in the match arms and println! at the end, and try to figure out what the code will print before running this code or reading further.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(y) => println!("Matched, y = {y}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}match expression with an arm that introduces a new variable which shadows an existing variable yVoyons ce qui se passe lorsque l’expression match est utilisée. Le motif présent dans la première branche du match ne correspond pas à la valeur actuelle de x, donc le code passe à la branche suivante.
The pattern in the second match arm introduces a new variable named y that will match any value inside a Some value. Because we’re in a new scope inside the match expression, this is a new y variable, not the y we declared at the beginning with the value 10. This new y binding will match any value inside a Some, which is what we have in x. Therefore, this new y binds to the inner value of the Some in x. That value is 5, so the expression for that arm executes and prints Matched, y = 5.
En supposant maintenant que x ait la valeur None plutôt que Some(5), les motifs présents dans les deux premières branches ne correspondront pas, donc la valeur qui correspondra sera celle avec le tiret du bas. Comme nous n’avons pas introduit de nouvelle variable x dans la branche du motif, le x de l’expression associée désigne toujours la variable x en dehors et qui n’a pas été masquée. Le match va donc afficher Cas par défaut, x = None.
Lorsque l’expression match est terminée, sa portée se termine également, et avec elle la portée de la variable interne y. Le dernier println! affiche donc À la fin : x = Some(5), y = 10.
To create a match expression that compares the values of the outer x and y, rather than introducing a new variable that shadows the existing y variable, we would need to use a match guard conditional instead. We’ll talk about match guards later in the “Adding Conditionals with Match Guards” section.
Matching Multiple Patterns
In match expressions, you can match multiple patterns using the | syntax, which is the pattern or operator. For example, in the following code, we match the value of x against the match arms, the first of which has an or option, meaning if the value of x matches either of the values in that arm, that arm’s code will run:
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
}This code prints one or two.
Matching Ranges of Values with ..=
The ..= syntax allows us to match to an inclusive range of values. In the following code, when a pattern matches any of the values within the given range, that arm will execute:
fn main() {
let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}
}If x is 1, 2, 3, 4, or 5, the first arm will match. This syntax is more convenient for multiple match values than using the | operator to express the same idea; if we were to use |, we would have to specify 1 | 2 | 3 | 4 | 5. Specifying a range is much shorter, especially if we want to match, say, any number between 1 and 1,000!
The compiler checks that the range isn’t empty at compile time, and because the only types for which Rust can tell if a range is empty or not are char and numeric values, ranges are only allowed with numeric or char values.
Here is an example using ranges of char values:
fn main() {
let x = 'c';
match x {
'a'..='j' => println!("early ASCII letter"),
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}Rust can tell that 'c' is within the first pattern’s range and prints early ASCII letter.
Destructuring to Break Apart Values
Nous pouvons aussi utiliser les motifs pour déstructurer les structures, les énumérations, et les tuples pour utiliser différentes parties de ces valeurs. Passons en revue chacun des cas.
Structs
Listing 19-12 shows a Point struct with two fields, x and y, that we can break apart using a pattern with a let statement.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}This code creates the variables a and b that match the values of the x and y fields of the p struct. This example shows that the names of the variables in the pattern don’t have to match the field names of the struct. However, it’s common to match the variable names to the field names to make it easier to remember which variables came from which fields. Because of this common usage, and because writing let Point { x: x, y: y } = p; contains a lot of duplication, Rust has a shorthand for patterns that match struct fields: You only need to list the name of the struct field, and the variables created from the pattern will have the same names. Listing 19-13 behaves in the same way as the code in Listing 19-12, but the variables created in the let pattern are x and y instead of a and b.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}Ce code crée les variables x et y qui correspondent aux champs x et y de la variable p. Il en résulte que les variables x et y contiennent les valeurs correspondantes de la structure p.
Nous pouvons aussi déstructurer en utilisant des valeurs littérales faisant partie du motif de la structure plutôt que d’avoir à créer les variables pour tous les champs. Ceci nous permet de tester que certains champs possèdent des valeurs particulières tout en créant des variables pour déstructurer les autres champs.
In Listing 19-14, we have a match expression that separates Point values into three cases: points that lie directly on the x axis (which is true when y = 0), on the y axis (x = 0), or on neither axis.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
}La première branche va correspondre avec tous les points qui se trouvent sur l’axe x en précisant que le champ y correspond au littéral 0. Le motif va systématiquement créer une variable x que nous pourrons utiliser dans le code de cette branche.
De la même manière, la deuxième branche correspondra avec tous les points sur l’axe y en précisant que le champ x correspondra uniquement si sa valeur est 0 et créera une variable y pour la valeur du champ y. La troisième branche n’a pas besoin d’un littéral en particulier, donc elle correspondra à n’importe quel autre Point et créera les variables pour les champs x et y.
In this example, the value p matches the second arm by virtue of x containing a 0, so this code will print On the y axis at 7.
Remember that a match expression stops checking arms once it has found the first matching pattern, so even though Point { x: 0, y: 0 } is on the x axis and the y axis, this code would only print On the x axis at 0.
Enums
We’ve destructured enums in this book (for example, Listing 6-5 in Chapter 6), but we haven’t yet explicitly discussed that the pattern to destructure an enum corresponds to the way the data stored within the enum is defined. As an example, in Listing 19-15, we use the Message enum from Listing 6-2 and write a match with patterns that will destructure each inner value.
enum Message {
Quitter,
Deplacer { x: i32, y: i32 },
Ecrire(String),
ChangerCouleur(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
}
}This code will print Change color to red 0, green 160, and blue 255. Try changing the value of msg to see the code from the other arms run.
Pour les variantes d’énumération sans aucune donnée, telle que Message::Quitter, nous ne pouvons pas déstructurer de valeurs. Nous pouvons uniquement correspondre à la valeur littérale Message::Quitter et il n’y a pas de variable dans ce motif.
For struct-like enum variants, such as Message::Move, we can use a pattern similar to the pattern we specify to match structs. After the variant name, we place curly brackets and then list the fields with variables so that we break apart the pieces to use in the code for this arm. Here we use the shorthand form as we did in Listing 19-13.
Pour les variantes d’énumérations qui ressemblent à des tuples, telles que Message::Ecrire qui stocke un tuple avec un seul élément, ou Message::ChangerCouleur qui stocke un tuple avec trois éléments, le motif est semblable à celui que nous renseignons pour correspondre aux tuples. Le nombre de variables dans le motif doit correspondre au nombre d’éléments dans la variante qui correspond.
Nested Structs and Enums
So far, our examples have all been matching structs or enums one level deep, but matching can work on nested items too! For example, we can refactor the code in Listing 19-15 to support RGB and HSV colors in the ChangeColor message, as shown in Listing 19-16.
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quitter,
Deplacer { x: i32, y: i32 },
Ecrire(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}");
}
_ => (),
}
}The pattern of the first arm in the match expression matches a Message::ChangeColor enum variant that contains a Color::Rgb variant; then, the pattern binds to the three inner i32 values. The pattern of the second arm also matches a Message::ChangeColor enum variant, but the inner enum matches Color::Hsv instead. We can specify these complex conditions in one match expression, even though two enums are involved.
Structs and Tuples
Nous pouvons mélanger les correspondances et les motifs pour déstructurer des éléments imbriqués de manière bien plus complexe. L’exemple suivant montre une déstructuration complexe dans laquelle nous imbriquons des structures et des tuples à l’intérieur d’un tuple et nous y déstructurons toutes les valeurs primitives :
fn main() {
struct Point {
x: i32,
y: i32,
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}This code lets us break complex types into their component parts so that we can use the values we’re interested in separately.
La déstructuration avec les motifs est un moyen efficace d’utiliser des parties de valeurs, comme par exemple la valeur de chaque champ d’une structure, indépendamment les unes des autres.
Ignoring Values in a Pattern
You’ve seen that it’s sometimes useful to ignore values in a pattern, such as in the last arm of a match, to get a catch-all that doesn’t actually do anything but does account for all remaining possible values. There are a few ways to ignore entire values or parts of values in a pattern: using the _ pattern (which you’ve seen), using the _ pattern within another pattern, using a name that starts with an underscore, or using .. to ignore remaining parts of a value. Let’s explore how and why to use each of these patterns.
An Entire Value with _
We’ve used the underscore as a wildcard pattern that will match any value but not bind to the value. This is especially useful as the last arm in a match expression, but we can also use it in any pattern, including function parameters, as shown in Listing 19-17.
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {y}");
}
fn main() {
foo(3, 4);
}_ in a function signatureThis code will completely ignore the value 3 passed as the first argument, and will print This code only uses the y parameter: 4.
In most cases when you no longer need a particular function parameter, you would change the signature so that it doesn’t include the unused parameter. Ignoring a function parameter can be especially useful in cases when, for example, you’re implementing a trait when you need a certain type signature but the function body in your implementation doesn’t need one of the parameters. You then avoid getting a compiler warning about unused function parameters, as you would if you used a name instead.
Parts of a Value with a Nested _
We can also use _ inside another pattern to ignore just part of a value, for example, when we want to test for only part of a value but have no use for the other parts in the corresponding code we want to run. Listing 19-18 shows code responsible for managing a setting’s value. The business requirements are that the user should not be allowed to overwrite an existing customization of a setting but can unset the setting and give it a value if it is currently unset.
fn main() {
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {setting_value:?}");
}Some variants when we don’t need to use the value inside the SomeThis code will print Can't overwrite an existing customized value and then setting is Some(5). In the first match arm, we don’t need to match on or use the values inside either Some variant, but we do need to test for the case when setting_value and new_setting_value are the Some variant. In that case, we print the reason for not changing setting_value, and it doesn’t get changed.
In all other cases (if either setting_value or new_setting_value is None) expressed by the _ pattern in the second arm, we want to allow new_setting_value to become setting_value.
We can also use underscores in multiple places within one pattern to ignore particular values. Listing 19-19 shows an example of ignoring the second and fourth values in a tuple of five items.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, _, third, _, fifth) => {
println!("Some numbers: {first}, {third}, {fifth}");
}
}
}This code will print Some numbers: 2, 8, 32, and the values 4 and 16 will be ignored.
An Unused Variable by Starting Its Name with _
If you create a variable but don’t use it anywhere, Rust will usually issue a warning because an unused variable could be a bug. However, sometimes it’s useful to be able to create a variable you won’t use yet, such as when you’re prototyping or just starting a project. In this situation, you can tell Rust not to warn you about the unused variable by starting the name of the variable with an underscore. In Listing 19-20, we create two unused variables, but when we compile this code, we should only get a warning about one of them.
fn main() {
let _x = 5;
let y = 10;
}Here, we get a warning about not using the variable y, but we don’t get a warning about not using _x.
Note that there is a subtle difference between using only _ and using a name that starts with an underscore. The syntax _x still binds the value to the variable, whereas _ doesn’t bind at all. To show a case where this distinction matters, Listing 19-21 will provide us with an error.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}We’ll receive an error because the s value will still be moved into _s, which prevents us from using s again. However, using the underscore by itself doesn’t ever bind to the value. Listing 19-22 will compile without any errors because s doesn’t get moved into _.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{s:?}");
}This code works just fine because we never bind s to anything; it isn’t moved.
Remaining Parts of a Value with ..
With values that have many parts, we can use the .. syntax to use specific parts and ignore the rest, avoiding the need to list underscores for each ignored value. The .. pattern ignores any parts of a value that we haven’t explicitly matched in the rest of the pattern. In Listing 19-23, we have a Point struct that holds a coordinate in three-dimensional space. In the match expression, we want to operate only on the x coordinate and ignore the values in the y and z fields.
fn main() {
struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {x}"),
}
}Point except for x by using ..Nous ajoutons la valeur x puis nous insérons simplement le motif ... C’est plus rapide que d’avoir à ajouter y: _ et z: _, en particulier lorsque nous travaillons avec des structures qui ont beaucoup de champs alors qu’un seul champ ou deux nous intéressent.
The syntax .. will expand to as many values as it needs to be. Listing 19-24 shows how to use .. with a tuple.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {first}, {last}");
}
}
}In this code, the first and last values are matched with first and last. The .. will match and ignore everything in the middle.
However, using .. must be unambiguous. If it is unclear which values are intended for matching and which should be ignored, Rust will give us an error. Listing 19-25 shows an example of using .. ambiguously, so it will not compile.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}.. in an ambiguous wayWhen we compile this example, we get this error:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Il est impossible pour Rust de déterminer combien de valeurs doivent être ignorées dans le tuple avant de faire correspondre une valeur avec second et ensuite combien d’autres doivent être ignorées après. Ce code pourrait signifier que nous voulons ignorer 2, faire correspondre second avec 4, puis ignorer ensuite 8, 16 et 32 ; ou que nous souhaitons ignorer 2 et 4, faire correspondre second à 8, puis ignorer ensuite 16 et 32 ; et ainsi de suite. Le nom de la variable second ne signifie pas grand-chose pour Rust, donc nous obtenons une erreur de compilation à cause de l’utilisation de .. à deux endroits qui rendent la situation ambigüe.
Adding Conditionals with Match Guards
A match guard is an additional if condition, specified after the pattern in a match arm, that must also match for that arm to be chosen. Match guards are useful for expressing more complex ideas than a pattern alone allows. Note, however, that they are only available in match expressions, not if let or while let expressions.
The condition can use variables created in the pattern. Listing 19-26 shows a match where the first arm has the pattern Some(x) and also has a match guard of if x % 2 == 0 (which will be true if the number is even).
fn main() {
let num = Some(4);
match num {
Some(x) if x % 2 == 0 => println!("The number {x} is even"),
Some(x) => println!("The number {x} is odd"),
None => (),
}
}This example will print The number 4 is even. When num is compared to the pattern in the first arm, it matches because Some(4) matches Some(x). Then, the match guard checks whether the remainder of dividing x by 2 is equal to 0, and because it is, the first arm is selected.
If num had been Some(5) instead, the match guard in the first arm would have been false because the remainder of 5 divided by 2 is 1, which is not equal to 0. Rust would then go to the second arm, which would match because the second arm doesn’t have a match guard and therefore matches any Some variant.
There is no way to express the if x % 2 == 0 condition within a pattern, so the match guard gives us the ability to express this logic. The downside of this additional expressiveness is that the compiler doesn’t try to check for exhaustiveness when match guard expressions are involved.
When discussing Listing 19-11, we mentioned that we could use match guards to solve our pattern-shadowing problem. Recall that we created a new variable inside the pattern in the match expression instead of using the variable outside the match. That new variable meant we couldn’t test against the value of the outer variable. Listing 19-27 shows how we can use a match guard to fix this problem.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {n}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}Ce code va maintenant afficher Cas par défaut, x = Some(5). Le motif de la deuxième branche du match ne crée pas de nouvelle variable y qui masquerait le y externe, ce qui signifie que nous pouvons utiliser le y externe dans le contrôle de correspondance. Au lieu de renseigner le motif comme étant Some(y), ce qui aurait masqué le y externe, nous renseignons Some(n). Cela va créer une nouvelle variable n qui ne masque rien car il n’y a pas de variable n à l’extérieur du match.
The match guard if n == y is not a pattern and therefore doesn’t introduce new variables. This y is the outer y rather than a new y shadowing it, and we can look for a value that has the same value as the outer y by comparing n to y.
You can also use the or operator | in a match guard to specify multiple patterns; the match guard condition will apply to all the patterns. Listing 19-28 shows the precedence when combining a pattern that uses | with a match guard. The important part of this example is that the if y match guard applies to 4, 5, and 6, even though it might look like if y only applies to 6.
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"),
_ => println!("no"),
}
}The match condition states that the arm only matches if the value of x is equal to 4, 5, or 6 and if y is true. When this code runs, the pattern of the first arm matches because x is 4, but the match guard if y is false, so the first arm is not chosen. The code moves on to the second arm, which does match, and this program prints no. The reason is that the if condition applies to the whole pattern 4 | 5 | 6, not just to the last value 6. In other words, the precedence of a match guard in relation to a pattern behaves like this:
(4 | 5 | 6) if y => ...
rather than this:
4 | 5 | (6 if y) => ...
After running the code, the precedence behavior is evident: If the match guard were applied only to the final value in the list of values specified using the | operator, the arm would have matched, and the program would have printed yes.
Using @ Bindings
The at operator @ lets us create a variable that holds a value at the same time we’re testing that value for a pattern match. In Listing 19-29, we want to test that a Message::Hello id field is within the range 3..=7. We also want to bind the value to the variable id so that we can use it in the code associated with the arm.
fn main() {
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id @ 3..=7 } => {
println!("Found an id in range: {id}")
}
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
Message::Hello { id } => println!("Found some other id: {id}"),
}
}@ to bind to a value in a pattern while also testing itThis example will print Found an id in range: 5. By specifying id @ before the range 3..=7, we’re capturing whatever value matched the range in a variable named id while also testing that the value matched the range pattern.
In the second arm, where we only have a range specified in the pattern, the code associated with the arm doesn’t have a variable that contains the actual value of the id field. The id field’s value could have been 10, 11, or 12, but the code that goes with that pattern doesn’t know which it is. The pattern code isn’t able to use the value from the id field because we haven’t saved the id value in a variable.
In the last arm, where we’ve specified a variable without a range, we do have the value available to use in the arm’s code in a variable named id. The reason is that we’ve used the struct field shorthand syntax. But we haven’t applied any test to the value in the id field in this arm, as we did with the first two arms: Any value would match this pattern.
Using @ lets us test a value and save it in a variable within one pattern.
Résumé
Rust’s patterns are very useful in distinguishing between different kinds of data. When used in match expressions, Rust ensures that your patterns cover every possible value, or your program won’t compile. Patterns in let statements and function parameters make those constructs more useful, enabling the destructuring of values into smaller parts and assigning those parts to variables. We can create simple or complex patterns to suit our needs.
Dans le chapitre suivant, qui sera l’avant-dernier du livre, nous allons découvrir quelques aspects avancés de l’éventail de fonctionnalités de Rust.
Les fonctionnalités avancées
By now, you’ve learned the most commonly used parts of the Rust programming language. Before we do one more project, in Chapter 21, we’ll look at a few aspects of the language you might run into every once in a while but may not use every day. You can use this chapter as a reference for when you encounter any unknowns. The features covered here are useful in very specific situations. Although you might not reach for them often, we want to make sure you have a grasp of all the features Rust has to offer.
In this chapter, we’ll cover:
- Unsafe Rust: How to opt out of some of Rust’s guarantees and take responsibility for manually upholding those guarantees
- Advanced traits: Associated types, default type parameters, fully qualified syntax, supertraits, and the newtype pattern in relation to traits
- Advanced types: More about the newtype pattern, type aliases, the never type, and dynamically sized types
- Advanced functions and closures: Function pointers and returning closures
- Macros: Ways to define code that defines more code at compile time
It’s a panoply of Rust features with something for everyone! Let’s dive in!
Le Rust non sécurisé (unsafe)
Le Rust non sécurisé (unsafe)
All the code we’ve discussed so far has had Rust’s memory safety guarantees enforced at compile time. However, Rust has a second language hidden inside it that doesn’t enforce these memory safety guarantees: It’s called unsafe Rust and works just like regular Rust but gives us extra superpowers.
Unsafe Rust exists because, by nature, static analysis is conservative. When the compiler tries to determine whether or not code upholds the guarantees, it’s better for it to reject some valid programs than to accept some invalid programs. Although the code might be okay, if the Rust compiler doesn’t have enough information to be confident, it will reject the code. In these cases, you can use unsafe code to tell the compiler, “Trust me, I know what I’m doing.” Be warned, however, that you use unsafe Rust at your own risk: If you use unsafe code incorrectly, problems can occur due to memory unsafety, such as null pointer dereferencing.
Une autre raison pour laquelle Rust embarque son alter-ego non sécurisé est que le matériel des ordinateurs sur lequel il repose n’est pas sécurisé par essence. Si Rust ne vous laissait pas procéder à des opérations non sécurisées, vous ne pourriez pas faire certaines choses. Rust doit pouvoir vous permettre de développer du code bas-niveau, comme pouvoir interagir directement avec le système d’exploitation ou même écrire votre propre système d’exploitation. Pouvoir travailler avec des systèmes bas-niveau est un des objectifs du langage. Voyons ce que nous pouvons faire avec le Rust non sécurisé et comment le faire.
Performing Unsafe Superpowers
To switch to unsafe Rust, use the unsafe keyword and then start a new block that holds the unsafe code. You can take five actions in unsafe Rust that you can’t in safe Rust, which we call unsafe superpowers. Those superpowers include the ability to:
- Dereference a raw pointer.
- Call an unsafe function or method.
- Access or modify a mutable static variable.
- Implement an unsafe trait.
- Access fields of
unions.
It’s important to understand that unsafe doesn’t turn off the borrow checker or disable any of Rust’s other safety checks: If you use a reference in unsafe code, it will still be checked. The unsafe keyword only gives you access to these five features that are then not checked by the compiler for memory safety. You’ll still get some degree of safety inside an unsafe block.
In addition, unsafe does not mean the code inside the block is necessarily dangerous or that it will definitely have memory safety problems: The intent is that as the programmer, you’ll ensure that the code inside an unsafe block will access memory in a valid way.
People are fallible and mistakes will happen, but by requiring these five unsafe operations to be inside blocks annotated with unsafe, you’ll know that any errors related to memory safety must be within an unsafe block. Keep unsafe blocks small; you’ll be thankful later when you investigate memory bugs.
To isolate unsafe code as much as possible, it’s best to enclose such code within a safe abstraction and provide a safe API, which we’ll discuss later in the chapter when we examine unsafe functions and methods. Parts of the standard library are implemented as safe abstractions over unsafe code that has been audited. Wrapping unsafe code in a safe abstraction prevents uses of unsafe from leaking out into all the places that you or your users might want to use the functionality implemented with unsafe code, because using a safe abstraction is safe.
Analysons ces cinq super-pouvoirs à tour de rôle. Nous allons aussi découvrir quelques abstractions qui fournissent une interface sécurisée pour faire fonctionner du code non sécurisé.
Dereferencing a Raw Pointer
In Chapter 4, in the “Dangling References” section, we mentioned that the compiler ensures that references are always valid. Unsafe Rust has two new types called raw pointers that are similar to references. As with references, raw pointers can be immutable or mutable and are written as *const T and *mut T, respectively. The asterisk isn’t the dereference operator; it’s part of the type name. In the context of raw pointers, immutable means that the pointer can’t be directly assigned to after being dereferenced.
Different from references and smart pointers, raw pointers:
- Are allowed to ignore the borrowing rules by having both immutable and mutable pointers or multiple mutable pointers to the same location
- Aren’t guaranteed to point to valid memory
- Are allowed to be null
- Don’t implement any automatic cleanup
En renonçant à ce que Rust fasse respecter ces garanties, vous pouvez sacrifier la sécurité garantie pour obtenir de meilleures performances ou avoir la possibilité de vous interfacer avec un autre langage ou matériel pour lesquels les garanties de Rust ne s’appliquent pas.
Listing 20-1 shows how to create an immutable and a mutable raw pointer.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
}Remarquez que nous n’incorporons pas le mot-clé unsafe dans ce code. Nous pouvons créer des pointeurs bruts dans du code sécurisé ; nous ne pouvons simplement pas déréférencer les pointeurs bruts à l’extérieur d’un bloc non sécurisé, comme vous allez le constater d’ici peu.
We’ve created raw pointers by using the raw borrow operators: &raw const num creates a *const i32 immutable raw pointer, and &raw mut num creates a *mut i32 mutable raw pointer. Because we created them directly from a local variable, we know these particular raw pointers are valid, but we can’t make that assumption about just any raw pointer.
To demonstrate this, next we’ll create a raw pointer whose validity we can’t be so certain of, using the keyword as to cast a value instead of using the raw borrow operator. Listing 20-2 shows how to create a raw pointer to an arbitrary location in memory. Trying to use arbitrary memory is undefined: There might be data at that address or there might not, the compiler might optimize the code so that there is no memory access, or the program might terminate with a segmentation fault. Usually, there is no good reason to write code like this, especially in cases where you can use a raw borrow operator instead, but it is possible.
fn main() {
let address = 0x012345usize;
let r = address as *const i32;
}Recall that we can create raw pointers in safe code, but we can’t dereference raw pointers and read the data being pointed to. In Listing 20-3, we use the dereference operator * on a raw pointer that requires an unsafe block.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
}unsafe blockLa création de pointeur ne pose pas de problèmes ; c’est seulement lorsque nous essayons d’accéder aux valeurs sur lesquelles ils pointent qu’on risque d’obtenir une valeur invalide.
Note also that in Listings 20-1 and 20-3, we created *const i32 and *mut i32 raw pointers that both pointed to the same memory location, where num is stored. If we instead tried to create an immutable and a mutable reference to num, the code would not have compiled because Rust’s ownership rules don’t allow a mutable reference at the same time as any immutable references. With raw pointers, we can create a mutable pointer and an immutable pointer to the same location and change data through the mutable pointer, potentially creating a data race. Be careful!
With all of these dangers, why would you ever use raw pointers? One major use case is when interfacing with C code, as you’ll see in the next section. Another case is when building up safe abstractions that the borrow checker doesn’t understand. We’ll introduce unsafe functions and then look at an example of a safe abstraction that uses unsafe code.
Calling an Unsafe Function or Method
The second type of operation you can perform in an unsafe block is calling unsafe functions. Unsafe functions and methods look exactly like regular functions and methods, but they have an extra unsafe before the rest of the definition. The unsafe keyword in this context indicates the function has requirements we need to uphold when we call this function, because Rust can’t guarantee we’ve met these requirements. By calling an unsafe function within an unsafe block, we’re saying that we’ve read this function’s documentation and we take responsibility for upholding the function’s contracts.
Voici une fonction non sécurisée dangereux, qui ne fait rien dans son corps :
fn main() {
unsafe fn dangerous() {}
unsafe {
dangerous();
}
}Nous devons faire appel à la fonction dangereux dans un bloc unsafe séparé. Si nous essayons d’appeler dangereux sans le bloc unsafe, nous obtenons une erreur :
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
With the unsafe block, we’re asserting to Rust that we’ve read the function’s documentation, we understand how to use it properly, and we’ve verified that we’re fulfilling the contract of the function.
To perform unsafe operations in the body of an unsafe function, you still need to use an unsafe block, just as within a regular function, and the compiler will warn you if you forget. This helps us keep unsafe blocks as small as possible, as unsafe operations may not be needed across the whole function body.
Creating a Safe Abstraction over Unsafe Code
Just because a function contains unsafe code doesn’t mean we need to mark the entire function as unsafe. In fact, wrapping unsafe code in a safe function is a common abstraction. As an example, let’s study the split_at_mut function from the standard library, which requires some unsafe code. We’ll explore how we might implement it. This safe method is defined on mutable slices: It takes one slice and makes it two by splitting the slice at the index given as an argument. Listing 20-4 shows how to use split_at_mut.
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}split_at_mut functionWe can’t implement this function using only safe Rust. An attempt might look something like Listing 20-5, which won’t compile. For simplicity, we’ll implement split_at_mut as a function rather than a method and only for slices of i32 values rather than for a generic type T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut using only safe RustThis function first gets the total length of the slice. Then, it asserts that the index given as a parameter is within the slice by checking whether it’s less than or equal to the length. The assertion means that if we pass an index that is greater than the length to split the slice at, the function will panic before it attempts to use that index.
Then, we return two mutable slices in a tuple: one from the start of the original slice to the mid index and another from mid to the end of the slice.
When we try to compile the code in Listing 20-5, we’ll get an error:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Le vérificateur d’emprunt de Rust ne comprend pas que nous empruntons différentes parties de la slice ; il comprend seulement que nous empruntons la même slice à deux reprises. L’emprunt de différentes parties d’une slice ne pose fondamentalement pas de problèmes car les deux slices ne se chevauchent pas, mais Rust n’est pas suffisamment intelligent pour comprendre ceci. Lorsque nous savons que ce code est correct, mais que Rust ne le sait pas, il est approprié d’utiliser du code non sécurisé.
Listing 20-6 shows how to use an unsafe block, a raw pointer, and some calls to unsafe functions to make the implementation of split_at_mut work.
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut functionRecall from “The Slice Type” section in Chapter 4 that a slice is a pointer to some data and the length of the slice. We use the len method to get the length of a slice and the as_mut_ptr method to access the raw pointer of a slice. In this case, because we have a mutable slice to i32 values, as_mut_ptr returns a raw pointer with the type *mut i32, which we’ve stored in the variable ptr.
We keep the assertion that the mid index is within the slice. Then, we get to the unsafe code: The slice::from_raw_parts_mut function takes a raw pointer and a length, and it creates a slice. We use this function to create a slice that starts from ptr and is mid items long. Then, we call the add method on ptr with mid as an argument to get a raw pointer that starts at mid, and we create a slice using that pointer and the remaining number of items after mid as the length.
The function slice::from_raw_parts_mut is unsafe because it takes a raw pointer and must trust that this pointer is valid. The add method on raw pointers is also unsafe because it must trust that the offset location is also a valid pointer. Therefore, we had to put an unsafe block around our calls to slice::from_raw_parts_mut and add so that we could call them. By looking at the code and by adding the assertion that mid must be less than or equal to len, we can tell that all the raw pointers used within the unsafe block will be valid pointers to data within the slice. This is an acceptable and appropriate use of unsafe.
Note that we don’t need to mark the resultant split_at_mut function as unsafe, and we can call this function from safe Rust. We’ve created a safe abstraction to the unsafe code with an implementation of the function that uses unsafe code in a safe way, because it creates only valid pointers from the data this function has access to.
In contrast, the use of slice::from_raw_parts_mut in Listing 20-7 would likely crash when the slice is used. This code takes an arbitrary memory location and creates a slice 10,000 items long.
fn main() {
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
}Nous ne possédons pas la mémoire à cet emplacement arbitraire, et il n’y a aucune garantie que la slice créée par ce code contiennent des valeurs i32 valides. Toute tentative d’utilisation de valeurs aura un comportement imprévisible bien qu’il s’agisse d’une slice valide.
Using extern Functions to Call External Code
Sometimes your Rust code might need to interact with code written in another language. For this, Rust has the keyword extern that facilitates the creation and use of a Foreign Function Interface (FFI), which is a way for a programming language to define functions and enable a different (foreign) programming language to call those functions.
Listing 20-8 demonstrates how to set up an integration with the abs function from the C standard library. Functions declared within extern blocks are generally unsafe to call from Rust code, so extern blocks must also be marked unsafe. The reason is that other languages don’t enforce Rust’s rules and guarantees, and Rust can’t check them, so responsibility falls on the programmer to ensure safety.
unsafe extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}extern function defined in another languageWithin the unsafe extern "C" block, we list the names and signatures of external functions from another language we want to call. The "C" part defines which application binary interface (ABI) the external function uses: The ABI defines how to call the function at the assembly level. The "C" ABI is the most common and follows the C programming language’s ABI. Information about all the ABIs Rust supports is available in the Rust Reference.
Every item declared within an unsafe extern block is implicitly unsafe. However, some FFI functions are safe to call. For example, the abs function from C’s standard library does not have any memory safety considerations, and we know it can be called with any i32. In cases like this, we can use the safe keyword to say that this specific function is safe to call even though it is in an unsafe extern block. Once we make that change, calling it no longer requires an unsafe block, as shown in Listing 20-9.
unsafe extern "C" {
safe fn abs(input: i32) -> i32;
}
fn main() {
println!("Absolute value of -3 according to C: {}", abs(-3));
}safe within an unsafe extern block and calling it safelyMarking a function as safe does not inherently make it safe! Instead, it is like a promise you are making to Rust that it is safe. It is still your responsibility to make sure that promise is kept!
Calling Rust Functions from Other Languages
We can also use extern to create an interface that allows other languages to call Rust functions. Instead of creating a whole extern block, we add the extern keyword and specify the ABI to use just before the fn keyword for the relevant function. We also need to add an #[unsafe(no_mangle)] annotation to tell the Rust compiler not to mangle the name of this function. Mangling is when a compiler changes the name we’ve given a function to a different name that contains more information for other parts of the compilation process to consume but is less human readable. Every programming language compiler mangles names slightly differently, so for a Rust function to be nameable by other languages, we must disable the Rust compiler’s name mangling. This is unsafe because there might be name collisions across libraries without the built-in mangling, so it is our responsibility to make sure the name we choose is safe to export without mangling.
In the following example, we make the call_from_c function accessible from C code, after it’s compiled to a shared library and linked from C:
#[unsafe(no_mangle)]
pub extern "C" fn call_from_c() {
println!("Just called a Rust function from C!");
}
This usage of extern requires unsafe only in the attribute, not on the extern block.
Accessing or Modifying a Mutable Static Variable
In this book, we’ve not yet talked about global variables, which Rust does support but which can be problematic with Rust’s ownership rules. If two threads are accessing the same mutable global variable, it can cause a data race.
In Rust, global variables are called static variables. Listing 20-10 shows an example declaration and use of a static variable with a string slice as a value.
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("value is: {HELLO_WORLD}");
}Static variables are similar to constants, which we discussed in the “Declaring Constants” section in Chapter 3. The names of static variables are in SCREAMING_SNAKE_CASE by convention. Static variables can only store references with the 'static lifetime, which means the Rust compiler can figure out the lifetime and we aren’t required to annotate it explicitly. Accessing an immutable static variable is safe.
A subtle difference between constants and immutable static variables is that values in a static variable have a fixed address in memory. Using the value will always access the same data. Constants, on the other hand, are allowed to duplicate their data whenever they’re used. Another difference is that static variables can be mutable. Accessing and modifying mutable static variables is unsafe. Listing 20-11 shows how to declare, access, and modify a mutable static variable named COUNTER.
static mut COUNTER: u32 = 0;
/// SAFETY: Calling this from more than a single thread at a time is undefined
/// behavior, so you *must* guarantee you only call it from a single thread at
/// a time.
unsafe fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
unsafe {
// SAFETY: This is only called from a single thread in `main`.
add_to_count(3);
println!("COUNTER: {}", *(&raw const COUNTER));
}
}As with regular variables, we specify mutability using the mut keyword. Any code that reads or writes from COUNTER must be within an unsafe block. The code in Listing 20-11 compiles and prints COUNTER: 3 as we would expect because it’s single threaded. Having multiple threads access COUNTER would likely result in data races, so it is undefined behavior. Therefore, we need to mark the entire function as unsafe and document the safety limitation so that anyone calling the function knows what they are and are not allowed to do safely.
Whenever we write an unsafe function, it is idiomatic to write a comment starting with SAFETY and explaining what the caller needs to do to call the function safely. Likewise, whenever we perform an unsafe operation, it is idiomatic to write a comment starting with SAFETY to explain how the safety rules are upheld.
Additionally, the compiler will deny by default any attempt to create references to a mutable static variable through a compiler lint. You must either explicitly opt out of that lint’s protections by adding an #[allow(static_mut_refs)] annotation or access the mutable static variable via a raw pointer created with one of the raw borrow operators. That includes cases where the reference is created invisibly, as when it is used in the println! in this code listing. Requiring references to static mutable variables to be created via raw pointers helps make the safety requirements for using them more obvious.
With mutable data that is globally accessible, it’s difficult to ensure that there are no data races, which is why Rust considers mutable static variables to be unsafe. Where possible, it’s preferable to use the concurrency techniques and thread-safe smart pointers we discussed in Chapter 16 so that the compiler checks that data access from different threads is done safely.
Implementing an Unsafe Trait
We can use unsafe to implement an unsafe trait. A trait is unsafe when at least one of its methods has some invariant that the compiler can’t verify. We declare that a trait is unsafe by adding the unsafe keyword before trait and marking the implementation of the trait as unsafe too, as shown in Listing 20-12.
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}En utilisant unsafe impl, nous promettons que nous veillons aux invariantes que le compilateur ne peut pas vérifier.
As an example, recall the Send and Sync marker traits we discussed in the “Extensible Concurrency with Send and Sync” section in Chapter 16: The compiler implements these traits automatically if our types are composed entirely of other types that implement Send and Sync. If we implement a type that contains a type that does not implement Send or Sync, such as raw pointers, and we want to mark that type as Send or Sync, we must use unsafe. Rust can’t verify that our type upholds the guarantees that it can be safely sent across threads or accessed from multiple threads; therefore, we need to do those checks manually and indicate as such with unsafe.
Accessing Fields of a Union
The final action that works only with unsafe is accessing fields of a union. A union is similar to a struct, but only one declared field is used in a particular instance at one time. Unions are primarily used to interface with unions in C code. Accessing union fields is unsafe because Rust can’t guarantee the type of the data currently being stored in the union instance. You can learn more about unions in the Rust Reference.
Using Miri to Check Unsafe Code
When writing unsafe code, you might want to check that what you have written actually is safe and correct. One of the best ways to do that is to use Miri, an official Rust tool for detecting undefined behavior. Whereas the borrow checker is a static tool that works at compile time, Miri is a dynamic tool that works at runtime. It checks your code by running your program, or its test suite, and detecting when you violate the rules it understands about how Rust should work.
Using Miri requires a nightly build of Rust (which we talk about more in Appendix G: How Rust is Made and “Nightly Rust”). You can install both a nightly version of Rust and the Miri tool by typing rustup +nightly component add miri. This does not change what version of Rust your project uses; it only adds the tool to your system so you can use it when you want to. You can run Miri on a project by typing cargo +nightly miri run or cargo +nightly miri test.
For an example of how helpful this can be, consider what happens when we run it against Listing 20-7.
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
Miri correctly warns us that we’re casting an integer to a pointer, which might be a problem, but Miri can’t determine whether a problem exists because it doesn’t know how the pointer originated. Then, Miri returns an error where Listing 20-7 has undefined behavior because we have a dangling pointer. Thanks to Miri, we now know there is a risk of undefined behavior, and we can think about how to make the code safe. In some cases, Miri can even make recommendations about how to fix errors.
Miri doesn’t catch everything you might get wrong when writing unsafe code. Miri is a dynamic analysis tool, so it only catches problems with code that actually gets run. That means you will need to use it in conjunction with good testing techniques to increase your confidence about the unsafe code you have written. Miri also does not cover every possible way your code can be unsound.
Put another way: If Miri does catch a problem, you know there’s a bug, but just because Miri doesn’t catch a bug doesn’t mean there isn’t a problem. It can catch a lot, though. Try running it on the other examples of unsafe code in this chapter and see what it says!
You can learn more about Miri at its GitHub repository.
Using Unsafe Code Correctly
Using unsafe to use one of the five superpowers just discussed isn’t wrong or even frowned upon, but it is trickier to get unsafe code correct because the compiler can’t help uphold memory safety. When you have a reason to use unsafe code, you can do so, and having the explicit unsafe annotation makes it easier to track down the source of problems when they occur. Whenever you write unsafe code, you can use Miri to help you be more confident that the code you have written upholds Rust’s rules.
For a much deeper exploration of how to work effectively with unsafe Rust, read Rust’s official guide for unsafe, The Rustonomicon.
Les traits avancés
Les traits avancés
We first covered traits in the “Defining Shared Behavior with Traits” section in Chapter 10, but we didn’t discuss the more advanced details. Now that you know more about Rust, we can get into the nitty-gritty.
Defining Traits with Associated Types
Associated types connect a type placeholder with a trait such that the trait method definitions can use these placeholder types in their signatures. The implementor of a trait will specify the concrete type to be used instead of the placeholder type for the particular implementation. That way, we can define a trait that uses some types without needing to know exactly what those types are until the trait is implemented.
We’ve described most of the advanced features in this chapter as being rarely needed. Associated types are somewhere in the middle: They’re used more rarely than features explained in the rest of the book but more commonly than many of the other features discussed in this chapter.
One example of a trait with an associated type is the Iterator trait that the standard library provides. The associated type is named Item and stands in for the type of the values the type implementing the Iterator trait is iterating over. The definition of the Iterator trait is as shown in Listing 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Iterator trait that has an associated type ItemThe type Item is a placeholder, and the next method’s definition shows that it will return values of type Option<Self::Item>. Implementors of the Iterator trait will specify the concrete type for Item, and the next method will return an Option containing a value of that concrete type.
Associated types might seem like a similar concept to generics, in that the latter allow us to define a function without specifying what types it can handle. To examine the difference between the two concepts, we’ll look at an implementation of the Iterator trait on a type named Counter that specifies the Item type is u32:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// -- partie masquée ici --
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}This syntax seems comparable to that of generics. So, why not just define the Iterator trait with generics, as shown in Listing 20-14?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Iterator trait using genericsThe difference is that when using generics, as in Listing 20-14, we must annotate the types in each implementation; because we can also implement Iterator<String> for Counter or any other type, we could have multiple implementations of Iterator for Counter. In other words, when a trait has a generic parameter, it can be implemented for a type multiple times, changing the concrete types of the generic type parameters each time. When we use the next method on Counter, we would have to provide type annotations to indicate which implementation of Iterator we want to use.
With associated types, we don’t need to annotate types, because we can’t implement a trait on a type multiple times. In Listing 20-13 with the definition that uses associated types, we can choose what the type of Item will be only once because there can be only one impl Iterator for Counter. We don’t have to specify that we want an iterator of u32 values everywhere we call next on Counter.
Associated types also become part of the trait’s contract: Implementors of the trait must provide a type to stand in for the associated type placeholder. Associated types often have a name that describes how the type will be used, and documenting the associated type in the API documentation is a good practice.
Using Default Generic Parameters and Operator Overloading
When we use generic type parameters, we can specify a default concrete type for the generic type. This eliminates the need for implementors of the trait to specify a concrete type if the default type works. You specify a default type when declaring a generic type with the <PlaceholderType=ConcreteType> syntax.
A great example of a situation where this technique is useful is with operator overloading, in which you customize the behavior of an operator (such as +) in particular situations.
Rust doesn’t allow you to create your own operators or overload arbitrary operators. But you can overload the operations and corresponding traits listed in std::ops by implementing the traits associated with the operator. For example, in Listing 20-15, we overload the + operator to add two Point instances together. We do this by implementing the Add trait on a Point struct.
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Point { x: 1, y: 0 } + Point { x: 2, y: 3 },
Point { x: 3, y: 3 }
);
}Add trait to overload the + operator for Point instancesLa méthode add ajoute les valeurs x de deux instances de Point ainsi que les valeurs y de deux instances de Point pour créer un nouveau Point. Le trait Add a un type associé Output qui détermine le type retourné pour la méthode add.
Le type générique par défaut dans ce code est dans le trait Add. Voici sa définition :
#![allow(unused)]
fn main() {
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
}This code should look generally familiar: a trait with one method and an associated type. The new part is Rhs=Self: This syntax is called default type parameters. The Rhs generic type parameter (short for “right-hand side”) defines the type of the rhs parameter in the add method. If we don’t specify a concrete type for Rhs when we implement the Add trait, the type of Rhs will default to Self, which will be the type we’re implementing Add on.
Lorsque nous avons implémenté Add sur Point, nous avons utilisé la valeur par défaut de Rhs car nous voulions additionner deux instances de Point. Voyons un exemple d’implémentation du trait Add dans lequel nous souhaitons personnaliser le type Rhs plutôt que d’utiliser celui par défaut.
We have two structs, Millimeters and Meters, holding values in different units. This thin wrapping of an existing type in another struct is known as the newtype pattern, which we describe in more detail in the “Implementing External Traits with the Newtype Pattern” section. We want to add values in millimeters to values in meters and have the implementation of Add do the conversion correctly. We can implement Add for Millimeters with Meters as the Rhs, as shown in Listing 20-16.
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Add trait on Millimeters to add Millimeters and MetersPour additionner Millimetres et Metres, nous renseignons impl Add<Metres> pour régler la valeur du paramètre de type Rhs au lieu d’utiliser la valeur par défaut Self.
You’ll use default type parameters in two main ways:
- To extend a type without breaking existing code
- To allow customization in specific cases most users won’t need
The standard library’s Add trait is an example of the second purpose: Usually, you’ll add two like types, but the Add trait provides the ability to customize beyond that. Using a default type parameter in the Add trait definition means you don’t have to specify the extra parameter most of the time. In other words, a bit of implementation boilerplate isn’t needed, making it easier to use the trait.
The first purpose is similar to the second but in reverse: If you want to add a type parameter to an existing trait, you can give it a default to allow extension of the functionality of the trait without breaking the existing implementation code.
Disambiguating Between Identically Named Methods
Il n’y a rien en Rust qui empêche un trait d’avoir une méthode portant le même nom qu’une autre méthode d’un autre trait, ni ne vous empêche d’implémenter ces deux traits sur un même type. Il est aussi possible d’implémenter directement une méthode avec le même nom que celle présente dans les traits sur ce type.
When calling methods with the same name, you’ll need to tell Rust which one you want to use. Consider the code in Listing 20-17 where we’ve defined two traits, Pilot and Wizard, that both have a method called fly. We then implement both traits on a type Human that already has a method named fly implemented on it. Each fly method does something different.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {}fly method and are implemented on the Human type, and a fly method is implemented on Human directly.When we call fly on an instance of Human, the compiler defaults to calling the method that is directly implemented on the type, as shown in Listing 20-18.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
}fly on an instance of HumanL’exécution de ce code va afficher *agite frénétiquement ses bras*, ce qui démontre que Rust a appelé la méthode voler implémentée directement sur Humain.
To call the fly methods from either the Pilot trait or the Wizard trait, we need to use more explicit syntax to specify which fly method we mean. Listing 20-19 demonstrates this syntax.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
person.fly();
}fly method we want to callSpecifying the trait name before the method name clarifies to Rust which implementation of fly we want to call. We could also write Human::fly(&person), which is equivalent to the person.fly() that we used in Listing 20-19, but this is a bit longer to write if we don’t need to disambiguate.
L’exécution de ce code affichera ceci :
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Because the fly method takes a self parameter, if we had two types that both implement one trait, Rust could figure out which implementation of a trait to use based on the type of self.
However, associated functions that are not methods don’t have a self parameter. When there are multiple types or traits that define non-method functions with the same function name, Rust doesn’t always know which type you mean unless you use fully qualified syntax. For example, in Listing 20-20, we create a trait for an animal shelter that wants to name all baby dogs Spot. We make an Animal trait with an associated non-method function baby_name. The Animal trait is implemented for the struct Dog, on which we also provide an associated non-method function baby_name directly.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
}We implement the code for naming all puppies Spot in the baby_name associated function that is defined on Dog. The Dog type also implements the trait Animal, which describes characteristics that all animals have. Baby dogs are called puppies, and that is expressed in the implementation of the Animal trait on Dog in the baby_name function associated with the Animal trait.
Dans le main, nous faisons appel à la fonction Chien::nom_bebe, qui fait appel à la fonction associée directement définie sur Chien. Ce code affiche ceci :
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
This output isn’t what we wanted. We want to call the baby_name function that is part of the Animal trait that we implemented on Dog so that the code prints A baby dog is called a puppy. The technique of specifying the trait name that we used in Listing 20-19 doesn’t help here; if we change main to the code in Listing 20-21, we’ll get a compilation error.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}baby_name function from the Animal trait, but Rust doesn’t know which implementation to useComme Animal::nom_bebe n’a pas de paramètre self, et qu’il peut y avoir d’autres types qui implémentent le trait Animal, Rust ne peut pas savoir quelle implémentation de Animal::nom_bebe nous souhaitons utiliser. Nous obtenons alors cette erreur de compilation :
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
To disambiguate and tell Rust that we want to use the implementation of Animal for Dog as opposed to the implementation of Animal for some other type, we need to use fully qualified syntax. Listing 20-22 demonstrates how to use fully qualified syntax.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}baby_name function from the Animal trait as implemented on DogNous avons donné à Rust une annotation de type entre des chevrons, ce qui indique que nous souhaitons appeler la méthode nom_bebe du trait Animal telle qu’elle est implémentée sur Chien en indiquant que nous souhaitons traiter le type Chien comme étant un Animal pour cet appel de fonction. Ce code va désormais afficher ce que nous souhaitons :
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
In general, fully qualified syntax is defined as follows:
<Type as Trait>::function(receiver_if_method, next_arg, ...);For associated functions that aren’t methods, there would not be a receiver: There would only be the list of other arguments. You could use fully qualified syntax everywhere that you call functions or methods. However, you’re allowed to omit any part of this syntax that Rust can figure out from other information in the program. You only need to use this more verbose syntax in cases where there are multiple implementations that use the same name and Rust needs help to identify which implementation you want to call.
Using Supertraits
Sometimes you might write a trait definition that depends on another trait: For a type to implement the first trait, you want to require that type to also implement the second trait. You would do this so that your trait definition can make use of the associated items of the second trait. The trait your trait definition is relying on is called a supertrait of your trait.
For example, let’s say we want to make an OutlinePrint trait with an outline_print method that will print a given value formatted so that it’s framed in asterisks. That is, given a Point struct that implements the standard library trait Display to result in (x, y), when we call outline_print on a Point instance that has 1 for x and 3 for y, it should print the following:
**********
* *
* (1, 3) *
* *
**********
In the implementation of the outline_print method, we want to use the Display trait’s functionality. Therefore, we need to specify that the OutlinePrint trait will work only for types that also implement Display and provide the functionality that OutlinePrint needs. We can do that in the trait definition by specifying OutlinePrint: Display. This technique is similar to adding a trait bound to the trait. Listing 20-23 shows an implementation of the OutlinePrint trait.
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
fn main() {}OutlinePrint trait that requires the functionality from DisplayComme nous avons précisé que OutlinePrint nécessite le trait Display, nous pouvons utiliser la fonction to_string qui est automatiquement implémentée pour n’importe quel type qui implémente Display. Si nous avions essayé d’utiliser to_string sans ajouter un double-point et en renseignant le trait Display après le nom du trait, nous aurions alors obtenu une erreur qui nous informerait qu’il n’y a pas de méthode to_string pour le type &Self dans la portée courante.
Voyons ce qui ce passe lorsque nous essayons d’implémenter OutlinePrint sur un type qui n’implémente pas Display, comme c’est le cas de la structure Point :
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}We get an error saying that Display is required but not implemented:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
Pour régler cela, nous implémentons Display sur Point afin de répondre aux besoins de OutlinePrint, comme ceci :
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
use std::fmt;
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Then, implementing the OutlinePrint trait on Point will compile successfully, and we can call outline_print on a Point instance to display it within an outline of asterisks.
Implementing External Traits with the Newtype Pattern
In the “Implementing a Trait on a Type” section in Chapter 10, we mentioned the orphan rule that states we’re only allowed to implement a trait on a type if either the trait or the type, or both, are local to our crate. It’s possible to get around this restriction using the newtype pattern, which involves creating a new type in a tuple struct. (We covered tuple structs in the “Creating Different Types with Tuple Structs” section in Chapter 5.) The tuple struct will have one field and be a thin wrapper around the type for which we want to implement a trait. Then, the wrapper type is local to our crate, and we can implement the trait on the wrapper. Newtype is a term that originates from the Haskell programming language. There is no runtime performance penalty for using this pattern, and the wrapper type is elided at compile time.
As an example, let’s say we want to implement Display on Vec<T>, which the orphan rule prevents us from doing directly because the Display trait and the Vec<T> type are defined outside our crate. We can make a Wrapper struct that holds an instance of Vec<T>; then, we can implement Display on Wrapper and use the Vec<T> value, as shown in Listing 20-24.
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {w}");
}Wrapper type around Vec<String> to implement DisplayThe implementation of Display uses self.0 to access the inner Vec<T> because Wrapper is a tuple struct and Vec<T> is the item at index 0 in the tuple. Then, we can use the functionality of the Display trait on Wrapper.
The downside of using this technique is that Wrapper is a new type, so it doesn’t have the methods of the value it’s holding. We would have to implement all the methods of Vec<T> directly on Wrapper such that the methods delegate to self.0, which would allow us to treat Wrapper exactly like a Vec<T>. If we wanted the new type to have every method the inner type has, implementing the Deref trait on the Wrapper to return the inner type would be a solution (we discussed implementing the Deref trait in the “Treating Smart Pointers Like Regular References” section in Chapter 15). If we didn’t want the Wrapper type to have all the methods of the inner type—for example, to restrict the Wrapper type’s behavior—we would have to implement just the methods we do want manually.
This newtype pattern is also useful even when traits are not involved. Let’s switch focus and look at some advanced ways to interact with Rust’s type system.
Les types avancés
Les types avancés
The Rust type system has some features that we’ve so far mentioned but haven’t yet discussed. We’ll start by discussing newtypes in general as we examine why they are useful as types. Then, we’ll move on to type aliases, a feature similar to newtypes but with slightly different semantics. We’ll also discuss the ! type and dynamically sized types.
Type Safety and Abstraction with the Newtype Pattern
This section assumes you’ve read the earlier section “Implementing External Traits with the Newtype Pattern”. The newtype pattern is also useful for tasks beyond those we’ve discussed so far, including statically enforcing that values are never confused and indicating the units of a value. You saw an example of using newtypes to indicate units in Listing 20-16: Recall that the Millimeters and Meters structs wrapped u32 values in a newtype. If we wrote a function with a parameter of type Millimeters, we wouldn’t be able to compile a program that accidentally tried to call that function with a value of type Meters or a plain u32.
We can also use the newtype pattern to abstract away some implementation details of a type: The new type can expose a public API that is different from the API of the private inner type.
Newtypes can also hide internal implementation. For example, we could provide a People type to wrap a HashMap<i32, String> that stores a person’s ID associated with their name. Code using People would only interact with the public API we provide, such as a method to add a name string to the People collection; that code wouldn’t need to know that we assign an i32 ID to names internally. The newtype pattern is a lightweight way to achieve encapsulation to hide implementation details, which we discussed in the “Encapsulation that Hides Implementation Details” section in Chapter 18.
Type Synonyms and Type Aliases
Rust provides the ability to declare a type alias to give an existing type another name. For this we use the type keyword. For example, we can create the alias Kilometers to i32 like so:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Now the alias Kilometers is a synonym for i32; unlike the Millimeters and Meters types we created in Listing 20-16, Kilometers is not a separate, new type. Values that have the type Kilometers will be treated the same as values of type i32:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Because Kilometers and i32 are the same type, we can add values of both types and can pass Kilometers values to functions that take i32 parameters. However, using this method, we don’t get the type-checking benefits that we get from the newtype pattern discussed earlier. In other words, if we mix up Kilometers and i32 values somewhere, the compiler will not give us an error.
L’utilisation principale pour les synonymes de types est de réduire la répétition. Par exemple, nous pourrions avoir un type un peu long tel que celui-ci :
Box<dyn Fn() + Send + 'static>Writing this lengthy type in function signatures and as type annotations all over the code can be tiresome and error-prone. Imagine having a project full of code like that in Listing 20-25.
fn main() {
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));
fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {
// -- partie masquée ici --
}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
// -- partie masquée ici --
Box::new(|| ())
}
}A type alias makes this code more manageable by reducing the repetition. In Listing 20-26, we’ve introduced an alias named Thunk for the verbose type and can replace all uses of the type with the shorter alias Thunk.
fn main() {
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// -- partie masquée ici --
}
fn returns_long_type() -> Thunk {
// -- partie masquée ici --
Box::new(|| ())
}
}Thunk, to reduce repetitionThis code is much easier to read and write! Choosing a meaningful name for a type alias can help communicate your intent as well (thunk is a word for code to be evaluated at a later time, so it’s an appropriate name for a closure that gets stored).
Les alias de type sont couramment utilisés avec le type Result<T, E> pour réduire la répétition. Regardez le module std::io de la bibliothèque standard. Les opérations d’entrée/sortie retournent souvent un Result<T, E> pour gérer les situations où les opérations échouent. Cette bibliothèque a une structure std::io::Error qui représente toutes les erreurs possibles d’entrée/sortie. De nombreuses fonctions dans std::io vont retourner un Result<T, E> avec E qui est un alias pour std::io::Error, comme par exemple ces fonctions sont dans le trait Write :
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Le Result<..., Error> est répété plein de fois. C’est pourquoi std::io possède cette déclaration d’alias de type :
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Because this declaration is in the std::io module, we can use the fully qualified alias std::io::Result<T>; that is, a Result<T, E> with the E filled in as std::io::Error. The Write trait function signatures end up looking like this:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}The type alias helps in two ways: It makes code easier to write and it gives us a consistent interface across all of std::io. Because it’s an alias, it’s just another Result<T, E>, which means we can use any methods that work on Result<T, E> with it, as well as special syntax like the ? operator.
The Never Type That Never Returns
Rust has a special type named ! that’s known in type theory lingo as the empty type because it has no values. We prefer to call it the never type because it stands in the place of the return type when a function will never return. Here is an example:
fn bar() -> ! {
// -- partie masquée ici --
panic!();
}This code is read as “the function bar returns never.” Functions that return never are called diverging functions. We can’t create values of the type !, so bar can never possibly return.
But what use is a type you can never create values for? Recall the code from Listing 2-5, part of the number-guessing game; we’ve reproduced a bit of it here in Listing 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Devinez le nombre !");
let nombre_secret = rand::thread_rng().gen_range(1..=100);
println!("Le nombre secret est : {nombre_secret}");
loop {
println!("Veuillez entrer un nombre.");
let mut supposition = String::new();
// -- partie masquée ici --
io::stdin()
.read_line(&mut supposition)
.expect("Échec de la lecture de l'entrée utilisateur");
let supposition: u32 = match supposition.trim().parse() {
Ok(nombre) => nombre,
Err(_) => continue,
};
println!("Votre nombre : {supposition}");
// -- partie masquée ici --
match supposition.cmp(&nombre_secret) {
Ordering::Less => println!("C'est plus !"),
Ordering::Greater => println!("C'est moins !"),
Ordering::Equal => {
println!("Vous avez gagné !");
break;
}
}
}
}match with an arm that ends in continueAt the time, we skipped over some details in this code. In “The match Control Flow Construct” section in Chapter 6, we discussed that match arms must all return the same type. So, for example, the following code doesn’t work:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}The type of guess in this code would have to be an integer and a string, and Rust requires that guess have only one type. So, what does continue return? How were we allowed to return a u32 from one arm and have another arm that ends with continue in Listing 20-27?
Comme vous l’avez deviné, continue a une valeur !. Ainsi, lorsque Rust calcule le type de supposition, il regarde les deux branches, la première avec une valeur u32 et la seconde avec une valeur !. Comme ! ne peut jamais retourner de valeur, Rust décide alors que le type de supposition est u32.
Une façon classique de décrire ce comportement est de dire que les expressions du type ! peuvent être transformées dans n’importe quel type. Nous pouvons finir cette branche de match avec continue car continue ne retourne pas de valeur ; à la place, il retourne le contrôle en haut de la boucle, donc dans le cas d’un Err, nous n’assignons jamais de valeur à supposition.
The never type is useful with the panic! macro as well. Recall the unwrap function that we call on Option<T> values to produce a value or panic with this definition:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}In this code, the same thing happens as in the match in Listing 20-27: Rust sees that val has the type T and panic! has the type !, so the result of the overall match expression is T. This code works because panic! doesn’t produce a value; it ends the program. In the None case, we won’t be returning a value from unwrap, so this code is valid.
One final expression that has the type ! is a loop:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}Ici, la boucle ne se termine jamais, donc ! est la valeur de cette expression. En revanche, cela ne sera pas vrai si nous utilisons un break, car la boucle va s’arrêter lorsqu’elle rencontrera le break.
Dynamically Sized Types and the Sized Trait
Rust needs to know certain details about its types, such as how much space to allocate for a value of a particular type. This leaves one corner of its type system a little confusing at first: the concept of dynamically sized types. Sometimes referred to as DSTs or unsized types, these types let us write code using values whose size we can know only at runtime.
Let’s dig into the details of a dynamically sized type called str, which we’ve been using throughout the book. That’s right, not &str, but str on its own, is a DST. In many cases, such as when storing text entered by a user, we can’t know how long the string is until runtime. That means we can’t create a variable of type str, nor can we take an argument of type str. Consider the following code, which does not work:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust a besoin de savoir combien de mémoire allouer pour chaque valeur d’un type donné, et toutes les valeurs de ce type doivent utiliser la même quantité de mémoire. Si Rust nous avait autorisé à écrire ce code, ces deux valeurs str devraient occuper la même quantité de mémoire. Mais elles ont deux longueurs différentes : s1 prend 21 octets en mémoire alors que s2 en a besoin de 15. C’est pourquoi il est impossible de créer une variable qui stocke un type à taille dynamique.
So, what do we do? In this case, you already know the answer: We make the type of s1 and s2 string slice (&str) rather than str. Recall from the “String Slices” section in Chapter 4 that the slice data structure only stores the starting position and the length of the slice. So, although &T is a single value that stores the memory address of where the T is located, a string slice is two values: the address of the str and its length. As such, we can know the size of a string slice value at compile time: It’s twice the length of a usize. That is, we always know the size of a string slice, no matter how long the string it refers to is. In general, this is the way in which dynamically sized types are used in Rust: They have an extra bit of metadata that stores the size of the dynamic information. The golden rule of dynamically sized types is that we must always put values of dynamically sized types behind a pointer of some kind.
We can combine str with all kinds of pointers: for example, Box<str> or Rc<str>. In fact, you’ve seen this before but with a different dynamically sized type: traits. Every trait is a dynamically sized type we can refer to by using the name of the trait. In the “Using Trait Objects to Abstract over Shared Behavior” section in Chapter 18, we mentioned that to use traits as trait objects, we must put them behind a pointer, such as &dyn Trait or Box<dyn Trait> (Rc<dyn Trait> would work too).
To work with DSTs, Rust provides the Sized trait to determine whether or not a type’s size is known at compile time. This trait is automatically implemented for everything whose size is known at compile time. In addition, Rust implicitly adds a bound on Sized to every generic function. That is, a generic function definition like this:
fn generic<T>(t: T) {
// -- partie masquée ici --
}is actually treated as though we had written this:
fn generic<T: Sized>(t: T) {
// -- partie masquée ici --
}Par défaut, les fonctions génériques vont fonctionner uniquement sur des types qui ont une taille connue à la compilation. Cependant, vous pouvez utiliser la syntaxe spéciale suivante pour éviter cette restriction :
fn generic<T: ?Sized>(t: &T) {
// -- partie masquée ici --
}A trait bound on ?Sized means “T may or may not be Sized,” and this notation overrides the default that generic types must have a known size at compile time. The ?Trait syntax with this meaning is only available for Sized, not any other traits.
Remarquez aussi que nous avons changé le type du paramètre t de T en &T. Comme ce type pourrait ne pas être un Sized, nous devons l’utiliser via un pointeur d’une sorte ou d’une autre. Dans ce cas, nous avons choisi une référence.
Next, we’ll talk about functions and closures!
Les fonctions et fermetures avancées
Les fonctions et fermetures avancées
Dans cette section, nous allons explorer quelques fonctionnalités avancées liées aux fonctions et aux fermetures, y compris les pointeurs de fonctions et la capacité de retourner des fermetures.
Function Pointers
We’ve talked about how to pass closures to functions; you can also pass regular functions to functions! This technique is useful when you want to pass a function you’ve already defined rather than defining a new closure. Functions coerce to the type fn (with a lowercase f), not to be confused with the Fn closure trait. The fn type is called a function pointer. Passing functions with function pointers will allow you to use functions as arguments to other functions.
The syntax for specifying that a parameter is a function pointer is similar to that of closures, as shown in Listing 20-28, where we’ve defined a function add_one that adds 1 to its parameter. The function do_twice takes two parameters: a function pointer to any function that takes an i32 parameter and returns an i32, and one i32 value. The do_twice function calls the function f twice, passing it the arg value, then adds the two function call results together. The main function calls do_twice with the arguments add_one and 5.
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {answer}");
}fn type to accept a function pointer as an argumentCe code affiche La réponse est : 12. Nous avons précisé que le paramètre f dans le_faire_deux_fois est une fn qui prend en argument un paramètre du type i32 et retourne un i32. Nous pouvons ensuite appeler f dans le corps de le_faire_deux_fois. Dans main, nous pouvons envoyer le nom de la fonction ajouter_un dans le premier argument de le_faire_deux_fois.
Contrairement aux fermetures, fn est un type plutôt qu’un trait, donc nous indiquons fn directement comme type de paramètre plutôt que de déclarer un paramètre de type générique avec un des traits Fn comme trait lié.
Function pointers implement all three of the closure traits (Fn, FnMut, and FnOnce), meaning you can always pass a function pointer as an argument for a function that expects a closure. It’s best to write functions using a generic type and one of the closure traits so that your functions can accept either functions or closures.
That said, one example of where you would want to only accept fn and not closures is when interfacing with external code that doesn’t have closures: C functions can accept functions as arguments, but C doesn’t have closures.
As an example of where you could use either a closure defined inline or a named function, let’s look at a use of the map method provided by the Iterator trait in the standard library. To use the map method to turn a vector of numbers into a vector of strings, we could use a closure, as in Listing 20-29.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}map method to convert numbers to stringsOr we could name a function as the argument to map instead of the closure. Listing 20-30 shows what this would look like.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}String::to_string function with the map method to convert numbers to stringsNote that we must use the fully qualified syntax that we talked about in the “Advanced Traits” section because there are multiple functions available named to_string.
Here, we’re using the to_string function defined in the ToString trait, which the standard library has implemented for any type that implements Display.
Recall from the “Enum Values” section in Chapter 6 that the name of each enum variant that we define also becomes an initializer function. We can use these initializer functions as function pointers that implement the closure traits, which means we can specify the initializer functions as arguments for methods that take closures, as seen in Listing 20-31.
fn main() {
enum Status {
Value(u32),
Stop,
}
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
}map method to create a Status instance from numbersHere, we create Status::Value instances using each u32 value in the range that map is called on by using the initializer function of Status::Value. Some people prefer this style and some people prefer to use closures. They compile to the same code, so use whichever style is clearer to you.
Returning Closures
Closures are represented by traits, which means you can’t return closures directly. In most cases where you might want to return a trait, you can instead use the concrete type that implements the trait as the return value of the function. However, you can’t usually do that with closures because they don’t have a concrete type that is returnable; you’re not allowed to use the function pointer fn as a return type if the closure captures any values from its scope, for example.
Instead, you will normally use the impl Trait syntax we learned about in Chapter 10. You can return any function type, using Fn, FnOnce, and FnMut. For example, the code in Listing 20-32 will compile just fine.
#![allow(unused)]
fn main() {
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
}impl Trait syntaxHowever, as we noted in the “Inferring and Annotating Closure Types” section in Chapter 13, each closure is also its own distinct type. If you need to work with multiple functions that have the same signature but different implementations, you will need to use a trait object for them. Consider what happens if you write code like that shown in Listing 20-33.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}Vec<T> of closures defined by functions that return impl Fn typesHere we have two functions, returns_closure and returns_initialized_closure, which both return impl Fn(i32) -> i32. Notice that the closures that they return are different, even though they implement the same type. If we try to compile this, Rust lets us know that it won’t work:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
The error message tells us that whenever we return an impl Trait, Rust creates a unique opaque type, a type where we cannot see into the details of what Rust constructs for us, nor can we guess the type Rust will generate to write ourselves. So, even though these functions return closures that implement the same trait, Fn(i32) -> i32, the opaque types Rust generates for each are distinct. (This is similar to how Rust produces different concrete types for distinct async blocks even when they have the same output type, as we saw in “The Pin Type and the Unpin Trait” in Chapter 17.) We have seen a solution to this problem a few times now: We can use a trait object, as in Listing 20-34.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}Vec<T> of closures defined by functions that return Box<dyn Fn> so that they have the same typeThis code will compile just fine. For more about trait objects, refer to the section “Using Trait Objects To Abstract over Shared Behavior” in Chapter 18.
Next, let’s look at macros!
Les macros
Les macros
We’ve used macros like println! throughout this book, but we haven’t fully explored what a macro is and how it works. The term macro refers to a family of features in Rust—declarative macros with macro_rules! and three kinds of procedural macros:
- Custom
#[derive]macros that specify code added with thederiveattribute used on structs and enums - Attribute-like macros that define custom attributes usable on any item
- Function-like macros that look like function calls but operate on the tokens specified as their argument
Nous allons voir chacune d’entre elles à leur tour, mais avant, posons-nous la question de pourquoi nous avons besoin de macros alors que nous avons déjà les fonctions.
The Difference Between Macros and Functions
Fundamentally, macros are a way of writing code that writes other code, which is known as metaprogramming. In Appendix C, we discuss the derive attribute, which generates an implementation of various traits for you. We’ve also used the println! and vec! macros throughout the book. All of these macros expand to produce more code than the code you’ve written manually.
Metaprogramming is useful for reducing the amount of code you have to write and maintain, which is also one of the roles of functions. However, macros have some additional powers that functions don’t have.
A function signature must declare the number and type of parameters the function has. Macros, on the other hand, can take a variable number of parameters: We can call println!("hello") with one argument or println!("hello {}", name) with two arguments. Also, macros are expanded before the compiler interprets the meaning of the code, so a macro can, for example, implement a trait on a given type. A function can’t, because it gets called at runtime and a trait needs to be implemented at compile time.
Le désavantage d’implémenter une macro par rapport à une fonction est que les définitions de macros sont plus complexes que les définitions de fonction car vous écrivez du code Rust qui écrit lui-même du code Rust. À cause de cette approche, les définitions de macro sont généralement plus difficiles à lire, à comprendre et à maintenir que les définitions de fonctions.
Another important difference between macros and functions is that you must define macros or bring them into scope before you call them in a file, as opposed to functions you can define anywhere and call anywhere.
Declarative Macros for General Metaprogramming
The most widely used form of macros in Rust is the declarative macro. These are also sometimes referred to as “macros by example,” “macro_rules! macros,” or just plain “macros.” At their core, declarative macros allow you to write something similar to a Rust match expression. As discussed in Chapter 6, match expressions are control structures that take an expression, compare the resultant value of the expression to patterns, and then run the code associated with the matching pattern. Macros also compare a value to patterns that are associated with particular code: In this situation, the value is the literal Rust source code passed to the macro; the patterns are compared with the structure of that source code; and the code associated with each pattern, when matched, replaces the code passed to the macro. This all happens during compilation.
Pour définir une macro, il faut utiliser la construction macro_rules!. Explorons l’utilisation de macro_rules! en observant comment la macro vec! est définie. Le chapitre 8 nous a permis de comprendre comment utiliser la macro vec! pour créer un nouveau vecteur avec des valeurs précises. Par exemple, la macro suivante crée un nouveau vecteur qui contient trois entiers :
#![allow(unused)]
fn main() {
let v: Vec<u32> = vec![1, 2, 3];
}Nous aurions pu aussi utiliser la macro vec! pour créer un vecteur de deux entiers ou un vecteur de cinq slices de chaînes de caractères. Nous n’aurions pas pu utiliser une fonction pour faire la même chose car nous n’aurions pas pu connaître le nombre ou le type des valeurs au départ.
Listing 20-35 shows a slightly simplified definition of the vec! macro.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}vec! macro definitionNote: The actual definition of the vec! macro in the standard library includes code to pre-allocate the correct amount of memory up front. That code is an optimization that we don’t include here, to make the example simpler.
L’annotation #[macro_export] indique que cette macro doit être disponible à chaque fois que la crate dans laquelle la macro est définie est importée dans la portée. Sans cette annotation, la macro ne pourrait pas être importée dans la portée.
We then start the macro definition with macro_rules! and the name of the macro we’re defining without the exclamation mark. The name, in this case vec, is followed by curly brackets denoting the body of the macro definition.
La structure dans le corps de vec! ressemble à la structure d’une expression match. Ici nous avons une branche avec le motif ( $( $x:expr ), * ), suivie par => et le code du bloc associé à ce motif. Si le motif correspond, le bloc de code associé sera déployé. Etant donné que c’est le seul motif dans cette macro, il n’y a qu’une seule bonne façon d’y correspondre ; tout autre motif va déboucher sur une erreur. Des macros plus complexes auront plus qu’une seule branche.
Valid pattern syntax in macro definitions is different from the pattern syntax covered in Chapter 19 because macro patterns are matched against Rust code structure rather than values. Let’s walk through what the pattern pieces in Listing 20-29 mean; for the full macro pattern syntax, see the Rust Reference.
First, we use a set of parentheses to encompass the whole pattern. We use a dollar sign ($) to declare a variable in the macro system that will contain the Rust code matching the pattern. The dollar sign makes it clear this is a macro variable as opposed to a regular Rust variable. Next comes a set of parentheses that captures values that match the pattern within the parentheses for use in the replacement code. Within $() is $x:expr, which matches any Rust expression and gives the expression the name $x.
The comma following $() indicates that a literal comma separator character must appear between each instance of the code that matches the code in $(). The * specifies that the pattern matches zero or more of whatever precedes the *.
Lorsque nous faisons appel à cette macro avec vec![1, 2, 3];, le motif $x correspond à trois reprises avec les trois expressions 1, 2, et 3.
Maintenant, penchons-nous sur le motif dans le corps du code associé à cette branche : temp_vec.push() dans le $()* est généré pour chacune des parties qui correspondent au $() dans le motif pour zéro ou plus de fois, en fonction de combien de fois le motif correspond. Le $x est remplacé par chaque expression qui correspond. Lorsque nous faisons appel à cette macro avec vec![1, 2, 3];, le code généré qui remplace cet appel de macro ressemblera à ceci :
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Nous avons défini une macro qui peut prendre n’importe quel nombre d’arguments de n’importe quel type et qui peut générer du code pour créer un vecteur qui contient les éléments renseignés.
To learn more about how to write macros, consult the online documentation or other resources, such as “The Little Book of Rust Macros” started by Daniel Keep and continued by Lukas Wirth.
Procedural Macros for Generating Code from Attributes
The second form of macros is the procedural macro, which acts more like a function (and is a type of procedure). Procedural macros accept some code as an input, operate on that code, and produce some code as an output rather than matching against patterns and replacing the code with other code as declarative macros do. The three kinds of procedural macros are custom derive, attribute-like, and function-like, and all work in a similar fashion.
When creating procedural macros, the definitions must reside in their own crate with a special crate type. This is for complex technical reasons that we hope to eliminate in the future. In Listing 20-36, we show how to define a procedural macro, where some_attribute is a placeholder for using a specific macro variety.
use proc_macro::TokenStream;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}The function that defines a procedural macro takes a TokenStream as an input and produces a TokenStream as an output. The TokenStream type is defined by the proc_macro crate that is included with Rust and represents a sequence of tokens. This is the core of the macro: The source code that the macro is operating on makes up the input TokenStream, and the code the macro produces is the output TokenStream. The function also has an attribute attached to it that specifies which kind of procedural macro we’re creating. We can have multiple kinds of procedural macros in the same crate.
Let’s look at the different kinds of procedural macros. We’ll start with a custom derive macro and then explain the small dissimilarities that make the other forms different.
Custom derive Macros
Let’s create a crate named hello_macro that defines a trait named HelloMacro with one associated function named hello_macro. Rather than making our users implement the HelloMacro trait for each of their types, we’ll provide a procedural macro so that users can annotate their type with #[derive(HelloMacro)] to get a default implementation of the hello_macro function. The default implementation will print Hello, Macro! My name is TypeName! where TypeName is the name of the type on which this trait has been defined. In other words, we’ll write a crate that enables another programmer to write code like Listing 20-37 using our crate.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}Ce code va afficher Hello, Macro ! Mon nom est Pancakes ! lorsque vous en aurez fini. La première étape consiste à créer une nouvelle crate de bibliothèque, comme ceci :
$ cargo new hello_macro --lib
Next, in Listing 20-38, we’ll define the HelloMacro trait and its associated function.
pub trait HelloMacro {
fn hello_macro();
}derive macroWe have a trait and its function. At this point, our crate user could implement the trait to achieve the desired functionality, as in Listing 20-39.
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}HelloMacro traitCependant, l’utilisateur doit écrire le bloc d’implémentation pour chacun des types qu’il souhaite utiliser avec hello_macro ; nous souhaitons lui épargner ce travail.
De plus, nous ne pouvons pas encore fournir la fonction hello_macro avec l’implémentation par défaut qui va afficher le nom du type du trait sur lequel nous l’implémentons : Rust n’est pas réflexif, donc il ne peut pas connaître le nom du type à l’exécution. Nous avons besoin d’une macro pour générer le code à la compilation.
The next step is to define the procedural macro. At the time of this writing, procedural macros need to be in their own crate. Eventually, this restriction might be lifted. The convention for structuring crates and macro crates is as follows: For a crate named foo, a custom derive procedural macro crate is called foo_derive. Let’s start a new crate called hello_macro_derive inside our hello_macro project:
$ cargo new hello_macro_derive --lib
Nos deux crates sont étroitement liées, donc nous créons la crate de macro procédurale à l’intérieur du répertoire de notre crate hello_macro. Si nous changeons la définition du trait dans hello_macro, nous aurons aussi à changer l’implémentation de la macro procédurale dans hello_macro_derive. Les deux crates vont devoir être publiées séparément, et les développeurs qui vont utiliser ces crates vont avoir besoin d’ajouter les deux dépendances et les importer dans la portée. Nous pourrions plutôt faire en sorte que la crate hello_macro utilise hello_macro_derive comme dépendance et ré-exporter le code de la macro procédurale. Cependant, la façon dont nous avons structuré le projet donne la possibilité aux développeurs d’utiliser hello_macro même s’ils ne veulent pas la fonctionnalité derive.
We need to declare the hello_macro_derive crate as a procedural macro crate. We’ll also need functionality from the syn and quote crates, as you’ll see in a moment, so we need to add them as dependencies. Add the following to the Cargo.toml file for hello_macro_derive:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
To start defining the procedural macro, place the code in Listing 20-40 into your src/lib.rs file for the hello_macro_derive crate. Note that this code won’t compile until we add a definition for the impl_hello_macro function.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}Notice that we’ve split the code into the hello_macro_derive function, which is responsible for parsing the TokenStream, and the impl_hello_macro function, which is responsible for transforming the syntax tree: This makes writing a procedural macro more convenient. The code in the outer function (hello_macro_derive in this case) will be the same for almost every procedural macro crate you see or create. The code you specify in the body of the inner function (impl_hello_macro in this case) will be different depending on your procedural macro’s purpose.
We’ve introduced three new crates: proc_macro, syn, and quote. The proc_macro crate comes with Rust, so we didn’t need to add that to the dependencies in Cargo.toml. The proc_macro crate is the compiler’s API that allows us to read and manipulate Rust code from our code.
The syn crate parses Rust code from a string into a data structure that we can perform operations on. The quote crate turns syn data structures back into Rust code. These crates make it much simpler to parse any sort of Rust code we might want to handle: Writing a full parser for Rust code is no simple task.
The hello_macro_derive function will be called when a user of our library specifies #[derive(HelloMacro)] on a type. This is possible because we’ve annotated the hello_macro_derive function here with proc_macro_derive and specified the name HelloMacro, which matches our trait name; this is the convention most procedural macros follow.
The hello_macro_derive function first converts the input from a TokenStream to a data structure that we can then interpret and perform operations on. This is where syn comes into play. The parse function in syn takes a TokenStream and returns a DeriveInput struct representing the parsed Rust code. Listing 20-41 shows the relevant parts of the DeriveInput struct we get from parsing the struct Pancakes; string.
DeriveInput {
// -- partie masquée ici --
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}DeriveInput instance we get when parsing the code that has the macro’s attribute in Listing 20-37The fields of this struct show that the Rust code we’ve parsed is a unit struct with the ident (identifier, meaning the name) of Pancakes. There are more fields on this struct for describing all sorts of Rust code; check the syn documentation for DeriveInput for more information.
Soon we’ll define the impl_hello_macro function, which is where we’ll build the new Rust code we want to include. But before we do, note that the output for our derive macro is also a TokenStream. The returned TokenStream is added to the code that our crate users write, so when they compile their crate, they’ll get the extra functionality that we provide in the modified TokenStream.
Vous avez peut-être remarqué que nous faisons appel à unwrap pour faire paniquer la fonction hello_macro_derive si l’appel à la fonction syn::parse que nous faisons échoue. Il est nécessaire de faire paniquer notre macro procédurale si elle rencontre des erreurs car les fonctions proc_macro_derive doivent retourner un TokenStream plutôt qu’un Result pour se conformer à l’API de la macro procédurale. Nous avons simplifié cet exemple en utilisant unwrap ; dans du code en production, vous devriez renseigner des messages d’erreur plus précis sur ce qui s’est mal passé en utilisant panic! ou expect.
Now that we have the code to turn the annotated Rust code from a TokenStream into a DeriveInput instance, let’s generate the code that implements the HelloMacro trait on the annotated type, as shown in Listing 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}HelloMacro trait using the parsed Rust codeWe get an Ident struct instance containing the name (identifier) of the annotated type using ast.ident. The struct in Listing 20-41 shows that when we run the impl_hello_macro function on the code in Listing 20-37, the ident we get will have the ident field with a value of "Pancakes". Thus, the name variable in Listing 20-42 will contain an Ident struct instance that, when printed, will be the string "Pancakes", the name of the struct in Listing 20-37.
The quote! macro lets us define the Rust code that we want to return. The compiler expects something different from the direct result of the quote! macro’s execution, so we need to convert it to a TokenStream. We do this by calling the into method, which consumes this intermediate representation and returns a value of the required TokenStream type.
The quote! macro also provides some very cool templating mechanics: We can enter #name, and quote! will replace it with the value in the variable name. You can even do some repetition similar to the way regular macros work. Check out the quote crate’s docs for a thorough introduction.
We want our procedural macro to generate an implementation of our HelloMacro trait for the type the user annotated, which we can get by using #name. The trait implementation has the one function hello_macro, whose body contains the functionality we want to provide: printing Hello, Macro! My name is and then the name of the annotated type.
The stringify! macro used here is built into Rust. It takes a Rust expression, such as 1 + 2, and at compile time turns the expression into a string literal, such as "1 + 2". This is different from format! or println!, which are macros that evaluate the expression and then turn the result into a String. There is a possibility that the #name input might be an expression to print literally, so we use stringify!. Using stringify! also saves an allocation by converting #name to a string literal at compile time.
At this point, cargo build should complete successfully in both hello_macro and hello_macro_derive. Let’s hook up these crates to the code in Listing 20-37 to see the procedural macro in action! Create a new binary project in your projects directory using cargo new pancakes. We need to add hello_macro and hello_macro_derive as dependencies in the pancakes crate’s Cargo.toml. If you’re publishing your versions of hello_macro and hello_macro_derive to crates.io, they would be regular dependencies; if not, you can specify them as path dependencies as follows:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Put the code in Listing 20-37 into src/main.rs, and run cargo run: It should print Hello, Macro! My name is Pancakes!. The implementation of the HelloMacro trait from the procedural macro was included without the pancakes crate needing to implement it; the #[derive(HelloMacro)] added the trait implementation.
Next, let’s explore how the other kinds of procedural macros differ from custom derive macros.
Attribute-Like Macros
Attribute-like macros are similar to custom derive macros, but instead of generating code for the derive attribute, they allow you to create new attributes. They’re also more flexible: derive only works for structs and enums; attributes can be applied to other items as well, such as functions. Here’s an example of using an attribute-like macro. Say you have an attribute named route that annotates functions when using a web application framework:
#[route(GET, "/")]
fn index() {Cet attribut #[chemin] sera défini par l’environnement de développement comme étant une macro procédurale. La signature de la fonction de définition de la macro ressemblera à ceci :
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Maintenant, nous avons deux paramètres de type TokenStream. Le premier correspond au contenu de l’attribut : la partie GET, "/". Le second est le corps de l’élément sur lequel cet attribut sera appliqué : dans notre cas, fn index() {} et le reste du corps de la fonction.
Other than that, attribute-like macros work the same way as custom derive macros: You create a crate with the proc-macro crate type and implement a function that generates the code you want!
Function-Like Macros
Function-like macros define macros that look like function calls. Similarly to macro_rules! macros, they’re more flexible than functions; for example, they can take an unknown number of arguments. However, macro_rules! macros can only be defined using the match-like syntax we discussed in the “Declarative Macros for General Metaprogramming” section earlier. Function-like macros take a TokenStream parameter, and their definition manipulates that TokenStream using Rust code as the other two types of procedural macros do. An example of a function-like macro is an sql! macro that might be called like so:
let sql = sql!(SELECT * FROM posts WHERE id=1);Cette macro devrait interpréter l’instruction SQL qu’on lui envoie et vérifier si elle est syntaxiquement correcte, ce qui est un procédé bien plus complexe que ce qu’une macro macro_rules! peut faire. La macro sql! sera définie comme ceci :
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {This definition is similar to the custom derive macro’s signature: We receive the tokens that are inside the parentheses and return the code we wanted to generate.
Résumé
Whew! Now you have some Rust features in your toolbox that you likely won’t use often, but you’ll know they’re available in very particular circumstances. We’ve introduced several complex topics so that when you encounter them in error message suggestions or in other people’s code, you’ll be able to recognize these concepts and syntax. Use this chapter as a reference to guide you to solutions.
Au chapitre suivant, nous allons mettre en pratique tout ce que nous avons appris dans ce livre en l’appliquant à un nouveau projet !
Projet final : construire un serveur web multitâches
Ce fut un long voyage, mais nous avons atteint la fin de ce livre. Dans ce chapitre, nous allons construire un nouveau projet ensemble pour mettre en application certains concepts que nous avons vus dans les derniers chapitres, et aussi pour récapituler quelques leçons précédentes.
For our final project, we’ll make a web server that says “Hello!” and looks like Figure 21-1 in a web browser.
Here is our plan for building the web server:
- Learn a bit about TCP and HTTP.
- Listen for TCP connections on a socket.
- Parse a small number of HTTP requests.
- Create a proper HTTP response.
- Improve the throughput of our server with a thread pool.
Figure 21-1: Our final shared project
Before we get started, we should mention two details. First, the method we’ll use won’t be the best way to build a web server with Rust. Community members have published a number of production-ready crates available at crates.io that provide more complete web server and thread pool implementations than we’ll build. However, our intention in this chapter is to help you learn, not to take the easy route. Because Rust is a systems programming language, we can choose the level of abstraction we want to work with and can go to a lower level than is possible or practical in other languages.
Second, we will not be using async and await here. Building a thread pool is a big enough challenge on its own, without adding in building an async runtime! However, we will note how async and await might be applicable to some of the same problems we will see in this chapter. Ultimately, as we noted back in Chapter 17, many async runtimes use thread pools for managing their work.
We’ll therefore write the basic HTTP server and thread pool manually so that you can learn the general ideas and techniques behind the crates you might use in the future.
Développer un serveur web monotâche
Développer un serveur web monotâche
Nous allons commencer par faire fonctionner un serveur web monotâche. Avant de commencer, faisons un survol rapide des protocoles utilisés dans les serveurs web. Les détails de ces protocoles ne sont pas le sujet de ce livre, mais un rapide aperçu vous donnera les informations dont vous avez besoin.
The two main protocols involved in web servers are Hypertext Transfer Protocol (HTTP) and Transmission Control Protocol (TCP). Both protocols are request-response protocols, meaning a client initiates requests and a server listens to the requests and provides a response to the client. The contents of those requests and responses are defined by the protocols.
TCP est le protocole le plus bas-niveau qui décrit les détails de comment une information passe d’un serveur à un autre mais ne précise pas ce qu’est cette information. HTTP est construit sur TCP en définissant le contenu des requêtes et des réponses. Il est techniquement possible d’utiliser HTTP avec d’autres protocoles, mais dans la grande majorité des cas, HTTP envoie ses données via TCP. Nous allons travailler avec les octets bruts des requêtes et des réponses de TCP et HTTP.
Listening to the TCP Connection
Notre serveur web a besoin d’écouter les connexions TCP, donc cela sera la première partie sur laquelle nous travaillerons. La bibliothèque standard offre un module std::net qui nous permet de faire ceci. Créons un nouveau projet de manière habituelle :
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Now enter the code in Listing 21-1 in src/main.rs to start. This code will listen at the local address 127.0.0.1:7878 for incoming TCP streams. When it gets an incoming stream, it will print Connection established!.
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("Connection established!");
}
}Using TcpListener, we can listen for TCP connections at the address 127.0.0.1:7878. In the address, the section before the colon is an IP address representing your computer (this is the same on every computer and doesn’t represent the authors’ computer specifically), and 7878 is the port. We’ve chosen this port for two reasons: HTTP isn’t normally accepted on this port, so our server is unlikely to conflict with any other web server you might have running on your machine, and 7878 is rust typed on a telephone.
The bind function in this scenario works like the new function in that it will return a new TcpListener instance. The function is called bind because, in networking, connecting to a port to listen to is known as “binding to a port.”
The bind function returns a Result<T, E>, which indicates that it’s possible for binding to fail, for example, if we ran two instances of our program and so had two programs listening to the same port. Because we’re writing a basic server just for learning purposes, we won’t worry about handling these kinds of errors; instead, we use unwrap to stop the program if errors happen.
The incoming method on TcpListener returns an iterator that gives us a sequence of streams (more specifically, streams of type TcpStream). A single stream represents an open connection between the client and the server. Connection is the name for the full request and response process in which a client connects to the server, the server generates a response, and the server closes the connection. As such, we will read from the TcpStream to see what the client sent and then write our response to the stream to send data back to the client. Overall, this for loop will process each connection in turn and produce a series of streams for us to handle.
For now, our handling of the stream consists of calling unwrap to terminate our program if the stream has any errors; if there aren’t any errors, the program prints a message. We’ll add more functionality for the success case in the next listing. The reason we might receive errors from the incoming method when a client connects to the server is that we’re not actually iterating over connections. Instead, we’re iterating over connection attempts. The connection might not be successful for a number of reasons, many of them operating system specific. For example, many operating systems have a limit to the number of simultaneous open connections they can support; new connection attempts beyond that number will produce an error until some of the open connections are closed.
Let’s try running this code! Invoke cargo run in the terminal and then load 127.0.0.1:7878 in a web browser. The browser should show an error message like “Connection reset” because the server isn’t currently sending back any data. But when you look at your terminal, you should see several messages that were printed when the browser connected to the server!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Sometimes you’ll see multiple messages printed for one browser request; the reason might be that the browser is making a request for the page as well as a request for other resources, like the favicon.ico icon that appears in the browser tab.
It could also be that the browser is trying to connect to the server multiple times because the server isn’t responding with any data. When stream goes out of scope and is dropped at the end of the loop, the connection is closed as part of the drop implementation. Browsers sometimes deal with closed connections by retrying, because the problem might be temporary.
Browsers also sometimes open multiple connections to the server without sending any requests so that if they do later send requests, those requests can happen more quickly. When this occurs, our server will see each connection, regardless of whether there are any requests over that connection. Many versions of Chrome-based browsers do this, for example; you can disable that optimization by using private browsing mode or using a different browser.
The important factor is that we’ve successfully gotten a handle to a TCP connection!
Remember to stop the program by pressing ctrl-C when you’re done running a particular version of the code. Then, restart the program by invoking the cargo run command after you’ve made each set of code changes to make sure you’re running the newest code.
Reading the Request
Let’s implement the functionality to read the request from the browser! To separate the concerns of first getting a connection and then taking some action with the connection, we’ll start a new function for processing connections. In this new handle_connection function, we’ll read data from the TCP stream and print it so that we can see the data being sent from the browser. Change the code to look like Listing 21-2.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("Request: {http_request:#?}");
}TcpStream and printing the dataWe bring std::io::BufReader and std::io::prelude into scope to get access to traits and types that let us read from and write to the stream. In the for loop in the main function, instead of printing a message that says we made a connection, we now call the new handle_connection function and pass the stream to it.
In the handle_connection function, we create a new BufReader instance that wraps a reference to the stream. The BufReader adds buffering by managing calls to the std::io::Read trait methods for us.
We create a variable named http_request to collect the lines of the request the browser sends to our server. We indicate that we want to collect these lines in a vector by adding the Vec<_> type annotation.
BufReader implements the std::io::BufRead trait, which provides the lines method. The lines method returns an iterator of Result<String, std::io::Error> by splitting the stream of data whenever it sees a newline byte. To get each String, we map and unwrap each Result. The Result might be an error if the data isn’t valid UTF-8 or if there was a problem reading from the stream. Again, a production program should handle these errors more gracefully, but we’re choosing to stop the program in the error case for simplicity.
The browser signals the end of an HTTP request by sending two newline characters in a row, so to get one request from the stream, we take lines until we get a line that is the empty string. Once we’ve collected the lines into the vector, we’re printing them out using pretty debug formatting so that we can take a look at the instructions the web browser is sending to our server.
Essayons ce code ! Démarrez le programme et faites à nouveau une requête dans un navigateur web. Notez que nous obtenons toujours une page d’erreur dans le navigateur web, mais que la sortie de notre programme dans le terminal devrait ressembler à ceci :
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
Depending on your browser, you might get slightly different output. Now that we’re printing the request data, we can see why we get multiple connections from one browser request by looking at the path after GET in the first line of the request. If the repeated connections are all requesting /, we know the browser is trying to fetch / repeatedly because it’s not getting a response from our program.
Décomposons les données de cette requête pour comprendre ce que le navigateur demande à notre programme.
Looking More Closely at an HTTP Request
HTTP is a text-based protocol, and a request takes this format:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
The first line is the request line that holds information about what the client is requesting. The first part of the request line indicates the method being used, such as GET or POST, which describes how the client is making this request. Our client used a GET request, which means it is asking for information.
The next part of the request line is /, which indicates the uniform resource identifier (URI) the client is requesting: A URI is almost, but not quite, the same as a uniform resource locator (URL). The difference between URIs and URLs isn’t important for our purposes in this chapter, but the HTTP spec uses the term URI, so we can just mentally substitute URL for URI here.
The last part is the HTTP version the client uses, and then the request line ends in a CRLF sequence. (CRLF stands for carriage return and line feed, which are terms from the typewriter days!) The CRLF sequence can also be written as \r\n, where \r is a carriage return and \n is a line feed. The CRLF sequence separates the request line from the rest of the request data. Note that when the CRLF is printed, we see a new line start rather than \r\n.
Looking at the request line data we received from running our program so far, we see that GET is the method, / is the request URI, and HTTP/1.1 is the version.
Après la ligne de requête, les lignes suivant celle où nous avons Host: sont des entêtes. Les requêtes GET n’ont pas de corps.
Try making a request from a different browser or asking for a different address, such as 127.0.0.1:7878/test, to see how the request data changes.
Now that we know what the browser is asking for, let’s send back some data!
Writing a Response
We’re going to implement sending data in response to a client request. Responses have the following format:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
The first line is a status line that contains the HTTP version used in the response, a numeric status code that summarizes the result of the request, and a reason phrase that provides a text description of the status code. After the CRLF sequence are any headers, another CRLF sequence, and the body of the response.
Here is an example response that uses HTTP version 1.1 and has a status code of 200, an OK reason phrase, no headers, and no body:
HTTP/1.1 200 OK\r\n\r\n
The status code 200 is the standard success response. The text is a tiny successful HTTP response. Let’s write this to the stream as our response to a successful request! From the handle_connection function, remove the println! that was printing the request data and replace it with the code in Listing 21-3.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let response = "HTTP/1.1 200 OK\r\n\r\n";
stream.write_all(response.as_bytes()).unwrap();
}The first new line defines the response variable that holds the success message’s data. Then, we call as_bytes on our response to convert the string data to bytes. The write_all method on stream takes a &[u8] and sends those bytes directly down the connection. Because the write_all operation could fail, we use unwrap on any error result as before. Again, in a real application, you would add error handling here.
With these changes, let’s run our code and make a request. We’re no longer printing any data to the terminal, so we won’t see any output other than the output from Cargo. When you load 127.0.0.1:7878 in a web browser, you should get a blank page instead of an error. You’ve just handcoded receiving an HTTP request and sending a response!
Returning Real HTML
Let’s implement the functionality for returning more than a blank page. Create the new file hello.html in the root of your project directory, not in the src directory. You can input any HTML you want; Listing 21-4 shows one possibility.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
This is a minimal HTML5 document with a heading and some text. To return this from the server when a request is received, we’ll modify handle_connection as shown in Listing 21-5 to read the HTML file, add it to the response as a body, and send it.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
// -- partie masquée ici --
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}We’ve added fs to the use statement to bring the standard library’s filesystem module into scope. The code for reading the contents of a file to a string should look familiar; we used it when we read the contents of a file for our I/O project in Listing 12-4.
Next, we use format! to add the file’s contents as the body of the success response. To ensure a valid HTTP response, we add the Content-Length header, which is set to the size of our response body—in this case, the size of hello.html.
Run this code with cargo run and load 127.0.0.1:7878 in your browser; you should see your HTML rendered!
Currently, we’re ignoring the request data in http_request and just sending back the contents of the HTML file unconditionally. That means if you try requesting 127.0.0.1:7878/something-else in your browser, you’ll still get back this same HTML response. At the moment, our server is very limited and does not do what most web servers do. We want to customize our responses depending on the request and only send back the HTML file for a well-formed request to /.
Validating the Request and Selectively Responding
Right now, our web server will return the HTML in the file no matter what the client requested. Let’s add functionality to check that the browser is requesting / before returning the HTML file and to return an error if the browser requests anything else. For this we need to modify handle_connection, as shown in Listing 21-6. This new code checks the content of the request received against what we know a request for / looks like and adds if and else blocks to treat requests differently.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// -- partie masquée ici --
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
} else {
// some other request
}
}We’re only going to be looking at the first line of the HTTP request, so rather than reading the entire request into a vector, we’re calling next to get the first item from the iterator. The first unwrap takes care of the Option and stops the program if the iterator has no items. The second unwrap handles the Result and has the same effect as the unwrap that was in the map added in Listing 21-2.
Next, we check the request_line to see if it equals the request line of a GET request to the / path. If it does, the if block returns the contents of our HTML file.
If the request_line does not equal the GET request to the / path, it means we’ve received some other request. We’ll add code to the else block in a moment to respond to all other requests.
Run this code now and request 127.0.0.1:7878; you should get the HTML in hello.html. If you make any other request, such as 127.0.0.1:7878/something-else, you’ll get a connection error like those you saw when running the code in Listing 21-1 and Listing 21-2.
Now let’s add the code in Listing 21-7 to the else block to return a response with the status code 404, which signals that the content for the request was not found. We’ll also return some HTML for a page to render in the browser indicating the response to the end user.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
// -- partie masquée ici --
} else {
let status_line = "HTTP/1.1 404 NOT FOUND";
let contents = fs::read_to_string("404.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
}
}Here, our response has a status line with status code 404 and the reason phrase NOT FOUND. The body of the response will be the HTML in the file 404.html. You’ll need to create a 404.html file next to hello.html for the error page; again, feel free to use any HTML you want, or use the example HTML in Listing 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
With these changes, run your server again. Requesting 127.0.0.1:7878 should return the contents of hello.html, and any other request, like 127.0.0.1:7878/foo, should return the error HTML from 404.html.
Refactoring
At the moment, the if and else blocks have a lot of repetition: They’re both reading files and writing the contents of the files to the stream. The only differences are the status line and the filename. Let’s make the code more concise by pulling out those differences into separate if and else lines that will assign the values of the status line and the filename to variables; we can then use those variables unconditionally in the code to read the file and write the response. Listing 21-9 shows the resultant code after replacing the large if and else blocks.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// -- partie masquée ici --
fn handle_connection(mut stream: TcpStream) {
// -- partie masquée ici --
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = if request_line == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}if and else blocks to contain only the code that differs between the two casesNow the if and else blocks only return the appropriate values for the status line and filename in a tuple; we then use destructuring to assign these two values to status_line and filename using a pattern in the let statement, as discussed in Chapter 19.
The previously duplicated code is now outside the if and else blocks and uses the status_line and filename variables. This makes it easier to see the difference between the two cases, and it means we have only one place to update the code if we want to change how the file reading and response writing work. The behavior of the code in Listing 21-9 will be the same as that in Listing 21-7.
Super ! Nous avons maintenant un serveur web simple qui tient dans environ 40 lignes de code, qui répond à une requête précise par une page de contenu et répond à toutes les autres avec une réponse 404.
Currently, our server runs in a single thread, meaning it can only serve one request at a time. Let’s examine how that can be a problem by simulating some slow requests. Then, we’ll fix it so that our server can handle multiple requests at once.
Transformer notre serveur monotâche en serveur multitâches
From a Single-Threaded to a Multithreaded Server
Right now, the server will process each request in turn, meaning it won’t process a second connection until the first connection is finished processing. If the server received more and more requests, this serial execution would be less and less optimal. If the server receives a request that takes a long time to process, subsequent requests will have to wait until the long request is finished, even if the new requests can be processed quickly. We’ll need to fix this, but first we’ll look at the problem in action.
Simulating a Slow Request
We’ll look at how a slowly processing request can affect other requests made to our current server implementation. Listing 21-10 implements handling a request to /sleep with a simulated slow response that will cause the server to sleep for five seconds before responding.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// -- partie masquée ici --
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
// -- partie masquée ici --
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// -- partie masquée ici --
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}We switched from if to match now that we have three cases. We need to explicitly match on a slice of request_line to pattern-match against the string literal values; match doesn’t do automatic referencing and dereferencing, like the equality method does.
The first arm is the same as the if block from Listing 21-9. The second arm matches a request to /sleep. When that request is received, the server will sleep for five seconds before rendering the successful HTML page. The third arm is the same as the else block from Listing 21-9.
You can see how primitive our server is: Real libraries would handle the recognition of multiple requests in a much less verbose way!
Start the server using cargo run. Then, open two browser windows: one for http://127.0.0.1:7878 and the other for http://127.0.0.1:7878/sleep. If you enter the / URI a few times, as before, you’ll see it respond quickly. But if you enter /sleep and then load /, you’ll see that / waits until sleep has slept for its full five seconds before loading.
There are multiple techniques we could use to avoid requests backing up behind a slow request, including using async as we did Chapter 17; the one we’ll implement is a thread pool.
Improving Throughput with a Thread Pool
A thread pool is a group of spawned threads that are ready and waiting to handle a task. When the program receives a new task, it assigns one of the threads in the pool to the task, and that thread will process the task. The remaining threads in the pool are available to handle any other tasks that come in while the first thread is processing. When the first thread is done processing its task, it’s returned to the pool of idle threads, ready to handle a new task. A thread pool allows you to process connections concurrently, increasing the throughput of your server.
We’ll limit the number of threads in the pool to a small number to protect us from DoS attacks; if we had our program create a new thread for each request as it came in, someone making 10 million requests to our server could wreak havoc by using up all our server’s resources and grinding the processing of requests to a halt.
Rather than spawning unlimited threads, then, we’ll have a fixed number of threads waiting in the pool. Requests that come in are sent to the pool for processing. The pool will maintain a queue of incoming requests. Each of the threads in the pool will pop off a request from this queue, handle the request, and then ask the queue for another request. With this design, we can process up to N requests concurrently, where N is the number of threads. If each thread is responding to a long-running request, subsequent requests can still back up in the queue, but we’ve increased the number of long-running requests we can handle before reaching that point.
This technique is just one of many ways to improve the throughput of a web server. Other options you might explore are the fork/join model, the single-threaded async I/O model, and the multithreaded async I/O model. If you’re interested in this topic, you can read more about other solutions and try to implement them; with a low-level language like Rust, all of these options are possible.
Before we begin implementing a thread pool, let’s talk about what using the pool should look like. When you’re trying to design code, writing the client interface first can help guide your design. Write the API of the code so that it’s structured in the way you want to call it; then, implement the functionality within that structure rather than implementing the functionality and then designing the public API.
Similar to how we used test-driven development in the project in Chapter 12, we’ll use compiler-driven development here. We’ll write the code that calls the functions we want, and then we’ll look at errors from the compiler to determine what we should change next to get the code to work. Before we do that, however, we’ll explore the technique we’re not going to use as a starting point.
Spawning a Thread for Each Request
First, let’s explore how our code might look if it did create a new thread for every connection. As mentioned earlier, this isn’t our final plan due to the problems with potentially spawning an unlimited number of threads, but it is a starting point to get a working multithreaded server first. Then, we’ll add the thread pool as an improvement, and contrasting the two solutions will be easier.
Listing 21-11 shows the changes to make to main to spawn a new thread to handle each stream within the for loop.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}As you learned in Chapter 16, thread::spawn will create a new thread and then run the code in the closure in the new thread. If you run this code and load /sleep in your browser, then / in two more browser tabs, you’ll indeed see that the requests to / don’t have to wait for /sleep to finish. However, as we mentioned, this will eventually overwhelm the system because you’d be making new threads without any limit.
You may also recall from Chapter 17 that this is exactly the kind of situation where async and await really shine! Keep that in mind as we build the thread pool and think about how things would look different or the same with async.
Creating a Finite Number of Threads
We want our thread pool to work in a similar, familiar way so that switching from threads to a thread pool doesn’t require large changes to the code that uses our API. Listing 21-12 shows the hypothetical interface for a ThreadPool struct we want to use instead of thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}ThreadPool interfaceWe use ThreadPool::new to create a new thread pool with a configurable number of threads, in this case four. Then, in the for loop, pool.execute has a similar interface as thread::spawn in that it takes a closure that the pool should run for each stream. We need to implement pool.execute so that it takes the closure and gives it to a thread in the pool to run. This code won’t yet compile, but we’ll try so that the compiler can guide us in how to fix it.
Building ThreadPool Using Compiler-Driven Development
Make the changes in Listing 21-12 to src/main.rs, and then let’s use the compiler errors from cargo check to drive our development. Here is the first error we get:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Bien ! Cette erreur nous informe que nous avons besoin d’un type ou d’un module qui s’appelle GroupeTaches, donc nous allons le créer. Notre implémentation de GroupeTaches sera indépendante du type de travail qu’accomplira notre serveur web. Donc, transformons la crate binaire salutations en crate de bibliothèque pour y implémenter notre GroupeTaches. Après l’avoir changé en crate de bibliothèque, nous pourrons utiliser ensuite cette bibliothèque de groupe de tâches dans n’importe quel projet où nous aurons besoin d’un groupe de tâches, et pas seulement pour servir des requêtes web.
Create a src/lib.rs file that contains the following, which is the simplest definition of a ThreadPool struct that we can have for now:
pub struct ThreadPool;Then, edit the main.rs file to bring ThreadPool into scope from the library crate by adding the following code to the top of src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Ce code ne fonctionne toujours pas, mais vérifions-le à nouveau pour obtenir l’erreur que nous devons maintenant résoudre :
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Cette erreur indique que nous devons ensuite créer une fonction associée new pour GroupeTaches. Nous savons aussi que new nécessite d’avoir un paramètre qui peut accepter 4 comme argument et doit retourner une instance de GroupeTaches. Implémentons la fonction new la plus simple possible qui aura ces caractéristiques :
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}We chose usize as the type of the size parameter because we know that a negative number of threads doesn’t make any sense. We also know we’ll use this 4 as the number of elements in a collection of threads, which is what the usize type is for, as discussed in the “Integer Types” section in Chapter 3.
Let’s check the code again:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Now the error occurs because we don’t have an execute method on ThreadPool. Recall from the “Creating a Finite Number of Threads” section that we decided our thread pool should have an interface similar to thread::spawn. In addition, we’ll implement the execute function so that it takes the closure it’s given and gives it to an idle thread in the pool to run.
We’ll define the execute method on ThreadPool to take a closure as a parameter. Recall from the “Moving Captured Values Out of Closures” in Chapter 13 that we can take closures as parameters with three different traits: Fn, FnMut, and FnOnce. We need to decide which kind of closure to use here. We know we’ll end up doing something similar to the standard library thread::spawn implementation, so we can look at what bounds the signature of thread::spawn has on its parameter. The documentation shows us the following:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Le paramètre de type F est celui qui nous intéresse ici ; le paramètre de type T est lié à la valeur de retour, et ceci ne nous intéresse pas ici. Nous pouvons constater que spawn utilise le trait FnOnce lié à F. C’est probablement ce dont nous avons besoin, parce que nous allons sûrement passer cet argument dans le execute de spawn. Nous pouvons aussi être sûr que FnOnce est le trait dont nous avons besoin car la tâche qui va traiter une requête ne va le faire qu’une seule fois, ce qui correspond à la partie Once dans FnOnce.
The F type parameter also has the trait bound Send and the lifetime bound 'static, which are useful in our situation: We need Send to transfer the closure from one thread to another and 'static because we don’t know how long the thread will take to execute. Let’s create an execute method on ThreadPool that will take a generic parameter of type F with these bounds:
pub struct ThreadPool;
impl ThreadPool {
// -- partie masquée ici --
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Nous utilisons toujours le () après FnOne car ce FnOnce représente une fermeture qui ne prend pas de paramètres et retourne le type unité (). Exactement comme les définitions de fonctions, le type de retour peut être omis de la signature, mais même si elle ne contient pas de paramètre, nous avons tout de même besoin des parenthèses.
Again, this is the simplest implementation of the execute method: It does nothing, but we’re only trying to make our code compile. Let’s check it again:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
Cela se compile ! Mais remarquez que si vous lancez cargo run et faites la requête dans votre navigateur web, vous verrez l’erreur dans le navigateur que nous avions tout au début du chapitre. Notre bibliothèque n’exécute pas encore la fermeture envoyée à executer !
Note: A saying you might hear about languages with strict compilers, such as Haskell and Rust, is “If the code compiles, it works.” But this saying is not universally true. Our project compiles, but it does absolutely nothing! If we were building a real, complete project, this would be a good time to start writing unit tests to check that the code compiles and has the behavior we want.
Consider: What would be different here if we were going to execute a future instead of a closure?
Validating the Number of Threads in new
We aren’t doing anything with the parameters to new and execute. Let’s implement the bodies of these functions with the behavior we want. To start, let’s think about new. Earlier we chose an unsigned type for the size parameter because a pool with a negative number of threads makes no sense. However, a pool with zero threads also makes no sense, yet zero is a perfectly valid usize. We’ll add code to check that size is greater than zero before we return a ThreadPool instance, and we’ll have the program panic if it receives a zero by using the assert! macro, as shown in Listing 21-13.
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// -- partie masquée ici --
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool::new to panic if size is zeroWe’ve also added some documentation for our ThreadPool with doc comments. Note that we followed good documentation practices by adding a section that calls out the situations in which our function can panic, as discussed in Chapter 14. Try running cargo doc --open and clicking the ThreadPool struct to see what the generated docs for new look like!
Instead of adding the assert! macro as we’ve done here, we could change new into build and return a Result like we did with Config::build in the I/O project in Listing 12-9. But we’ve decided in this case that trying to create a thread pool without any threads should be an unrecoverable error. If you’re feeling ambitious, try to write a function named build with the following signature to compare with the new function:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Creating Space to Store the Threads
Now that we have a way to know we have a valid number of threads to store in the pool, we can create those threads and store them in the ThreadPool struct before returning the struct. But how do we “store” a thread? Let’s take another look at the thread::spawn signature:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,La fonction spawn retourne un JoinHandle<T>, où T est le type que retourne notre fermeture. Essayons d’utiliser nous aussi JoinHandle pour voir ce qu’il va se passer. Dans notre cas, les fermetures que nous passons dans le groupe de tâches vont traiter les connexions mais ne vont rien retourner, donc T sera le type unité, ().
The code in Listing 21-14 will compile, but it doesn’t create any threads yet. We’ve changed the definition of ThreadPool to hold a vector of thread::JoinHandle<()> instances, initialized the vector with a capacity of size, set up a for loop that will run some code to create the threads, and returned a ThreadPool instance containing them.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// -- partie masquée ici --
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// -- partie masquée ici --
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool to hold the threadsWe’ve brought std::thread into scope in the library crate because we’re using thread::JoinHandle as the type of the items in the vector in ThreadPool.
Once a valid size is received, our ThreadPool creates a new vector that can hold size items. The with_capacity function performs the same task as Vec::new but with an important difference: It pre-allocates space in the vector. Because we know we need to store size elements in the vector, doing this allocation up front is slightly more efficient than using Vec::new, which resizes itself as elements are inserted.
When you run cargo check again, it should succeed.
Sending Code from the ThreadPool to a Thread
We left a comment in the for loop in Listing 21-14 regarding the creation of threads. Here, we’ll look at how we actually create threads. The standard library provides thread::spawn as a way to create threads, and thread::spawn expects to get some code the thread should run as soon as the thread is created. However, in our case, we want to create the threads and have them wait for code that we’ll send later. The standard library’s implementation of threads doesn’t include any way to do that; we have to implement it manually.
We’ll implement this behavior by introducing a new data structure between the ThreadPool and the threads that will manage this new behavior. We’ll call this data structure Worker, which is a common term in pooling implementations. The Worker picks up code that needs to be run and runs the code in its thread.
Think of people working in the kitchen at a restaurant: The workers wait until orders come in from customers, and then they’re responsible for taking those orders and filling them.
Instead of storing a vector of JoinHandle<()> instances in the thread pool, we’ll store instances of the Worker struct. Each Worker will store a single JoinHandle<()> instance. Then, we’ll implement a method on Worker that will take a closure of code to run and send it to the already running thread for execution. We’ll also give each Worker an id so that we can distinguish between the different instances of Worker in the pool when logging or debugging.
Here is the new process that will happen when we create a ThreadPool. We’ll implement the code that sends the closure to the thread after we have Worker set up in this way:
- Define a
Workerstruct that holds anidand aJoinHandle<()>. - Change
ThreadPoolto hold a vector ofWorkerinstances. - Define a
Worker::newfunction that takes anidnumber and returns aWorkerinstance that holds theidand a thread spawned with an empty closure. - In
ThreadPool::new, use theforloop counter to generate anid, create a newWorkerwith thatid, and store theWorkerin the vector.
If you’re up for a challenge, try implementing these changes on your own before looking at the code in Listing 21-15.
Ready? Here is Listing 21-15 with one way to make the preceding modifications.
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// -- partie masquée ici --
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// -- partie masquée ici --
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool to hold Worker instances instead of holding threads directlyNous avons changé le nom du champ taches de GroupeTaches en operateurs car il stocke maintenant des instances de Operateur plutôt que des instances de JoinHandle<()>. Nous utilisons le compteur de la boucle for comme argument de Operateur::new et nous stockons chacun des nouveaux Operateur dans le vecteur operateurs.
External code (like our server in src/main.rs) doesn’t need to know the implementation details regarding using a Worker struct within ThreadPool, so we make the Worker struct and its new function private. The Worker::new function uses the id we give it and stores a JoinHandle<()> instance that is created by spawning a new thread using an empty closure.
Note: If the operating system can’t create a thread because there aren’t enough system resources, thread::spawn will panic. That will cause our whole server to panic, even though the creation of some threads might succeed. For simplicity’s sake, this behavior is fine, but in a production thread pool implementation, you’d likely want to use std::thread::Builder and its spawn method that returns Result instead.
This code will compile and will store the number of Worker instances we specified as an argument to ThreadPool::new. But we’re still not processing the closure that we get in execute. Let’s look at how to do that next.
Sending Requests to Threads via Channels
The next problem we’ll tackle is that the closures given to thread::spawn do absolutely nothing. Currently, we get the closure we want to execute in the execute method. But we need to give thread::spawn a closure to run when we create each Worker during the creation of the ThreadPool.
We want the Worker structs that we just created to fetch the code to run from a queue held in the ThreadPool and send that code to its thread to run.
The channels we learned about in Chapter 16—a simple way to communicate between two threads—would be perfect for this use case. We’ll use a channel to function as the queue of jobs, and execute will send a job from the ThreadPool to the Worker instances, which will send the job to its thread. Here is the plan:
- The
ThreadPoolwill create a channel and hold on to the sender. - Each
Workerwill hold on to the receiver. - We’ll create a new
Jobstruct that will hold the closures we want to send down the channel. - The
executemethod will send the job it wants to execute through the sender. - In its thread, the
Workerwill loop over its receiver and execute the closures of any jobs it receives.
Let’s start by creating a channel in ThreadPool::new and holding the sender in the ThreadPool instance, as shown in Listing 21-16. The Job struct doesn’t hold anything for now but will be the type of item we’re sending down the channel.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// -- partie masquée ici --
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// -- partie masquée ici --
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool to store the sender of a channel that transmits Job instancesIn ThreadPool::new, we create our new channel and have the pool hold the sender. This will successfully compile.
Let’s try passing a receiver of the channel into each Worker as the thread pool creates the channel. We know we want to use the receiver in the thread that the Worker instances spawn, so we’ll reference the receiver parameter in the closure. The code in Listing 21-17 won’t quite compile yet.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// -- partie masquée ici --
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// -- partie masquée ici --
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// -- partie masquée ici --
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}WorkerWe’ve made some small and straightforward changes: We pass the receiver into Worker::new, and then we use it inside the closure.
When we try to check this code, we get this error:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
The code is trying to pass receiver to multiple Worker instances. This won’t work, as you’ll recall from Chapter 16: The channel implementation that Rust provides is multiple producer, single consumer. This means we can’t just clone the consuming end of the channel to fix this code. We also don’t want to send a message multiple times to multiple consumers; we want one list of messages with multiple Worker instances such that each message gets processed once.
De plus, obtenir une mission de la file d’attente du canal implique de modifier la reception, donc les tâches ont besoin d’une méthode sécurisée pour partager et modifier reception ; autrement, nous risquons de nous trouver dans des situations de concurrence (comme nous l’avons vu dans le chapitre 16).
Recall the thread-safe smart pointers discussed in Chapter 16: To share ownership across multiple threads and allow the threads to mutate the value, we need to use Arc<Mutex<T>>. The Arc type will let multiple Worker instances own the receiver, and Mutex will ensure that only one Worker gets a job from the receiver at a time. Listing 21-18 shows the changes we need to make.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// -- partie masquée ici --
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// -- partie masquée ici --
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// -- partie masquée ici --
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// -- partie masquée ici --
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// -- partie masquée ici --
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Worker instances using Arc and MutexIn ThreadPool::new, we put the receiver in an Arc and a Mutex. For each new Worker, we clone the Arc to bump the reference count so that the Worker instances can share ownership of the receiver.
With these changes, the code compiles! We’re getting there!
Implementing the execute Method
Let’s finally implement the execute method on ThreadPool. We’ll also change Job from a struct to a type alias for a trait object that holds the type of closure that execute receives. As discussed in the “Type Synonyms and Type Aliases” section in Chapter 20, type aliases allow us to make long types shorter for ease of use. Look at Listing 21-19.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// -- partie masquée ici --
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// -- partie masquée ici --
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// -- partie masquée ici --
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Job type alias for a Box that holds each closure and then sending the job down the channelAfter creating a new Job instance using the closure we get in execute, we send that job down the sending end of the channel. We’re calling unwrap on send for the case that sending fails. This might happen if, for example, we stop all our threads from executing, meaning the receiving end has stopped receiving new messages. At the moment, we can’t stop our threads from executing: Our threads continue executing as long as the pool exists. The reason we use unwrap is that we know the failure case won’t happen, but the compiler doesn’t know that.
But we’re not quite done yet! In the Worker, our closure being passed to thread::spawn still only references the receiving end of the channel. Instead, we need the closure to loop forever, asking the receiving end of the channel for a job and running the job when it gets one. Let’s make the change shown in Listing 21-20 to Worker::new.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// -- partie masquée ici --
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Worker instance’s threadHere, we first call lock on the receiver to acquire the mutex, and then we call unwrap to panic on any errors. Acquiring a lock might fail if the mutex is in a poisoned state, which can happen if some other thread panicked while holding the lock rather than releasing the lock. In this situation, calling unwrap to have this thread panic is the correct action to take. Feel free to change this unwrap to an expect with an error message that is meaningful to you.
If we get the lock on the mutex, we call recv to receive a Job from the channel. A final unwrap moves past any errors here as well, which might occur if the thread holding the sender has shut down, similar to how the send method returns Err if the receiver shuts down.
L’appel à recv bloque l’exécution, donc s’il n’y a pas encore de mission, la tâche courante va attendre jusqu’à ce qu’une mission soit disponible. Le Mutex<T> s’assure qu’une seule tâche d’Operateur essaie d’obtenir une mission à un instant donné.
Notre groupe de tâches est désormais en état de fonctionner ! Faites un cargo run et faites quelques requêtes :
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Success! We now have a thread pool that executes connections asynchronously. There are never more than four threads created, so our system won’t get overloaded if the server receives a lot of requests. If we make a request to /sleep, the server will be able to serve other requests by having another thread run them.
Note: If you open /sleep in multiple browser windows simultaneously, they might load one at a time in five-second intervals. Some web browsers execute multiple instances of the same request sequentially for caching reasons. This limitation is not caused by our web server.
This is a good time to pause and consider how the code in Listings 21-18, 21-19, and 21-20 would be different if we were using futures instead of a closure for the work to be done. What types would change? How would the method signatures be different, if at all? What parts of the code would stay the same?
After learning about the while let loop in Chapter 17 and Chapter 19, you might be wondering why we didn’t write the Worker thread code as shown in Listing 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// -- partie masquée ici --
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Worker::new using while letThis code compiles and runs but doesn’t result in the desired threading behavior: A slow request will still cause other requests to wait to be processed. The reason is somewhat subtle: The Mutex struct has no public unlock method because the ownership of the lock is based on the lifetime of the MutexGuard<T> within the LockResult<MutexGuard<T>> that the lock method returns. At compile time, the borrow checker can then enforce the rule that a resource guarded by a Mutex cannot be accessed unless we hold the lock. However, this implementation can also result in the lock being held longer than intended if we aren’t mindful of the lifetime of the MutexGuard<T>.
The code in Listing 21-20 that uses let job = receiver.lock().unwrap().recv().unwrap(); works because with let, any temporary values used in the expression on the right-hand side of the equal sign are immediately dropped when the let statement ends. However, while let (and if let and match) does not drop temporary values until the end of the associated block. In Listing 21-21, the lock remains held for the duration of the call to job(), meaning other Worker instances cannot receive jobs.
Arrêt propre et nettoyage
Arrêt propre et nettoyage
The code in Listing 21-20 is responding to requests asynchronously through the use of a thread pool, as we intended. We get some warnings about the workers, id, and thread fields that we’re not using in a direct way that reminds us we’re not cleaning up anything. When we use the less elegant ctrl-C method to halt the main thread, all other threads are stopped immediately as well, even if they’re in the middle of serving a request.
Next, then, we’ll implement the Drop trait to call join on each of the threads in the pool so that they can finish the requests they’re working on before closing. Then, we’ll implement a way to tell the threads they should stop accepting new requests and shut down. To see this code in action, we’ll modify our server to accept only two requests before gracefully shutting down its thread pool.
One thing to notice as we go: None of this affects the parts of the code that handle executing the closures, so everything here would be the same if we were using a thread pool for an async runtime.
Implementing the Drop Trait on ThreadPool
Let’s start with implementing Drop on our thread pool. When the pool is dropped, our threads should all join to make sure they finish their work. Listing 21-22 shows a first attempt at a Drop implementation; this code won’t quite work yet.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}First, we loop through each of the thread pool workers. We use &mut for this because self is a mutable reference, and we also need to be able to mutate worker. For each worker, we print a message saying that this particular Worker instance is shutting down, and then we call join on that Worker instance’s thread. If the call to join fails, we use unwrap to make Rust panic and go into an ungraceful shutdown.
Here is the error we get when we compile this code:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:1921:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
The error tells us we can’t call join because we only have a mutable borrow of each worker and join takes ownership of its argument. To solve this issue, we need to move the thread out of the Worker instance that owns thread so that join can consume the thread. One way to do this is to take the same approach we took in Listing 18-15. If Worker held an Option<thread::JoinHandle<()>>, we could call the take method on the Option to move the value out of the Some variant and leave a None variant in its place. In other words, a Worker that is running would have a Some variant in thread, and when we wanted to clean up a Worker, we’d replace Some with None so that the Worker wouldn’t have a thread to run.
However, the only time this would come up would be when dropping the Worker. In exchange, we’d have to deal with an Option<thread::JoinHandle<()>> anywhere we accessed worker.thread. Idiomatic Rust uses Option quite a bit, but when you find yourself wrapping something you know will always be present in an Option as a workaround like this, it’s a good idea to look for alternative approaches to make your code cleaner and less error-prone.
In this case, a better alternative exists: the Vec::drain method. It accepts a range parameter to specify which items to remove from the vector and returns an iterator of those items. Passing the .. range syntax will remove every value from the vector.
So, we need to update the ThreadPool drop implementation like this:
#![allow(unused)]
fn main() {
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}
}This resolves the compiler error and does not require any other changes to our code. Note that, because drop can be called when panicking, the unwrap could also panic and cause a double panic, which immediately crashes the program and ends any cleanup in progress. This is fine for an example program, but it isn’t recommended for production code.
Signaling to the Threads to Stop Listening for Jobs
With all the changes we’ve made, our code compiles without any warnings. However, the bad news is that this code doesn’t function the way we want it to yet. The key is the logic in the closures run by the threads of the Worker instances: At the moment, we call join, but that won’t shut down the threads, because they loop forever looking for jobs. If we try to drop our ThreadPool with our current implementation of drop, the main thread will block forever, waiting for the first thread to finish.
To fix this problem, we’ll need a change in the ThreadPool drop implementation and then a change in the Worker loop.
First, we’ll change the ThreadPool drop implementation to explicitly drop the sender before waiting for the threads to finish. Listing 21-23 shows the changes to ThreadPool to explicitly drop sender. Unlike with the thread, here we do need to use an Option to be able to move sender out of ThreadPool with Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// -- partie masquée ici --
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// -- partie masquée ici --
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}sender before joining the Worker threadsDropping sender closes the channel, which indicates no more messages will be sent. When that happens, all the calls to recv that the Worker instances do in the infinite loop will return an error. In Listing 21-24, we change the Worker loop to gracefully exit the loop in that case, which means the threads will finish when the ThreadPool drop implementation calls join on them.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker { id, thread }
}
}recv returns an errorTo see this code in action, let’s modify main to accept only two requests before gracefully shutting down the server, as shown in Listing 21-25.
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Dans la réalité on ne voudrait pas qu’un serveur web s’arrête après avoir servi seulement deux requêtes. Ce code sert uniquement à montrer que l’arrêt et le nettoyage s’effectuent bien proprement.
La méthode take est définie dans le trait Iterator et limite l’itération aux deux premiers éléments au maximum. Le GroupeTaches va sortir de la portée à la fin du main et l’implémentation de drop va s’exécuter.
Start the server with cargo run and make three requests. The third request should error, and in your terminal, you should see output similar to this:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
You might see a different ordering of Worker IDs and messages printed. We can see how this code works from the messages: Worker instances 0 and 3 got the first two requests. The server stopped accepting connections after the second connection, and the Drop implementation on ThreadPool starts executing before Worker 3 even starts its job. Dropping the sender disconnects all the Worker instances and tells them to shut down. The Worker instances each print a message when they disconnect, and then the thread pool calls join to wait for each Worker thread to finish.
Notice one interesting aspect of this particular execution: The ThreadPool dropped the sender, and before any Worker received an error, we tried to join Worker 0. Worker 0 had not yet gotten an error from recv, so the main thread blocked, waiting for Worker 0 to finish. In the meantime, Worker 3 received a job and then all threads received an error. When Worker 0 finished, the main thread waited for the rest of the Worker instances to finish. At that point, they had all exited their loops and stopped.
Félicitations ! Nous avons maintenant terminé notre projet ; nous avons un serveur web basique qui utilise un groupe de tâches pour répondre de manière asynchrone. Nous pouvons demander un arrêt propre du serveur qui va nettoyer toutes les tâches du groupe.
Here’s the full code for reference:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Nous aurions pu faire bien plus ! Si vous souhaitez continuer à améliorer ce projet, voici quelques idées :
- Add more documentation to
ThreadPooland its public methods. - Add tests of the library’s functionality.
- Change calls to
unwrapto more robust error handling. - Use
ThreadPoolto perform some task other than serving web requests. - Find a thread pool crate on crates.io and implement a similar web server using the crate instead. Then, compare its API and robustness to the thread pool we implemented.
Résumé
Well done! You’ve made it to the end of the book! We want to thank you for joining us on this tour of Rust. You’re now ready to implement your own Rust projects and help with other people’s projects. Keep in mind that there is a welcoming community of other Rustaceans who would love to help you with any challenges you encounter on your Rust journey.
Annexes
Les sections suivantes contiennent des informations de référence que vous pourriez trouver utile pour votre exploration de Rust.
Annexe A : les mots-clés
Appendix A: Keywords
The following lists contain keywords that are reserved for current or future use by the Rust language. As such, they cannot be used as identifiers (except as raw identifiers, as we discuss in the “Raw Identifiers” section). Identifiers are names of functions, variables, parameters, struct fields, modules, crates, constants, macros, static values, attributes, types, traits, or lifetimes.
Keywords Currently in Use
The following is a list of keywords currently in use, with their functionality described.
as: Perform primitive casting, disambiguate the specific trait containing an item, or rename items inusestatements.async: Return aFutureinstead of blocking the current thread.await: Suspend execution until the result of aFutureis ready.break: Exit a loop immediately.const: Define constant items or constant raw pointers.continue: Continue to the next loop iteration.crate: In a module path, refers to the crate root.dyn: Dynamic dispatch to a trait object.else: Fallback forifandif letcontrol flow constructs.enum: Define an enumeration.extern: Link an external function or variable.false: Boolean false literal.fn: Define a function or the function pointer type.for: Loop over items from an iterator, implement a trait, or specify a higher ranked lifetime.if: Branch based on the result of a conditional expression.impl: Implement inherent or trait functionality.in: Part offorloop syntax.let: Bind a variable.loop: Loop unconditionally.match: Match a value to patterns.mod: Define a module.move: Make a closure take ownership of all its captures.mut: Denote mutability in references, raw pointers, or pattern bindings.pub: Denote public visibility in struct fields,implblocks, or modules.ref: Bind by reference.return: Return from function.Self: A type alias for the type we are defining or implementing.self: Method subject or current module.static: Global variable or lifetime lasting the entire program execution.struct: Define a structure.super: Parent module of the current module.trait: Define a trait.true: Boolean true literal.type: Define a type alias or associated type.union: Define a union; is a keyword only when used in a union declaration.unsafe: Denote unsafe code, functions, traits, or implementations.use: Bring symbols into scope.where: Denote clauses that constrain a type.while: Loop conditionally based on the result of an expression.
Keywords Reserved for Future Use
The following keywords do not yet have any functionality but are reserved by Rust for potential future use:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Raw Identifiers
Raw identifiers are the syntax that lets you use keywords where they wouldn’t normally be allowed. You use a raw identifier by prefixing a keyword with r#.
Par exemple, match est un mot-clé. Si vous essayez de compiler la fonction suivante qui utilise match comme nom :
Fichier : src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}you’ll get this error:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
L’erreur montre que vous ne pouvez pas utiliser le mot-clé match comme identificateur de la fonction. Pour utiliser match comme nom de fonction, vous devez utiliser la syntaxe d’identificateur brut, comme ceci :
Fichier : src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}Ce code va se compiler sans erreur. Remarquez le préfixe r# sur le nom de la fonction dans sa définition mais aussi lorsque cette fonction est appelée dans main.
Raw identifiers allow you to use any word you choose as an identifier, even if that word happens to be a reserved keyword. This gives us more freedom to choose identifier names, as well as lets us integrate with programs written in a language where these words aren’t keywords. In addition, raw identifiers allow you to use libraries written in a different Rust edition than your crate uses. For example, try isn’t a keyword in the 2015 edition but is in the 2018, 2021, and 2024 editions. If you depend on a library that is written using the 2015 edition and has a try function, you’ll need to use the raw identifier syntax, r#try in this case, to call that function from your code on later editions. See Appendix E for more information on editions.
Annexe B : opérateurs et symboles
Appendix B: Operators and Symbols
This appendix contains a glossary of Rust’s syntax, including operators and other symbols that appear by themselves or in the context of paths, generics, trait bounds, macros, attributes, comments, tuples, and brackets.
Operators
Table B-1 contains the operators in Rust, an example of how the operator would appear in context, a short explanation, and whether that operator is overloadable. If an operator is overloadable, the relevant trait to use to overload that operator is listed.
Table B-1: Operators
| Operator | Exemple | Explanation | Overloadable? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Macro expansion | |
! | !expr | Bitwise or logical complement | Not |
!= | expr != expr | Nonequality comparison | PartialEq |
% | expr % expr | Arithmetic remainder | Rem |
%= | var %= expr | Arithmetic remainder and assignment | RemAssign |
& | &expr, &mut expr | Borrow | |
& | &type, &mut type, &'a type, &'a mut type | Borrowed pointer type | |
& | expr & expr | Bitwise AND | BitAnd |
&= | var &= expr | Bitwise AND and assignment | BitAndAssign |
&& | expr && expr | Short-circuiting logical AND | |
* | expr * expr | Arithmetic multiplication | Mul |
*= | var *= expr | Arithmetic multiplication and assignment | MulAssign |
* | *expr | Dereference | Deref |
* | *const type, *mut type | Raw pointer | |
+ | trait + trait, 'a + trait | Compound type constraint | |
+ | expr + expr | Arithmetic addition | Add |
+= | var += expr | Arithmetic addition and assignment | AddAssign |
, | expr, expr | Argument and element separator | |
- | - expr | Arithmetic negation | Neg |
- | expr - expr | Arithmetic subtraction | Sub |
-= | var -= expr | Arithmetic subtraction and assignment | SubAssign |
-> | fn(...) -> type, |…| -> type | Function and closure return type | |
. | expr.ident | Field access | |
. | expr.ident(expr, ...) | Method call | |
. | expr.0, expr.1, and so on | Tuple indexing | |
.. | .., expr.., ..expr, expr..expr | Right-exclusive range literal | PartialOrd |
..= | ..=expr, expr..=expr | Right-inclusive range literal | PartialOrd |
.. | ..expr | Struct literal update syntax | |
.. | variant(x, ..), struct_type { x, .. } | “And the rest” pattern binding | |
... | expr...expr | (Deprecated, use ..= instead) In a pattern: inclusive range pattern | |
/ | expr / expr | Arithmetic division | Div |
/= | var /= expr | Arithmetic division and assignment | DivAssign |
: | pat: type, ident: type | Constraints | |
: | ident: expr | Struct field initializer | |
: | 'a: loop {...} | Loop label | |
; | expr; | Statement and item terminator | |
; | [...; len] | Part of fixed-size array syntax | |
<< | expr << expr | Left-shift | Shl |
<<= | var <<= expr | Left-shift and assignment | ShlAssign |
< | expr < expr | Less than comparison | PartialOrd |
<= | expr <= expr | Less than or equal to comparison | PartialOrd |
= | var = expr, ident = type | Assignment/equivalence | |
== | expr == expr | Equality comparison | PartialEq |
=> | pat => expr | Part of match arm syntax | |
> | expr > expr | Greater than comparison | PartialOrd |
>= | expr >= expr | Greater than or equal to comparison | PartialOrd |
>> | expr >> expr | Right-shift | Shr |
>>= | var >>= expr | Right-shift and assignment | ShrAssign |
@ | ident @ pat | Pattern binding | |
^ | expr ^ expr | Bitwise exclusive OR | BitXor |
^= | var ^= expr | Bitwise exclusive OR and assignment | BitXorAssign |
| | pat | pat | Pattern alternatives | |
| | expr | expr | Bitwise OR | BitOr |
|= | var |= expr | Bitwise OR and assignment | BitOrAssign |
|| | expr || expr | Short-circuiting logical OR | |
? | expr? | Error propagation |
Non-operator Symbols
The following tables contain all symbols that don’t function as operators; that is, they don’t behave like a function or method call.
Table B-2 shows symbols that appear on their own and are valid in a variety of locations.
Table B-2: Stand-alone Syntax
| Symbol | Explanation |
|---|---|
'ident | Named lifetime or loop label |
Digits immediately followed by u8, i32, f64, usize, and so on | Numeric literal of specific type |
"..." | String literal |
r"...", r#"..."#, r##"..."##, and so on | Raw string literal; escape characters not processed |
b"..." | Byte string literal; constructs an array of bytes instead of a string |
br"...", br#"..."#, br##"..."##, and so on | Raw byte string literal; combination of raw and byte string literal |
'...' | Character literal |
b'...' | ASCII byte literal |
|…| expr | Closure |
! | Always-empty bottom type for diverging functions |
_ | “Ignored” pattern binding; also used to make integer literals readable |
Table B-3 shows symbols that appear in the context of a path through the module hierarchy to an item.
Table B-3: Path-Related Syntax
| Symbol | Explanation |
|---|---|
ident::ident | Namespace path |
::path | Path relative to the crate root (that is, an explicitly absolute path) |
self::path | Path relative to the current module (that is, an explicitly relative path) |
super::path | Path relative to the parent of the current module |
type::ident, <type as trait>::ident | Associated constants, functions, and types |
<type>::... | Associated item for a type that cannot be directly named (for example, <&T>::..., <[T]>::..., and so on) |
trait::method(...) | Disambiguating a method call by naming the trait that defines it |
type::method(...) | Disambiguating a method call by naming the type for which it’s defined |
<type as trait>::method(...) | Disambiguating a method call by naming the trait and type |
Table B-4 shows symbols that appear in the context of using generic type parameters.
Table B-4: Generics
| Symbol | Explanation |
|---|---|
path<...> | Specifies parameters to a generic type in a type (for example, Vec<u8>) |
path::<...>, method::<...> | Specifies parameters to a generic type, function, or method in an expression; often referred to as turbofish (for example, "42".parse::<i32>()) |
fn ident<...> ... | Define generic function |
struct ident<...> ... | Define generic structure |
enum ident<...> ... | Define generic enumeration |
impl<...> ... | Define generic implementation |
for<...> type | Higher ranked lifetime bounds |
type<ident=type> | A generic type where one or more associated types have specific assignments (for example, Iterator<Item=T>) |
Table B-5 shows symbols that appear in the context of constraining generic type parameters with trait bounds.
Table B-5: Trait Bound Constraints
| Symbol | Explanation |
|---|---|
T: U | Generic parameter T constrained to types that implement U |
T: 'a | Generic type T must outlive lifetime 'a (meaning the type cannot transitively contain any references with lifetimes shorter than 'a) |
T: 'static | Generic type T contains no borrowed references other than 'static ones |
'b: 'a | Generic lifetime 'b must outlive lifetime 'a |
T: ?Sized | Allow generic type parameter to be a dynamically sized type |
'a + trait, trait + trait | Compound type constraint |
Table B-6 shows symbols that appear in the context of calling or defining macros and specifying attributes on an item.
Table B-6: Macros and Attributes
| Symbol | Explanation |
|---|---|
#[meta] | Outer attribute |
#![meta] | Inner attribute |
$ident | Macro substitution |
$ident:kind | Macro metavariable |
$(...)... | Macro repetition |
ident!(...), ident!{...}, ident![...] | Macro invocation |
Table B-7 shows symbols that create comments.
Table B-7: Comments
| Symbol | Explanation |
|---|---|
// | Line comment |
//! | Inner line doc comment |
/// | Outer line doc comment |
/*...*/ | Block comment |
/*!...*/ | Inner block doc comment |
/**...*/ | Outer block doc comment |
Table B-8 shows the contexts in which parentheses are used.
Encart 9-3 : Ouverture d’un fichier
| Symbol | Explanation |
|---|---|
() | Empty tuple (aka unit), both literal and type |
(expr) | Parenthesized expression |
(expr,) | Single-element tuple expression |
(type,) | Single-element tuple type |
(expr, ...) | Tuple expression |
(type, ...) | Tuple type |
expr(expr, ...) | Function call expression; also used to initialize tuple structs and tuple enum variants |
Table B-9 shows the contexts in which curly brackets are used.
Table B-9: Curly Brackets
| Context | Explanation |
|---|---|
{...} | Block expression |
Type {...} | Struct literal |
Table B-10 shows the contexts in which square brackets are used.
Table B-10: Square Brackets
| Context | Explanation |
|---|---|
[...] | Array literal |
[expr; len] | Array literal containing len copies of expr |
[type; len] | Array type containing len instances of type |
expr[expr] | Collection indexing; overloadable (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Collection indexing pretending to be collection slicing, using Range, RangeFrom, RangeTo, or RangeFull as the “index” |
Annexe C : traits dérivables
Appendix C: Derivable Traits
In various places in the book, we’ve discussed the derive attribute, which you can apply to a struct or enum definition. The derive attribute generates code that will implement a trait with its own default implementation on the type you’ve annotated with the derive syntax.
In this appendix, we provide a reference of all the traits in the standard library that you can use with derive. Each section covers:
- What operators and methods deriving this trait will enable
- What the implementation of the trait provided by
derivedoes - What implementing the trait signifies about the type
- The conditions in which you’re allowed or not allowed to implement the trait
- Examples of operations that require the trait
If you want different behavior from that provided by the derive attribute, consult the standard library documentation for each trait for details on how to manually implement them.
The traits listed here are the only ones defined by the standard library that can be implemented on your types using derive. Other traits defined in the standard library don’t have sensible default behavior, so it’s up to you to implement them in the way that makes sense for what you’re trying to accomplish.
An example of a trait that can’t be derived is Display, which handles formatting for end users. You should always consider the appropriate way to display a type to an end user. What parts of the type should an end user be allowed to see? What parts would they find relevant? What format of the data would be most relevant to them? The Rust compiler doesn’t have this insight, so it can’t provide appropriate default behavior for you.
The list of derivable traits provided in this appendix is not comprehensive: Libraries can implement derive for their own traits, making the list of traits you can use derive with truly open ended. Implementing derive involves using a procedural macro, which is covered in the “Custom derive Macros” section in Chapter 20.
Debug for Programmer Output
The Debug trait enables debug formatting in format strings, which you indicate by adding :? within {} placeholders.
The Debug trait allows you to print instances of a type for debugging purposes, so you and other programmers using your type can inspect an instance at a particular point in a program’s execution.
The Debug trait is required, for example, in the use of the assert_eq! macro. This macro prints the values of instances given as arguments if the equality assertion fails so that programmers can see why the two instances weren’t equal.
PartialEq and Eq for Equality Comparisons
The PartialEq trait allows you to compare instances of a type to check for equality and enables use of the == and != operators.
Deriving PartialEq implements the eq method. When PartialEq is derived on structs, two instances are equal only if all fields are equal, and the instances are not equal if any fields are not equal. When derived on enums, each variant is equal to itself and not equal to the other variants.
The PartialEq trait is required, for example, with the use of the assert_eq! macro, which needs to be able to compare two instances of a type for equality.
The Eq trait has no methods. Its purpose is to signal that for every value of the annotated type, the value is equal to itself. The Eq trait can only be applied to types that also implement PartialEq, although not all types that implement PartialEq can implement Eq. One example of this is floating-point number types: The implementation of floating-point numbers states that two instances of the not-a-number (NaN) value are not equal to each other.
An example of when Eq is required is for keys in a HashMap<K, V> so that the HashMap<K, V> can tell whether two keys are the same.
PartialOrd and Ord for Ordering Comparisons
The PartialOrd trait allows you to compare instances of a type for sorting purposes. A type that implements PartialOrd can be used with the <, >, <=, and >= operators. You can only apply the PartialOrd trait to types that also implement PartialEq.
Deriving PartialOrd implements the partial_cmp method, which returns an Option<Ordering> that will be None when the values given don’t produce an ordering. An example of a value that doesn’t produce an ordering, even though most values of that type can be compared, is the NaN floating point value. Calling partial_cmp with any floating-point number and the NaN floating-point value will return None.
When derived on structs, PartialOrd compares two instances by comparing the value in each field in the order in which the fields appear in the struct definition. When derived on enums, variants of the enum declared earlier in the enum definition are considered less than the variants listed later.
The PartialOrd trait is required, for example, for the gen_range method from the rand crate that generates a random value in the range specified by a range expression.
The Ord trait allows you to know that for any two values of the annotated type, a valid ordering will exist. The Ord trait implements the cmp method, which returns an Ordering rather than an Option<Ordering> because a valid ordering will always be possible. You can only apply the Ord trait to types that also implement PartialOrd and Eq (and Eq requires PartialEq). When derived on structs and enums, cmp behaves the same way as the derived implementation for partial_cmp does with PartialOrd.
An example of when Ord is required is when storing values in a BTreeSet<T>, a data structure that stores data based on the sort order of the values.
Clone and Copy for Duplicating Values
The Clone trait allows you to explicitly create a deep copy of a value, and the duplication process might involve running arbitrary code and copying heap data. See the “Variables and Data Interacting with Clone” section in Chapter 4 for more information on Clone.
Deriving Clone implements the clone method, which when implemented for the whole type, calls clone on each of the parts of the type. This means all the fields or values in the type must also implement Clone to derive Clone.
An example of when Clone is required is when calling the to_vec method on a slice. The slice doesn’t own the type instances it contains, but the vector returned from to_vec will need to own its instances, so to_vec calls clone on each item. Thus, the type stored in the slice must implement Clone.
The Copy trait allows you to duplicate a value by only copying bits stored on the stack; no arbitrary code is necessary. See the “Stack-Only Data: Copy” section in Chapter 4 for more information on Copy.
The Copy trait doesn’t define any methods to prevent programmers from overloading those methods and violating the assumption that no arbitrary code is being run. That way, all programmers can assume that copying a value will be very fast.
You can derive Copy on any type whose parts all implement Copy. A type that implements Copy must also implement Clone because a type that implements Copy has a trivial implementation of Clone that performs the same task as Copy.
The Copy trait is rarely required; types that implement Copy have optimizations available, meaning you don’t have to call clone, which makes the code more concise.
Everything possible with Copy you can also accomplish with Clone, but the code might be slower or have to use clone in places.
Hash for Mapping a Value to a Value of Fixed Size
The Hash trait allows you to take an instance of a type of arbitrary size and map that instance to a value of fixed size using a hash function. Deriving Hash implements the hash method. The derived implementation of the hash method combines the result of calling hash on each of the parts of the type, meaning all fields or values must also implement Hash to derive Hash.
An example of when Hash is required is in storing keys in a HashMap<K, V> to store data efficiently.
Default for Default Values
The Default trait allows you to create a default value for a type. Deriving Default implements the default function. The derived implementation of the default function calls the default function on each part of the type, meaning all fields or values in the type must also implement Default to derive Default.
The Default::default function is commonly used in combination with the struct update syntax discussed in the “Creating Instances from Other Instances with Struct Update Syntax” section in Chapter 5. You can customize a few fields of a struct and then set and use a default value for the rest of the fields by using ..Default::default().
The Default trait is required when you use the method unwrap_or_default on Option<T> instances, for example. If the Option<T> is None, the method unwrap_or_default will return the result of Default::default for the type T stored in the Option<T>.
Annexe D : outils de développement utiles
Appendix D: Useful Development Tools
In this appendix, we talk about some useful development tools that the Rust project provides. We’ll look at automatic formatting, quick ways to apply warning fixes, a linter, and integrating with IDEs.
Automatic Formatting with rustfmt
The rustfmt tool reformats your code according to the community code style. Many collaborative projects use rustfmt to prevent arguments about which style to use when writing Rust: Everyone formats their code using the tool.
Rust installations include rustfmt by default, so you should already have the programs rustfmt and cargo-fmt on your system. These two commands are analogous to rustc and cargo in that rustfmt allows finer grained control and cargo-fmt understands conventions of a project that uses Cargo. To format any Cargo project, enter the following:
$ cargo fmt
Running this command reformats all the Rust code in the current crate. This should only change the code style, not the code semantics. For more information on rustfmt, see its documentation.
Fix Your Code with rustfix
The rustfix tool is included with Rust installations and can automatically fix compiler warnings that have a clear way to correct the problem that’s likely what you want. You’ve probably seen compiler warnings before. For example, consider this code:
Fichier : src/main.rs
fn main() {
let mut x = 42;
println!("{x}");
}Here, we’re defining the variable x as mutable, but we never actually mutate it. Rust warns us about that:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
The warning suggests that we remove the mut keyword. We can automatically apply that suggestion using the rustfix tool by running the command cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
When we look at src/main.rs again, we’ll see that cargo fix has changed the code:
Fichier : src/main.rs
fn main() {
let x = 42;
println!("{x}");
}The variable x is now immutable, and the warning no longer appears.
You can also use the cargo fix command to transition your code between different Rust editions. Editions are covered in Appendix E.
More Lints with Clippy
The Clippy tool is a collection of lints to analyze your code so that you can catch common mistakes and improve your Rust code. Clippy is included with standard Rust installations.
To run Clippy’s lints on any Cargo project, enter the following:
$ cargo clippy
For example, say you write a program that uses an approximation of a mathematical constant, such as pi, as this program does:
fn main() {
let x = 3.1415;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Running cargo clippy on this project results in this error:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
This error lets you know that Rust already has a more precise PI constant defined, and that your program would be more correct if you used the constant instead. You would then change your code to use the PI constant.
The following code doesn’t result in any errors or warnings from Clippy:
fn main() {
let x = std::f64::consts::PI;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}For more information on Clippy, see its documentation.
IDE Integration Using rust-analyzer
To help with IDE integration, the Rust community recommends using rust-analyzer. This tool is a set of compiler-centric utilities that speak Language Server Protocol, which is a specification for IDEs and programming languages to communicate with each other. Different clients can use rust-analyzer, such as the Rust analyzer plug-in for Visual Studio Code.
Visit the rust-analyzer project’s home page for installation instructions, then install the language server support in your particular IDE. Your IDE will gain capabilities such as autocompletion, jump to definition, and inline errors.
Annexe E : éditions
Appendix E: Editions
In Chapter 1, you saw that cargo new adds a bit of metadata to your Cargo.toml file about an edition. This appendix talks about what that means!
The Rust language and compiler have a six-week release cycle, meaning users get a constant stream of new features. Other programming languages release larger changes less often; Rust releases smaller updates more frequently. After a while, all of these tiny changes add up. But from release to release, it can be difficult to look back and say, “Wow, between Rust 1.10 and Rust 1.31, Rust has changed a lot!”
Every three years or so, the Rust team produces a new Rust edition. Each edition brings together the features that have landed into a clear package with fully updated documentation and tooling. New editions ship as part of the usual six-week release process.
Editions serve different purposes for different people:
- For active Rust users, a new edition brings together incremental changes into an easy-to-understand package.
- For non-users, a new edition signals that some major advancements have landed, which might make Rust worth another look.
- For those developing Rust, a new edition provides a rallying point for the project as a whole.
At the time of this writing, four Rust editions are available: Rust 2015, Rust 2018, Rust 2021, and Rust 2024. This book is written using Rust 2024 edition idioms.
The edition key in Cargo.toml indicates which edition the compiler should use for your code. If the key doesn’t exist, Rust uses 2015 as the edition value for backward compatibility reasons.
Each project can opt in to an edition other than the default 2015 edition. Editions can contain incompatible changes, such as including a new keyword that conflicts with identifiers in code. However, unless you opt in to those changes, your code will continue to compile even as you upgrade the Rust compiler version you use.
All Rust compiler versions support any edition that existed prior to that compiler’s release, and they can link crates of any supported editions together. Edition changes only affect the way the compiler initially parses code. Therefore, if you’re using Rust 2015 and one of your dependencies uses Rust 2018, your project will compile and be able to use that dependency. The opposite situation, where your project uses Rust 2018 and a dependency uses Rust 2015, works as well.
To be clear: Most features will be available on all editions. Developers using any Rust edition will continue to see improvements as new stable releases are made. However, in some cases, mainly when new keywords are added, some new features might only be available in later editions. You will need to switch editions if you want to take advantage of such features.
For more details, see The Rust Edition Guide. This is a complete book that enumerates the differences between editions and explains how to automatically upgrade your code to a new edition via cargo fix.
Annexe F : traduction du Livre
Appendix F: Translations of the Book
For resources in languages other than English. Most are still in progress; see the Translations label to help or let us know about a new translation!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O’zbek
- Tiếng Việt
- Italiano
- বাংলা
Annexe G : comment Rust est fabriqué, et “Nightly Rust”
Appendix G - How Rust is Made and “Nightly Rust”
This appendix is about how Rust is made and how that affects you as a Rust developer.
Stability Without Stagnation
As a language, Rust cares a lot about the stability of your code. We want Rust to be a rock-solid foundation you can build on, and if things were constantly changing, that would be impossible. At the same time, if we can’t experiment with new features, we may not find out important flaws until after their release, when we can no longer change things.
Our solution to this problem is what we call “stability without stagnation”, and our guiding principle is this: you should never have to fear upgrading to a new version of stable Rust. Each upgrade should be painless, but should also bring you new features, fewer bugs, and faster compile times.
Choo, Choo! Release Channels and Riding the Trains
Rust development operates on a train schedule. That is, all development is done in the main branch of the Rust repository. Releases follow a software release train model, which has been used by Cisco IOS and other software projects. There are three release channels for Rust:
- Nightly
- Beta
- Stable
Most Rust developers primarily use the stable channel, but those who want to try out experimental new features may use nightly or beta.
Here’s an example of how the development and release process works: let’s assume that the Rust team is working on the release of Rust 1.5. That release happened in December of 2015, but it will provide us with realistic version numbers. A new feature is added to Rust: a new commit lands on the main branch. Each night, a new nightly version of Rust is produced. Every day is a release day, and these releases are created by our release infrastructure automatically. So as time passes, our releases look like this, once a night:
nightly: * - - * - - *
Every six weeks, it’s time to prepare a new release! The beta branch of the Rust repository branches off from the main branch used by nightly. Now, there are two releases:
nightly: * - - * - - *
|
beta: *
Most Rust users do not use beta releases actively, but test against beta in their CI system to help Rust discover possible regressions. In the meantime, there’s still a nightly release every night:
nightly: * - - * - - * - - * - - *
|
beta: *
Let’s say a regression is found. Good thing we had some time to test the beta release before the regression snuck into a stable release! The fix is applied to the main branch, so that nightly is fixed, and then the fix is backported to the beta branch, and a new release of beta is produced:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Six weeks after the first beta was created, it’s time for a stable release! The stable branch is produced from the beta branch:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Hooray! Rust 1.5 is done! However, we’ve forgotten one thing: because the six weeks have gone by, we also need a new beta of the next version of Rust, 1.6. So after stable branches off of beta, the next version of beta branches off of nightly again:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
This is called the “train model” because every six weeks, a release “leaves the station”, but still has to take a journey through the beta channel before it arrives as a stable release.
Rust releases every six weeks, like clockwork. If you know the date of one Rust release, you can know the date of the next one: it’s six weeks later. A nice aspect of having releases scheduled every six weeks is that the next train is coming soon. If a feature happens to miss a particular release, there’s no need to worry: another one is happening in a short time! This helps reduce pressure to sneak possibly unpolished features in close to the release deadline.
Thanks to this process, you can always check out the next build of Rust and verify for yourself that it’s easy to upgrade to: if a beta release doesn’t work as expected, you can report it to the team and get it fixed before the next stable release happens! Breakage in a beta release is relatively rare, but rustc is still a piece of software, and bugs do exist.
Maintenance time
The Rust project supports the most recent stable version. When a new stable version is released, the old version reaches its end of life (EOL). This means each version is supported for six weeks.
Unstable Features
There’s one more catch with this release model: unstable features. Rust uses a technique called “feature flags” to determine what features are enabled in a given release. If a new feature is under active development, it lands on the main branch, and therefore, in nightly, but behind a feature flag. If you, as a user, wish to try out the work-in-progress feature, you can, but you must be using a nightly release of Rust and annotate your source code with the appropriate flag to opt in.
If you’re using a beta or stable release of Rust, you can’t use any feature flags. This is the key that allows us to get practical use with new features before we declare them stable forever. Those who wish to opt into the bleeding edge can do so, and those who want a rock-solid experience can stick with stable and know that their code won’t break. Stability without stagnation.
This book only contains information about stable features, as in-progress features are still changing, and surely they’ll be different between when this book was written and when they get enabled in stable builds. You can find documentation for nightly-only features online.
Rustup and the Role of Rust Nightly
Rustup makes it easy to change between different release channels of Rust, on a global or per-project basis. By default, you’ll have stable Rust installed. To install nightly, for example:
$ rustup toolchain install nightly
You can see all of the toolchains (releases of Rust and associated components) you have installed with rustup as well. Here’s an example on one of your authors’ Windows computer:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
As you can see, the stable toolchain is the default. Most Rust users use stable most of the time. You might want to use stable most of the time, but use nightly on a specific project, because you care about a cutting-edge feature. To do so, you can use rustup override in that project’s directory to set the nightly toolchain as the one rustup should use when you’re in that directory:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Now, every time you call rustc or cargo inside of ~/projects/needs-nightly, rustup will make sure that you are using nightly Rust, rather than your default of stable Rust. This comes in handy when you have a lot of Rust projects!
The RFC Process and Teams
So how do you learn about these new features? Rust’s development model follows a Request For Comments (RFC) process. If you’d like an improvement in Rust, you can write up a proposal, called an RFC.
Anyone can write RFCs to improve Rust, and the proposals are reviewed and discussed by the Rust team, which is comprised of many topic subteams. There’s a full list of the teams on Rust’s website, which includes teams for each area of the project: language design, compiler implementation, infrastructure, documentation, and more. The appropriate team reads the proposal and the comments, writes some comments of their own, and eventually, there’s consensus to accept or reject the feature.
If the feature is accepted, an issue is opened on the Rust repository, and someone can implement it. The person who implements it very well may not be the person who proposed the feature in the first place! When the implementation is ready, it lands on the main branch behind a feature gate, as we discussed in the “Unstable Features” section.
After some time, once Rust developers who use nightly releases have been able to try out the new feature, team members will discuss the feature, how it’s worked out on nightly, and decide if it should make it into stable Rust or not. If the decision is to move forward, the feature gate is removed, and the feature is now considered stable! It rides the trains into a new stable release of Rust.